超好英文博客:understanding LSTM
LSTM ->Long Short-Term Memory,长短时记忆神经网络,1997年提出,主要用于解决RNN没办法长时间记忆(对于很久前的信息RNN会有一种失效的问题),是一种基于RNN变化的神经网络(使得神经网络具有对很久前的信息仍有记忆效果),现在广泛应用于自然语言处理(NLP),时间序列预测和构建一些高层次的模型。


我们先透过LSTM的模型内部,去挖掘LSTM学习长期依赖信息的秘密:
首先,我们要清楚的认识到,LSTM最上面有一层细胞层Ct,是信息的载体,用于记录数据的变化:
- 遗忘门
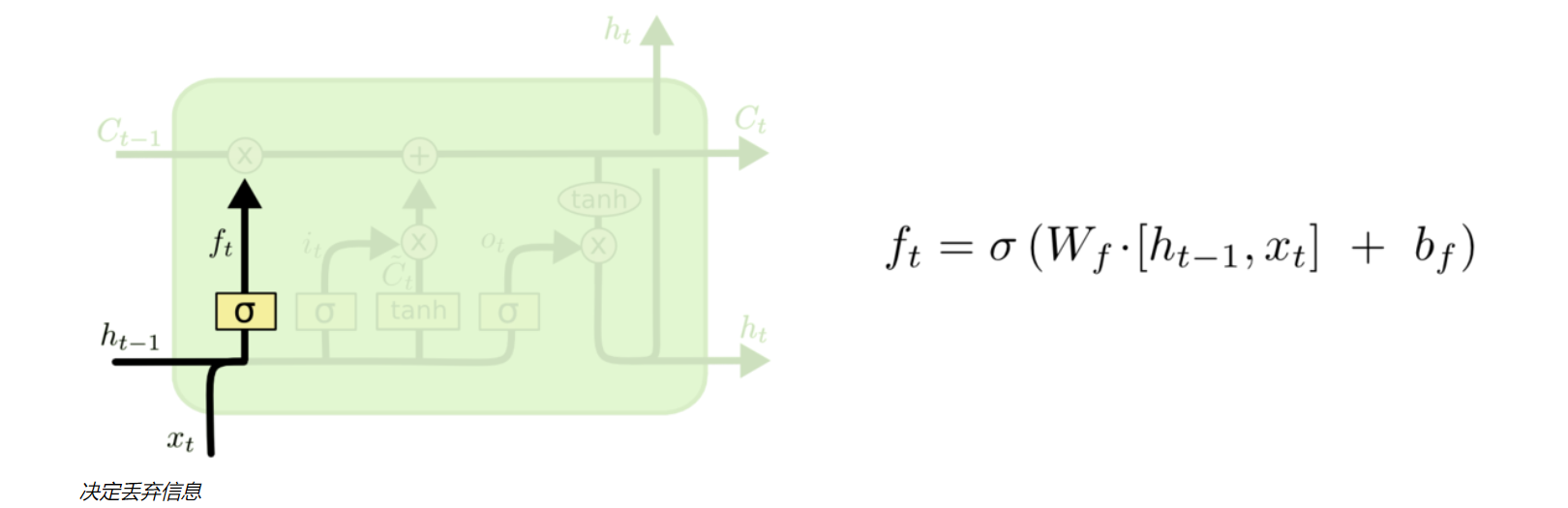
遗忘门是LSTM模型的第一步,它接收于上一个神经元传入的信息ht-1和新传入的信息Xt,通过sigmoid函数对所有信息进行处理,得到ft传入细胞状态Ct,ft位于0-1,越接近0 -> 遗忘,越接近1 -> 记得
- 输入门
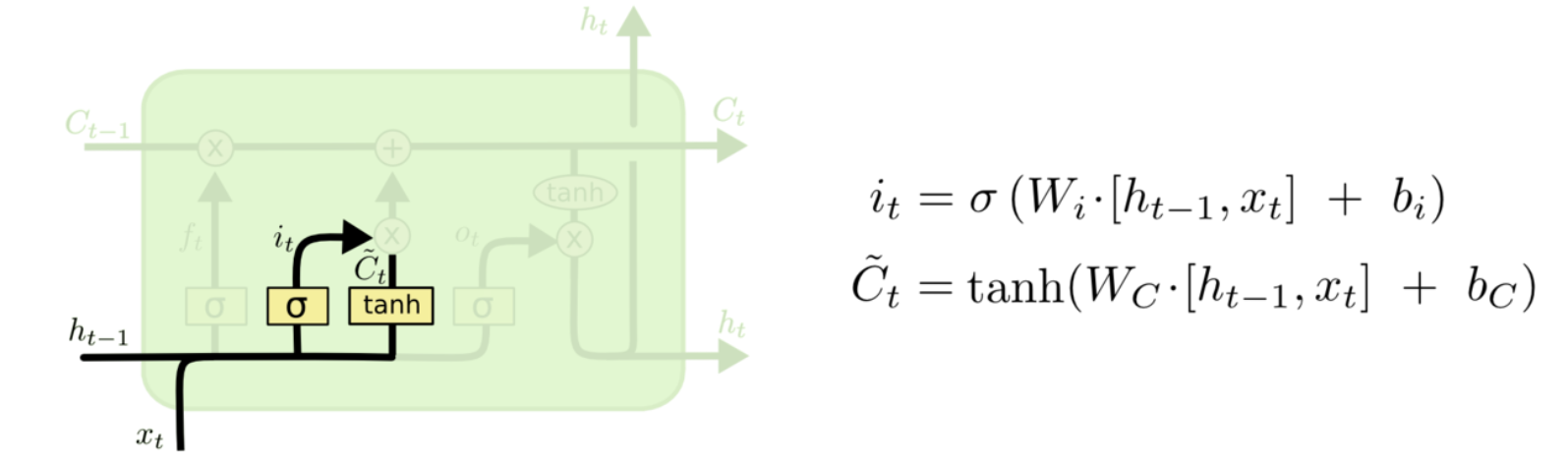
输入门是LSTM的第二步,它把ht和xt分别用sigmoid和tanh函数进行运算,确定我们需要更新的数据。
sigmoid的用处:决定什么值要更新(筛选)
- 更新门
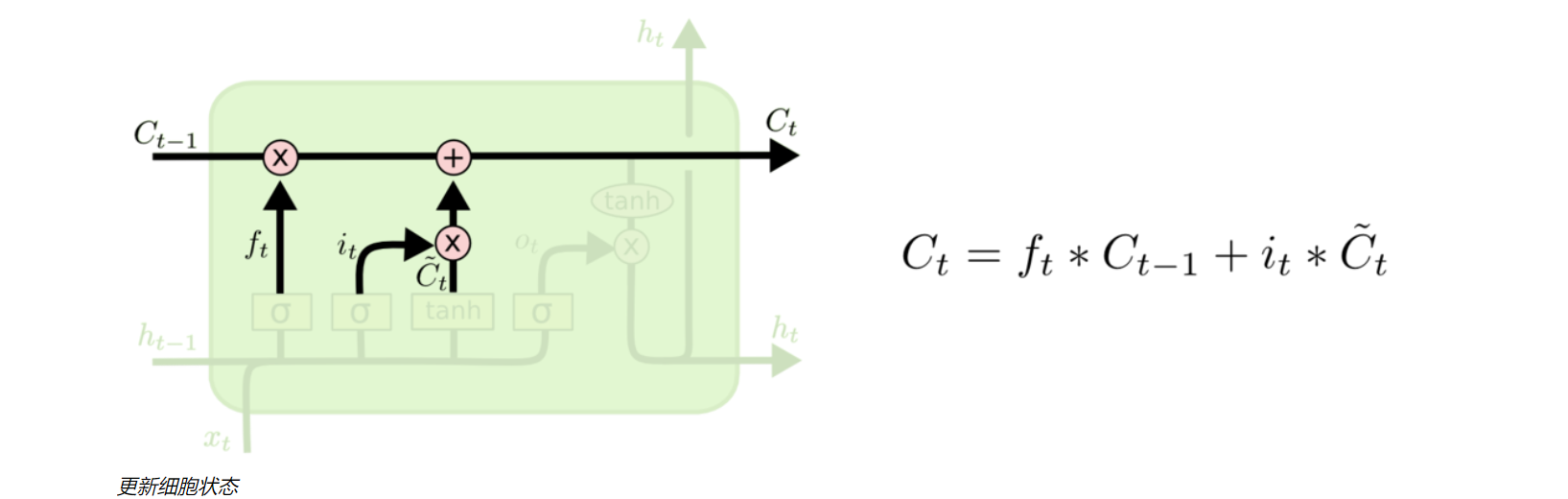
更新门是LSTM的第三步,它通过矩阵相乘和矩阵相加,把需要遗忘的数据和需要更新的数据传入细胞Ct,进行细胞状态的更新
- 输出门
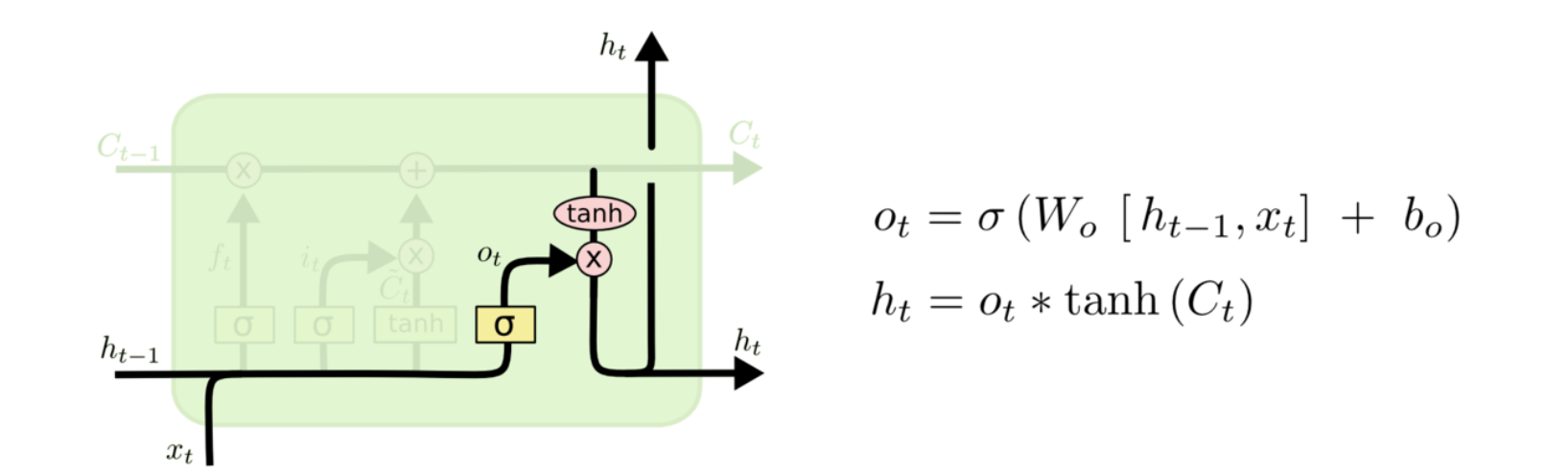
最后是输出门,通过对细胞状态Ct使用tanh函数更新出新的信息ht,输出到下一个LSTM神经元中。
sigmoid的用处:确定细胞状态Ct哪些部分输出出去(筛选)
当然这些都是我比较浅显的理解,详细可见我的参考文章理解 LSTM(Long Short-Term Memory, LSTM) 网络
关于LSTM的优缺点,可以查看这篇文章LSTM网络模型的原理和优缺点
建立LSTM ->pytorch
# LSTM pytorch模型import torchfrom torch import nnfrom torch.autograd import Variable#默认linner为一层,如果有需要可自行添加class lstm(nn.Module):def __init__(self,input_size=2,hidden_size=4,output_size=1,num_layer=2):super(lstm,self).__init__()self.layer1 = nn.LSTM(input_size,hidden_size,num_layer)self.layer2 = nn.Linear(hidden_size,output_size)#输出层def forward(self,x):x,_ = self.layer1(x) #输入:(seq_len,batch,input_size)s,b,h = x.shape #输出:(seq_len,batch,hidden_size)x = x.view(s*b,h) #调整模型的样子,使其能够进入线性层x = self.layer2(x)x = x.view(s,b,-1) #把模型原貌改回来return x
- 待解决问题:
作为时间序列预测,我们是通过捕捉时间序列的变化规律而进行预测,我们训练出来理想的模型应该是:把训练集最后一个窗口为look_back的数据预测出来的pred加入我们的训练集,反复进行预测从而得出几天后的数据,但是在使用单维单步(只预测后一步)进行实践的过程中发现它很容易失活。
我的初步思考:在这种预测想法下,单维单步的数据很容易陷入一种平缓,它的局限性太大了,对于新接收的数据如果相较于上一个数据很接近,那么它在这个基础上预测出的下一个数会延续这个接近的特性,非常容易陷入平缓性,所以这样子预测出来的效果十分差,于是我采用了单维多步预测进行实验,发现就没有这种问题了,因为多步预测的话不容易先入这种局部性,

若有收获,就点个赞吧
0 人点赞
