- 1. 为什么使用Spring(优缺点)
- 2. spring容器创建对象的时机
- 3. Spring的常用注解解释
- 3. Spring MVC的常用注解解释
- 4. Mybatis的常用标签或者注解用过哪些
- 5. spring bean 的生命周期【~】
- 6. Spring事务(ACID,隔离级别,事务传播机制)
- 7. Spring事务的失效场景
- 8. IOC底层实现原理【~】
- 9. AOP底层实现原理【~】
- 10. AOP详解
- 11. Spring MVC 运行流程(好)
- 12. 什么是控制反转(Inversion of Control)与依赖注入(Dependency Injection)
- 13. BeanFactory和ApplicationContext区别
- 14. Mybatis中的#{}跟${}有什么区别。
- {}是占位符 , 预编译处理 , ${}是字符串替换
- 15. 从架构设计的角度,可以将 MyBatis 分为哪几层?每层都有哪些主要模块?
- 16. spring 常用的注入方式有哪些?
- 17. spring bean 的作用域
- 18. 说一下 spring 的事务隔离?
- 19. @RequestMapping @Autowired 的作用是什么?
- 20. 说一下 hibernate 的缓存机制?
- 21. 分页插件的实现原理是什么?MyBatis 逻辑分页和物理分页的区别是什么
- 22. 说一下 MyBatis 的一级缓存和二级缓存
- 23. MyBatists的resultType和resultmap的区别
- 24. MyBatis的好处?
- 25. MyBatis 与 Hibernate 的区别?
- 26. 使用 MyBatis 的 mapper 接口调用时有哪些要求
- 27. BeanFactory
- 28. ApplicationContext
- 29. SpringBoot常用注解
- 30. 谈谈你对SpringBoot的理解
- 31. 讲一下SpringBoot的四大核心功能
1. 为什么使用Spring(优缺点)
Spring有如下优点:
1.低侵入式设计,代码污染极低
2.独立于各种应用服务器,基于Spring框架的应用,可以真正实现Write Once,Run Anywhere的承诺
3.Spring的DI机制降低了业务对象替换的复杂性,提高了组件之间的解耦
4.Spring的AOP支持允许将一些通用任务如安全、事务、日志等进行集中式管理,从而提供了更好的复用
5.Spring的ORM和DAO提供了与第三方持久层框架的良好整合,并简化了底层的数据库访问
6.Spring并不强制应用完全依赖于Spring,开发者可自由选用Spring框架的部分或全部
Spring的缺点:
1.使用门槛升高,入门Spring需要较长时间;
2.对过时技术兼容,导致复杂度升高;
3.使用XML进行配置,但已不是流行配置方式;
4.集成第三方工具时候需要考虑兼容性;
5.系统启动慢,不具备热部署功能,完全依赖虚拟机或Web服务器的热部署。
2. spring容器创建对象的时机
spring容器创建对象的时机
1,在单例的情况下:
1.1 在默认的情况下,启动spring容器时创建对象
1.2 在spring的配置文件bean中有一个属性lazy-init=”default/true/false”
1)如果lazy-init为”default/false”在启动spring容器时创建对象
优点:可以在启动spring容器的时候,检查spring容器配置文件的正确性,及早地发现错误。如果再结合tomcat,如果spring容器不能正常启动,整个tomcat就不能正常启动。
缺点:把一些bean过早的放在了内存中,如果有数据,则对内存来是一个消耗
2)如果lazy-init为”true”,在context.getBean时才创建对象
优点:减少内存的消耗 缺点:不能及早地发现错误
2,在多例的情况下:
在context.getBean时才创建对象
[
](https://blog.csdn.net/wodewutai17quiet/article/details/48681607)
3. Spring的常用注解解释
- @Component :标准一个普通的spring Bean类。
- @Autowired:属于Spring 的org.springframework.beans.factory.annotation包下,可用于为类的属性、构造器、方法进行注值
- @PostConstruct 和 @PreDestroy 方法 实现初始化和销毁bean之前进行的操作
- @Configuration 声明当前类为配置类,相当于xml形式的Spring配置(类上)
- @Bean 注解在方法上,声明当前方法的返回值为一个bean,替代xml中的方式(方法上)
- @ComponentScan 用于对Component进行扫描,相当于xml中的(类上)
- @Aspect 声明一个切面(类上)
使用@After、@Before、@Around定义建言(advice),可直接将拦截规则(切点)作为参数。 - @After 在方法执行之后执行(方法上)
@Before 在方法执行之前执行(方法上)
@Around 在方法执行之前与之后执行(方法上) - @PointCut 声明切点
- @Scope 设置Spring容器如何新建Bean实例(方法上,得有@Bean)
其设置类型包括: - Singleton (单例,一个Spring容器中只有一个bean实例,默认模式),
Protetype (每次调用新建一个bean),
Request (web项目中,给每个http request新建一个bean),
Session (web项目中,给每个http session新建一个bean),
GlobalSession(给每一个 global http session新建一个Bean实例) - @StepScope 在Spring Batch中还有涉及
- @PostConstruct 由JSR-250提供,在构造函数执行完之后执行,等价于xml配置文件中bean的initMethod
- @PreDestory 由JSR-250提供,在Bean销毁之前执行,等价于xml配置文件中bean的destroyMethod
- @Value 为属性注入值(属性上)
[
](https://blog.csdn.net/u010648555/article/details/76299467)
3. Spring MVC的常用注解解释
- @EnableWebMvc 在配置类中开启Web MVC的配置支持,如一些ViewResolver或者MessageConverter等,若无此句,重写WebMvcConfigurerAdapter方法(用于对SpringMVC的配置)。
- @Controller 声明该类为SpringMVC中的Controller
- @RequestMapping 用于映射Web请求,包括访问路径和参数(类或方法上)
- @ResponseBody 支持将返回值放在response内,而不是一个页面,通常用户返回json数据(返回值旁或方法上)
- @RequestBody 允许request的参数在request体中,而不是在直接连接在地址后面。(放在参数前)
- @PathVariable 用于接收路径参数,比如@RequestMapping(“/hello/{name}”)申明的路径,将注解放在参数中前,即可获取该值,通常作为Restful的接口实现方法。
- @RestController 该注解为一个组合注解,相当于@Controller和@ResponseBody的组合,注解在类上,意味着,该Controller的所有方法都默认加上了@ResponseBody。
- @ControllerAdvice 通过该注解,我们可以将对于控制器的全局配置放置在同一个位置,注解了@Controller的类的方法可使用@ExceptionHandler、@InitBinder、@ModelAttribute注解到方法上,
这对所有注解了 @RequestMapping的控制器内的方法有效。 - @ExceptionHandler 用于全局处理控制器里的异常
- @InitBinder 用来设置WebDataBinder,WebDataBinder用来自动绑定前台请求参数到Model中。
- @ModelAttribute 本来的作用是绑定键值对到Model里,在@ControllerAdvice中是让全局的@RequestMapping都能获得在此处设置的键值对。
4. Mybatis的常用标签或者注解用过哪些
常用标签:
1.select:用于编写查询语句用的标签
2.resultMap:用于解决实体类中属性和表字段名不相同的问题
3.insert – 映射插入语句
4.update – 映射更新语句
5.delete – 映射删除语句
6.if
7.choose (when, otherwise)(类似于switch)
8.trim (where, set)
9.foreach
10.bind
常见注解:
@MapperScan
该注解主要是扫描某个包目录下的Mapper,将Mapper接口类交给Spring进行管理。
@Param
作为Dao层的注解,作用是用于传递参数,从而可以与SQL中的的字段名相对应。
@Autowired
顾名思义,就是自动装配,其作用是为了消除代码Java代码里面的getter/setter与bean属性中的property。
@Service
此注注解属于业务逻辑层,service或者manager层
默认按照名称进行装配,如果名称可以通过name属性指定,如果没有name属性,注解写在字段上时,默认去字段名进行查找,如果注解写在setter方法上,默认按照方法属性名称进行装配。当找不到匹配的bean时,才按照类型进行装配,如果name名称一旦指定就会按照名称进行装配.
5. spring bean 的生命周期【~】
Spring Bean的完整生命周期从创建Spring容器开始,直到最终Spring容器销毁Bean,这其中包含了一系列关键点。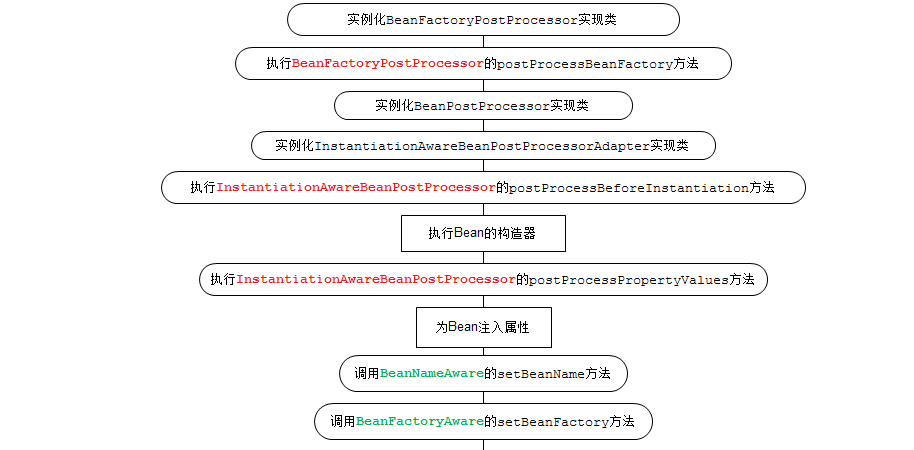

Spring生命周期大体就是4个,实例化->属性赋值->初始化->销毁。如果在面中被问到的化可以这样分为6点来回答:
实例化:Spring 容器根据配置中的 beanDefinition实例化bean。
属性赋值:Spring 使用依赖注入(构造器或者setter)填充所有属性,如 bean 中所定义的配置。
初始化之前: 如果存在bean实现的任何XXXBeanPostProcessors,则调用 postProcessBeforeInitialization() 方法。
初始化:如果为 bean 指定了 init 方法( 的 init-method 属性),那么将调用它,或者实现了InitializingBean接口,则调用postPropertiesSet()方法实现初始化逻辑。
初始化之后:如果存在与 bean 关联的任何 BeanPostProcessors,则将调用 postProcessAfterInitialization() 方法。
销毁:如果为 bean 指定了 destroy 方法( 的 destroy-method 属性),那么将调用它,或者实现了DisposableBean 接口,当 spring 容器关闭时,会调用 destory()。
6. Spring事务(ACID,隔离级别,事务传播机制)
事务的四大特性(ACID):
- 原子性:操作要么全成功,要么全失败回滚。
- 一致性:一致性是指事务必须使数据库从一个一致性状态变换到另一个一致性状态,也就是说一个事务执行之前和执行之后都必须处于一致性状态。
- 隔离性:事务之间互不干扰
- 持久性:事务一旦提交,数据的改变是永久性的。
Spring事务隔离级别 :
- TransactionDefinition.ISOLATION_DEFAULT(使用数据库默认级别)
- TransactionDefinition.ISOLATION_READ_UNCOMMITTED(读未提交)
- TransactionDefinition.ISOLATION_READ_COMMITTED(读提交)
- TransactionDefinition.ISOLATION_REPEATABLE_READ(可重复读)
- TransactionDefinition.ISOLATION_SERIALIZABLE(序列化)
Spring事务传播机制 :
- PROPAGATION_REQUIRED(默认) 若当前存在事务,则加入事务,若不存在事务,则新建事务。
- PROPAGATION_REQUIRE_NEW 无论当前有没有事务都会新建一个事务,新老事务独立。外部事务抛出异常不会影响内部事务正常提交。
- PROPAGATION_NESTED 如果当前存在事务,则嵌套(savepoint)在当前事务中执行。如果当前没有事务,则新建一个事务,类似REQUIRE_NEW。
- PROPAGATION_SUPPORTS支持当前事务,若当前不存在事务,以非事务的方式执行。
- PROPAGATION_NOT_SUPPORTED 以非事务的方式执行,若当前存在事务,则把当前事务挂起。
- PROPAGATION_NEVER 以非事务的方式执行,若当前存在事务则抛出异常。
- PROPAGATION_MANDATORY 强制事务执行,若当前不存在事务则抛出异常。
7. Spring事务的失效场景
@Transactional失效场景:
- 底层数据库引擎不支持事务
- 非public修饰的方法使用(因为是AOP,动态代理只能真的public方法)
- 异常被内部捕获(try-catch)
- 方法内部调用同类方法(因为是AOP,直接调用内部方法并非是代理类调用)
- 解决方案:AopContext.currentProxy()获取代理,需要配置@EnableAspectJAutoProxy(exposeProxy = true)
- rollbackFor属性设置错误
- noRollbackFor属性设置错误
- propagation属性设置错误
[
](https://blog.csdn.net/weixin_42573367/article/details/118086273)
8. IOC底层实现原理【~】
实现IOC的两种方式
- 底层实现使用的技术
1.1 xml配置文件
1.2 dom4j解析xml
1.3 工厂模式
1.4 反射
容器如何创建对象
IOC容器在准备创建对象时, 会判断是否有配置 factory-method方法
如果有配置 会调用factory-method所指向的方法构建对象.
如果没配置,会检查是否有配置构造参数
无构造参数: 调用默认构造器创建对象
有构造参数: 根据参数情况匹配对应的构造器
9. AOP底层实现原理【~】
AOP(Aspect Oriented Programming),即面向切面编程,可以说是OOP(Object Oriented Programming,面向对象编程)的补充和完善。OOP引入封装、继承、多态等概念来建立一种对象层次结构,用于模拟公共行为的一个集合。不过OOP允许开发者定义纵向的关系,但并不适合定义横向的关系,例如日志功能。日志代码往往横向地散布在所有对象层次中,而与它对应的对象的核心功能毫无关系对于其他类型的代码,如安全性、异常处理和透明的持续性也都是如此,这种散布在各处的无关的代码被称为横切(cross cutting),在OOP设计中,它导致了大量代码的重复,而不利于各个模块的重用。
AOP技术恰恰相反,它利用一种称为”横切”的技术,剖解开封装的对象内部,并将那些影响了多个类的公共行为封装到一个可重用模块,并将其命名为”Aspect”,即切面。所谓”切面”,简单说就是那些与业务无关,却为业务模块所共同调用的逻辑或责任封装起来,便于减少系统的重复代码,降低模块之间的耦合度,并有利于未来的可操作性和可维护性。
使用”横切”技术,AOP把软件系统分为两个部分:核心关注点和横切关注点。业务处理的主要流程是核心关注点,与之关系不大的部分是横切关注点。横切关注点的一个特点是,他们经常发生在核心关注点的多处,而各处基本相似,比如权限认证、日志、事物。AOP的作用在于分离系统中的各种关注点,将核心关注点和横切关注点分离开来。
10. AOP详解
AOP核心概念
1、横切关注点
对哪些方法进行拦截,拦截后怎么处理,这些关注点称之为横切关注点
2、切面(aspect)
类是对物体特征的抽象,切面就是对横切关注点的抽象
3、连接点(joinpoint)
被拦截到的点,因为Spring只支持方法类型的连接点,所以在Spring中连接点指的就是被拦截到的方法,实际上连接点还可以是字段或者构造器
4、切入点(pointcut)
对连接点进行拦截的定义
5、通知(advice)
所谓通知指的就是指拦截到连接点之后要执行的代码,通知分为前置、后置、异常、最终、环绕通知五类
6、目标对象
代理的目标对象
7、织入(weave)
将切面应用到目标对象并导致代理对象创建的过程
8、引入(introduction)
在不修改代码的前提下,引入可以在运行期为类动态地添加一些方法或字段
Spring对AOP的支持
Spring中AOP代理由Spring的IOC容器负责生成、管理,其依赖关系也由IOC容器负责管理。因此,AOP代理可以直接使用容器中的其它bean实例作为目标,这种关系可由IOC容器的依赖注入提供。Spring创建代理的规则为:
1、默认使用Java动态代理来创建AOP代理,这样就可以为任何接口实例创建代理了
2、当需要代理的类不是代理接口的时候,Spring会切换为使用CGLIB代理,也可强制使用CGLIB
AOP编程其实是很简单的事情,纵观AOP编程,程序员只需要参与三个部分:
1、定义普通业务组件
2、定义切入点,一个切入点可能横切多个业务组件
3、定义增强处理,增强处理就是在AOP框架为普通业务组件织入的处理动作
所以进行AOP编程的关键就是定义切入点和定义增强处理,一旦定义了合适的切入点和增强处理,AOP框架将自动生成AOP代理,即:代理对象的方法=增强处理+被代理对象的方法。
11. Spring MVC 运行流程(好)
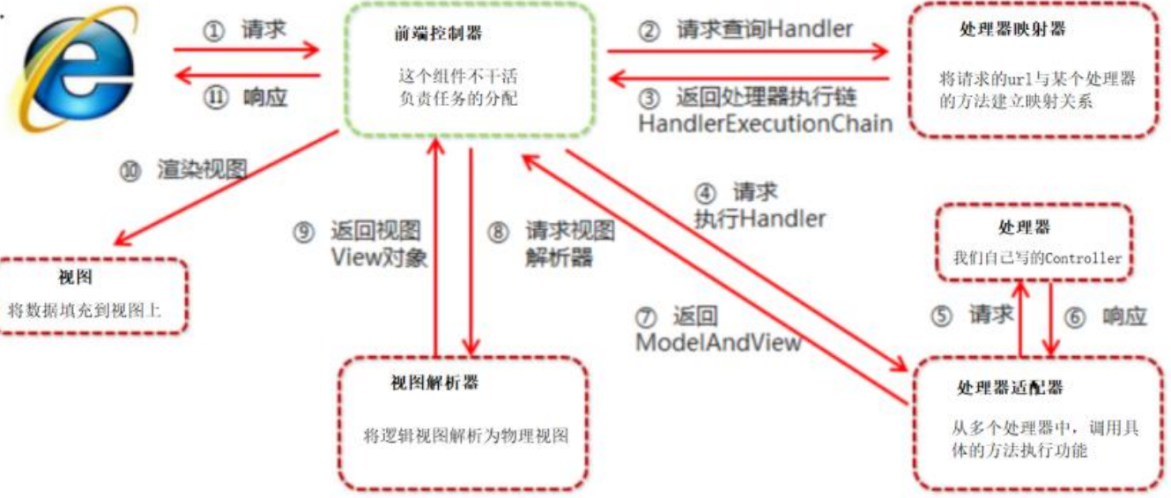
- 用户发送请求到前端控制器(DispatcherServlet)
- 前 端 控 制 器 ( DispatcherServlet ) 收 到 请 求 调 用 处 理 器 映 射 器 (HandlerMapping),去查找处理器(Handler)
- 处理器映射器(HandlerMapping)找到具体的处理器(可以根据 xml 配置、注解进行 查找),生成处理器对象及处理器拦截器(如果有则生成)一并返回给 DispatcherServlet。
- 前端控制器(DispatcherServlet)调用处理器映射器(HandlerMapping)
- 处理器适配器(HandlerAdapter)去调用自定义的处理器类(Controller,也叫 后端控制器)。
- 自定义的处理器类(Controller,也叫后端控制器)将得到的参数进行处理并返回结 果给处理器映射器(HandlerMapping)
- 处 理 器 适 配 器 ( HandlerAdapter ) 将 得 到 的 结 果 返 回 给 前 端 控 制 (DispatcherServlet)
- DispatcherServlet( 前 端 控 制 器 ) 将 ModelAndView 传 给 视 图 解 析 器
(ViewReslover) - 视图解析器(ViewReslover)将得到的参数从逻辑视图转换为物理视图并返回给
前端控制器(DispatcherServlet) - 前端控制器(DispatcherServlet)调用物理视图进行渲染并返回
- 前端控制器(DispatcherServlet)将渲染后的结果返回
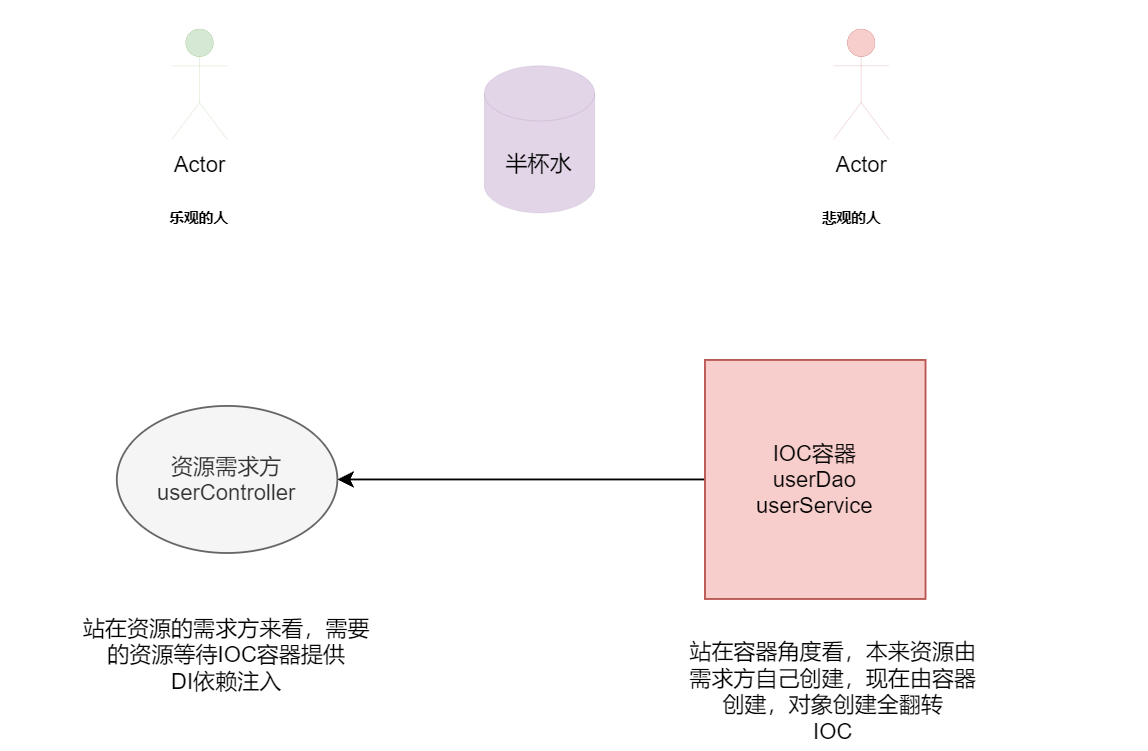
12. 什么是控制反转(Inversion of Control)与依赖注入(Dependency Injection)
1.控制反转(Inversion of Control)与依赖注入(Dependency Injection)
控制反转即IOC(Inversion of Control),它把传统上由程序代码直接操控的对象的调用权交给容器,通过容器来实现对象组件的装配和管理。所谓的“控制反转”概念就是对组件对象控制权的转移,从程序代码本身转移到了外部容器。
IoC是一个很大的概念,可以用不同的方式来实现。其主要实现方式有两种:<1>依赖查找(Dependency Lookup): 容器提供回调接口和上下文环境给 组件。EJB和Apache Avalon都使用这种方式。<2>依赖注入(Dependency Injection):组件不做定位查询,只提供普通的Java方法让容器去决定依赖关系。后者是时下最流行的IoC类型,其又有接口注入(Interface Injection),设值注入(Setter Injection)和构造子注入(Constructor Injection)三种方式。
依赖注入之所以更流行是因为它是一种更可取的方式:让容器全权负责依赖查询,受管组件只需要暴露JavaBean的setter方法或者带参数的构造子或者接口,使容器可以在初始化时组装 对象的依赖关系。其与依赖查找方式相比,主要优势为:<1>查找定位操作与应用代码完全无关。<2>不依赖于容器的API,可以很容易地在任何容器以外使用应用对象。<3>不需要特殊的接口,绝大多数对象可以做到完全不必依赖容器。
13. BeanFactory和ApplicationContext区别
BeanFactory:
- Spring最顶层接口, 实现了spring容器的最基础的一些功能 , 调用起来比较麻烦 , 一般面向spring自身使用
- BeanFactory在启动的时候不会去实例化Bean , 从容器中拿Bean的时候才会去实例化
ApplicationContext:
- 是BeanFactory的子接口 , 扩展了其功能 , 一般面向程序员使用
- ApplicationContext在启动的时候就把所有的Bean全部实例化了
14. Mybatis中的#{}跟${}有什么区别。
{}是占位符 , 预编译处理 , ${}是字符串替换
- MyBatis在处理#{}时,会将sql中的#{}替换为?号,调用PreparedStatement的set方法来赋值
- MyBatis在处理
{}替换成变量的值
- 使用#{}可以有效的防止SQL注入, 提高系统安全性
15. 从架构设计的角度,可以将 MyBatis 分为哪几层?每层都有哪些主要模块?
1.接口层
第一个是跟客户打交道的服务员,它是用来接收程序的工作指令的,我们把它叫做接口层。
接口层是我们打交道最多的。核心对象是 SqlSession,它是上层应用和 MyBatis 打交道的桥梁,SqlSession 上定义了非常多的对数据库的操作方法。接口层在接收到调用请求的时候,会调用核心处理层的相应模块来完成具体的数据库操作。
2.核心处理层
第二个是后台的厨师,他们根据客户的点菜单,把原材料加工成成品,然后传到窗口。这一层是真正去操作数据的,我们把它叫做核心层。
既然叫核心处理层,也就是跟数据库操作相关的动作都是在这一层完成的。核心处理层主要做了这几件事:
参数映射: 把接口中传入的参数解析并且映射成JDBC类型
SQL解析:解析xml文件中的SQL语句,包括插入参数,和动态SQL的生成;
SQL执行:执行SQL语句;
结果映射: 处理结果集,并映射成Java对象。
3.基础支持层
最后就是餐厅也需要有人做后勤(比如清洁、采购、财务),来支持厨师的工作和整个餐厅运营。我们把它叫做基础层。
基础支持层主要是一些抽取出来的通用的功能(实现复用),用来支持核心处理层的功能。比如数据源、缓存、日志、xml解析、反射、IO、事务等等这些功能。
[
](https://blog.csdn.net/weixin_43934607/article/details/114156578)
16. spring 常用的注入方式有哪些?
主要有三种注入方式:
- 构造方法注入
- set方法注入
- 注解注入
17. spring bean 的作用域
Spring 支持如下 5 种作用域:
(1)singleton:默认作用域,单例 bean,每个容器中只有一个 bean 的实例。
(2)prototype:为每一个 bean 请求创建一个实例。
(3)request:为每一个 request 请求创建一个实例,在请求完成以后,bean 会失效 并被垃圾回收器回收。 (4)session:与 request 范围类似,同一个 session 会话共享一个实例,不同会话 使用不同的实例
(5)global-session:全局作用域,所有会话共享一个实例。如果想要声明让所有会 话共享的存储变量的话,那么这全局变量需要存储在 global-session 中。
18. 说一下 spring 的事务隔离?
Spring 有五大隔离级别,默认值为 ISOLATION_DEFAULT(使用数据库的设置),其他四个隔离级别和数据库的隔离级别一致:
- ISOLATION_DEFAULT:用底层数据库的设置隔离级别,数据库设置的是什么我就用什么;
- ISOLATIONREADUNCOMMITTED:未提交读,最低隔离级别、事务未提交前,就可被其他事务读取(会出现幻读、脏读、不可重复读);
- ISOLATIONREADCOMMITTED:提交读,一个事务提交后才能被其他事务读取到(会造成幻读、不可重复读),SQL server 的默认级别;
- ISOLATIONREPEATABLEREAD:可重复读,保证多次读取同一个数据时,其值都和事务开始时候的内容是一致,禁止读取到别的事务未提交的数据(会造成幻读),MySQL 的默认级别; ISOLATION_SERIALIZABLE:序列化,代价最高最可靠的隔离级别,该隔离级别能防止脏读、不可重复读、幻读。
- 脏读 :表示一个事务能够读取另一个事务中还未提交的数据。比如,某个事务尝试插入记录 A,此时该事务还未提交,然后另一个事务尝试读取到了记录 A。
- 不可重复读 :是指在一个事务内,多次读同一数据。
- 幻读 :指同一个事务内多次查询返回的结果集不一样。比如同一个事务 A 第一次查询时候有 n 条记录,但是第二次同等条件下查询却有 n+1 条记录,这就好像产生了幻觉。发生幻读的原因也是另外一个事务新增或者删除或者修改了第一个事务结果集里面的数据,同一个记录的数据内容被修改了,所有数据行的记录就变多或者变少了。
[
](https://blog.csdn.net/qq_37651267/article/details/92425172)
19. @RequestMapping @Autowired 的作用是什么?
@RequestMapping
RequestMapping是一个用来处理请求地址映射的注解,可用于类或方法上。用于类上,表示类中的所有响应请求的方法都是以该地址作为父路径。
RequestMapping注解有六个属性,下面我们把她分成三类进行说明。
1、 value, method;
value: 指定请求的实际地址,指定的地址可以是URI Template 模式(后面将会说明);
method: 指定请求的method类型, GET、POST、PUT、DELETE等;
2、 consumes,produces;
consumes: 指定处理请求的提交内容类型(Content-Type),例如application/json, text/html;
produces: 指定返回的内容类型,仅当request请求头中的(Accept)类型中包含该指定类型才返回;
3、 params,headers;
params: 指定request中必须包含某些参数值是,才让该方法处理。
headers: 指定request中必须包含某些指定的header值,才能让该方法处理请求。
在java代码中使用@Autowired或@Resource注解方式进行装配,这两个注解的区别是:@Autowired 默认按类型装配,@Resource默认按名称装配,当找不到与名称匹配的bean才会按类型装配。
@Autowired
private PersonDao personDao;//用于字段上
@Autowired
public void setOrderDao(OrderDao orderDao) {//用于属性的setter方法上
this.orderDao = orderDao;
}
@Autowired (Spring框架)注解是按类型装配依赖对象,默认情况下它要求依赖对象必须存在,如果允许null值,可以设置它required属性为false。如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。如下:
@Autowired @Qualifier(“personDaoBean”)
private PersonDao personDao;
20. 说一下 hibernate 的缓存机制?
一级缓存,二级缓存
Session 的缓存被称为hibernate的第一级缓存。SessionFactory的外置缓存称为hibernate 的二级缓存。这两个缓存都位于持久层,它们存放的都是数据库数据的拷贝。SessionFactory的内置缓存存放元数据和预定义SQL,SessionFactory的内置缓存是只读缓存。
Hibernate的缓存包括Session的缓存和SessionFactory的缓存,其中SessionFactory的缓存又可以分为两类:内置缓存和外置缓存。Session的缓存是内置的,不能被卸载,也被称为Hibernate的第一级缓存。
[
](https://blog.csdn.net/weixin_42595331/article/details/87911162)
21. 分页插件的实现原理是什么?MyBatis 逻辑分页和物理分页的区别是什么
分页插件的原理就是使用MyBatis提供的插件接口,实现自定义插件,在插件的拦截方法内,拦截待执行的SQL,然后根据设置的dialect(方言),和设置的分页参数,重写SQL ,生成带有分页语句的SQL,执行重写后的SQL,从而实现分页
逻辑分页和物理分页的区别:
Mybatis实现分页的方法:
- 使用RowBounds对象进行逻辑(逻辑内存中)分页,它是针对ResultSet结果集执行的内存分页。
- 使用pageHelper插件进行物理分页(其实是依赖物理数据库实体)。
22. 说一下 MyBatis 的一级缓存和二级缓存
一级缓存
一级缓存是SqlSession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个数据结构用于存储缓存数据。不同的sqlSession之间的缓存数据区域是互相不影响的。也就是他只能作用在同一个sqlSession中,不同的sqlSession中的缓存是互相不能读取的。
一级缓存的工作原理: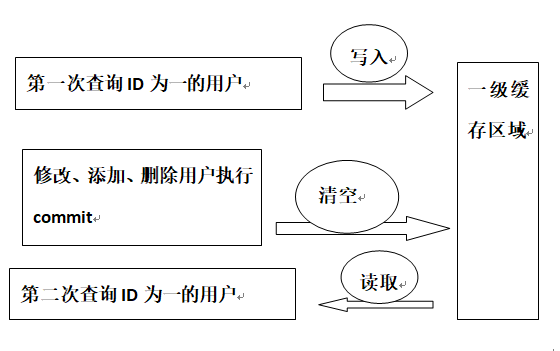
用户发起查询请求,查找某条数据,sqlSession先去缓存中查找,是否有该数据,如果有,读取;
如果没有,从数据库中查询,并将查询到的数据放入一级缓存区域,供下次查找使用。
但sqlSession执行commit,即增删改操作时会清空缓存。这么做的目的是避免脏读。
如果commit不清空缓存,会有以下场景:A查询了某商品库存为10件,并将10件库存的数据存入缓存中,之后被客户买走了10件,数据被delete了,但是下次查询这件商品时,并不从数据库中查询,而是从缓存中查询,就会出现错误。
既然有了一级缓存,那么为什么要提供二级缓存呢?
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。二级缓存的作用范围更大。
还有一个原因,实际开发中,MyBatis通常和Spring进行整合开发。Spring将事务放到Service中管理,对于每一个service中的sqlsession是不同的,这是通过mybatis-spring中的org.mybatis.spring.mapper.MapperScannerConfigurer创建sqlsession自动注入到service中的。 每次查询之后都要进行关闭sqlSession,关闭之后数据被清空。所以spring整合之后,如果没有事务,一级缓存是没有意义的。
二级缓存
二级缓存原理: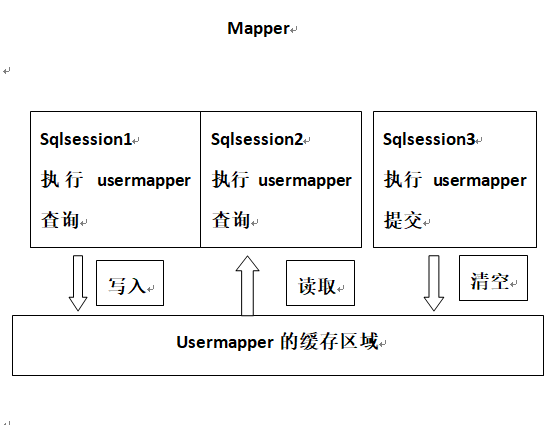
二级缓存是mapper级别的缓存,多个SqlSession去操作同一个Mapper的sql语句,多个SqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
UserMapper有一个二级缓存区域(按namespace分),其它mapper也有自己的二级缓存区域(按namespace分)。每一个namespace的mapper都有一个二级缓存区域,两个mapper的namespace如果相同,这两个mapper执行sql查询到数据将存在相同的二级缓存区域中。
开启二级缓存:
1,打开总开关
在MyBatis的配置文件中加入:
2,在需要开启二级缓存的mapper.xml中加入caceh标签
3,让使用二级缓存的POJO类实现Serializable接口
- public class User implements Serializable {}
23. MyBatists的resultType和resultmap的区别
resultType和resultMap功能类似 ,都是返回对象信息 ,但是resultMap要更强大一些 ,可自定义。因为resultMap要配置一下,表和类的一一对应关系,所以说就算你的字段名和你的实体类的属性名不一样也没关系,都会给你映射出来,但是,resultType就比较鸡肋了,必须字段名一样,比如说 cId和c_id 这种的都不能映射 。
24. MyBatis的好处?
1、MyBatis 把 sql 语句从 Java 源程序中独立出来,放在单独的 XML 文件中编写,给程序的维护带来了很大便利。
2、MyBatis 封装了底层 JDBC API 的调用细节,并能自动将结果集转换成 Java Bean 对象, 大大简化了 Java 数据库编程的重复工作。
3、因为 MyBatis 需要程序员自己去编写 sql 语句,程序员可以结合数据库自身的特点灵活控制 sql 语句,因此能够实现比 Hibernate 等全自动 orm 框架更高的查询效率,能够完成复杂查询。
[
](https://blog.csdn.net/m0_62052624/article/details/121507351)
25. MyBatis 与 Hibernate 的区别?
Hibernate与MyBatis对比
相同点:
Hibernate与MyBatis都可以是通过SessionFactoryBuider由XML配置文件生成SessionFactory,然后由SessionFactory 生成Session,最后由Session来开启执行事务和SQL语句。
其中SessionFactoryBuider,SessionFactory,Session的生命周期都是差不多的。Hibernate和MyBatis都支持JDBC和JTA事务处理。
不同点:
(1)hibernate是全自动,而mybatis是半自动
hibernate完全可以通过对象关系模型实现对数据库的操作,拥有完整的JavaBean对象与数据库的映射结构来自动生成sql。而mybatis仅有基本的字段映射,对象数据以及对象实际关系仍然需要通过手写sql来实现和管理。
(2)hibernate数据库移植性远大于mybatis
hibernate通过它强大的映射结构和hql语言,大大降低了对象与数据库(Oracle、MySQL等)的耦合性,而mybatis由于需要手写sql,因此与数据库的耦合性直接取决于程序员写sql的方法,如果sql不具通用性而用了很多某数据库特性的sql语句的话,移植性也会随之降低很多,成本很高。
(3)hibernate拥有完整的日志系统,mybatis则欠缺一些
hibernate日志系统非常健全,涉及广泛,包括:sql记录、关系异常、优化警告、缓存提示、脏数据警告等;而mybatis则除了基本记录功能外,功能薄弱很多。
(4)mybatis相比hibernate需要关心很多细节
hibernate配置要比mybatis复杂的多,学习成本也比mybatis高。但也正因为mybatis使用简单,才导致它要比hibernate关心很多技术细节。mybatis由于不用考虑很多细节,开发模式上与传统jdbc区别很小,因此很容易上手并开发项目,但忽略细节会导致项目前期bug较多,因而开发出相对稳定的软件很慢,而开发出软件却很快。hibernate则正好与之相反。但是如果使用hibernate很熟练的话,实际上开发效率丝毫不差于甚至超越mybatis。
(5)sql直接优化上,mybatis要比hibernate方便很多
由于mybatis的sql都是写在xml里,因此优化sql比hibernate方便很多。而hibernate的sql很多都是自动生成的,无法直接维护sql;虽有hql,但功能还是不及sql强大,见到报表等变态需求时,hql也歇菜,也就是说hql是有局限的;hibernate虽然也支持原生sql,但开发模式上却与orm不同,需要转换思维,因此使用上不是非常方便。总之写sql的灵活度上hibernate不及mybatis。
(6)缓存机制上,hibernate要比mybatis更好一些
MyBatis的二级缓存配置都是在每个具体的表-对象映射中进行详细配置,这样针对不同的表可以自定义不同的缓存机制。并且Mybatis可以在命名空间中共享相同的缓存配置和实例,通过Cache-ref来实现。
而Hibernate对查询对象有着良好的管理机制,用户无需关心SQL。所以在使用二级缓存时如果出现脏数据,系统会报出错误并提示。
总结
(1)两者相同点
Hibernate和Mybatis的二级缓存除了采用系统默认的缓存机制外,都可以通过实现你自己的缓存或为其他第三方缓存方案,创建适配器来完全覆盖缓存行为。
(2)两者不同点
Hibernate的二级缓存配置在SessionFactory生成的配置文件中进行详细配置,然后再在具体的表-对象映射中配置是那种缓存。而MyBatis在使用二级缓存时需要特别小心。如果不能完全确定数据更新操作的波及范围,避免Cache的盲目使用。否则,脏数据的出现会给系统的正常运行带来很大的隐患。
[
](https://blog.csdn.net/eff666/article/details/71332386)
26. 使用 MyBatis 的 mapper 接口调用时有哪些要求
1、Mapper 接口方法名和 mapper.xml 中定义的每个 sql 的 id 相同;
2、Mapper 接口方法的输入参数类型和 mapper.xml 中定义的每个 sql 的
parameterType 的类型相同;
3、Mapper 接口方法的输出参数类型和 mapper.xml 中定义的每个 sql 的
resultType 的类型相同;
4、Mapper.xml 文件中的 namespace 即是 mapper 接口的类路径。
27. BeanFactory
BeanFacotry是spring中比较原始的Factory。如XMLBeanFactory就是一种典型的BeanFactory。原始的BeanFactory无法支持spring的许多插件,如AOP功能、Web应用等。
ApplicationContext接口,它由BeanFactory接口派生而来,ApplicationContext包含BeanFactory的所有功能,通常建议比BeanFactory优先
BeanFactory和FactoryBean的区别
BeanFactory是接口,提供了OC容器最基本的形式,给具体的IOC容器的实现提供了规范,
FactoryBean也是接口,为IOC容器中Bean的实现提供了更加灵活的方式,FactoryBean在IOC容器的基础上给Bean的实现加上了一个简单工厂模式和装饰模式(如果想了解装饰模式参考:修饰者模式(装饰者模式,Decoration) 我们可以在getObject()方法中灵活配置。其实在Spring源码中有很多FactoryBean的实现类.
区别:BeanFactory是个Factory,也就是IOC容器或对象工厂,FactoryBean是个Bean。在Spring中,所有的Bean都是由BeanFactory(也就是IOC容器)来进行管理的。但对FactoryBean而言,这个Bean不是简单的Bean,而是一个能生产或者修饰对象生成的工厂Bean,它的实现与设计模式中的工厂模式和修饰器模式类似
1、 BeanFactory
BeanFactory,以Factory结尾,表示它是一个工厂类(接口), 它负责生产和管理bean的一个工厂。在Spring中,BeanFactory是IOC容器的核心接口,它的职责包括:实例化、定位、配置应用程序中的对象及建立这些对象间的依赖。BeanFactory只是个接口,并不是IOC容器的具体实现,但是Spring容器给出了很多种实现,如 DefaultListableBeanFactory、XmlBeanFactory、ApplicationContext等,其中XmlBeanFactory就是常用的一个,该实现将以XML方式描述组成应用的对象及对象间的依赖关系。XmlBeanFactory类将持有此XML配置元数据,并用它来构建一个完全可配置的系统或应用。
都是附加了某种功能的实现。 它为其他具体的IOC容器提供了最基本的规范,例如DefaultListableBeanFactory,XmlBeanFactory,ApplicationContext 等具体的容器都是实现了BeanFactory,再在其基础之上附加了其他的功能。
BeanFactory和ApplicationContext就是spring框架的两个IOC容器,现在一般使用ApplicationnContext,其不但包含了BeanFactory的作用,同时还进行更多的扩展。
BeanFacotry是spring中比较原始的Factory。如XMLBeanFactory就是一种典型的BeanFactory。
原始的BeanFactory无法支持spring的许多插件,如AOP功能、Web应用等。ApplicationContext接口,它由BeanFactory接口派生而来
28. ApplicationContext
29. SpringBoot常用注解
项目配置注解
1、@SpringBootApplication 注解
查看源码可发现,@SpringBootApplication是一个复合注解,包含了@SpringBootConfiguration,@EnableAutoConfiguration,@ComponentScan这三个注解。
这三个注解的作用分别为:
- @SpringBootConfiguration:标注当前类是配置类,这个注解继承自@Configuration。并会将当前类内声明的一个或多个以@Bean注解标记的方法的实例纳入到srping容器中,并且实例名就是方法名。
- @EnableAutoConfiguration:是自动配置的注解,这个注解会根据我们添加的组件jar来完成一些默认配置,我们做微服时会添加spring-boot-starter-web这个组件jar的pom依赖,这样配置会默认配置springmvc 和tomcat。
- @ComponentScan:扫描当前包及其子包下被@Component,@Controller,@Service,@Repository注解标记的类并纳入到spring容器中进行管理。等价于
2、@ServletComponentScan:Servlet、Filter、Listener 可以直接通过 @WebServlet、@WebFilter、@WebListener 注解自动注册,这样通过注解servlet ,拦截器,监听器的功能而无需其他配置,所以这次相中使用到了filter的实现,用到了这个注解。
3、@MapperScan:spring-boot支持mybatis组件的一个注解,通过此注解指定mybatis接口类的路径,即可完成对mybatis接口的扫描。
它和@mapper注解是一样的作用,不同的地方是扫描入口不一样。@mapper需要加在每一个mapper接口类上面。所以大多数情况下,都是在规划好工程目录之后,通过@MapperScan注解配置路径完成mapper接口的注入。
4、资源导入注解:@ImportResource @Import @PropertySource 这三个注解都是用来导入自定义的一些配置文件。
@ImportResource(locations={}) 导入其他xml配置文件,需要标准在主配置类上。
导入property的配置文件 @PropertySource指定文件路径,这个相当于使用spring的
@import注解是一个可以将普通类导入到spring容器中做管理
2、@CrossOrigin:@CrossOrigin(origins = “”, maxAge = 1000) 这个注解主要是为了解决跨域访问的问题。这个注解可以为整个controller配置启用跨域,也可以在方法级别启用。
我们在项目中使用这个注解是为了解决微服在做定时任务调度编排的时候,会访问不同的spider节点而出现跨域问题。
3、@Autowired:这是个最熟悉的注解,是spring的自动装配,这个个注解可以用到构造器,变量域,方法,注解类型上。当我们需要从bean 工厂中获取一个bean时,Spring会自动为我们装配该bean中标记为@Autowired的元素。
4、@EnablCaching@EnableCaching: 这个注解是spring framework中的注解驱动的缓存管理功能。自spring版本3.1起加入了该注解。其作用相当于spring配置文件中的cache manager标签。
5、@PathVariable:路径变量注解,@RequestMapping中用{}来定义url部分的变量名
30. 谈谈你对SpringBoot的理解
一、springboot的定义
Spring Boot是伴随着Spring4.0共同诞生的,它的目的就是简化spring的配置及开发,并协助开发人员可以整体管理应用程序的配置而不再像以前那样需要做大量的配置工作,它提供了很多开发组件,并且内嵌了web应用容器,如tomcat和Jetty等。其目的便是使我们的开发变得简化并且能大幅度提高开发人员的开发效率,为了简化Spring功能的配置我们可以引入或启动我们需要的Spring功能。这样做的好处就是避免开发人员过多的对框架的关注,而把更多的精力与时间放在系统的业务逻辑代码中。
二、SpringBoot的作用
Spring Boot框架,其功能非常简单,便是帮助我们实现自动配置。我们都知道Spring Boot框架的核心是自动配置。只要有相应的jar包,Spring就会帮助我们实现自动配置,而无需像以前我们使用spring框架一样要做很多配置。当默认配置不能满足我们要求的时候,我们能够用自己的配置来替换这些自动的配置类。此外,上面我们也提到Spring Boot内嵌了web应用容器,除此之外还集成了系统监控等功能,这些都可以帮助我们快速搭建企业级的应用程序并使用。
三、Spring Boot的核心功能
1.可以不依赖tomcat等外部容器来独立运行的web项目,springboot的优点是能够以jar包的形式运行。
2.嵌入式的Servlet容器:我们不需要像以前那边先打个war包,然后再运行,在springboot看来这些都是多余的,我们可以选择他内嵌的tomcat、Jetty或者Undertow等容器来直接运行。
3.使pom文件配置更简化:我们只需要在 pom 文件中添加starter-web 依赖即可,无需像以前一样引入很多依赖而造成容易漏掉。
4.能够生产环境中直接使用性能指标、健康检查和应用信息等。
5.springboot不需要任何xml文件配置而能实现所有的spring配置
31. 讲一下SpringBoot的四大核心功能
SpringBoot4大核心组件
starter, autoconfigure, CLI 以及actuator
Starter
- 官方提供的 starter 命名:spring-boot-starter-xxx
- 非官方的 starter 命名:xxx-spring-boot-starter其中 xxx 就是我们想要依赖的组件或者 jar 包。引入之后通过简单的约定配置就可以正常使用。
- Starter 帮我们封装好了所有需要的依赖,避免我们自己添加导致的一些Jar包冲突或者缺少包的情况;
- Starter 帮我们自动注入了需要的 Bean 实例到 Spring 容器中,不需要我们手动配置(这个可以说是 starter 干的,但实际上并不是);
所以: starter 包的内容就是 pom 文件,就是一个依赖传递包。
Spring Boot Autoconfigure
autoconfigure 在我们的开发中并不会被感知,因为它是存在与我们的 starter 中的。所以我们的每个 starter 都是依赖 autoconfigure 的
autoconfigure 内容是配置 Bean 实例到 Spring 容器的实际代码实现包,然后提供给 starter 依赖。所以说配置 Bean 实例到Spring容器中实际是 autoconfigure 做的,因为是 starter 依赖它,所以也可以说是 starter 干的。
所以:autocinfigure 是 starter 体现出来的能力的代码实现
Spring Boot CLI
Spring Boot CLI 是一个命令行使用 Spring Boot 的客户端工具;主要功能如下:
- 运行 groovy 脚本
- 打包 groovy 文件到 jar
- 初始化 Spring Boot 项目
- 其他
Spring Boot actuator
actuator 是 Spring Boot 的监控插件,本身提供了很多接口可以获取当前项目的各项运行状态指标。

若有收获,就点个赞吧
0 人点赞
