1. 数据操作
代码文件见 chapter_preliminaries/ndarray.ipynb
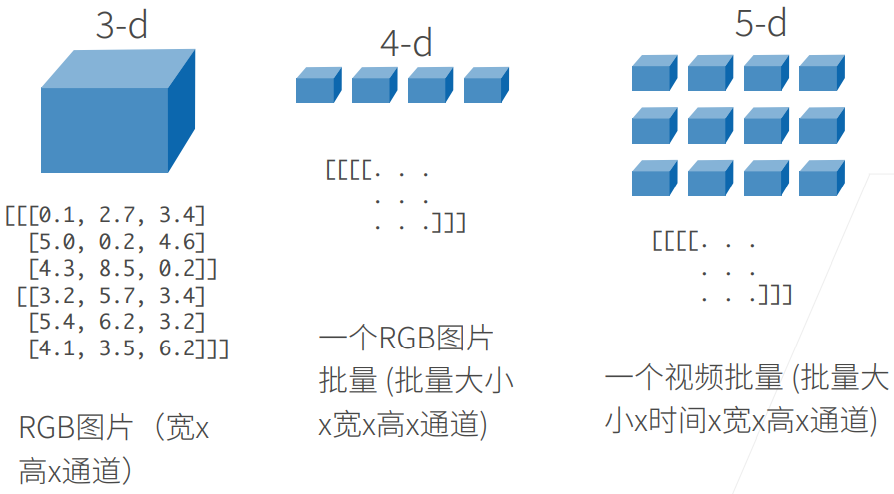
1.1 张量 Tensor / n 维数组
张量 Tensor 其实就是 n 维数组,只不过在 pytorch 和 tensorflow 中称为张量(tensor)
N 维数组(张量 Tensor)样例:
1.1.1 创建张量
创建张量,需要
- 形状:eg. 3×4 矩阵
- 每个元素的数据类型:eg. 32 位浮点数
每个元素的值:eg. 全是 0,或者随机数
# 用 arange 创建一个行向量 x,这个行向量包含从 0 开始的前 12 个整数,它们被默认创建为浮点数x = torch.arange(12)x # tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
# 通过张量的shape属性来访问张量(沿每个轴的长度)的形状x.shape # torch.Size([12])
# 张量中元素的总数,即形状的所有元素乘积x.numel() # 12
X = x.reshape(3, 4)X # tensor([[ 0, 1, 2, 3],# [ 4, 5, 6, 7],# [ 8, 9, 10, 11]])
torch.zeros((2, 3, 4)) # tensor([[[0., 0., 0., 0.],# [0., 0., 0., 0.],# [0., 0., 0., 0.]],# [[0., 0., 0., 0.],# [0., 0., 0., 0.],# [0., 0., 0., 0.]]])
torch.ones((2, 3, 4)) # tensor([[[1., 1., 1., 1.],# [1., 1., 1., 1.],# [1., 1., 1., 1.]],# [[1., 1., 1., 1.],# [1., 1., 1., 1.],# [1., 1., 1., 1.]]])
torch.randn(3, 4) # tensor([[ 0.8678, -0.7441, -1.8607, -0.1561],# [-0.8376, -0.6062, 0.5473, -0.6876],# [-0.9210, -0.4903, -1.2670, -1.5453]])
torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])# tensor([[2, 1, 4, 3],# [1, 2, 3, 4],# [4, 3, 2, 1]])
1.1.2 访问元素(索引/切片)
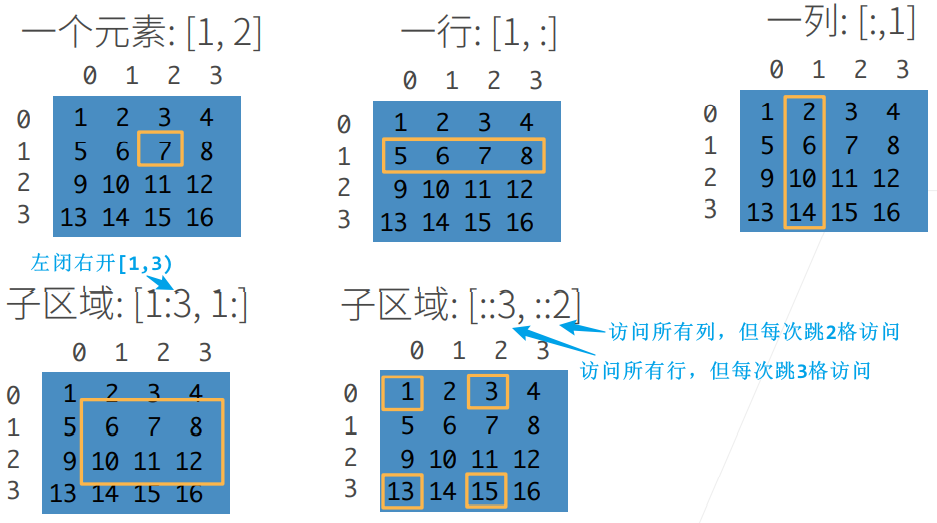
X = torch.arange(12, dtype=torch.float32).reshape((3,4))# tensor([[ 0., 1., 2., 3.],# [ 4., 5., 6., 7.],# [ 8., 9., 10., 11.]])
# 读取一个元素X[1, 2] # tensor(6.)# 改写一个元素X[1, 2] = 9X # tensor([[ 0., 1., 2., 3.],# [ 4., 5., 9., 7.],# [ 8., 9., 10., 11.]])
# 访问最后一行X[-1] # tensor([ 8., 9., 10., 11.])X[-1, :] # tensor([ 8., 9., 10., 11.])
X[:, 1] # tensor([1., 5., 9.])
# 注意 m:n 代表的是左闭右开区间 [m, n)# 取第 [0,2) 行,第 [1, end) 列X[0:2, 1:] # tensor([[1., 2., 3.],# [5., 9., 7.]])
X[0:2, :] = 12X # tensor([[12., 12., 12., 12.],# [12., 12., 12., 12.],# [ 8., 9., 10., 11.]])
1.1.3 运算符
按元素运算
x = torch.tensor([1.0, 2, 4, 8])y = torch.tensor([2, 2, 2, 2])x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算# (tensor([ 3., 4., 6., 10.]),# tensor([-1., 0., 2., 6.]),# tensor([ 2., 4., 8., 16.]),# tensor([0.5000, 1.0000, 2.0000, 4.0000]),# tensor([ 1., 4., 16., 64.]))
torch.exp(x) # tensor([2.7183e+00, 7.3891e+00, 5.4598e+01, 2.9810e+03])
concat 沿指定轴拼接两个张量
- 沿形状的维度 0 (轴 0)拼接张量:拼接后形状的维度 0 = 两个输入张量的形状的第 0 维数值之和
- 这里两个 shape=[3, 4] 的张量拼接,输出张量 shape = [6, 4]
- 沿形状的维度 1 (轴 1)拼接张量:拼接后形状的维度 1 = 两个输入张量的形状的第 1 维数值之和
- 这里两个 shape=[3, 4] 的张量拼接,输出张量 shape = [3, 8]
X = torch.arange(12, dtype=torch.float32).reshape((3,4))Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])# 沿形状的维度 0 (轴 0)拼接张量、沿形状的维度 1 (轴 1)拼接张量torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)# (tensor([[ 0., 1., 2., 3.],# [ 4., 5., 6., 7.],# [ 8., 9., 10., 11.],# [ 2., 1., 4., 3.],# [ 1., 2., 3., 4.],# [ 4., 3., 2., 1.]]),# tensor([[ 0., 1., 2., 3., 2., 1., 4., 3.],# [ 4., 5., 6., 7., 1., 2., 3., 4.],# [ 8., 9., 10., 11., 4., 3., 2., 1.]]))
- 这里两个 shape=[3, 4] 的张量拼接,输出张量 shape = [3, 8]
逻辑运算符,构建二元张量:输出张量的每个元素都为 True/False,代表两个输入向量对应位置的元素是否相等
X == Y# tensor([[False, True, False, True],# [False, False, False, False],# [False, False, False, False]])
求和
对张量中的所有元素进行求和,会产生一个单元素张量
X = torch.arange(12, dtype=torch.float32).reshape((3,4))X.sum() # tensor(66.)
沿特定轴求和,参见 3.6 降维(sum、mean)
1.1.4 广播机制
在某些情况下,即使形状不同,仍然可以通过调用 广播机制(broadcasting mechanism)来执行按元素操作
a = torch.arange(3).reshape((3, 1))b = torch.arange(2).reshape((1, 2))a, b # (tensor([[0],# [1],# [2]]),# tensor([[0, 1]]))
# 3*1 矩阵 和 1*2 矩阵相加,广播为 3*2 矩阵a + b # tensor([[0, 1],# [1, 2],# [2, 3]])
1.1.5 张量和 numpy、标量的转化
tensor 张量 ↔ numpy 张量 (ndarray):注意这样 tensor 和 numpy 张量共享底层内存,就地更改一个张量的同时也会更改另一个张量
A = X.numpy()B = torch.tensor(A)type(A), type(B) # (numpy.ndarray, torch.Tensor)
大小为 1 的 tensor 张量 -> 标量
a = torch.tensor([3.5])a, a.item(), float(a), int(a) # (tensor([3.5000]), 3.5, 3.5, 3)
2. 数据预处理
代码文件见 chapter_preliminaries/pandas.ipynb
2.1 读取数据集
- 创建一个人工数据集,并存储在 CSV(逗号分隔值)文件
../data/house_tiny.csv中 ```python import os
os.makedirs(os.path.join(‘..’, ‘data’), exist_ok=True) data_file = os.path.join(‘..’, ‘data’, ‘house_tiny.csv’) with open(data_file, ‘w’) as f: f.write(‘NumRooms,Alley,Price\n’) # 列名 f.write(‘NA,Pave,127500\n’) # 每行表示一个数据样本 f.write(‘2,NA,106000\n’) f.write(‘4,NA,178100\n’) f.write(‘NA,NA,140000\n’)
2. 从创建的 CSV 文件中**加载原始数据集**```python# 如果没有安装pandas,只需取消对以下行的注释来安装pandas# !pip install pandasimport pandas as pddata = pd.read_csv(data_file)# print(data)data# NumRooms Alley Price# 0 NaN Pave 127500# 1 2.0 NaN 106000# 2 4.0 NaN 178100# 3 NaN NaN 140000
2.2 处理缺失值
处理缺失值的典型方法:
- 插值法:用一个替代值(比如默认值、均值等)弥补缺失值
- 删除法:直接忽略缺失值
插值法处理缺失值:
数值型的缺失值,用均值代替
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2] inputs = inputs.fillna(inputs.mean()) # print(inputs) inputs # NumRooms Alley # 0 3.0 Pave # 1 2.0 NaN # 2 4.0 NaN # 3 3.0 NaN对于类别型/离散型的缺失值的处理:将缺失值 NAN 也视为一个类别,则 Alley 这一列包含两种类别,可以将每个类别作为一列,类似 multi-hot 编码
inputs = pd.get_dummies(inputs, dummy_na=True) # print(inputs) inputs # NumRooms Alley_Pave Alley_nan # 0 3.0 1 0 # 1 2.0 0 1 # 2 4.0 0 1 # 3 3.0 0 12.3 转换为张量格式
通过以上操作,所有条目都变为数值类型,因此可以转换为张量格式 ```python import torch
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values) X, y
(tensor([[3., 1., 0.],
[2., 0., 1.],
[4., 0., 1.],
[3., 0., 1.]], dtype=torch.float64),
tensor([127500, 106000, 178100, 140000]))
<a name="t9F7B"></a>
# 3. 线性代数
<a name="LlhJ6"></a>
## 3.1 标量
**标量 scalar**:称仅包含一个数值的叫标量(scalar),**标量由只有一个元素的张量表示**
```python
import torch
x = torch.tensor(3.0)
y = torch.tensor(2.0)
x + y, x * y, x / y, x**y # (tensor(5.), tensor(6.), tensor(1.5000), tensor(9.))
3.2 向量
从数学的习惯表达来看,向量(一维数组)应该是列向量。但是在 pytorch 中是以行向量的形式展现的,打印出来是一个行向量。并且在 pytorch 中,同一个向量(一维数组)放在 matmul 做第一个乘数就是行向量,放在 matmul 做第二个乘数就是列向量。
向量:标量值组成的列表,通过一维张量(只有一个轴的张量)处理向量
x = torch.arange(4)
x # tensor([0, 1, 2, 3])
向量元素的访问:通过张量的索引来访问任一元素
x[3] # tensor(3)
长度、维度和形状:
向量的长度通常称为向量的维度(dimension)
len(x) # 4因为向量是一维张量,也就是说只有一个轴,因此也可以通过
shape属性访问向量长度x.shape # torch.Size([4])
3.3 矩阵
矩阵:即二维张量(有两个轴的张量)
A = torch.arange(20).reshape(5, 4)
A # tensor([[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11],
# [12, 13, 14, 15],
# [16, 17, 18, 19]])
A.T # tensor([[ 0, 4, 8, 12, 16],
# [ 1, 5, 9, 13, 17],
# [ 2, 6, 10, 14, 18],
# [ 3, 7, 11, 15, 19]])
B = torch.tensor([[1, 2, 3], [2, 0, 4], [3, 4, 5]])
B == B.T # tensor([[True, True, True],
# [True, True, True],
# [True, True, True]])
3.4 张量
张量:具有任意轴数的 n 维数组(标量 -> 向量 -> 矩阵 -> 张量)
X = torch.arange(24).reshape(2, 3, 4)
X # tensor([[[ 0, 1, 2, 3],
# [ 4, 5, 6, 7],
# [ 8, 9, 10, 11]],
# [[12, 13, 14, 15],
# [16, 17, 18, 19],
# [20, 21, 22, 23]]])
3.5 张量算法的基本性质
元素操作:给定具有相同形状的任意两个张量,任何按元素二元运算的结果都将是相同形状的张量
A = torch.arange(20, dtype=torch.float32).reshape(5, 4)
B = A.clone() # 通过分配新内存,将A的一个副本分配给B
A, A + B # (tensor([[ 0., 1., 2., 3.],
# [ 4., 5., 6., 7.],
# [ 8., 9., 10., 11.],
# [12., 13., 14., 15.],
# [16., 17., 18., 19.]]),
# tensor([[ 0., 2., 4., 6.],
# [ 8., 10., 12., 14.],
# [16., 18., 20., 22.],
# [24., 26., 28., 30.],
# [32., 34., 36., 38.]]))
A * B # tensor([[ 0., 1., 4., 9.],
# [ 16., 25., 36., 49.],
# [ 64., 81., 100., 121.],
# [144., 169., 196., 225.],
# [256., 289., 324., 361.]])
a = 2
X = torch.arange(24).reshape(2, 3, 4)
a + X, (a * X).shape # (tensor([[[ 2, 3, 4, 5],
# [ 6, 7, 8, 9],
# [10, 11, 12, 13]],
# [[14, 15, 16, 17],
# [18, 19, 20, 21],
# [22, 23, 24, 25]]]),
# torch.Size([2, 3, 4]))
3.6 降维(sum、mean)
- 张量求和
sum
- 对张量的所有元素求和 ```python x = torch.arange(4, dtype=torch.float32) x, x.sum() # (tensor([0., 1., 2., 3.]), tensor(6.))
A.shape, A.sum() # (torch.Size([5, 4]), tensor(190.))
- 指定张量**沿某个轴求和**(降维):
- **沿 axis = k 求和,就相当于消去轴 k**(第 k 维),更形象地可以理解为**沿轴 k 拍扁**。
- 下面的例子沿 axis = 0 求和,就是将 shape = [5, 4] 的轴 0 (也就是 5)消去/拍扁,因此求和后的 shape = [4]
```python
A_sum_axis0 = A.sum(axis=0)
A_sum_axis0, A_sum_axis0.shape # (tensor([40., 45., 50., 55.]), torch.Size([4]))
A_sum_axis1 = A.sum(axis=1)
A_sum_axis1, A_sum_axis1.shape # (tensor([ 6., 22., 38., 54., 70.]), torch.Size([5]))
- 指定张量沿多个轴求和(降维)
- 沿 axis = [k1,k2] 求和,就相当于先消去轴 k1,再消去轴 k2(第 k1、k2 维),更形象地可以理解为先沿轴 k1 拍扁,再沿轴 k2 拍扁。
- shape = [2, 5, 4] 的张量沿轴 axis=[1,2] 求和,结果变为 shape = [2](只剩下轴 0)
A.sum(axis=[0, 1]) # Same as `A.sum()` # tensor(190.)
- 张量求均值
mean
对张量所有元素求均值
A.mean(), A.sum() / A.numel() # (tensor(9.5000), tensor(9.5000))指定张量沿某个轴求均值(降维)
A.mean(axis=0), A.sum(axis=0) / A.shape[0] # (tensor([ 8., 9., 10., 11.]), tensor([ 8., 9., 10., 11.]))3.6.1 非降维求和/平均
通过
**keepdims=True**使得计算总和 or 均值时保持轴数不变。例如 shape = [2, 5, 4] 的张量沿轴 axis=1 求和,结果变为 shape = [2,1,4](轴 1 的长度变为 1);shape = [2, 5, 4] 的张量沿轴 axis=[1,2] 求和,结果变为 shape = [2,1,1](轴 1、2 的长度都变为 1)如下求和操作的结果
sum_A的shape仍包含两个轴,只不过轴 1 的shape变为 1sum_A = A.sum(axis=1, keepdims=True) sum_A # tensor([[ 6.], # [22.], # [38.], # [54.], # [70.]])由于
sum_A在对每行进行求和后仍保持两个轴,可以通过广播将A除以sum_AA / sum_A # tensor([[0.0000, 0.1667, 0.3333, 0.5000], # [0.1818, 0.2273, 0.2727, 0.3182], # [0.2105, 0.2368, 0.2632, 0.2895], # [0.2222, 0.2407, 0.2593, 0.2778], # [0.2286, 0.2429, 0.2571, 0.2714]])cumsum沿某个轴计算 A 元素的累积总和,不会沿任何轴降低输入张量的维度A.cumsum(axis=0) # tensor([[ 0., 1., 2., 3.], # [ 4., 6., 8., 10.], # [12., 15., 18., 21.], # [24., 28., 32., 36.], # [40., 45., 50., 55.]])3.7 矩阵乘法
3.7.1 向量点积 dot product
两个向量点积,等价于元素乘再求和 ```python y = torch.ones(4, dtype = torch.float32) x, y, torch.dot(x, y)
(tensor([0., 1., 2., 3.]), tensor([1., 1., 1., 1.]), tensor(6.))
torch.sum(x * y) # tensor(6.)
<a name="CoaRp"></a>
### 3.7.2 矩阵-向量积
矩阵和向量相乘,使用与点积相同的 `mv` 函数,要求矩阵 A 的轴 1 的长度 = x 的长度(维数)
```python
A.shape, x.shape, torch.mv(A, x)
# (torch.Size([5, 4]), torch.Size([4]), tensor([ 14., 38., 62., 86., 110.]))
3.7.3 矩阵-矩阵乘法(矩阵乘法)
矩阵和矩阵相乘,用 mm 函数
B = torch.ones(4, 3)
torch.mm(A, B) # tensor([[ 6., 6., 6.],
# [22., 22., 22.],
# [38., 38., 38.],
# [54., 54., 54.],
# [70., 70., 70.]])
3.8 范数
向量范数是将向量映射到标量的函数 f(·)
L2 范数:张量元素平方和的平方根
向量的 L2 范数
u = torch.tensor([3.0, -4.0]) torch.norm(u) # tensor(5.)矩阵的 L2 范数
torch.norm(torch.ones((4, 9))) # tensor(6.)
L1 范数:张量元素的绝对值之和
torch.abs(u).sum() # tensor(7.)
4. 矩阵计算(矩阵求导/微积分)
梯度指向值变化最大的方向
4.1 标量导数
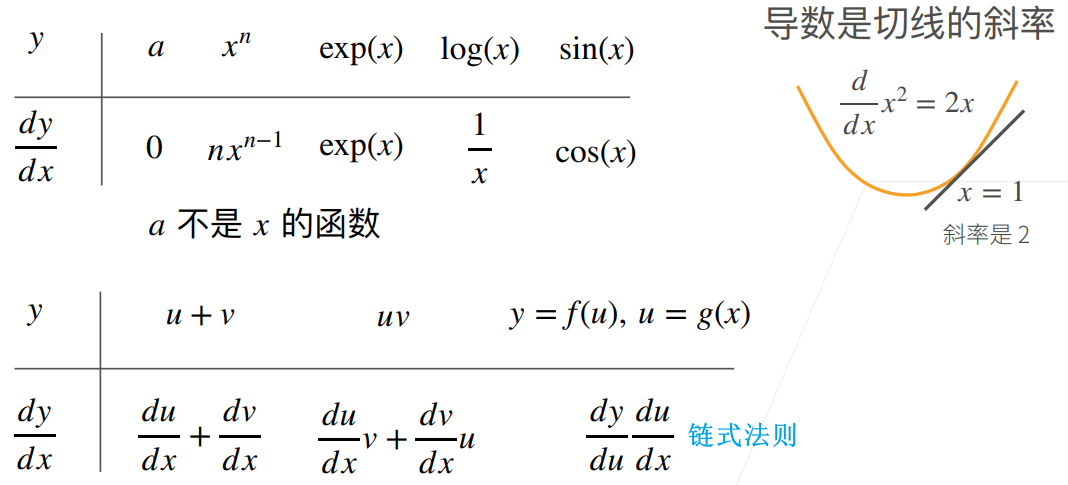
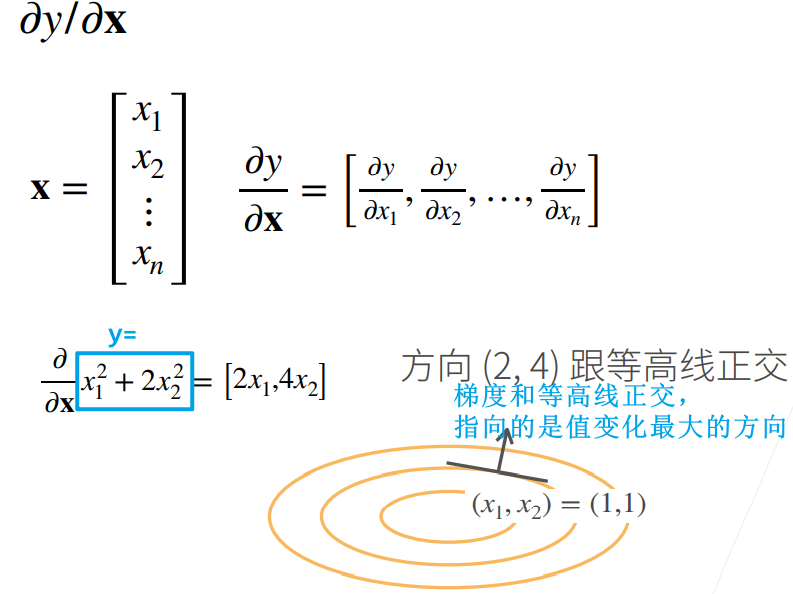
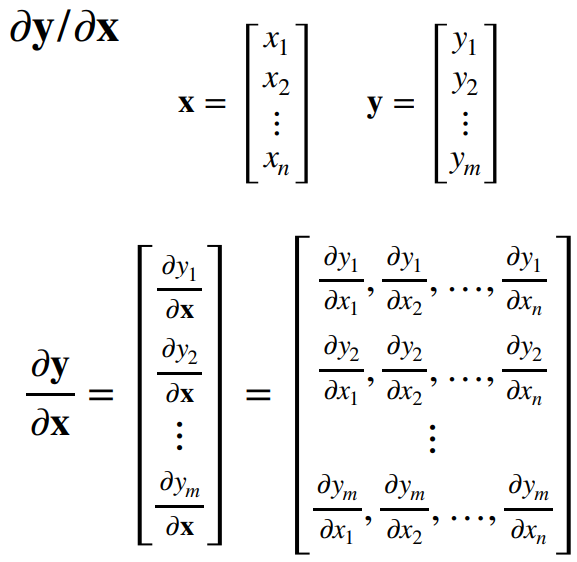
4.2 梯度:将导数拓展到向量
数学的习惯表达上,向量是列向量
深度学习中一般是标量对向量/矩阵求导,因为目标函数(loss)一般都是标量
- 标量对向量(
shape = [n, 1])求导,得到的是行向量(shape = [1, n],相当于经过了转置)
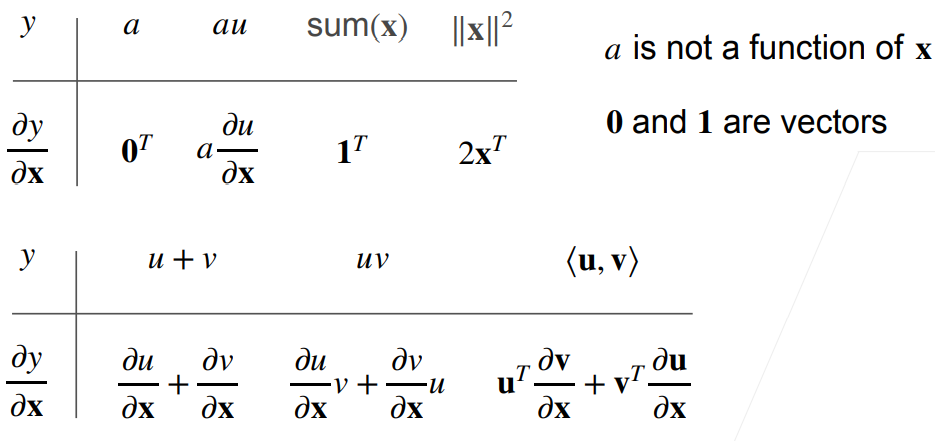
- 向量(
shape = [n, 1])对标量求导,得到的还是列向量(shape = [n, 1])
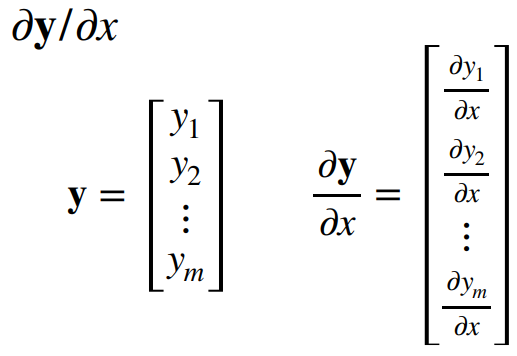
- 向量(
shape = [k, 1])对向量(shape = [n, 1])求导,得到的是矩阵(shape = [k, n])
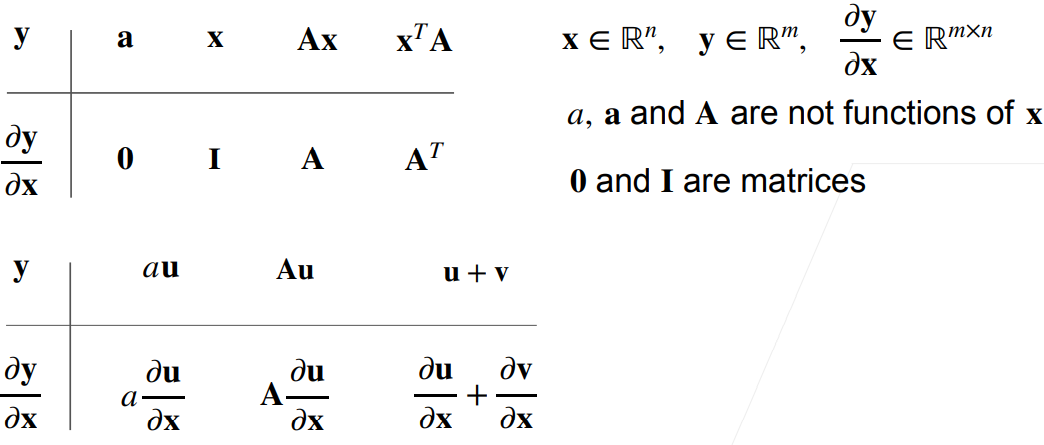
4.3 梯度:拓展到矩阵

5. 自动求导(微分)
5.1 向量链式法则
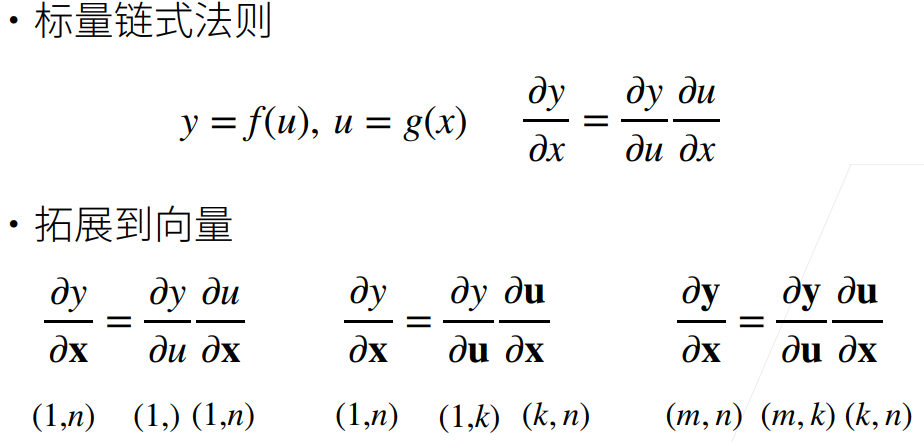
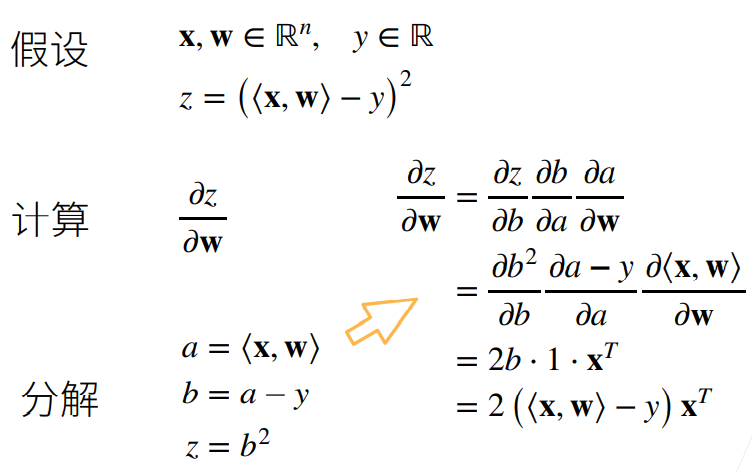
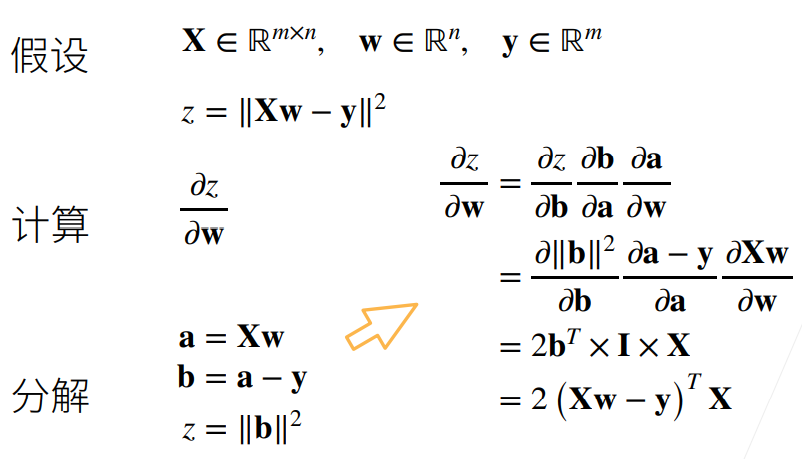
5.2 自动求导
通过计算图表示链式法则
- 将代码分解成操作子
- 将计算表示成一个无环图
链式法则  两种模式:
两种模式:
- 正向累积:

- 缺点:需要存储正向的所有中间结果,因此空间复杂度 O(n)
- 反向累积(反向传播):

- 时间复杂度和正向相同,都是 O(n);空间复杂度 O(1)
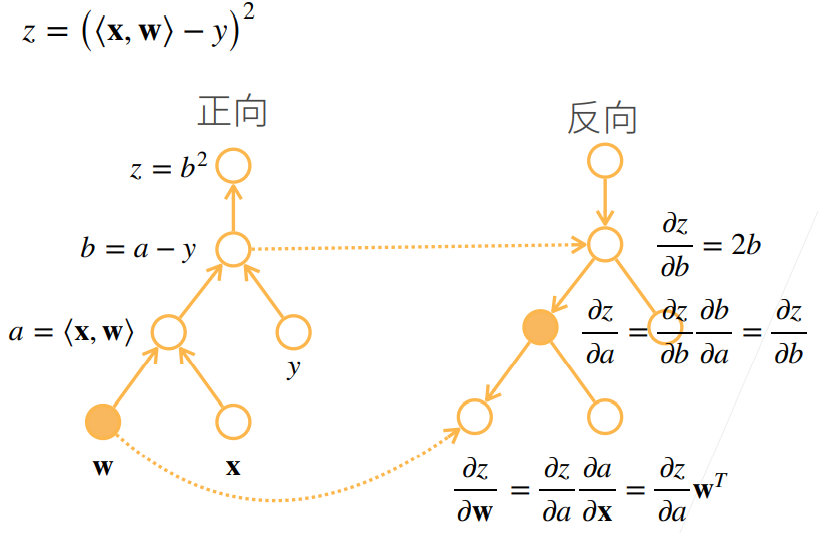
例子:
- 对函数
 关于列向量
关于列向量 求导,这里 y 是标量
求导,这里 y 是标量深度学习中 loss 通常是标量,因此一般都是标量对张量求导
import torch
x = torch.arange(4.0)
x # tensor([0., 1., 2., 3.])
x.requires_grad_(True) # 等价于 `x = torch.arange(4.0, requires_grad=True)`
x.grad # 变量 x 的梯度,默认值是 None
y = 2 * torch.dot(x, x) # 点积
y # tensor(28., grad_fn=<MulBackward0>)
y.backward() # 反向传播计算梯度
x.grad # tensor([ 0., 4., 8., 12.])
x.grad == 4 * x # tensor([True, True, True, True])
计算
 的另一个函数
的另一个函数x.grad.zero_() # 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值 y = x.sum() # 前向传播,计算 y 的值 y.backward() # 反向传播,自动计算 y 关于 x 每个分量的梯度 x.grad # tensor([1., 1., 1., 1.])分离计算:将某些计算移动到记录的计算图之外 ```python x.grad.zero_() # 清空梯度 y = x x
u = y.detach() # 阻止梯度回传,分离出 y,将其视作一个常数,记为 u z = u x
z.sum().backward() x.grad == u
```python
x.grad.zero_()
y.sum().backward()
x.grad == 2 * x
6. 概率

若有收获,就点个赞吧
0 人点赞
