传统的领域模型:
- 缺少每个业务对象的明确边界
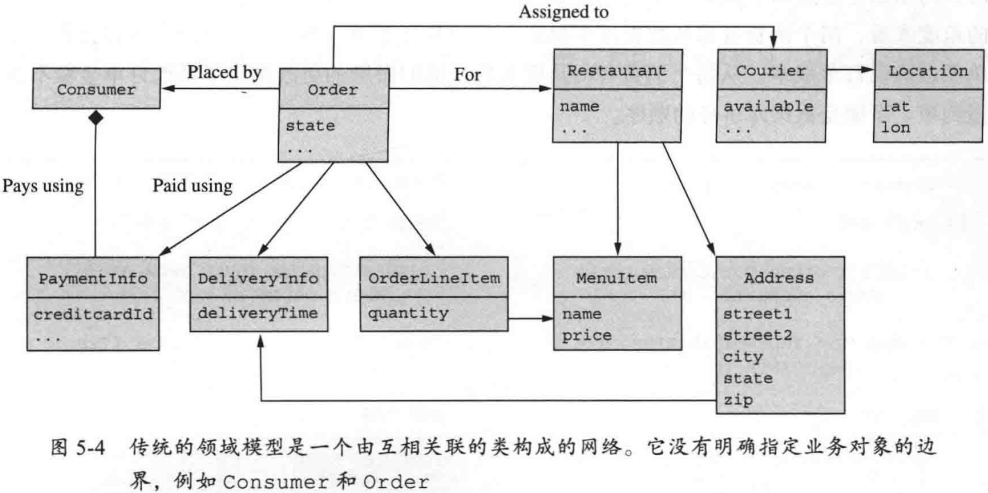
5.2.1 模糊边界所带来的问题
- 概念模糊
- 会在更新业务对象时导致问题
5.2.2 聚合拥有明确的边界
聚合是一个边界内的领域对象的集群, 可以将其视为一个单元. 它由根实体和可能的一个或多个其他实体和值对象组成. 许多业务对象都被建模为聚合.

Order 聚合及其边界:

- 聚合将领域模型分解为块, 每一块更容易理解
- 阐明了加载, 更新, 删除等操作的范围
- 操作作用于整额聚合而不是部分聚合
- 从数据库中完整加载
聚合代表了一致的边界
在根上调用更新操作, 这会强制执行各种不变量约束.
- 可以使用例如版本号或数据库级锁锁定聚合根来处理并发性
将对象组织成树状, 一系列操作由根对象触发.
识别聚合是关键
设计领域模型的关键部分是识别聚合, 以及它们的边界和根. 聚合内部结构的细节是次要的.
5.2.3 聚合的规则
这些规则确保聚合是一个可以强制执行各种不变量约束的自包含单元.
规则一: 只引用聚合根
要求聚合根是聚合中唯一可以由外部类引用的部分.
规则二: 聚合间的引用必须使用主键
引用聚合必须通过标识 (例如, 主键) 而不是对象引用.
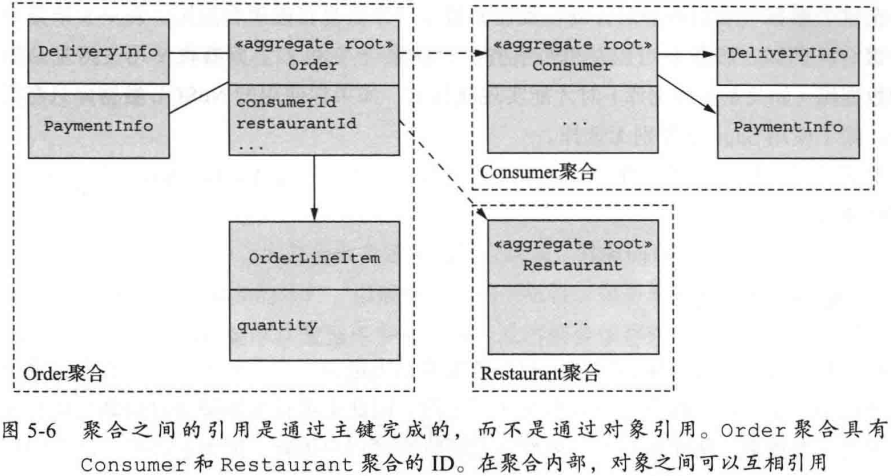
- 聚合是松耦合的, 确保聚合之间的边界得到很好的定义, 并避免意外更新不同的聚合
- 如果聚合是另一个服务的一部分, 则不会出现跨服务的对象引用问题
- 聚合同时也是存储的单元, 让持久化变得简单
规则三: 在一个事务中, 只能创建或更新一个聚合
确保单个事务的范围不超越服务的边界. 还满足大多数 NoSQL 数据库的受限事务模型.
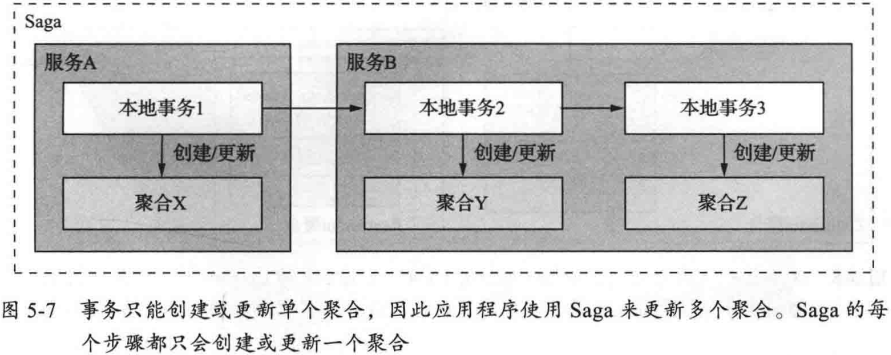
5.2.4 聚合的颗粒度
- 理想上应该很小
- 更细粒度的聚合将提高应用程序能同时处理的请求数量, 提高扩展性
- 改善用户体验, 因为它降低了两个用户尝试同时更新一个聚合而引发冲突的可能性
- 可能需要定义更大的聚合以使特定的聚合更新操作满足事务的原子性
使 Order 成为 Consumer 聚合的一部分的设计:
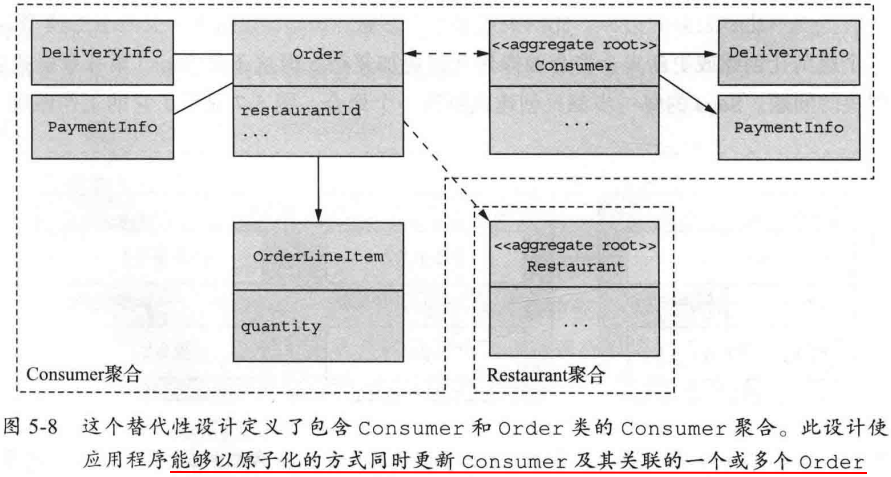
好处:
- 应用程序可以自动更新 Consumer 及其一个或多个与之关联的 Order
弊端:
- 降低了可扩展性
- 使服务分解的障碍
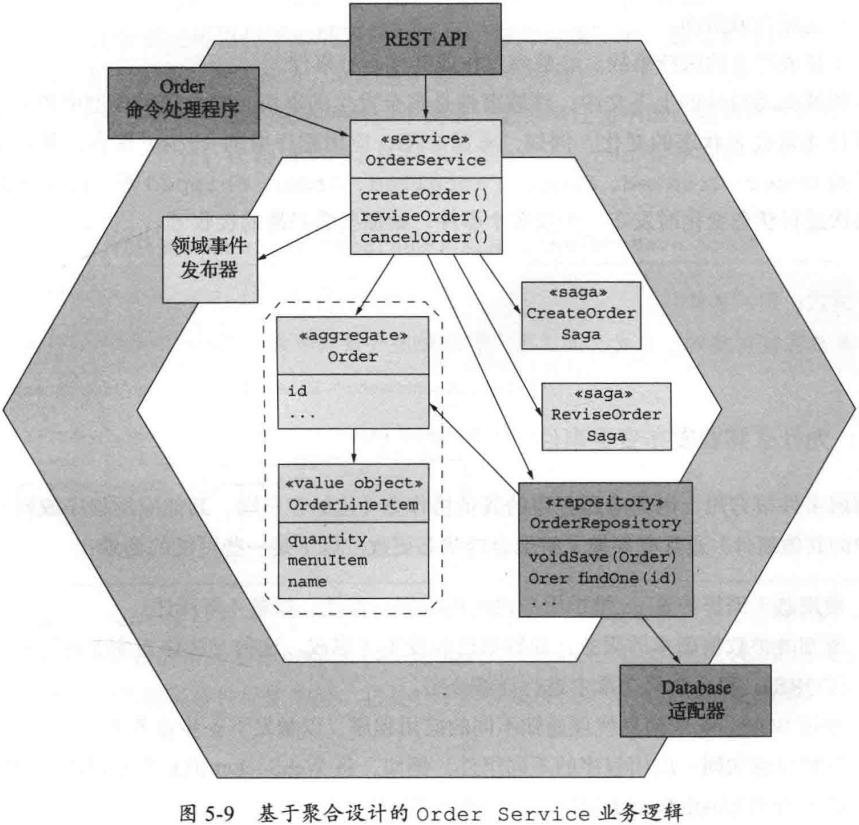
5.2.5 使用聚合设计业务逻辑
Order Service 基于聚合设计的业务逻辑:


若有收获,就点个赞吧
0 人点赞
