可以导出为word自己修改
1.论述题
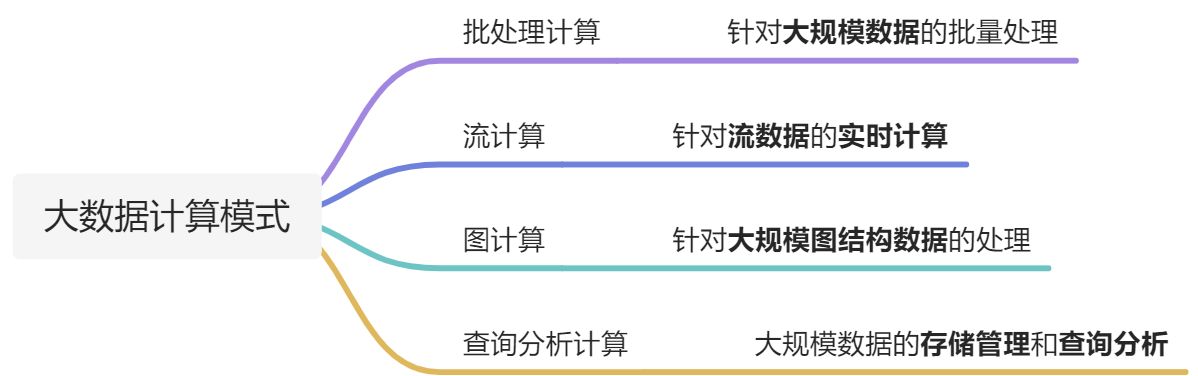
1·1 大数据的计算模式机器解决问题
1·2 spark-streaming的运行原理
1.将输入数据按照时间片分成一段一段的数据得到批数据,每一段数据都转化成Spark中的RDD。将DStream的Transformation操作变为RDD的Transformation操作
2.将RDD经过操作变成中间结果保存在内存中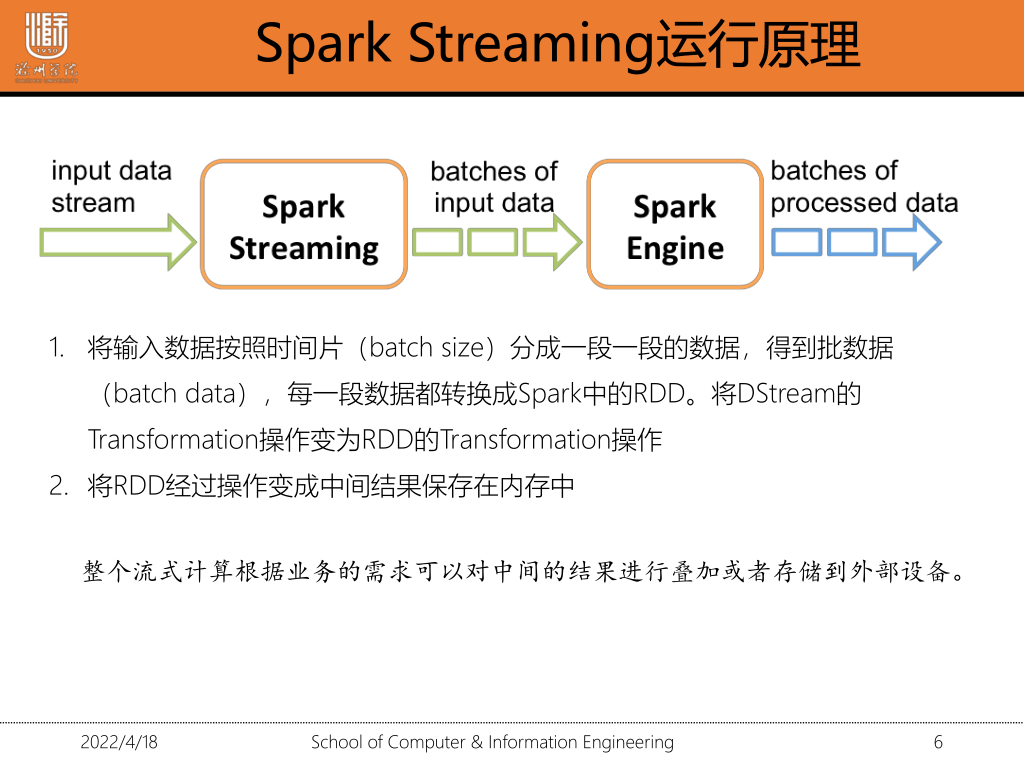
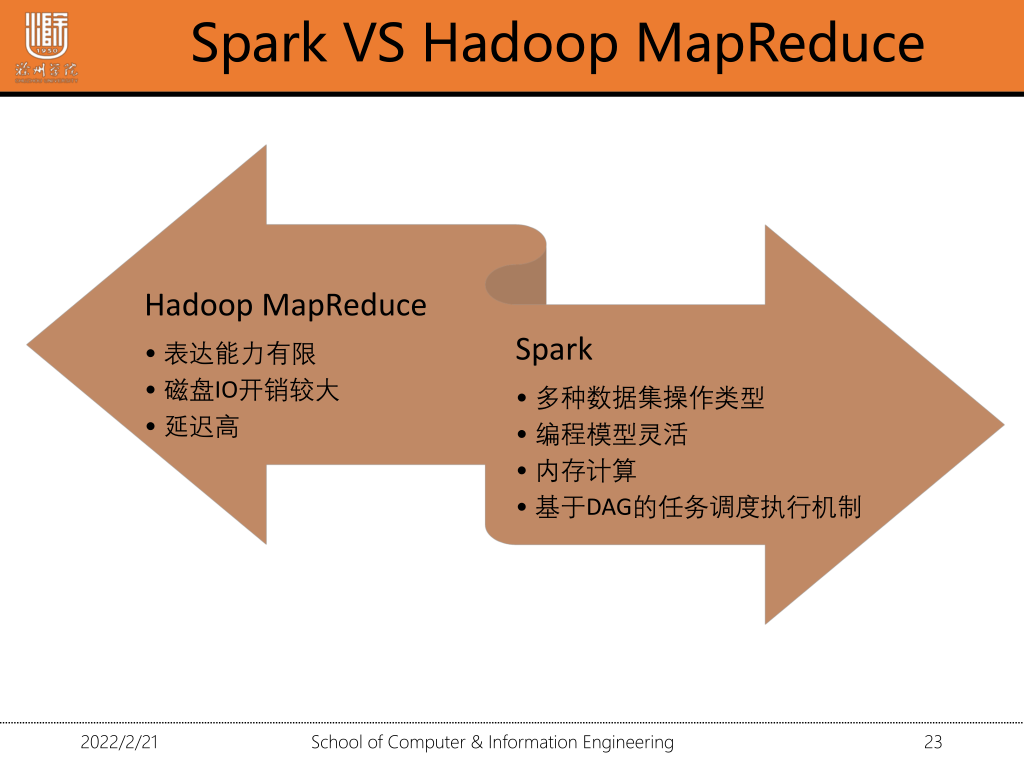
1·3 spark会取代Hadoop吗?
Hadoop包含三个组件yarn,hdfs,MapReduce,分别对应解决三个方面的问题,资源调度(yarn),分布式存储(hdfs),分布式计算(mapreudce)。而spark只解决了分布式计算方面的问题,跟MapReduce需要频繁写磁盘不同,spark重复利用内存,大大提高了计算效率,在分布式计算方面spark大有取代MapReduce之势,而在资源调度,和分布式存储方面spark还无法撼动。
1·4 宽依赖与窄依赖及其区别
宽依赖:父RDD的分区被子RDD的多个分区使用(一对多)
窄依赖:父RDD的分区最多被子RDD的一个分区使用(多对一/一对一)
区别:窄依赖父RDD的每个分区只被子RDD的一个分区所使用,宽依赖父RDD的每个分区都可能被多个子RDD分区所使用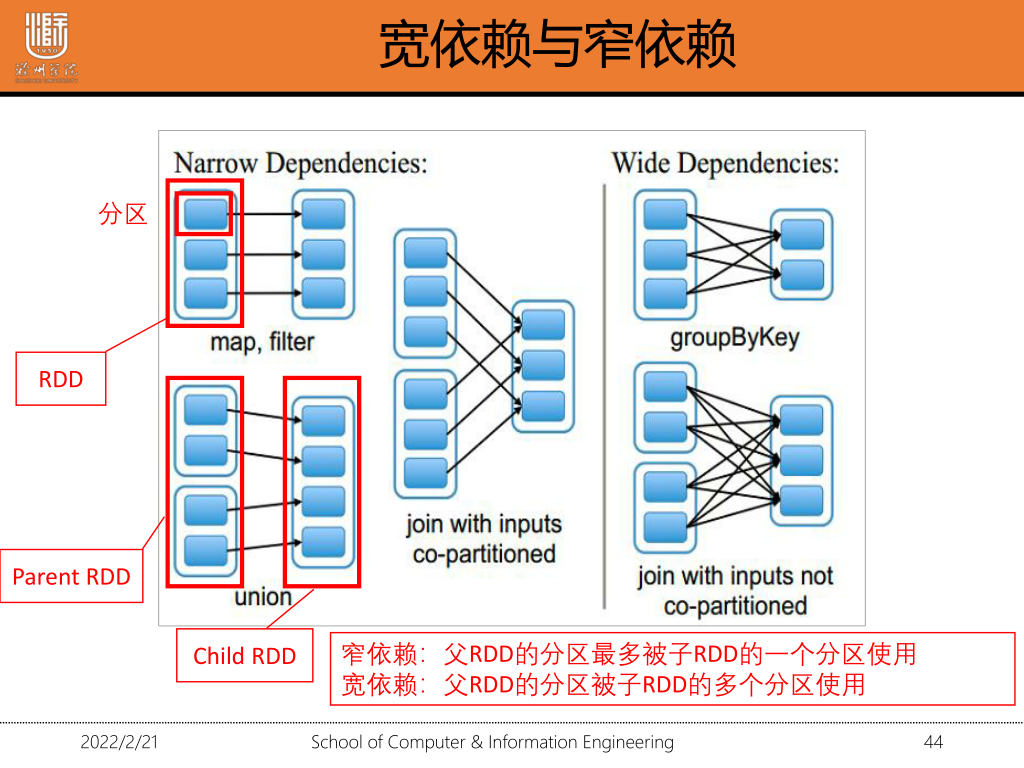
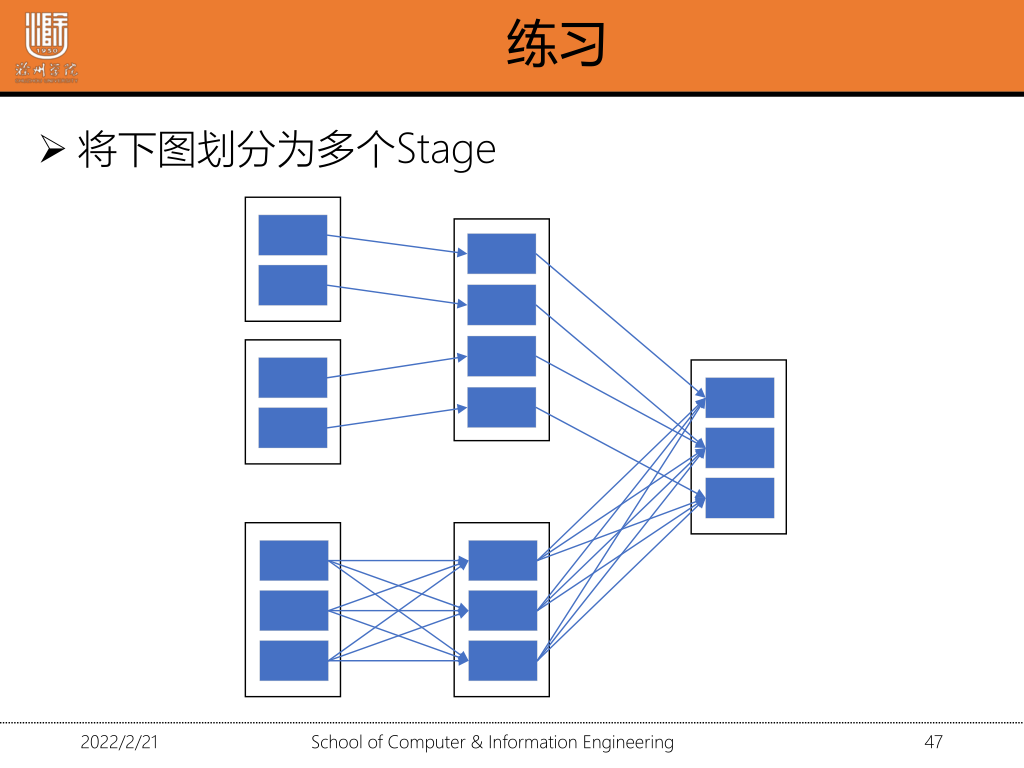
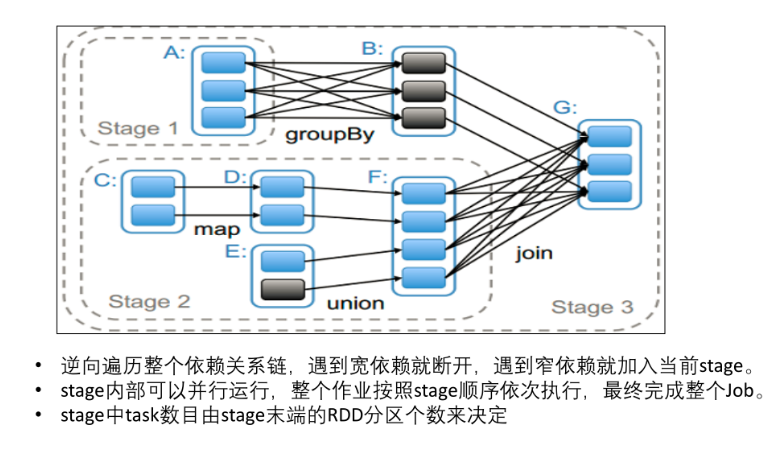
1·5 划分stage
Stage划分是从最终结果RDD从后往前,通过递归来划分stage,循环到最后会把所有rdd划分为一个Stage
遇到宽依赖就断开 遇到窄依赖就加入
1.6 函数式编程跟命令式编程
函数式编程:编程范式,即如何编写程序的方法论
特点:①函数是第一等公民②只用表达式不用语句③没有副作用④不修改状态⑤引用透明⑥惰性计算
命令式编程区别
命令式编程:描述计算机所需作出的行为的编程典范
对硬件操作的抽象, 程序员需要通过指令,精确地告诉计算机干什么事情
2.程序填空
2.1文件的加载
1.parallelise():将Seq数据加载为RDDval data=sc.parallelise(array(1,2,3))2.textFile加载本地文件和hdfs文件val test=sc.textFile("本地路径")val test=sc.textFile("/user/root/test.txt")//读取文件val test=sc.textFile("data.json")
2.2 map/flatMap()
1. map() 筛选出满足函数func的元素,并返回一个新的数据集
val rdd1=sc.parallelize(List(1,2))
val square=rdd1.map(x=>x*x) //平方操作
2.flatmap() 常用来切分单词。先map-》flat 将不同级别迭代器中的元素当成同级别的元素
test.flatMap(x=>x.split("")).collect
2.3 filter/reduceByKey
1. filter() 筛选出满足函数func的元素,并返回一个新的数据集
val rdd1=sc.parallelize(List(("a",1),("b",2)))
rdd1.filter(_._2>1).collect //_表示x
rdd1.filter(x=>x._2>1).collect //第二个字段》1
rdd1.filter(x=>x._2>100).collect //删选出第二个字段大于100的
2.reduceByKey() 合并有相同键的值。一个转换操作。返回一个新的RDD
例子:定义一个含有多个相同键 对每个键的值求和
val rdd=sc.parallelize(List(("a",1),("a",2)))
val re_rdd=rdd.reduceByKey((a,b)=>a+b)
re_add.collect /查询
2.4 保存输出文件
1.saveAsTextFiles:以文本形式保存,保存到任何文件系统 saveAsTextFiles
2.saveAsObjectFiles: 序列化格式
3.saveAsHadoopFiles:以文件形式保存到HDFS上
4.saveAsSequenceFiles:

1.将输出的内容保存到hdfs中
lines.saveAsTextFiles("hdfs://le/saveAsTextFile",'txt');
2.SequenceFile的保存
rdd.saveAsSequenceFiles()
3.prefix:前缀 suffix:后缀
3.Spark-sql
3.1 case class

1.利用反射机制推断RDD模式 定义一个case class
case class Person(name:String,age:Int)
2.读取数据源 分割数据
val data=sc.textFile("/user/wang/people.txt").map(_.split(","))
3.map转化为DF
val people=data.map(p=>Person(p(0),p(1).trim.toInt)).toDF()
3.2 如何使用join/groupBy
1.groupBy 根据字段进行分组
val userGroupBy=user.groupBy("gender")
2.使用join将两张表连接在一起
join: rdd1.join(rdd2)
rightOuterJoin:右外连接 rdd1 rightOuterJoin arr2
leftOutJoin:左外连接 rdd1 lefttOuterJoin arr2
fullOuterJoin:全连接
3.3 jdbc连接数据库创建dataframe
1.在数据库中建表

2.通过jdbc连接访问数据库
val url="jdbc:mysql://localhost:3306/test"
val jdbsDF=spark.read.format("jdbc").options(
Map("url"->url,
"user"->"hive",
"password"->"hive",
"dbtable"->"student"
)
).load()
查询
jdbcDF.show
4.操作题
1.启动
启动hadoop ./start-dfs.sh
启动spark ./spark-shell
启动spark集群 ./spark-all.sh
2.上传文件
hdfs dfs -put /本地文件目录 /上传路径
3.查看目录是否创建成功
hdfs dfs -ls /
4.查看是否上传成功
hdfs dfs -cat /文件
5.创建目录
hdfs dfs -mkdir /test/input
hdfs dfs -mkdir /test/input
6.删除
删除文件
hdfs dfs -rm /文件目录
删除文件夹
hdfs dfs -rm -r /文件夹目录
7.下载文件到本地
hdfs dfs -get /hdfs路径 /本地路径
8.提交到集群
./spark-submit --master yarn-cluster --class 程序入口 jar包路径 输入文件路径 输出文件路径
./spark-submit --master yarn-cluster --class demo.spark.WorldCount /opt/word.jar /user/root/words.txt /user/root/word_count
数据库操作
1.启动Hive的metastore
hive --service metastore &
2.登录
mysql -uroot -p
3.创建表
create table student(id int,name string)
4.使用spark.sql()执行sql语句
saprk.sql("show database").show()
DataFrame操作·
1.加载parquet文件为DataFrame 结构化数据创建DataFrame
var dfusers=spark.read.load("")
2.json-->dataframe json()
val dfPeople=spark.read.json("josn文件名")
val dfPeople1=spark.read.format("json").load("../data.json")
4.Spark-Streaming
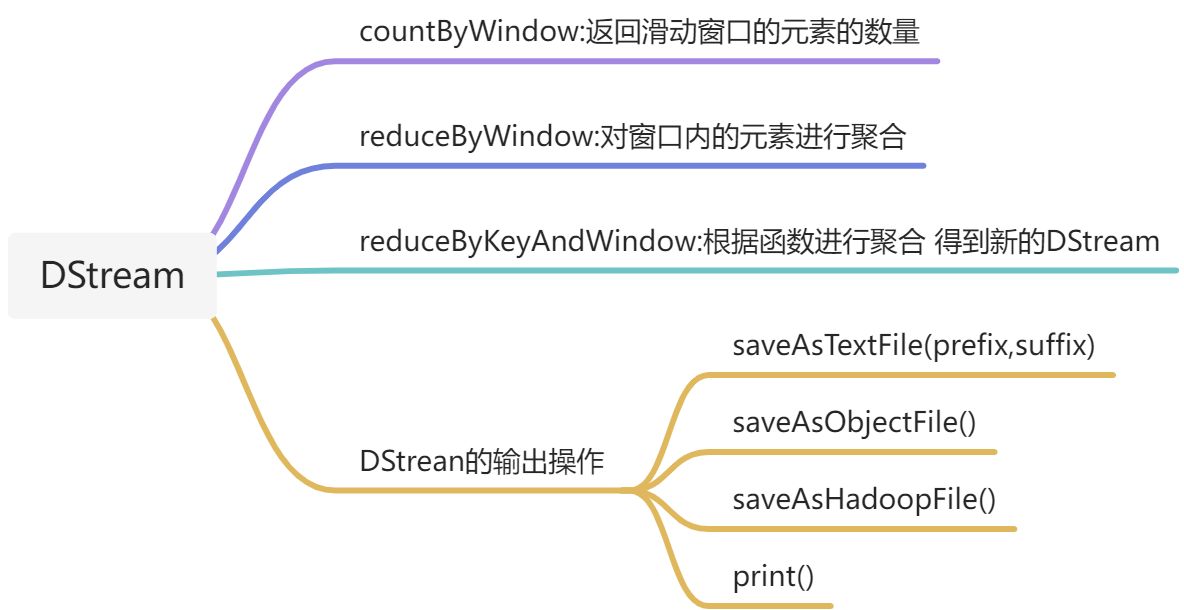
1.监控hdfs文件系统
val lines=ssc.textFileStream("home/wang/streaming/data")
3.window参数
val windowWords=words.window(Seconds(3),Seconds(1))
4.socket连接
val ssc=new StreamingContext(sc,Seconds(5))
val lines=ssc.socketTextStream("localhost",8888)
5.reduceByKeyAndWindow 与reduceByKey不同在于基于DStream的窗口长度中的所有数据
相同键求和 窗口长度为3 时间间隔为1
val windowWords=pairs.reduceByKeyAndWindow((a;Int,b:Int)=>a+b,Seconds(3),Seconds(1))
8.启动
ssc.start();
ssc.awaitTermination() //等待子线程结束
ssc.stop()
每隔10秒钟统计最近60秒的热点热搜词的搜索频率

val lines=ssc.socketTextStream("localhost",8888) //连接输入数据流
val words=lines.flatMap(_.split(" ")) //将数据分割
//设置窗口长度 滑动时间间隔
val windowWords=words.map(x=>x._1).reduceByKeyAndWindow((a:Int,b:Int)=>a+b),Seconds(60),Seconds(10)
2.排序 DStream operation :transfrom
val hottestWords=windowWords.transform(rdd=>{rdd.sort(_._2,false)})
//取前十打印出来
hottestWords.foreachRDD(_.take(10).foreach(println))
//start spark-streaming
ssc.start()
ssc.awaitTermination() //等待子线程结束
ssc.stop()
网页热度排序 transform

val hottestHtml=htmlCount.transfrom(rdd=>{
val top10=rdd.sortBy(_._2,false).take(10);
sc.makeRDD(top10)
})
5.Spark机器学习
5.1 常见的机器学习方法叫什么名字 模型
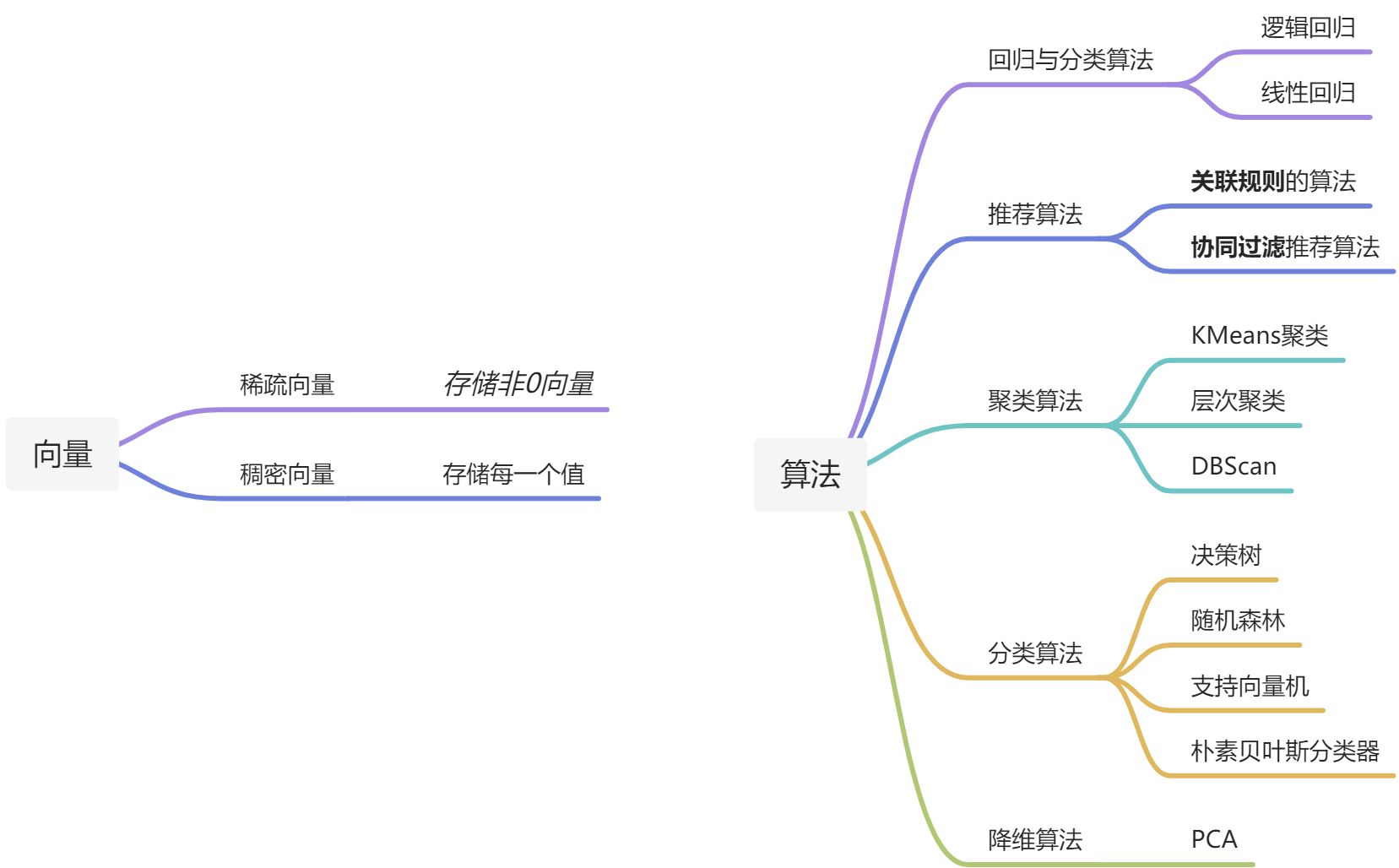
5.2 向量怎么来定义 稀疏的 稠密的

5.3 如何用模型来预测


1.
IrModel.predict(testValue)
2.
val model=new NaiveBayes().fit(trainingdata)
val predict=model.transform(testData)
5.4 如何加载数据 怎么把数据加载进去

5.5 如何拟合模型

val lsvcModel=lsvc.fit(trainng
6 Scala语法
1.定义函数
def functionName:(参数列表):[return type]={
}
def add(a:Int,b:Int):Int={
var sum=0;
sum=a+b;
return sum;
}
如果方法定义在类中,通过 类名.方法名(参数列表) 调用
2.定义类
class classname(参数列表){
}
class Point(xc:Int,yc:Int){
var x:Int=xc;
var y:Int=yc;
//定义函数
def move(dx:Int,dy:Int){
x=x+dx;
y=y+dy;
}
}

若有收获,就点个赞吧
0 人点赞
