Python分布式爬虫打造搜索引擎
1.课程介绍
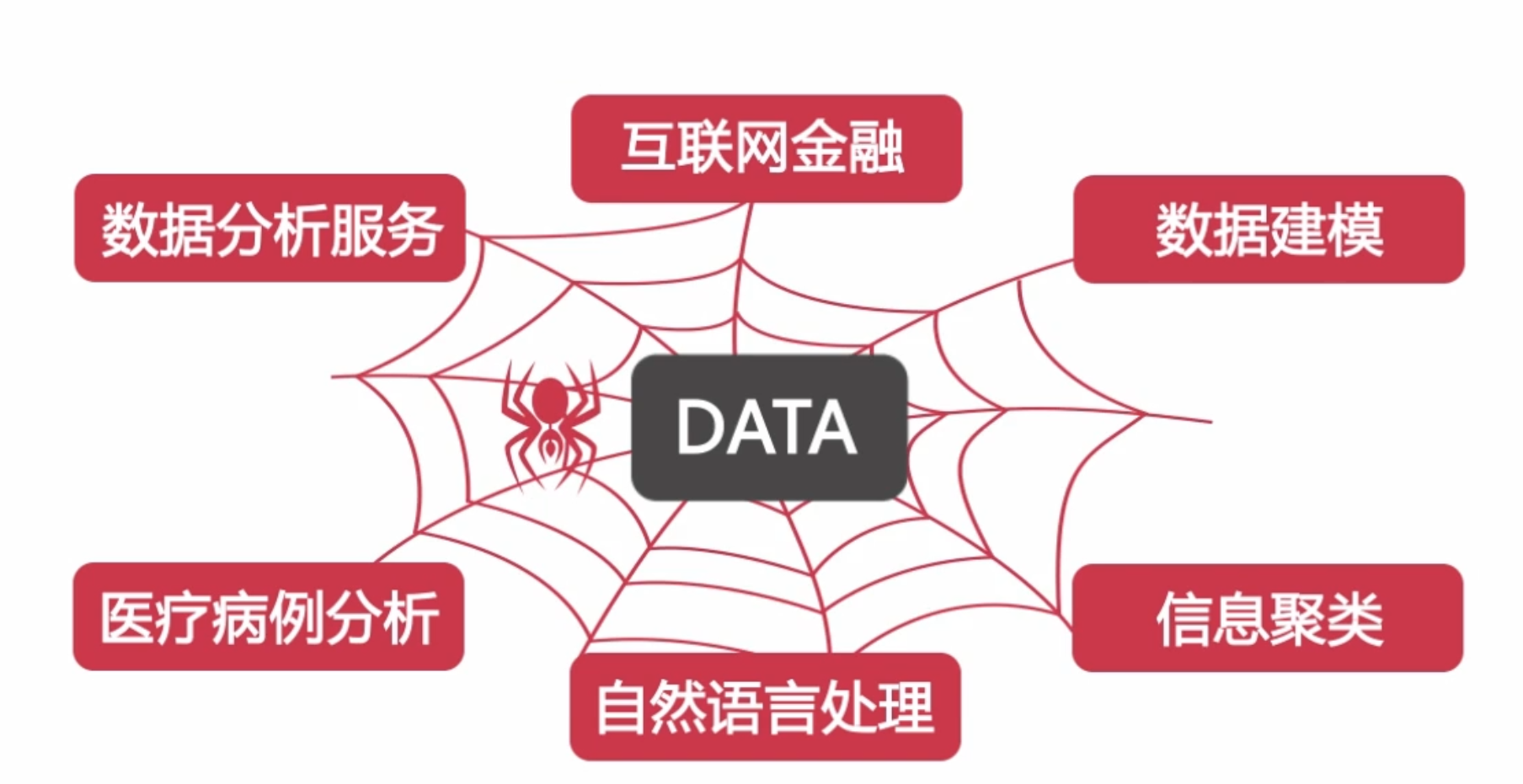



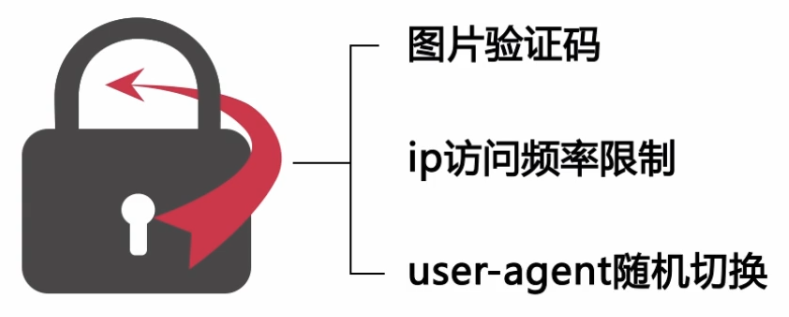

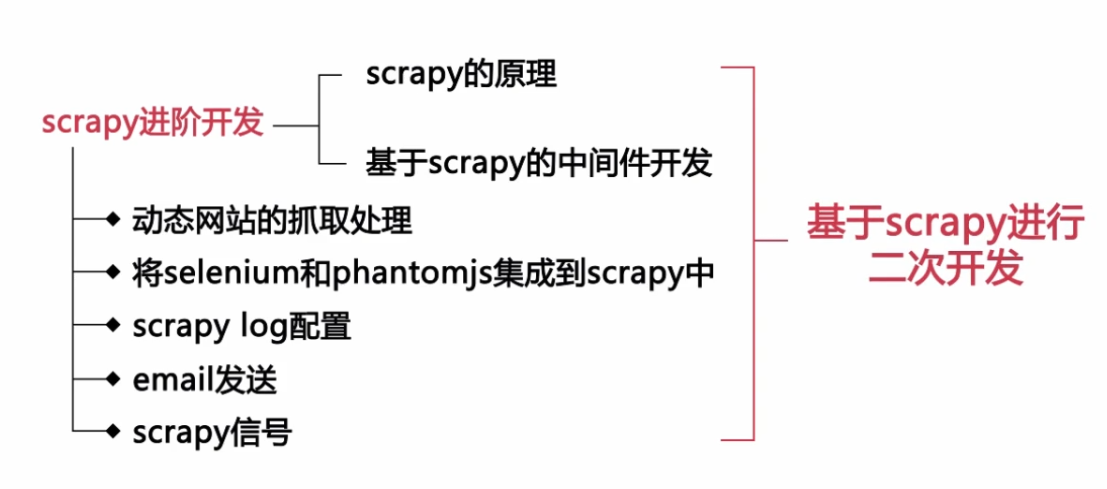
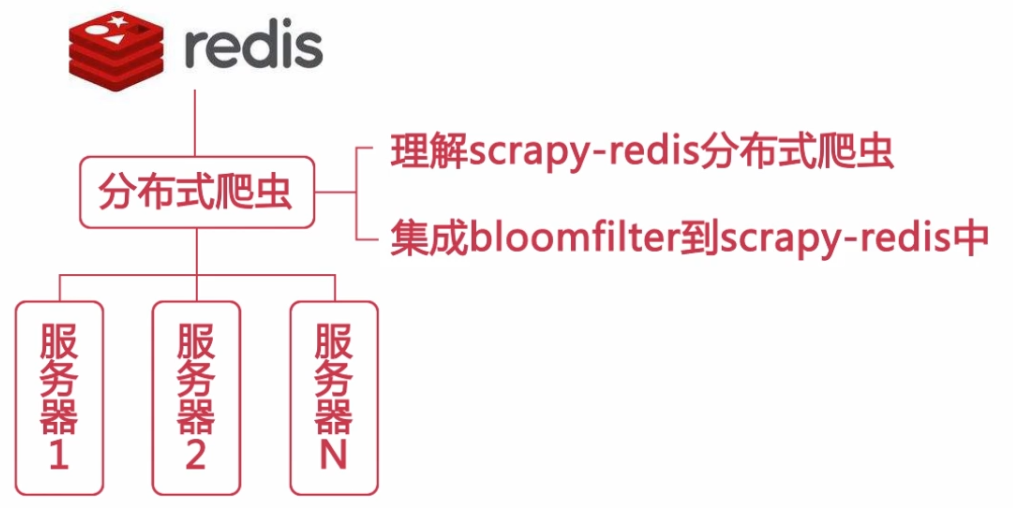

2.开发环境

3.基础知识
3.1 技术选型



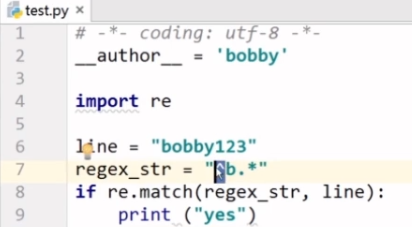
3.2 正则表达式

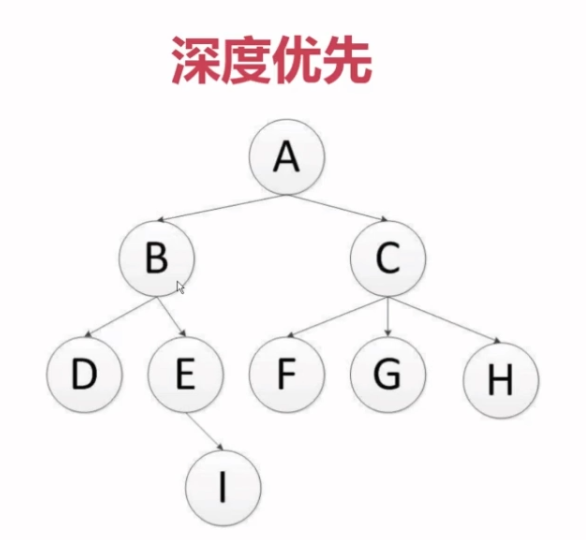
3.3 深度优先vs广度优先
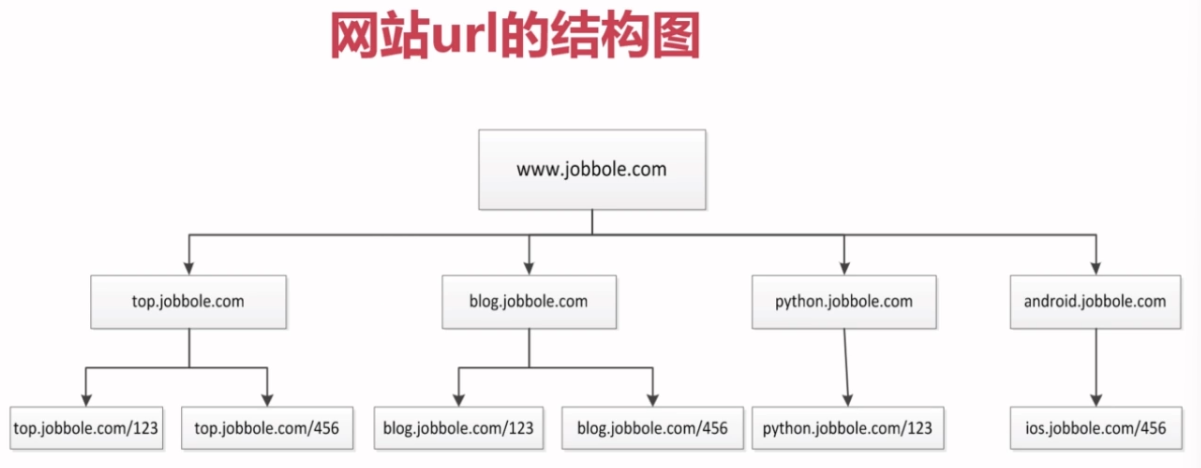
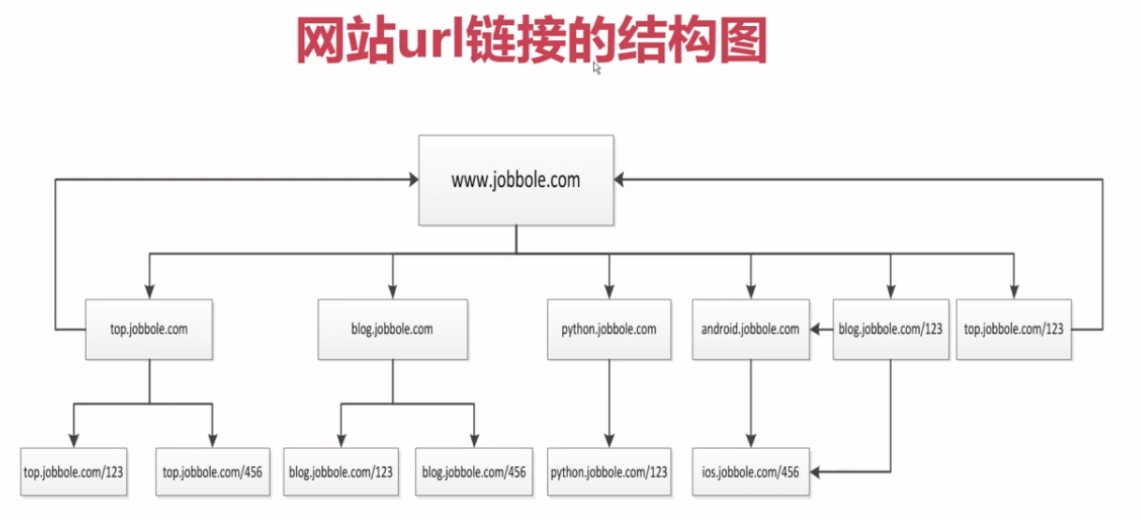



3.4 url去重

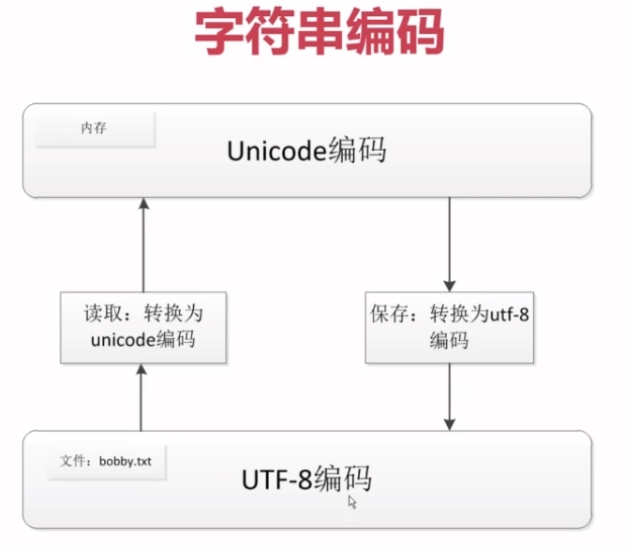
3.5 Unicode和utf8


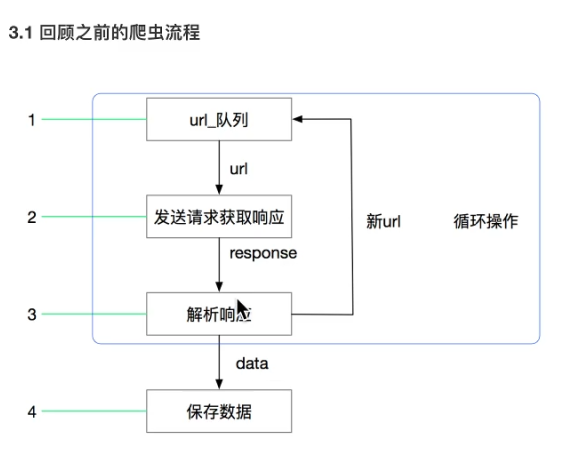
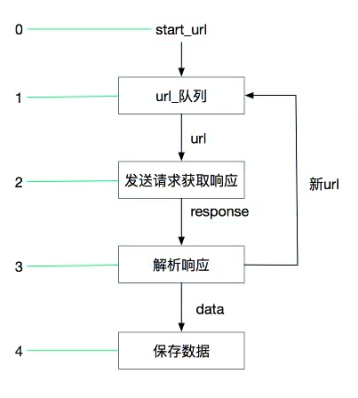
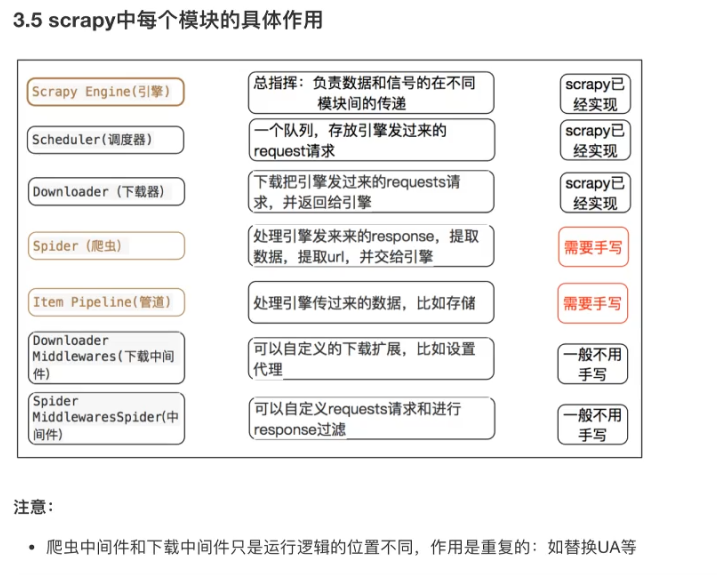
4.scrapy介绍
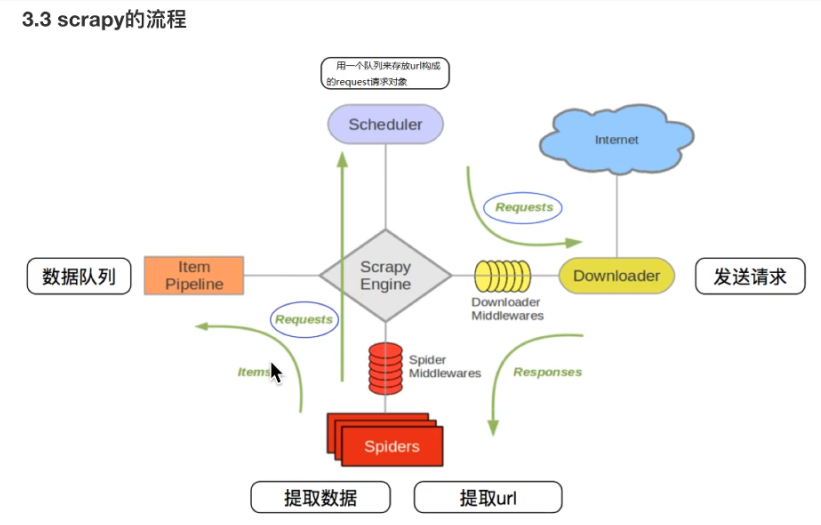
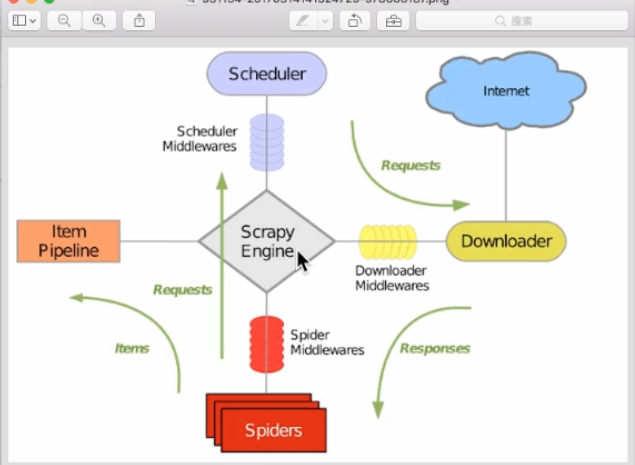
4.1 原理
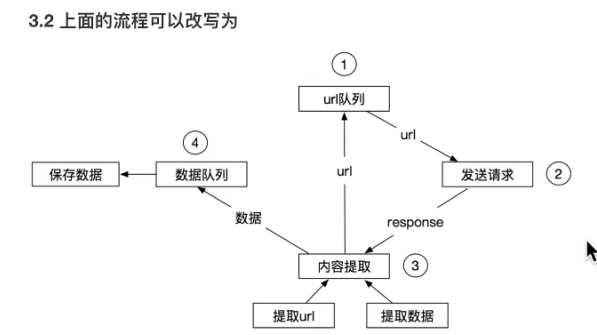
绿色箭头是数据流;中间是中间件;



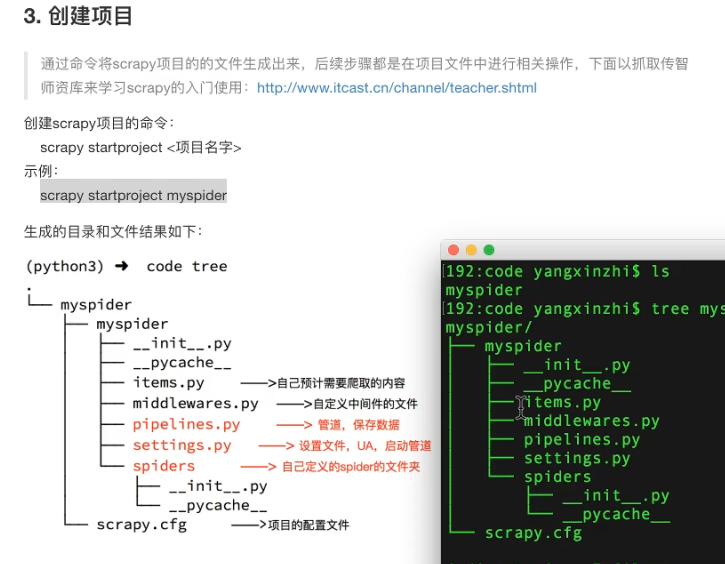
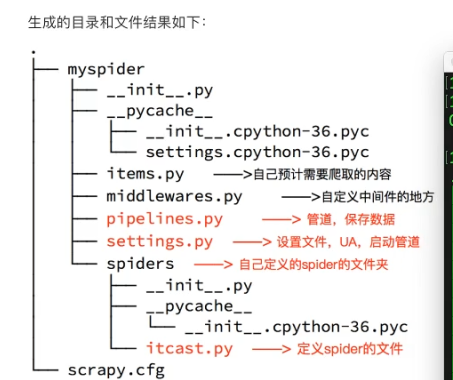
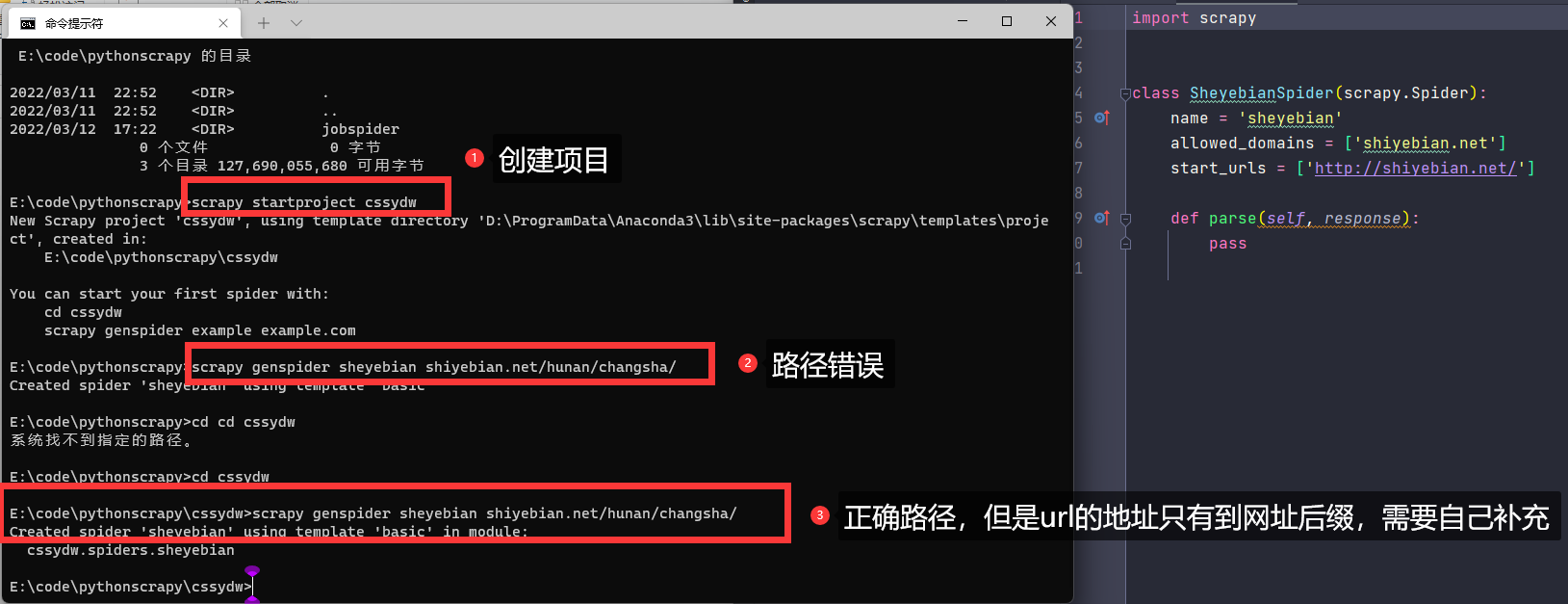
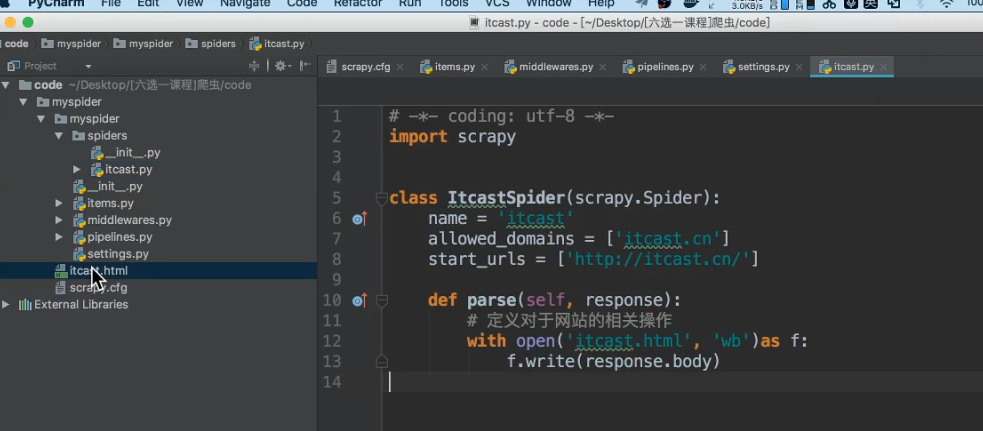
4.2 安装创建项目


http://changsha.offcn.com/html/shiyedanwei/



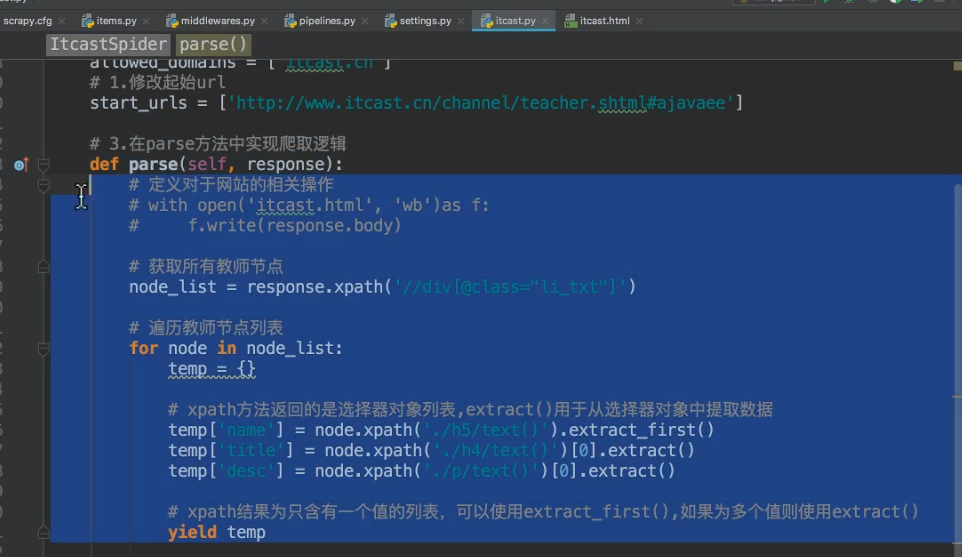
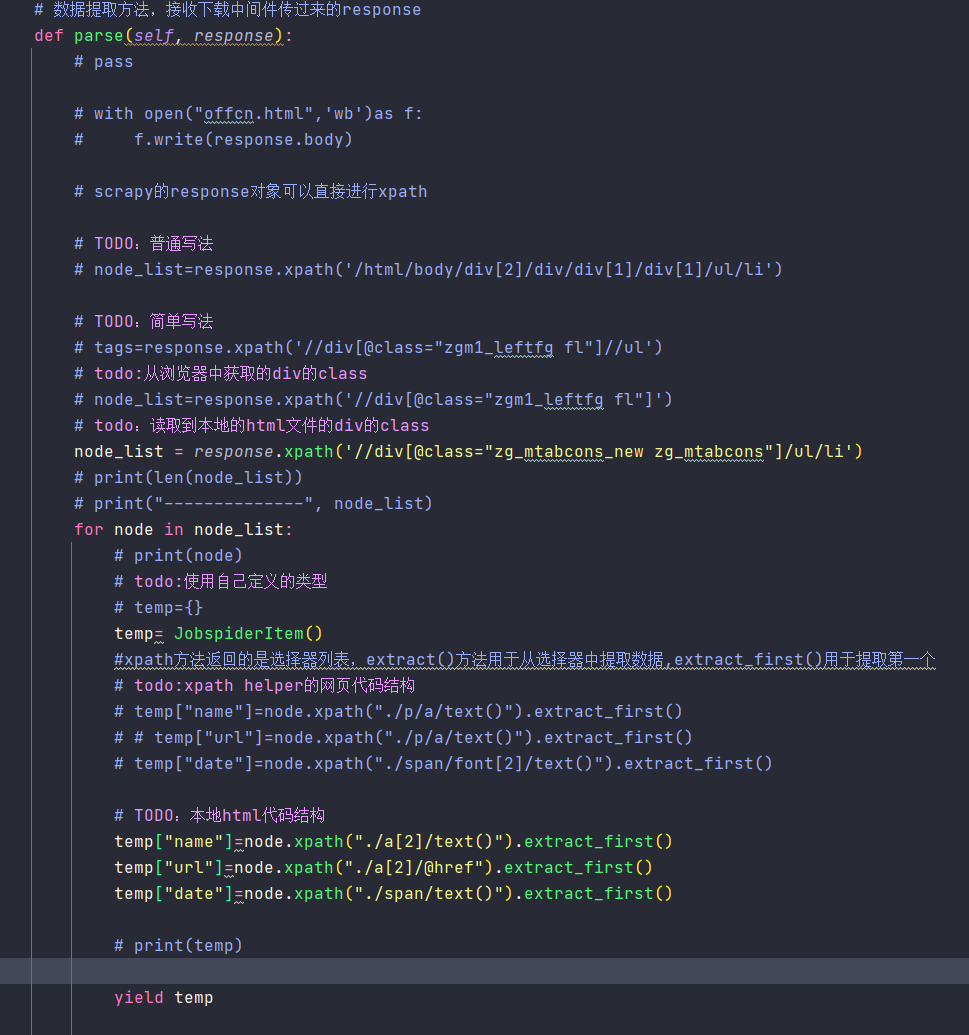




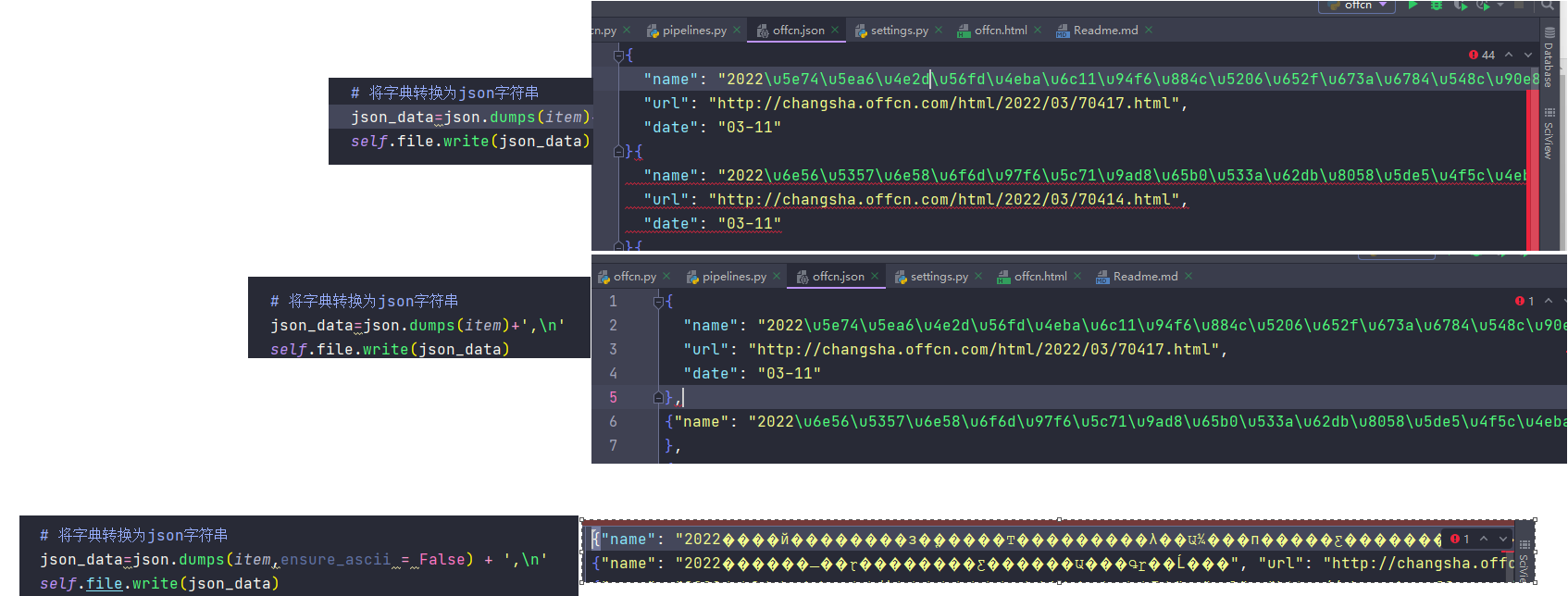
4.3 数据建模





4.4 翻页请求


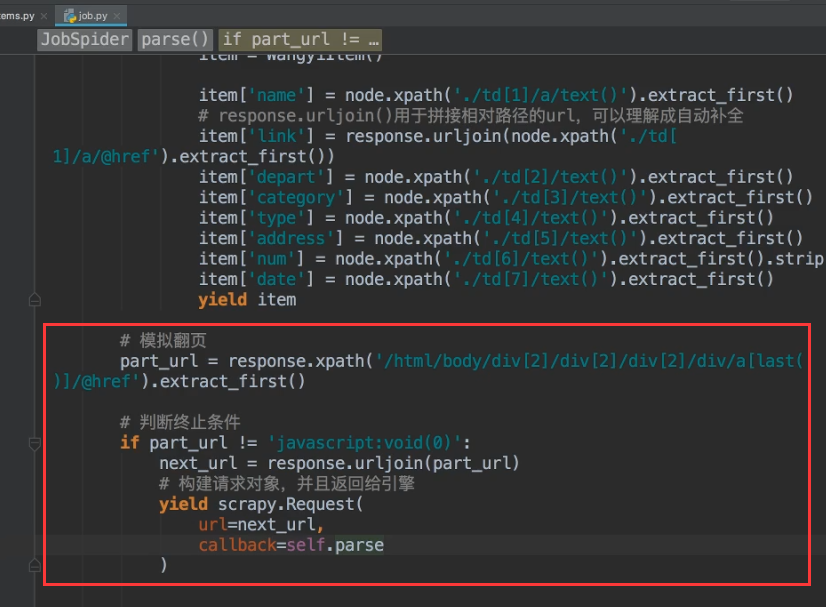
模拟翻页
找“下一页”的url
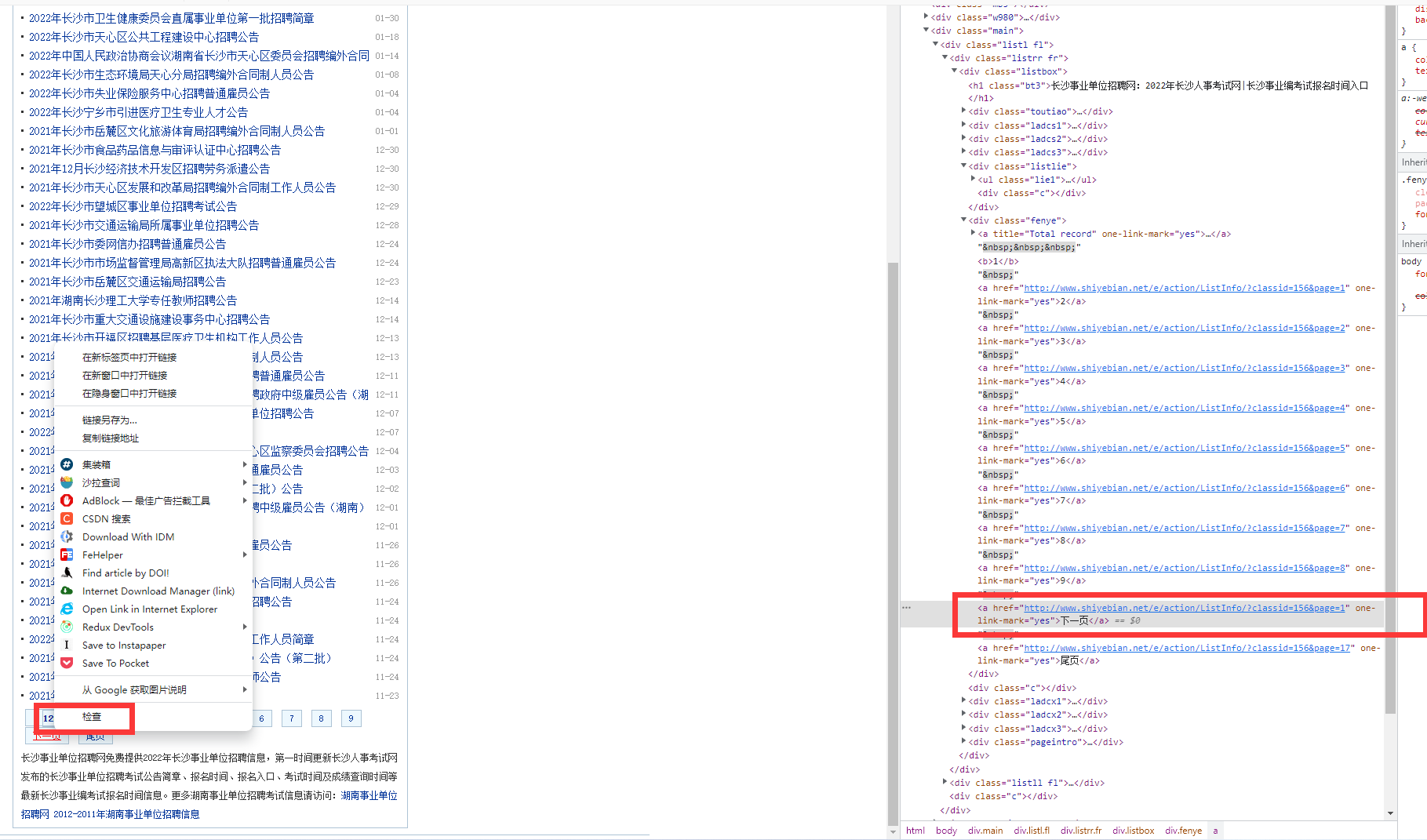
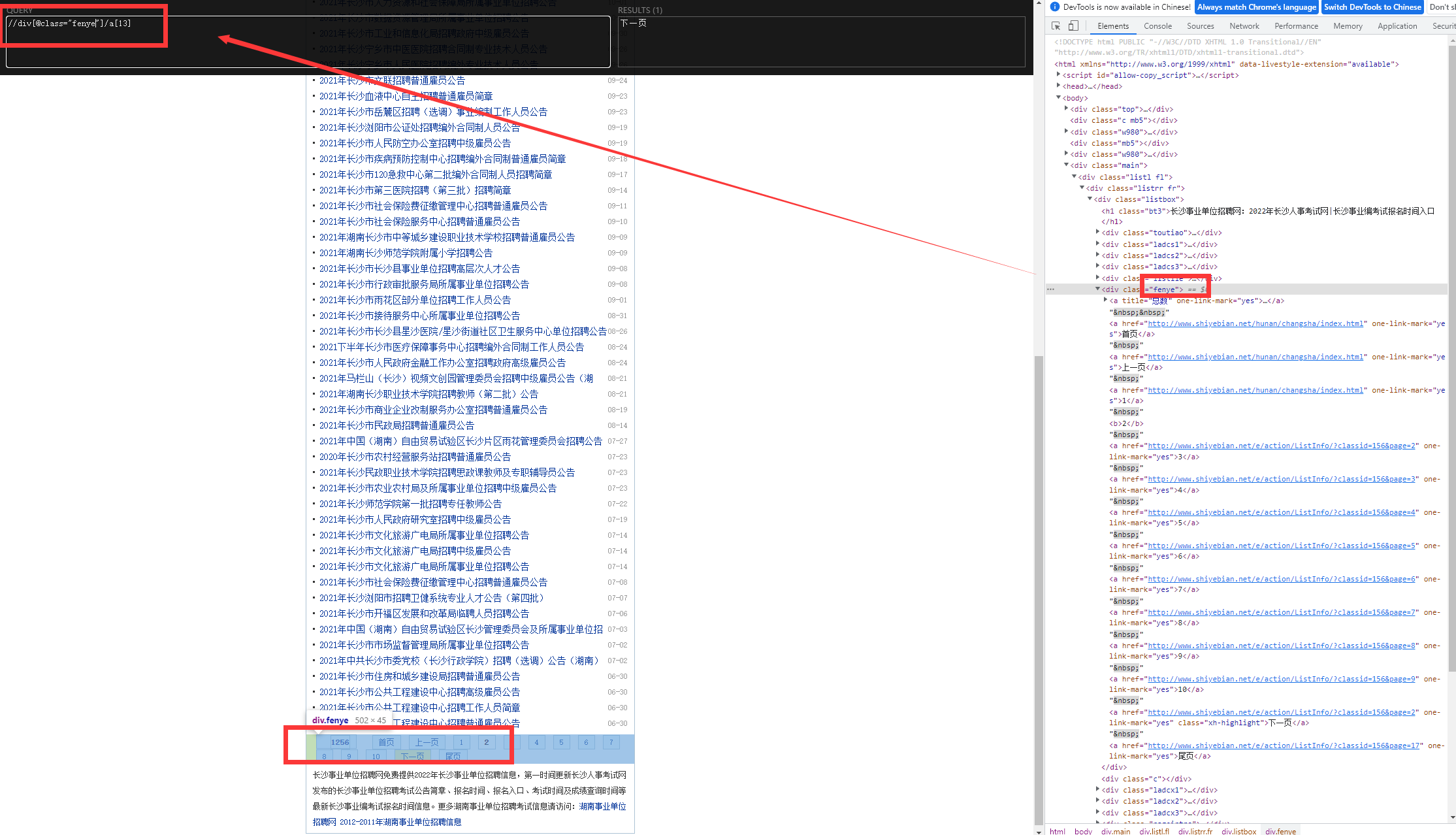
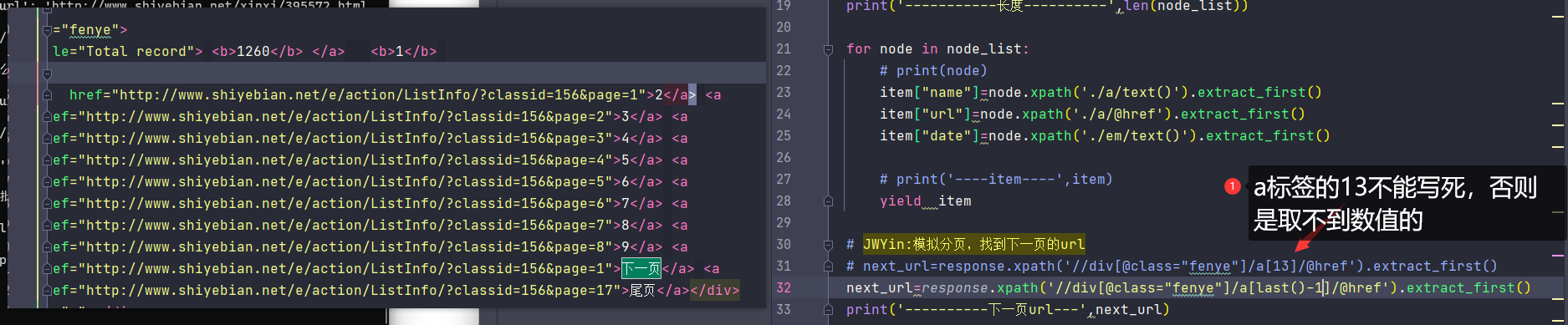
a标签的13不能写死,否则是取不到数值的
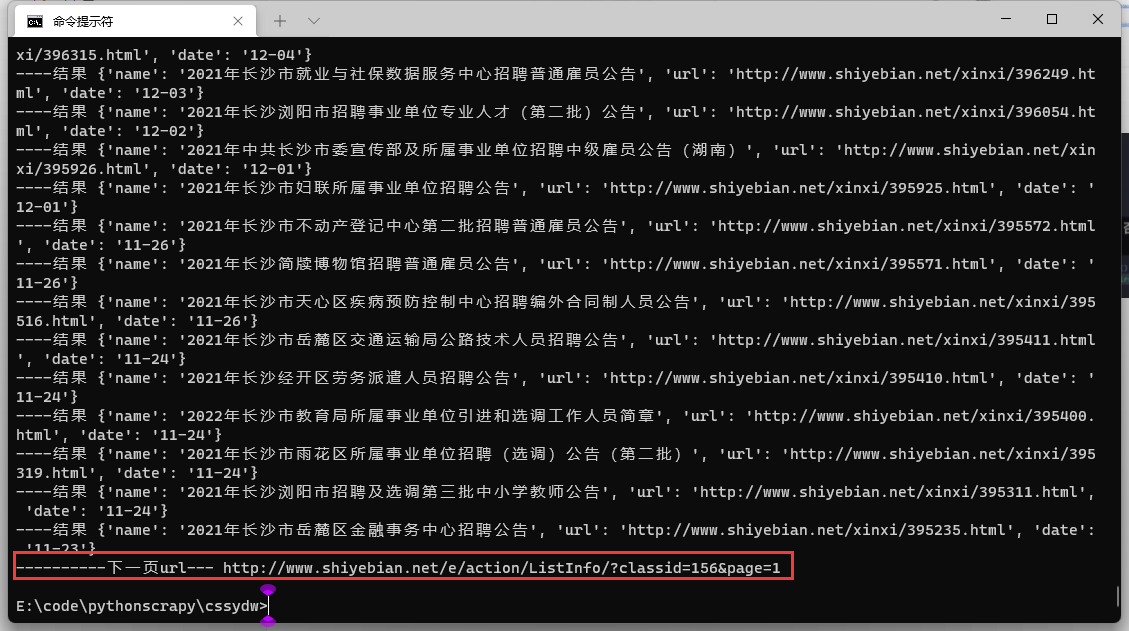
最终结果:
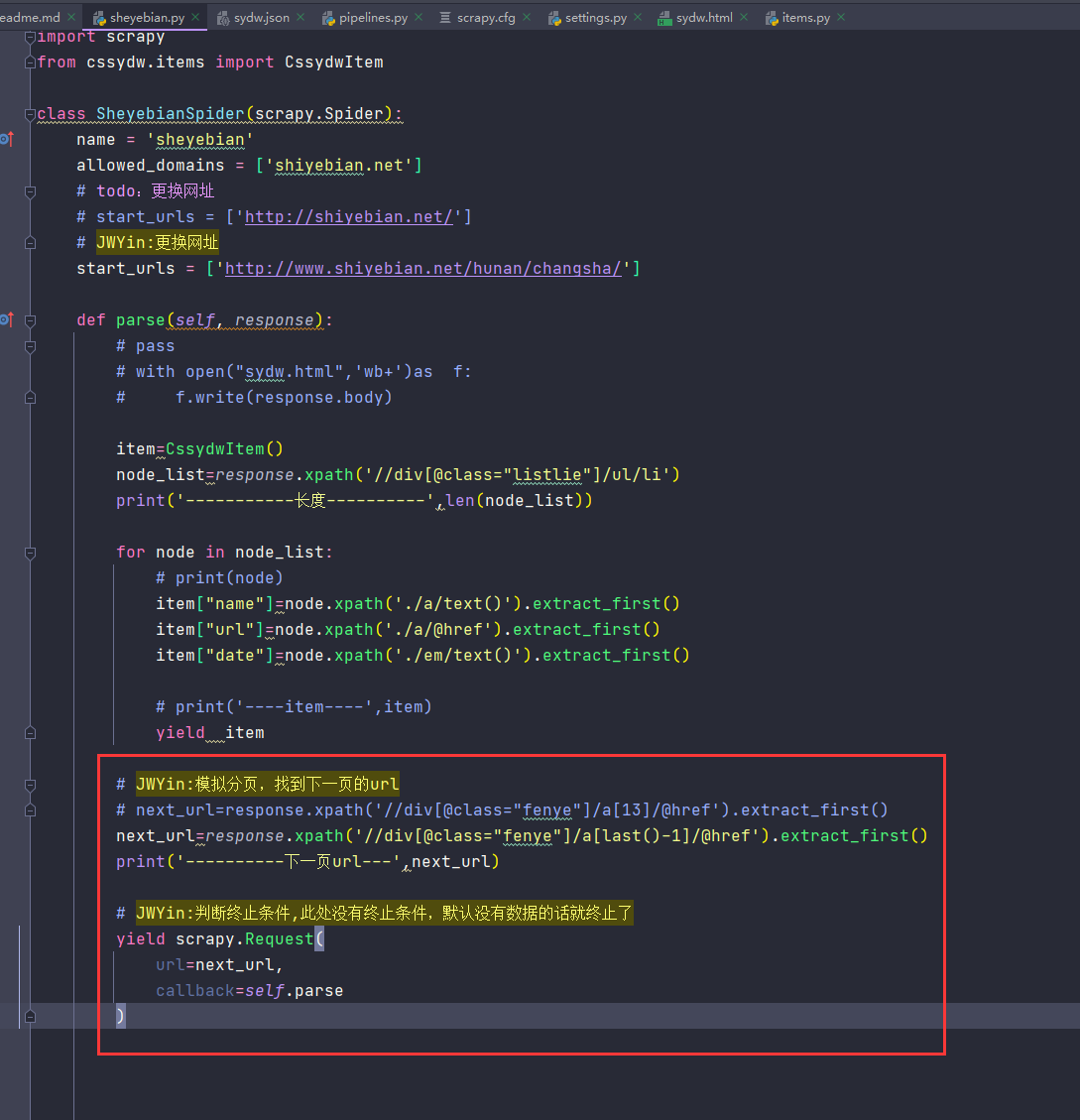
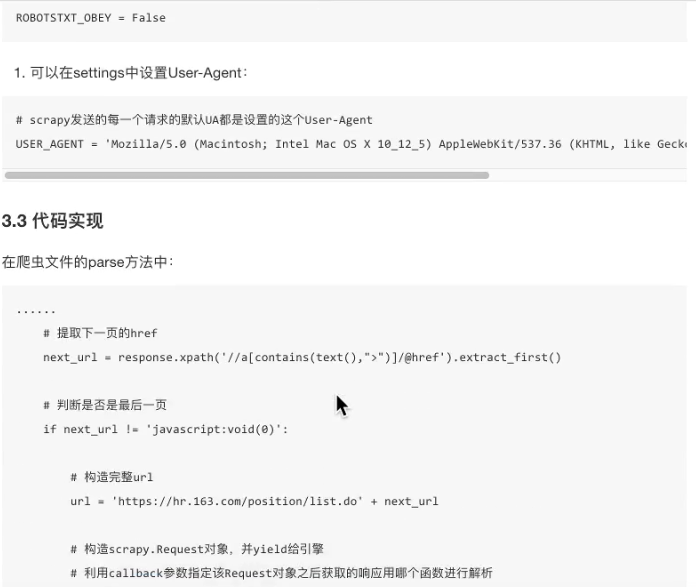
说明:首页跟翻页的url不一样也没有关系,这里获取到下一页的url之后直接进行替换了

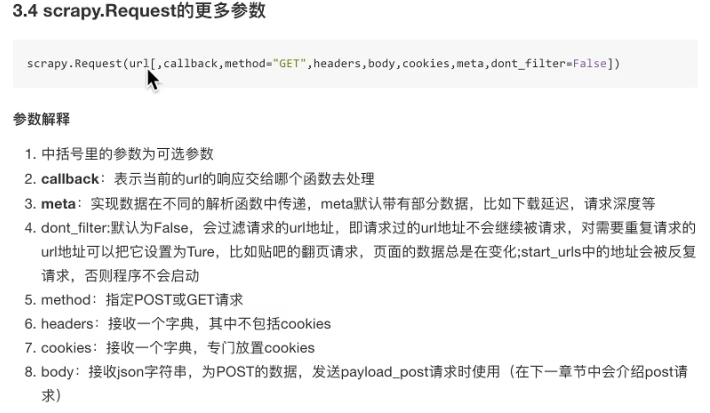
说明2:中括号的方法是可选的,如果Request不设置callback,那么就默认用parse方法解析
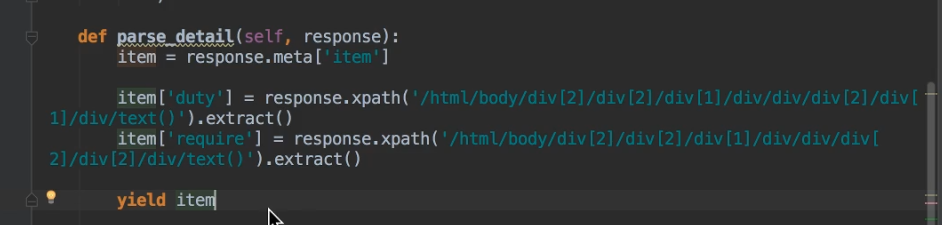
meta参数通常用于提取需要的详情页面

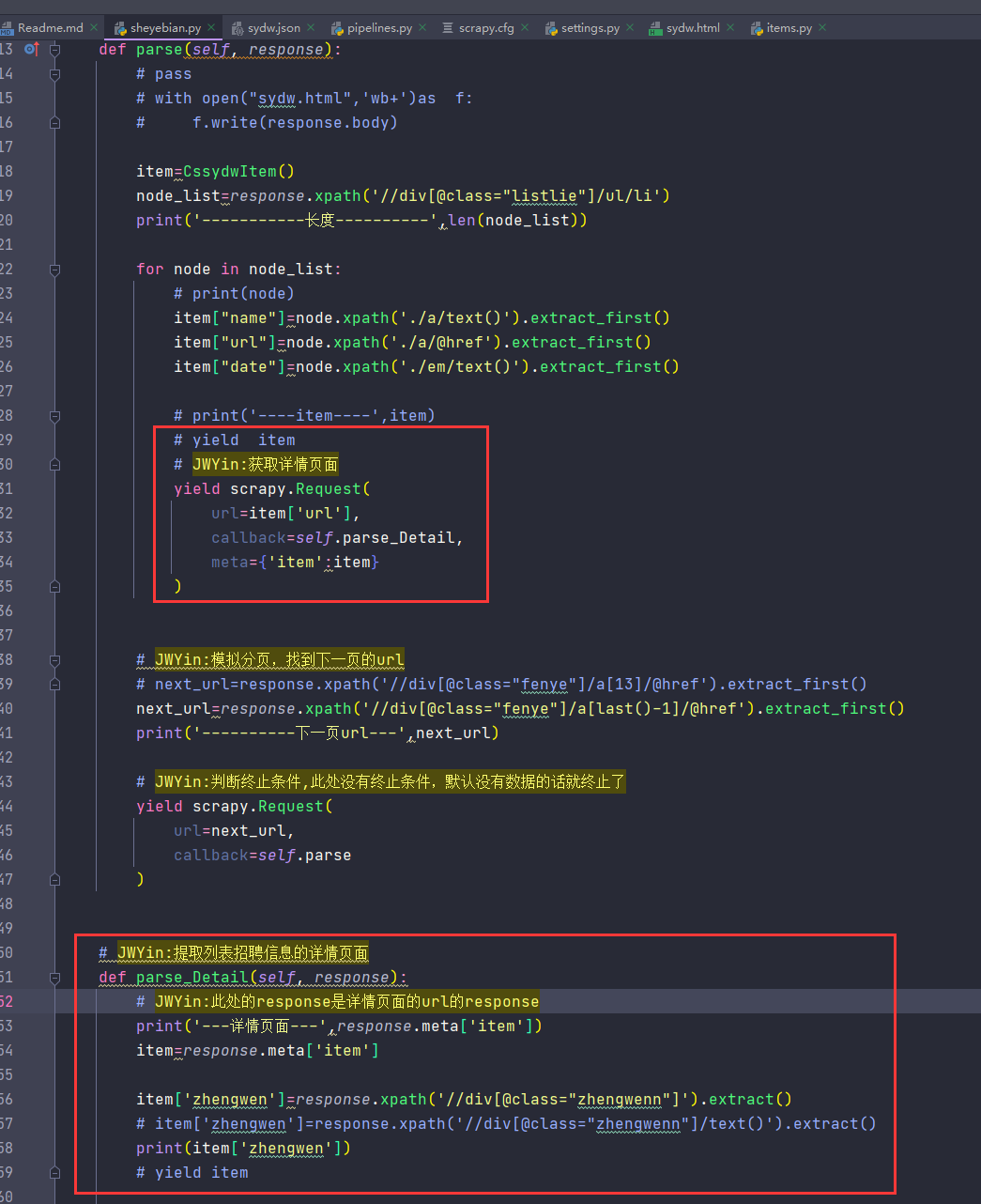 4.5 模拟登陆
4.5 模拟登陆




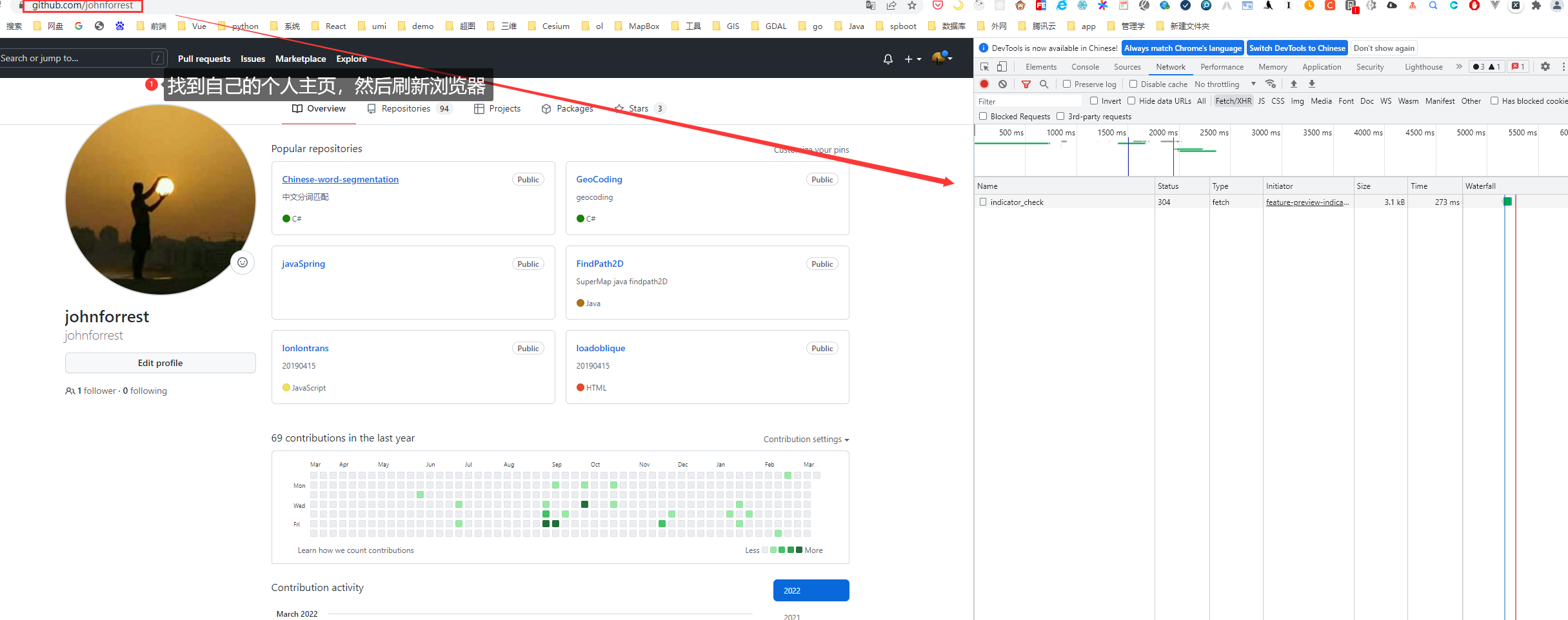
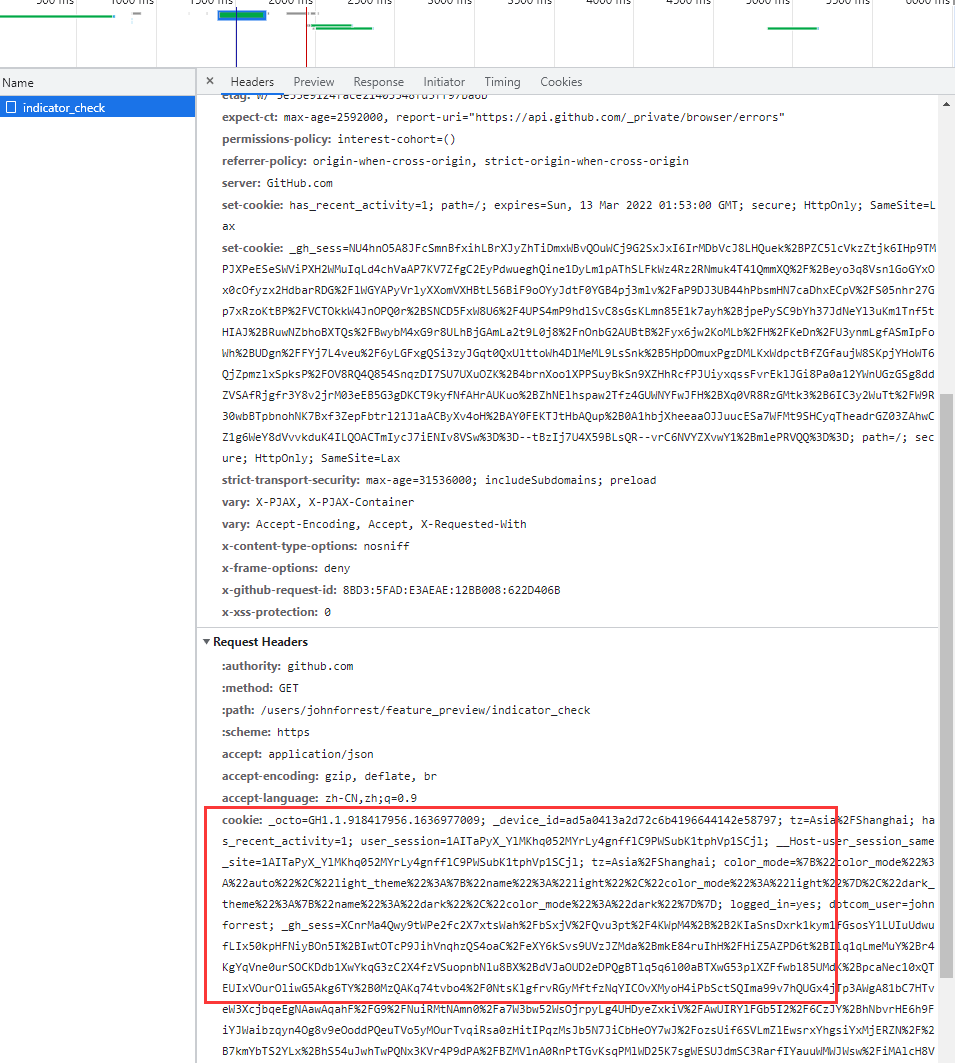
找到自己的个人主页,然后刷新浏览器,找到请求的cookies
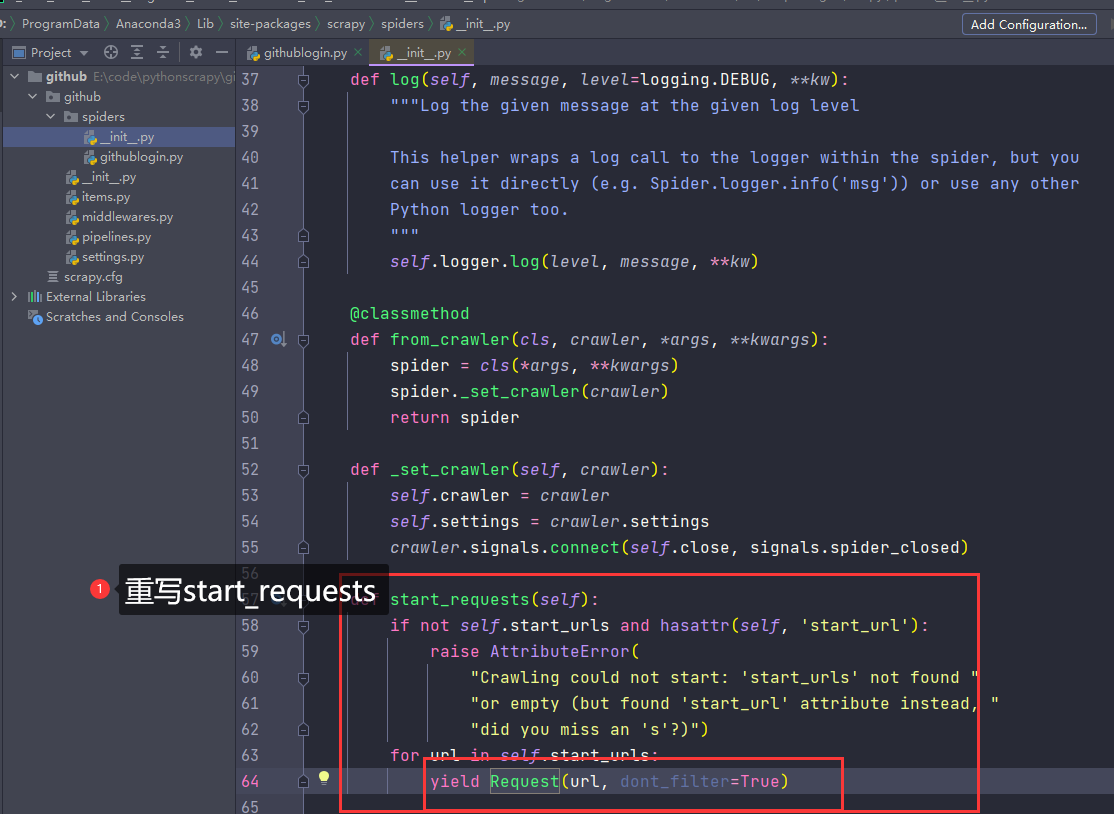
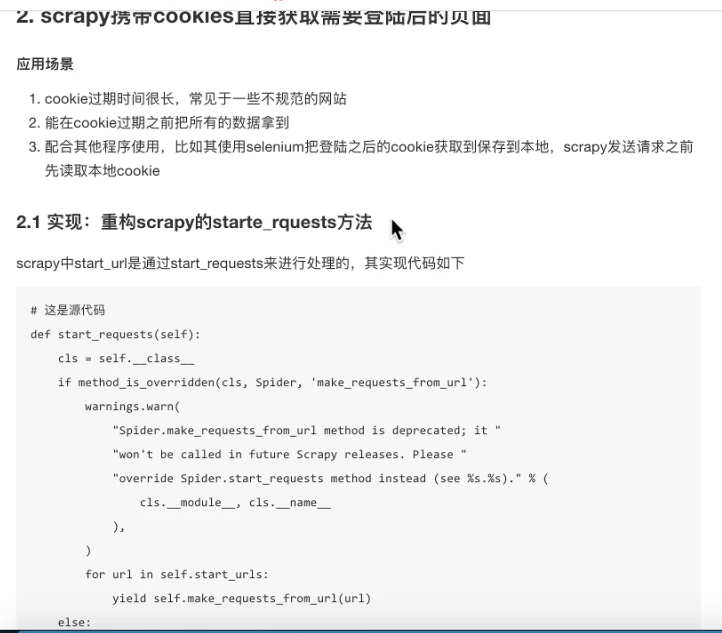
重写start_requests
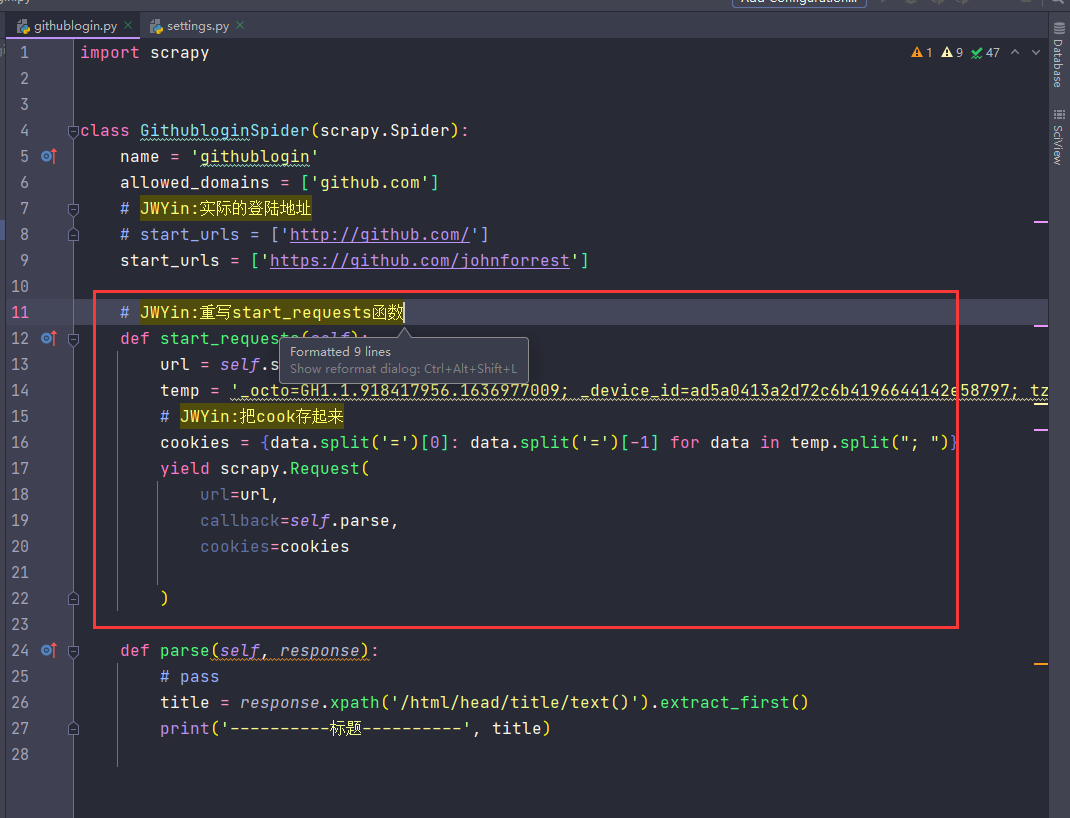
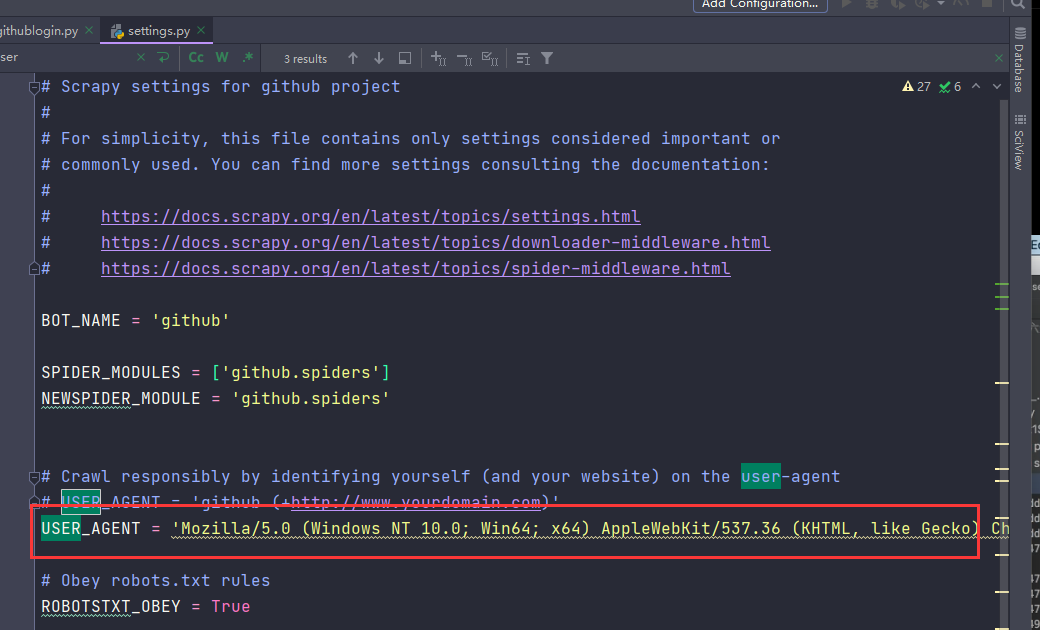
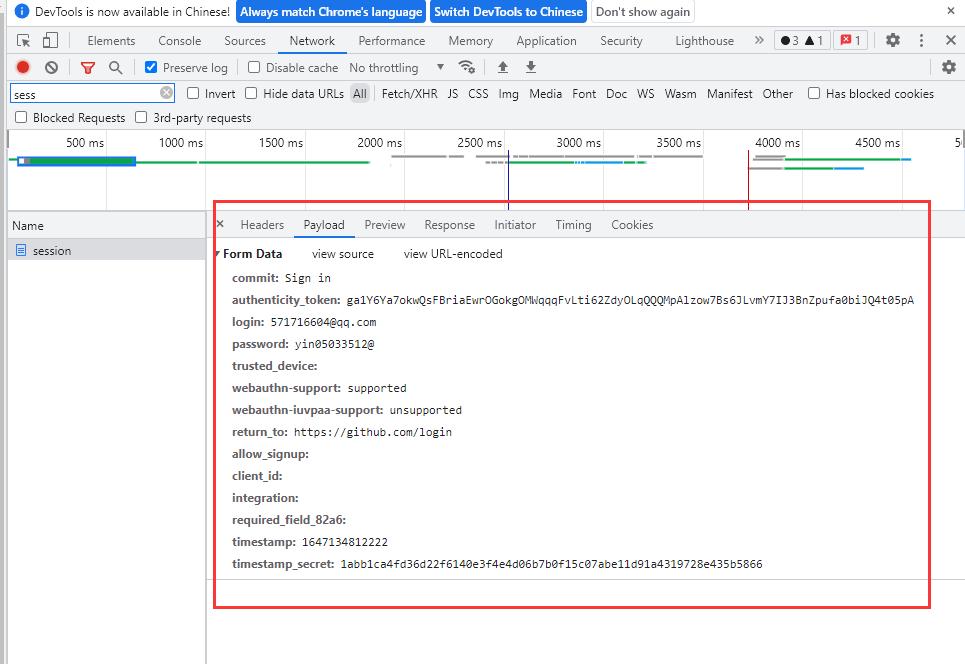
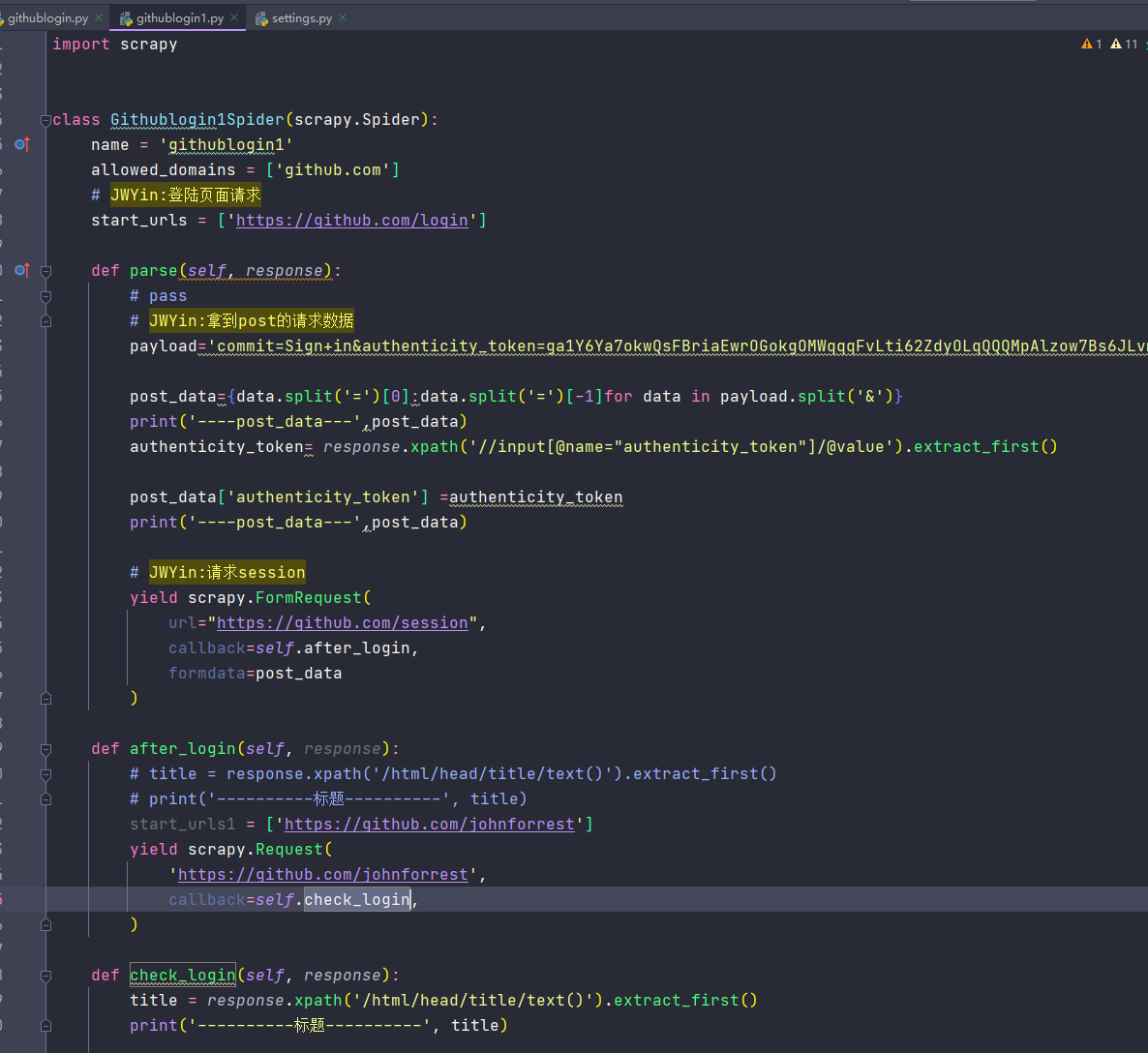
 发送post请求
发送post请求
方法1:

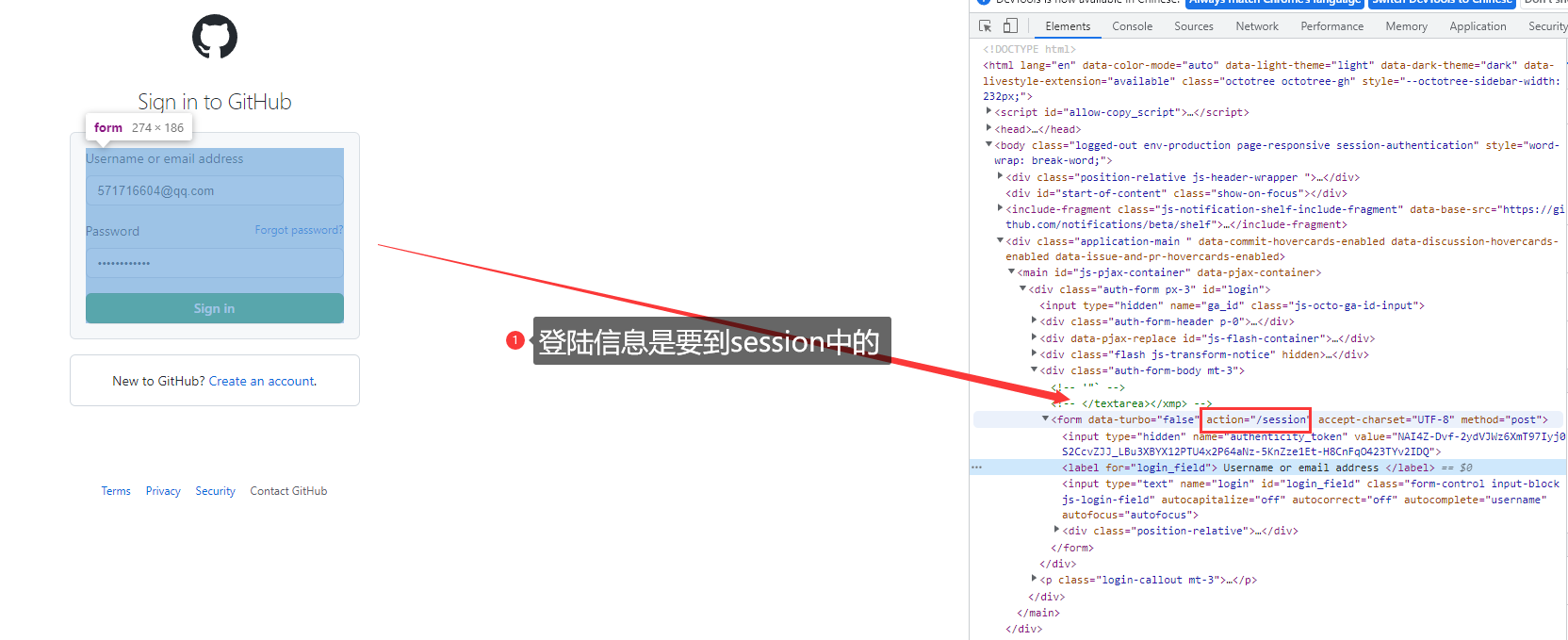
抓包
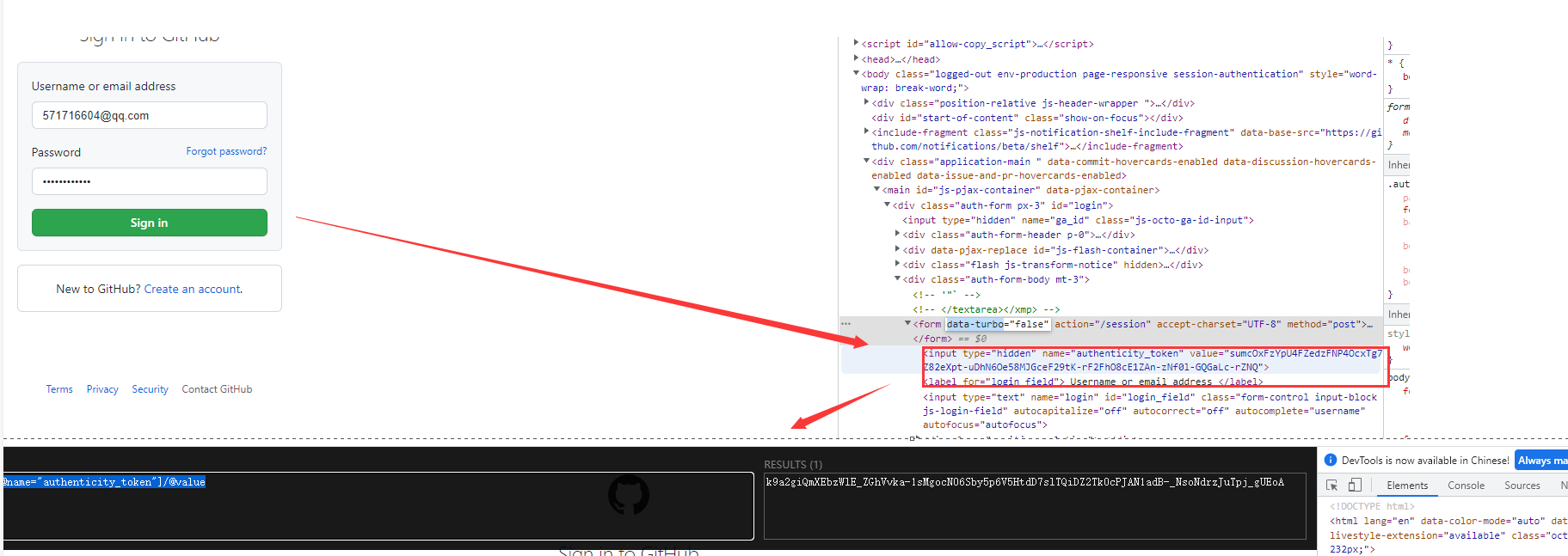


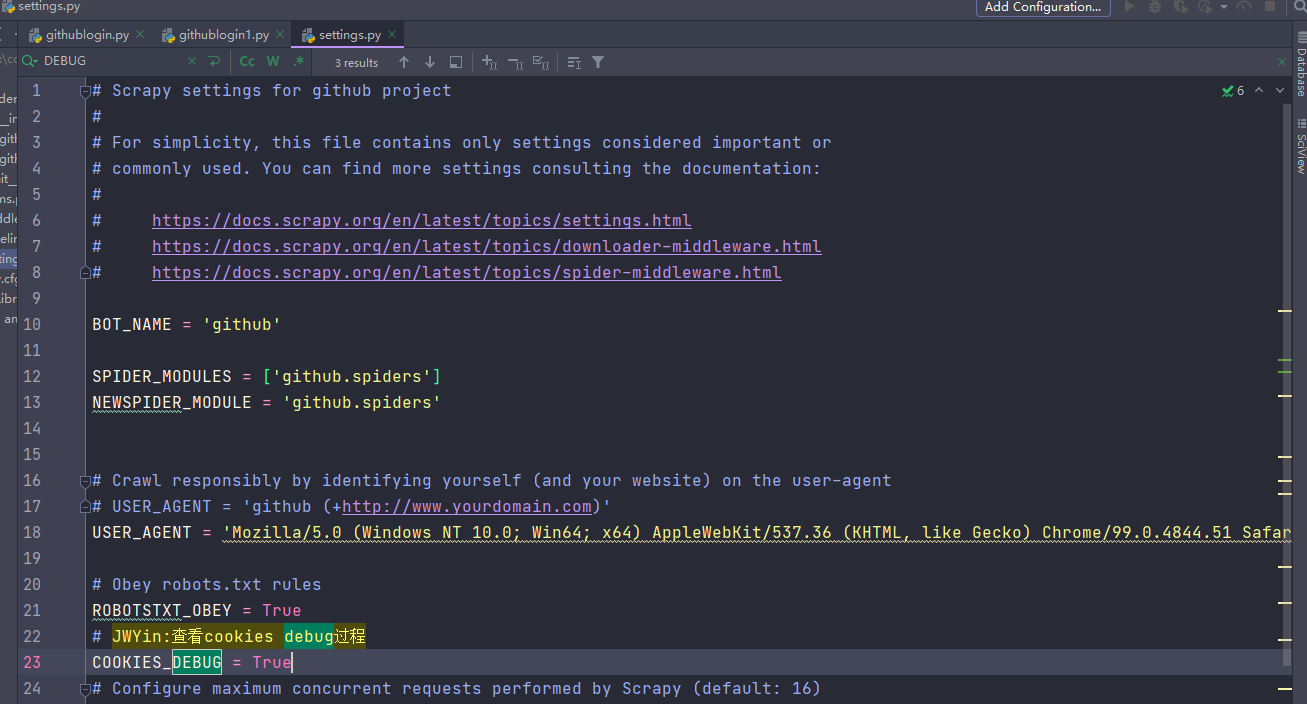
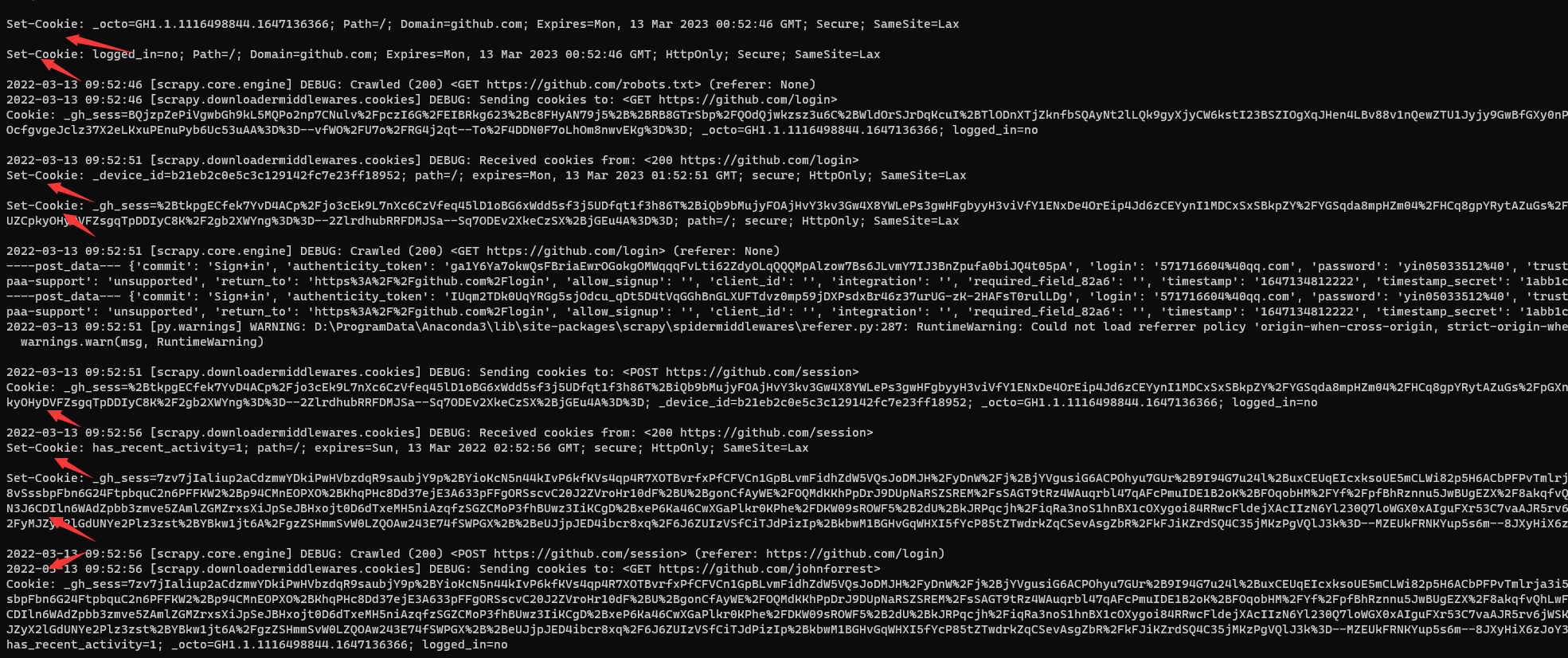
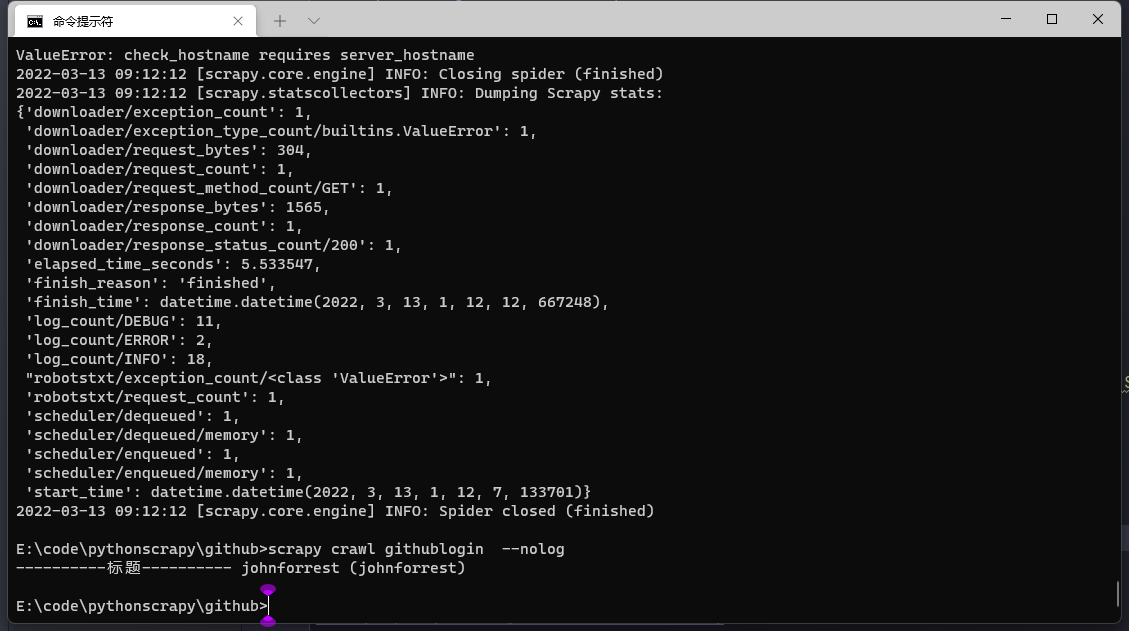
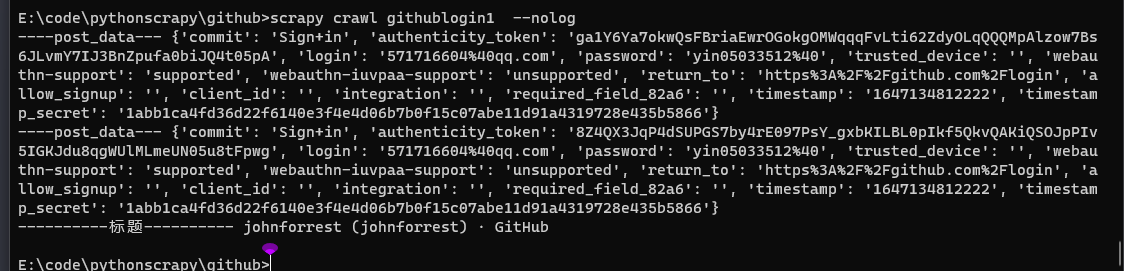
结果
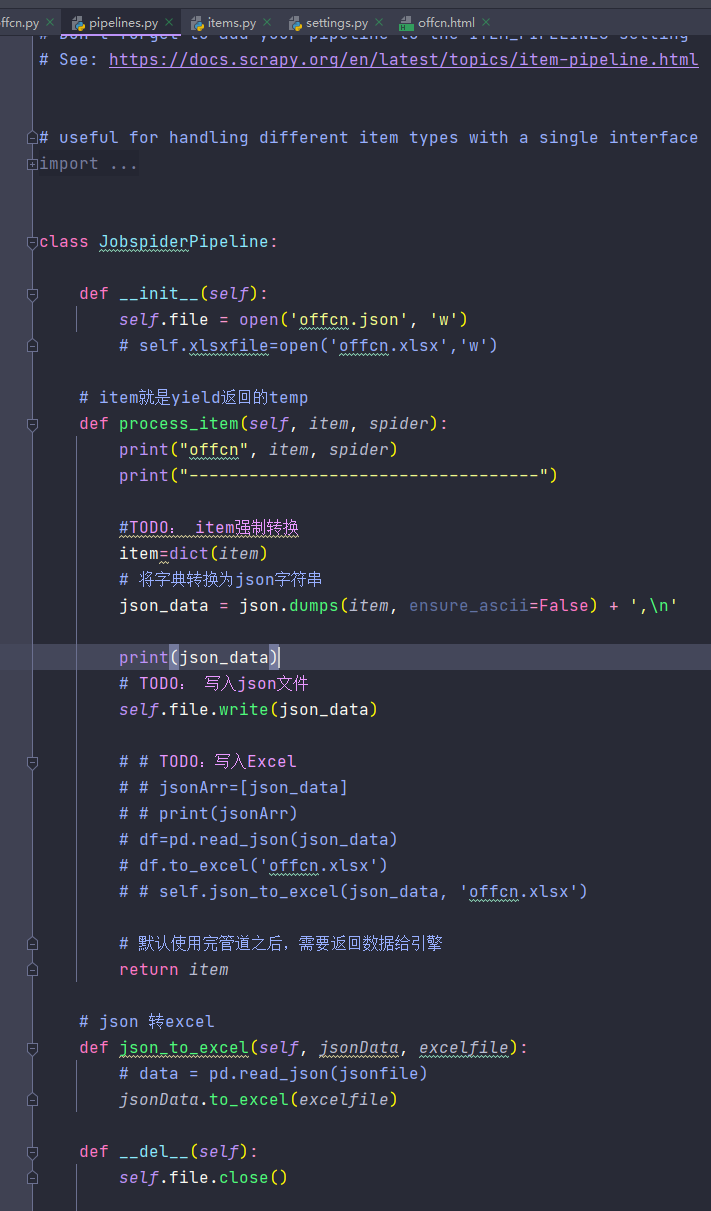
4.6 管道使用


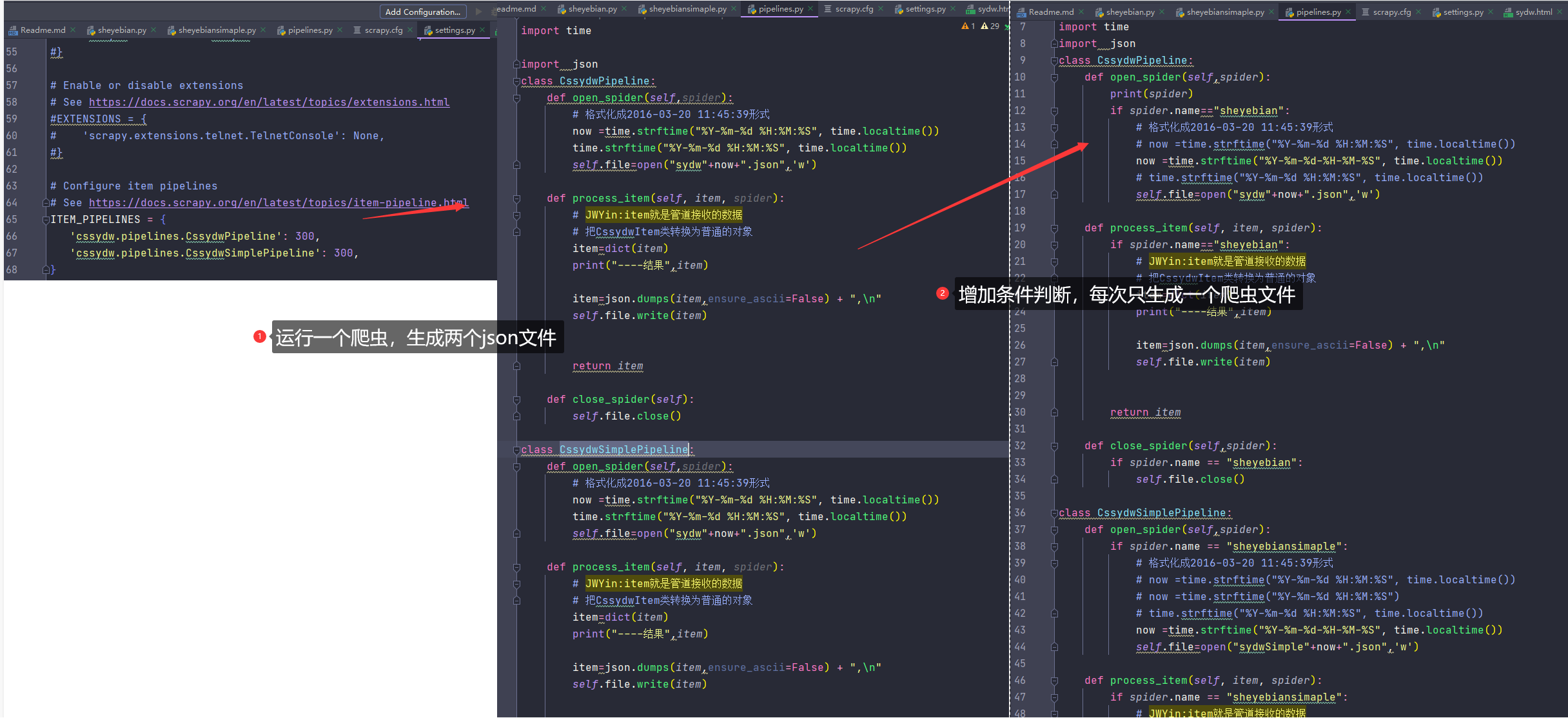
数据库管道:


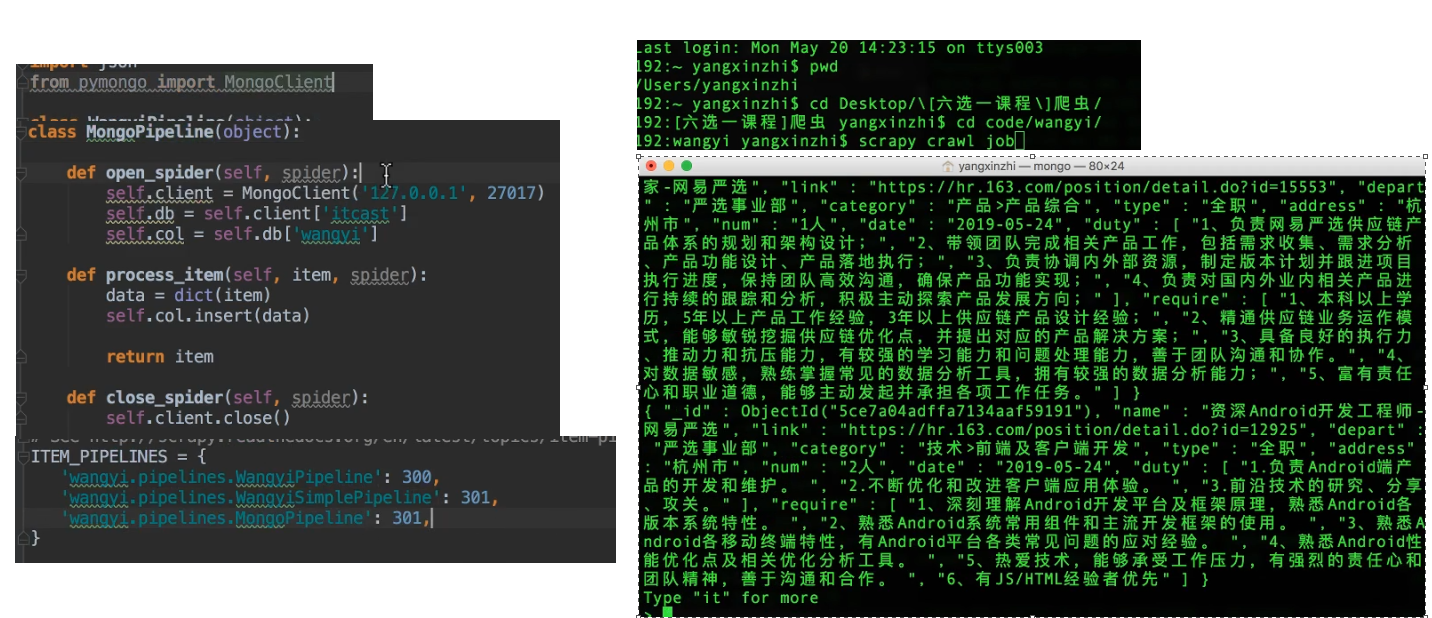

总结:

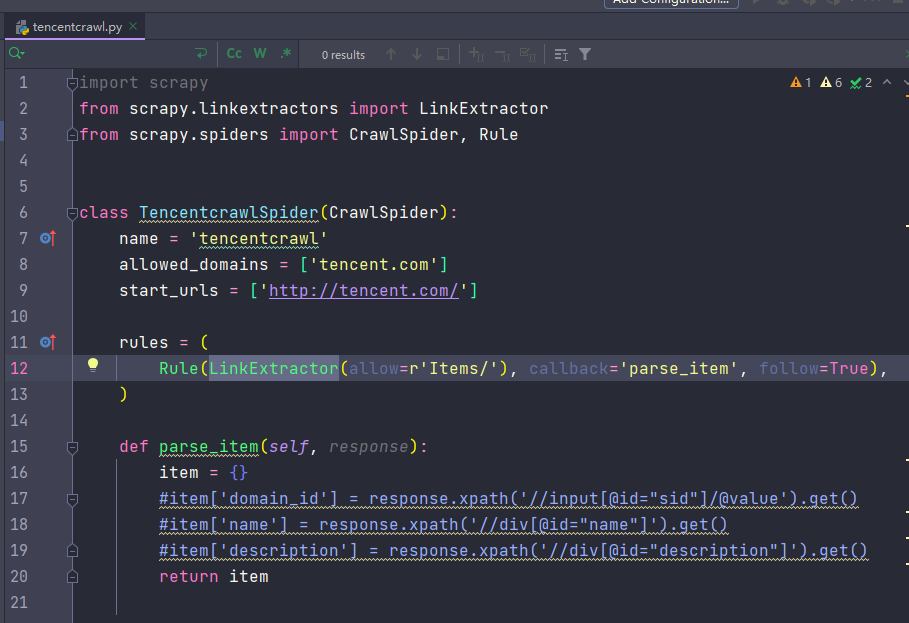
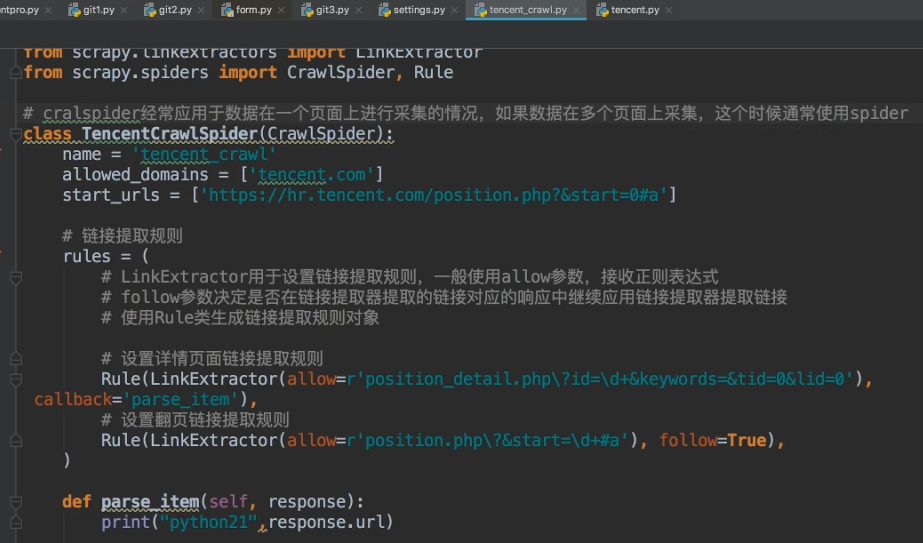
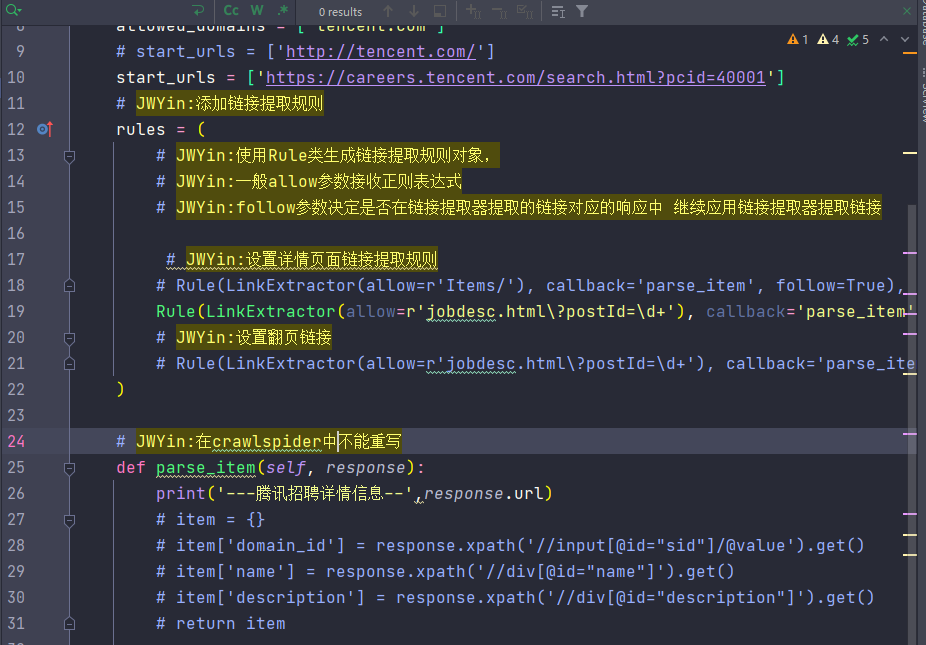
4.7 crawlspider



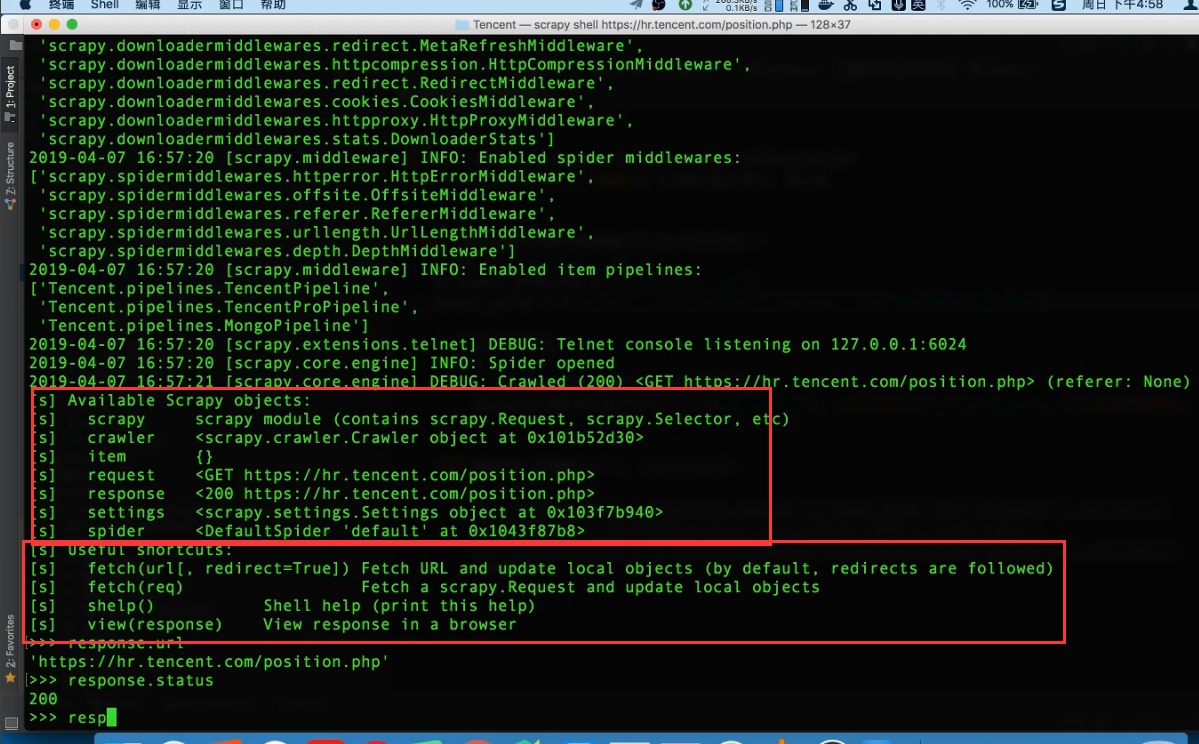
scrapy shell 链接
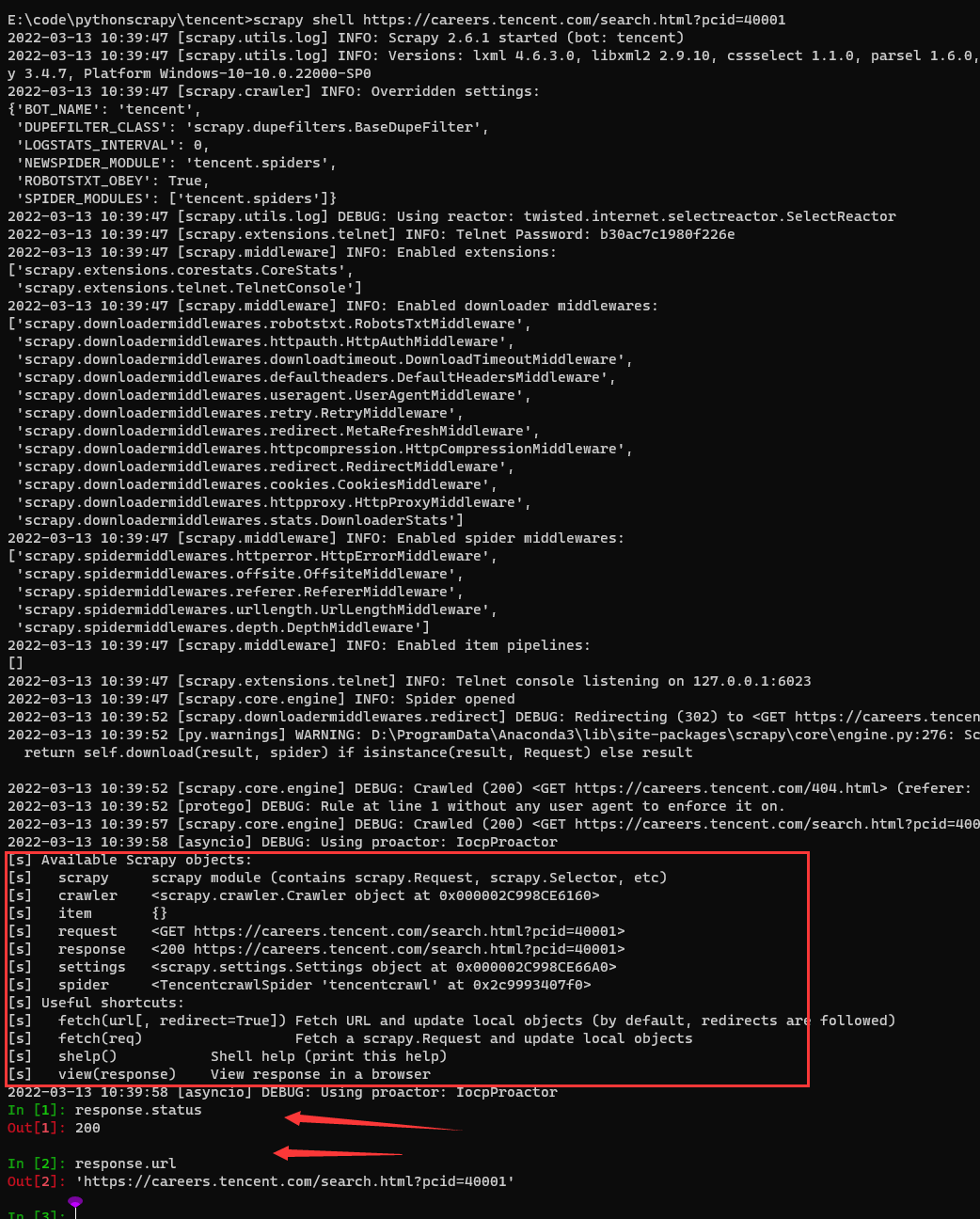
提取链接


4.8 中间件









若有收获,就点个赞吧
0 人点赞
