定义
前置知识
回一下我们之前,决策树小节,是否接受offer的决策树模型,如下图所示:
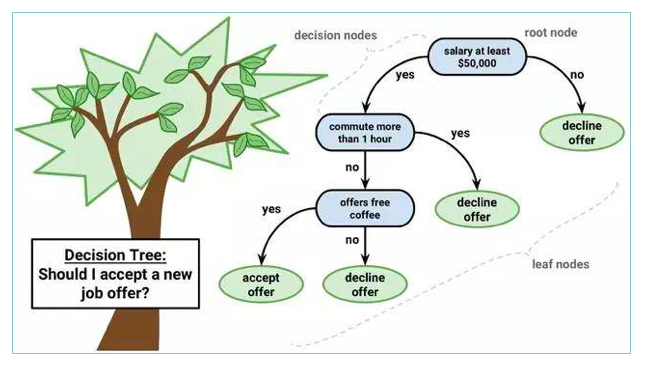
决策树是单个模型进行决策
学习随机森林之前,我们需要对决策树有一个基本的了解和掌握。
初步印象
随机森林是由多个决策树组成的,看下面我们放置了6个决策树模型
群体智慧:随机森林是多个决策树投票进行决策。
遵循少数服从多数的原则,通常来说群体的智慧是大于个人的智慧的,当然也存在特殊情况。
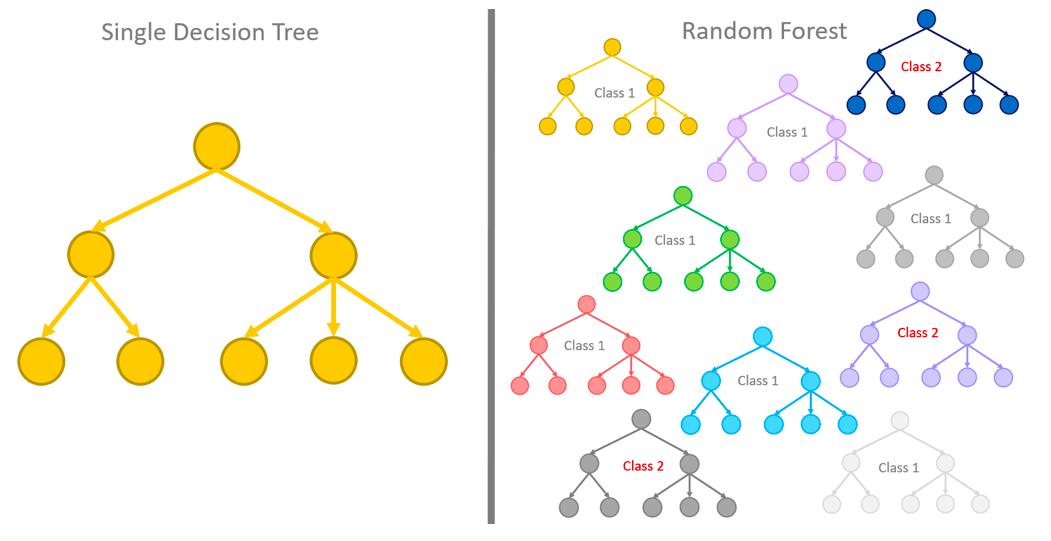
上面这个图就更加形象了,左侧是决策树,右侧是随机森林。
这里其实涉及到两个问题:
- 单一的决策树模型是怎么演变成多个决策树构成随机森林的?
- 有了随机森林,我们怎么评判某个样本最终的预测结果?
正式定义
随机森林是用于分类,回归和其他任务的集成学习方法,其通过在训练时构建多个决策树并输出作为类的模式(分类)或平均预测(回归)的类来操作。随机决策森林纠正决策树过度拟合其训练集的习惯。
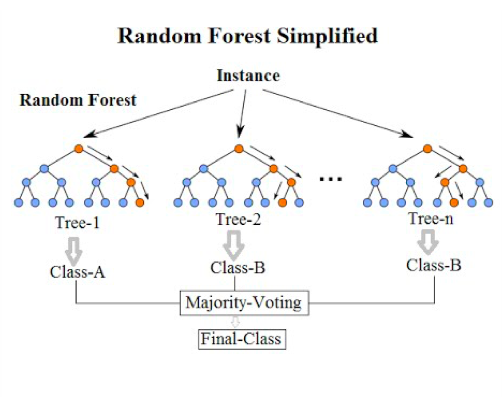
在上面的图中,每个Instance,(实例也就是某个样本),都可以输入到多个决策树,每个决策树都会产生一个结果,而最终随机森林输出的结果则取决于投票最多的那个类别。
现在我们来解答一下问题2:
如果是分类,则少数服从多数;如果是回归,则将每个决策树输出的结果求平均。(如上面定义所说)
原理
原理是很容易理解的,我们看下面的图示:
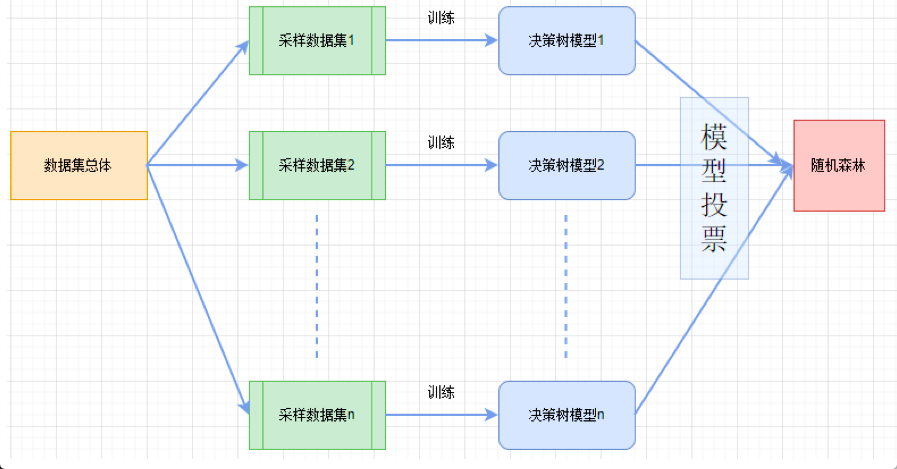
这里的采样有两个层面的含义:1,我们可以对样本进行有放回的随机采样;2,我们可以对特征进行随机的采样。
我们采集的数据集个数n,以及每个数据集内样本的个数,都是由我们自己控制的。
采集数据集是很关键的一步,正是由于样本和特征的随机采样,才保证了随机森林较高的正确性。
算法
算法是对上面原理部分的文字描述

随机抽样:如果我们抽样了全部的数据,那就没什么意义了
选取分裂点:这里的分裂点指的就是特征选取
组成森林:我们之前说过,分类就是少数服从多数;回归就是求平均值
分类还有一种情况:如果模型最终吐出的是某个类别的概率值,那我们可以计算加权平均值,看是更接近于哪个类别,从而决定最终结果。(逻辑斯蒂回归计算出的结果就是取某个类别的概率值)
OOB
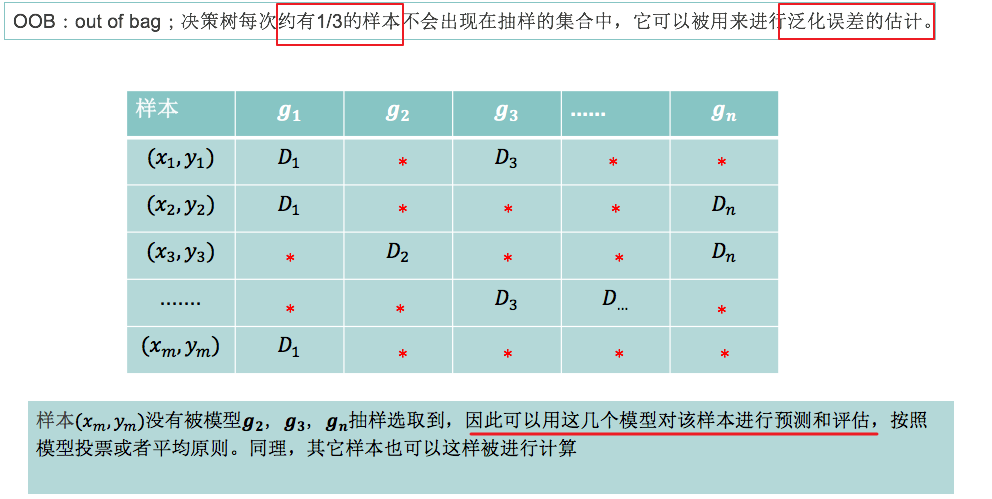
关键点解释:1/3的样本;这个是经过数学的严谨证明的,因为我们每次都是有放回的抽样,即便抽样许多次,每个样本被抽到的权重依旧不会改变。
关键点解释:泛化误差的估计;简单来说,它是用来评估模型效果的衡量指标,换句话说,OOB可以用来公平准确的衡量模型性能。
关键点解释:表格解释;第一行表示我们构建的n个决策树模型;第一列表示我们的m个样本x以及对应的预测值y;表格中的D就表示我们随机抽样的一个子数据集;表格中的红*号表示该样本(对应行上的)没有被该模型(对应列上的)随机采样到;
关键点解释:横线部分解释;也就是说,我们可以拿没有被模型学习的样本(充当测试集了)去预测和评估模型的效果
单颗树构建

这里之所以不会被剪枝,是因为众人拾柴火焰高,少数服从多数,最终的结果我们是看权重的;即便是其中一个决策树模型过拟合了,但不可能所有的决策树模型都是过拟合的,因此我们依旧可以保证较高的正确性
小结
- 随机样本随机特征的选取
- 未使用的样本可以被用来评估模型效果,即OOB

若有收获,就点个赞吧
0 人点赞
