一、领域驱动概述
1.1、概念 - 什么是领域驱动
领域驱动设计是更擅于解决复杂问题和大规模软件,领域驱动的作用是简化,而不是复杂化。领域驱动设计应对复杂问题的思想可以归类为:分治、抽象和知识。分治: 把问题空间分割为规模更小且易于处理的若干子问题。分割后的问题需要足够小,而且具有边界。
抽象:对业务进行高度的归纳概括,对具体场景总结提炼,提取出关键的特征。
知识:模型是对知识的提炼与转换,领域驱动中设计的模型本身是具备业务含义的。
1.2、作用 - 为什么要用领域驱动
二、传统开发模式
2.1、分层的作用
高内聚:分层的设计可以简化系统设计,让不同的层专注做某一块的事
低耦合:层与层之间通过接口或api来交互,依赖方不用知道被依赖方的细节
复用:分层之后可以做到很高的复用,分而治之
扩展性:分层架构可以让我们更容易做横向扩展
2.2、传统mvc架构
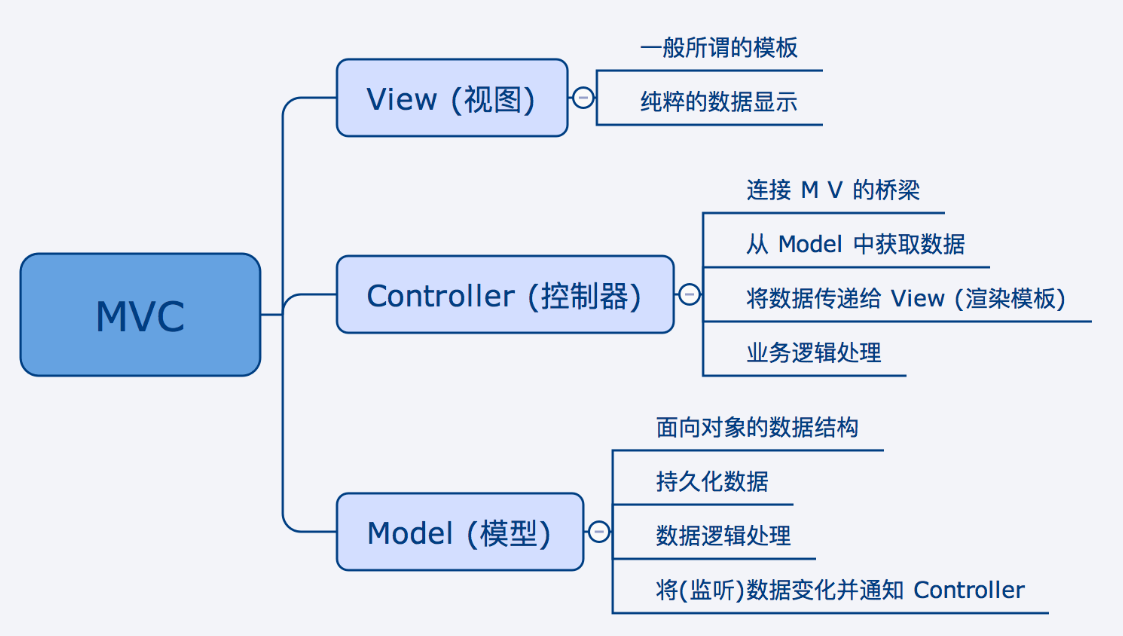
优点:关注前后端分离
缺点:模型层分层太粗,融合了数据处理,业务处理等所有的功能,核心的复杂业务逻辑都放到模型层,导致模型层很乱
使用场景:后端业务逻辑简单的服务,比如接口直接提供对数据库增删改查
2.3、后端分层架构
2.3.1、传统三层架构
表现层:controller
逻辑层:service
数据访问层:dao
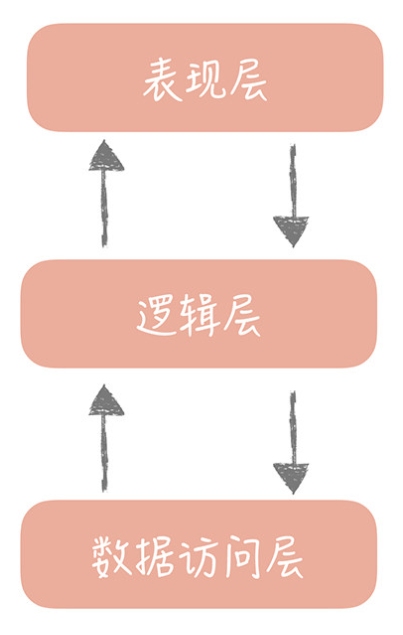
优点:分层简单,逻辑层与数据层分离
2.3.2、三层架构演进
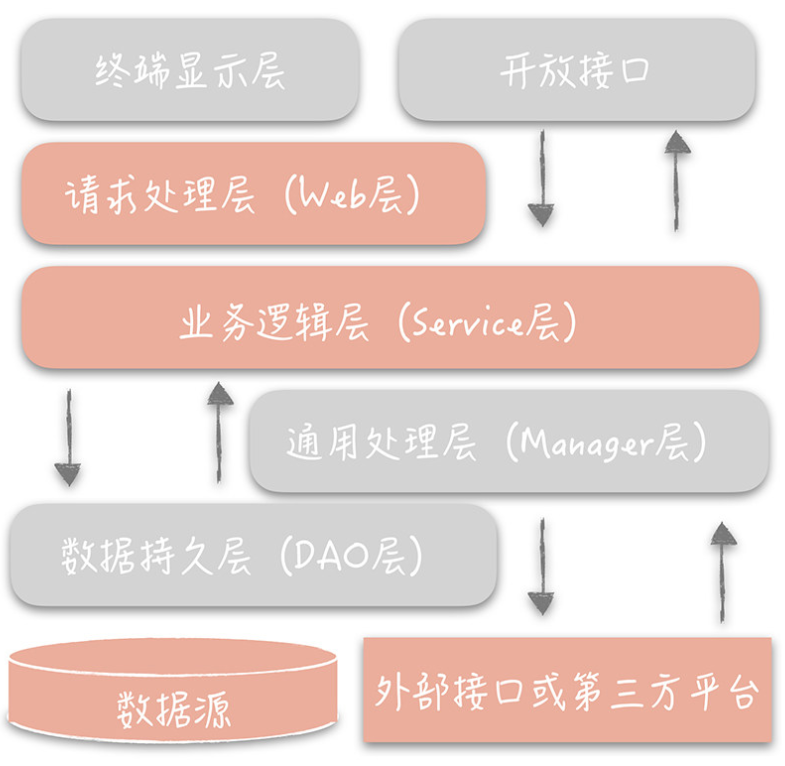
2.4、传统开发模式的弊端
对基础组件和外部服务依赖严重,应该尽可能对业务层屏蔽底层组件的变更
service层分层比较粗,核心的业务复杂度和技术复杂度都放到service层,导致service层很乱,职责不单一 复用性差 维护困难三、领域驱动基本概念
领域驱动设计(Domain-driven Design)是由Eric Evans最早提出的综合软件系统分析和设计的面向对象建模方法。领域驱动设计不同于传统的面向数据的建模方法,而是面向领域建模,将业务概念和业务规则转换为系统中的类型及其属性和行为,从而建立领域模型。领域模型是关于某个特定业务领域的软件模型。通常,领域模型通过对象模型来实现,这些对象同时包含数据和行为,并且表达了准确的业务含义。领域驱动设计通过面向对象的要素及设计原则降低了业务的复杂性,具有更好的可扩展性。3.1、领域驱动中的概念
在应用分治、抽象、知识思想的过程中,领域驱动提出了很多概念,比如领域、子域、核心域、通用域、支撑域、限界上下文、聚合、聚合根、实体、值对象等等,对这些概念的理解是实践的基础。充血模型 vs 贫血模型
通用语言
领域、子域、界限上下文
根据汉语词典的解释,领域具体指一种特定的范围或区域。领域是用来确定范围的,范围即边界。在研究和解决业务问题时,领域驱动设计会按照一定的规则将业务领域进行细分,当领域细分到一定的程度后,领域驱动设计会将问题范围限定在特定的边界内,在这个边界内建立领域模型,进而用代码实现该领域模型,解决相应的业务问题。一个大的领域可以先划分为子领域,我们把划分出来的多个子领域称为子域,每个子域对应一个更小的问题域或更小的业务范围。领域建模的核心思想就是将问题域逐步分解,降低业务理解和系统实现的复杂度。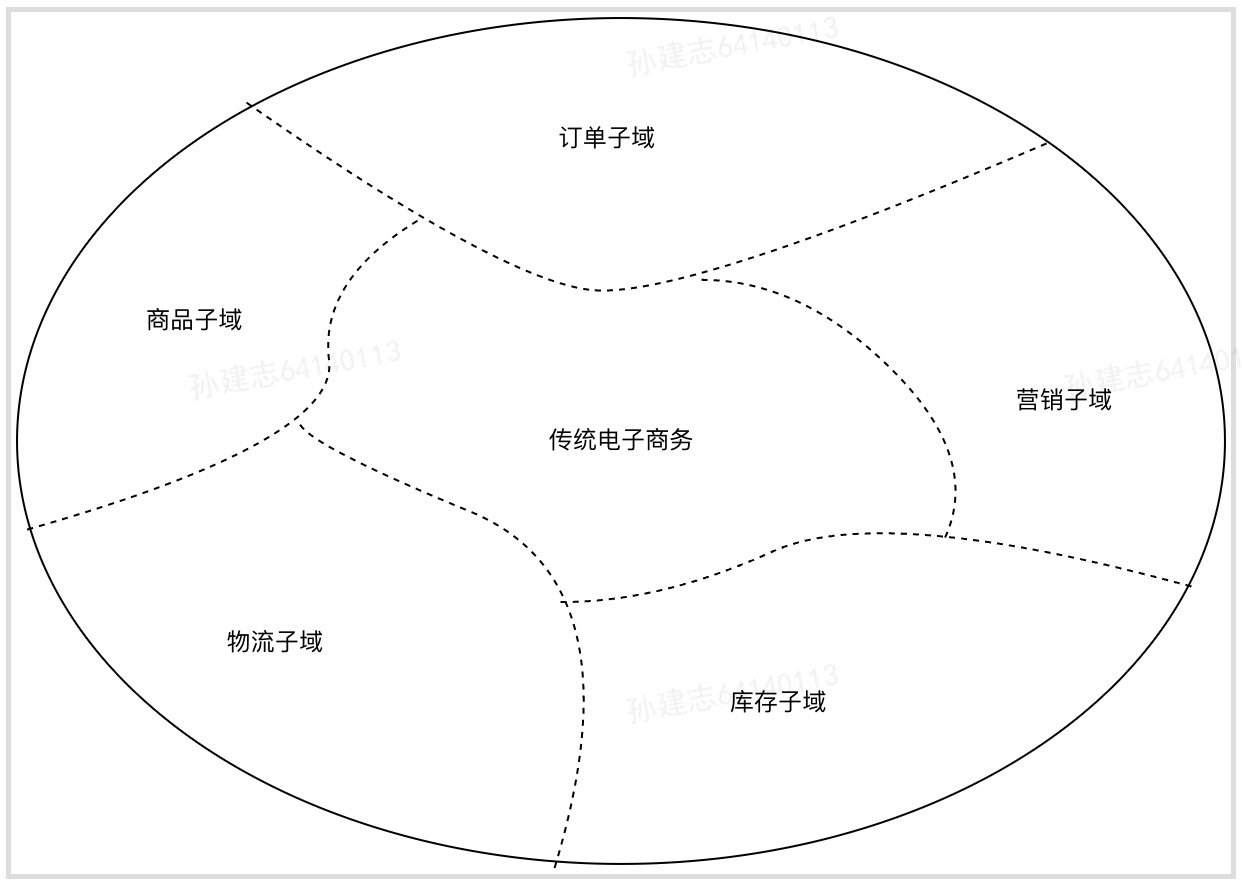
限界上下文是一个显式的边界,领域模型便存在于这个边界之内。领域模型把通用语言表达成软件模型。创建边界的原因在于:每一个模型概念,包括它的属性和方法,在边界之内都具有特殊含义,而在另一个边界里面可能表达不同的含义。以图书出版为例,图书的出版包括以下阶段:
- 概念设计,计划出书——关注图书的大概内容,此时还没有书的名称
- 联系作者,签订合同——关注图书的名称、作者、稿费、完成时间
- 管理图书的编辑过程——关注图书的文字编辑内容,图书的更新记录,历史版本
- 设计图书的布局 ——关注图书的排版、布局和插图内容。
实体、值对象
| 实体 | 值对象 |
|---|---|
| 实体对象表示的是具有一定生命周期并且拥有全局唯一标识的对象。没有身份标识的领域对象不是实体。比如在商户信息域,一个商户就是一个实体,它有唯一的商户id标识。 | 值对象表示用于起描述性作用的,没有唯一标识的对象。 比如,商户的地址信息则为值对象。 |
| 实体对象的相等性是通过比较ID来完成的,对于两个实体,如果他们的所有属性均相同,但是ID不同,那么他们依然是两个不同的实体。 | 对于值对象来说,相等性的判断是通过属性字段来完成的。如果两个值对象的各个属性相同,则是两个相同的值对象 |
值对象还有一个特点是**不变性**,也就是说一个值对象一旦被创建出来了便不能对其进行变更,如果要变更,必须重新创建一个新的值对象整体替换原有的。值对象的不变性使得程序的逻辑变得更加简单,你不用去维护复杂的状态信息,需要的时候创建,不要的时候直接扔掉即可。在领域驱动建模中,最佳实践便是将业务概念尽量建模为值对象。
另外,实体和值对象的划分并不是一成不变的,而应该根据所处的限界上下文来界定,相同一个业务名词,在一个限界上下文中可能是实体,在另外的限界上下文中可能是值对象。设计实体时,应该遵循保持实体专注于身份标识这一设计原则,让实体只承担符合它身份的业务行为,而把内聚性更强的属性分解为单独的值对象。聚合、聚合根
在《领域驱动设计》一书中,对聚合的解释是将实体和值对象划分为聚合并围绕着聚合定义边界。所谓“聚合”,顾名思义,即需要将领域中高度内聚的概念放到一起组成一个整体。至于哪些概念才能聚到一起,需要我们对业务本身有很深刻的认识。聚合根就是软件模型中那些位于一群关联关系中最中心的领域对象。比如,对于一个订单系统,订单(order)便是一个聚合根。聚合根是主要的业务逻辑载体,领域驱动设计中所有的战术实现都围绕着聚合根展开。聚合根一定是实体对象,但是并不是所有实体对象都是聚合根,同时聚合根还可以拥有其他子实体对象。聚合根的ID在整个软件系统中全局唯一,而其下的子实体对象的ID只需在单个聚合根下唯一即可。然而,并不是说领域模型中的所有名词都可以建模为聚合根。在实践时选择一个实体作为每个聚合的根,并允许外部对象仅能持有聚合根的引用。工厂
领域模型中主要是由实体和值对象聚合在一起来进行管理的。聚合对象从创建开始,经历各种不同的状态,直至达到终态。由于聚合是一个边界,聚合根作为对外交互的唯一通道,理应由其承担整个聚合的实例化工作。领域驱动设计要求聚合内所有对象保证一致的生命周期,这往往会导致创建逻辑趋于复杂。为了减少调用者的负担,同时也为了约束生命周期,通常都会引入工厂来创建聚合。严格控制聚合的生命周期,可以禁止任何外部对象绕开聚合根直接创建其内部的对象。
public class Shop {Shop(String id, Address address) {}}public class ShopFactory {public static Shop(String id, Address address) {return new Shop(id, address);}}
资源库
资源库就是用来持久化聚合根的。利用资源库抽象,就可以解耦领域层与外部资源;资源库可以代表任何可以获取资源的地方,而不仅限于数据库,还可以是分布式缓存、本地缓存、云文件等。引入资源库,主要目的还是为了管理聚合的生命周期。工厂负责聚合实例的生,垃圾回收负责聚合实例的死,资源库就负责聚合记录的查询与状态变更,即记录的“增删改查”操作。保证一个聚合对应一个资源库非常重要。聚合只有一个入口,那就是聚合根;对聚合生命周期的管理,也只有一个入口,那就是聚合对应的资源库。要访问聚合内的其他实体和值对象,也只能通过聚合对应的资源库进行,这就保护了聚合的封装性。一言以蔽之:通过资源库获取聚合的引用,通过对象图的单一遍历方向获得聚合内部对象。领域服务
聚合根是业务逻辑的主要载体,也就是说业务逻辑的实现代码应该尽量地放在聚合根或者聚合根的边界之内。但有时,有些业务逻辑并不适合于放在聚合根上,在这种情况下,我们引入领域服务。聚合内的实体与值对象负责处理与自身信息相关的领域行为,工厂和资源库负责管理聚合的生命周期,网关负责封装对外部资源的访问,而领域服务则封装了上述对象角色之间的协作,并被定义为类或接口,对外体现了一种领域行为。领域行为与状态无关,领域行为需要多个聚合参与协作,目的是使用聚合内的实体和值对象编排业务逻辑,领域行为需要与访问包括数据库在内的外部资源协作,切忌将所有的领域逻辑都往领域服务塞。四、领域驱动实践
参考文档

若有收获,就点个赞吧
0 人点赞
