ready to translate : https://developers.itextpdf.com/content/itext-7-jump-start-tutorial/chapter-7-creating-pdfua-and-pdfa-documents
第7章:创建PDF/UA和PDF/A文档
在第1章到第4章中,我们使用iText 7创建了PDF文档。在第5章和第6章中,我们操纵和重用了现有的PDF文档。我们在这些章节中处理的所有PDF都是符合ISO 32000(这是PDF的核心标准)的PDF文档。 ISO 32000不是PDF的唯一ISO标准,有许多不同的子标准是出于特定的原因而创建的。在本章中,我们将重点介绍两个标准:
ISO 14289也被称为PDF / UA。 UA代表通用可访问性。符合PDF / UA标准的PDF文件可供任何人使用,包括失明或视障人士。
ISO 19005也被称为PDF / A。 A代表归档。这个标准被创建的目标是实现数字文件的长期保存。
在本章中,我们将通过创建一系列PDF / A和PDF / UA文件来了解它们两者的更多信息。
创建可访问的PDF文档
在我们开始PDF / UA的例子之前,让我们仔细看看接下来想要解决的问题。在第1章中,我们创建了包含图像的文档。在“敏捷的棕色狐狸跳过懒惰的狗”的例子中,我们用代表狐狸和狗的图像替换了“狐狸”和“狗”这两个字。当这个文件被系统读取时,电脑并不知道第一个图像代表一只狐狸,而第二个图像代表一只狗,因此该文件将被读作“敏捷的棕色跳过懒惰”。
在普通的PDF中,内容被绘制到画布上。我们可以使用List和Table等高级对象,但一旦创建了PDF,就没有结构了。列表是一系列行,列表项中的文本片段不知道它是列表的一部分。表格只是一堆线条和文本添加在页面上的绝对位置。表中的文本片段不知道它属于特定列和特定行中的单元格。
In an ordinary PDF, content is painted to a canvas. We might use high-level objects such as List and Table, but once the PDF is created, there is no structure left. A list is a sequence of lines and a text snippet in a list item doesn’t know that it’s part of a list. A table is just a bunch of lines and text added at absolute positions on a page. A text snippet in a table doesn’t know it belongs to a cell in a specific column and a specific row.
除非我们使PDF成为带标签的PDF,否则文档不包含任何语义结构。当没有语义结构时,PDF不可访问。为了可访问,文档需要能够区分页面的哪一部分是实际内容,哪一部分是不是实际内容的一部分的工件(例如页眉,页码)。一行文本需要知道它的标题,是否是段落的一部分,等等。我们可以通过创建结构树并将内容定义为标记的内容来将所有这些信息添加到页面中。这听起来很复杂,但如果使用iText 7的高级对象,引入setTagged()方法就足够了。通过将PdfDocument定义为带标签的文档,我们通过使用List,Table,Paragraph等对象引入的结构将反映在Tagged PDF中。
Unless we make the PDF a tagged PDF, the document doesn’t contain any semantic structure. When there’s no semantic structure, the PDF isn’t accessible. To be accessible, the document needs to be able to distinguish which part of a page is actual content, and which part is an artifact that isn’t part of the actual content (e.g. a header, a page number). A line of text needs to know if its a title, if it’s part of a paragraph, and so on. We can add all of this information to the page, by creating a structure tree and by defining content as marked content. This sounds complex, but if you use iText 7’s high-level objects, it’s sufficient to introduce the method setTagged(). By defining a PdfDocument as a tagged document, the structure we introduce by using objects such as List, Table, Paragraph, will be reflected in the Tagged PDF.
这只是使PDF可访问的一个要求。 QuickBrownFox_PDFUA示例将帮助我们理解其他需求。
This is only one requirement to make a PDF accessible. The QuickBrownFox_PDFUA example will help us understand the other requirements.
PdfDocument pdf = new PdfDocument(new PdfWriter(dest),new WriterProperties().addXmpMetadata()));Document document = new Document(pdf);//Setting some required parameterspdf.setTagged();pdf.getCatalog().setLang(new PdfString("en-US"));pdf.getCatalog().setViewerPreferences(new PdfViewerPreferences().setDisplayDocTitle(true));PdfDocumentInfo info = pdf.getDocumentInfo();info.setTitle("iText7 PDF/UA example");//Fonts need to be embeddedPdfFont font = PdfFontFactory.createFont(FONT, PdfEncodings.WINANSI, true);Paragraph p = new Paragraph();p.setFont(font);p.add(new Text("The quick brown "));Image foxImage = new Image(ImageFactory.getImage(FOX));//PDF/UA: Set alt textfoxImage.getAccessibilityProperties().setAlternateDescription("Fox");p.add(foxImage);p.add(" jumps over the lazy ");Image dogImage = new Image(ImageFactory.getImage(DOG));//PDF/UA: Set alt textdogImage.getAccessibilityProperties().setAlternateDescription("Dog");p.add(dogImage);document.add(p);document.close();
我们创建了一个PdfDocument和一个Document,但这次我们告诉’PdfWriter’使用’WriterProperties’的’addXmpMetadata()’方法自动添加XMP元数据。在PDF / UA中,必须在PDF中以XML格式存储相同的元数据。这个XML可能不被压缩。不“理解”PDF的处理器必须能够检测到这个XMP元数据并对其进行处理。根据Info字典中的条目自动创建XMP流。这个Info字典是一个PDF对象,它包含诸如文档标题之类的数据。除了这个要求之外,我们还要确保我们遵从PDF,引入一些额外的功能:
We create a PdfDocument and a Document, but this time we tell the ‘PdfWriter’ to automatically add XMP metadata using the ‘addXmpMetadata()’ method of ‘WriterProperties’. In PDF/UA, it is mandatory to have the same metadata stored in the PDF as XML. This XML may not be compressed. Processors that don’t “understand” PDF must be able to detect this XMP metadata and process it. An XMP stream is created automatically based on the entries in the Info dictionary. This Info dictionary is a PDF Object that includes such data as the title of the document. In addition to this requirement, we make sure that we comply to PDF by introducing some extra features:
我们告诉PdfDocument,我们要创建Tagged PDF(第4行),
我们添加一个语言说明符。在我们的案例中,文件知道在这个文件中使用的主要语言是美国英语(第5行)。
我们更改查看器首选项,以便文档的标题始终显示在PDF查看器的顶部栏(第6-7行)中。显然,这意味着我们为文档的元数据添加一个标题(第8-9行)。
所有的字体都需要嵌入(第11行)。还有一些与字体有关的其他要求,但是现在我们可能会过分详细地讨论这些要求。
所有的内容需要被标记。当遇到图像时,我们需要使用替代文本提供该图像的描述(第17行和第22行)。
We tell the PdfDocument that we’re going to create Tagged PDF (line 4),
We add a language specifier. In our case, the document knows that the main language used in this document is American English (line 5).
We change the viewer preferences so that the title of the document is always displayed in the top bar of the PDF viewer (line 6-7). Obviously, this implies that we add a title to the metadata of the document (line 8-9).
All fonts need to be embedded (line 11). There are some other requirements relating to fonts, but it would lead us too far right now to discuss these in detail.
All the content needs to be tagged. When an image is encountered, we need to provide a description of that image using alt text (line 17 and line 22).
我们现在已经创建了PDF / UA文档。当我们查看图7.1中的结果页面时,我们没有看到太多的区别,但是如果我们打开“标签”面板,就会看到文档具有特定的结构。
We have now created a PDF/UA document. When we look at the resulting page in Figure 7.1, we don’t see much difference, but if we open the Tags panel, we see that the document has a specific structure.
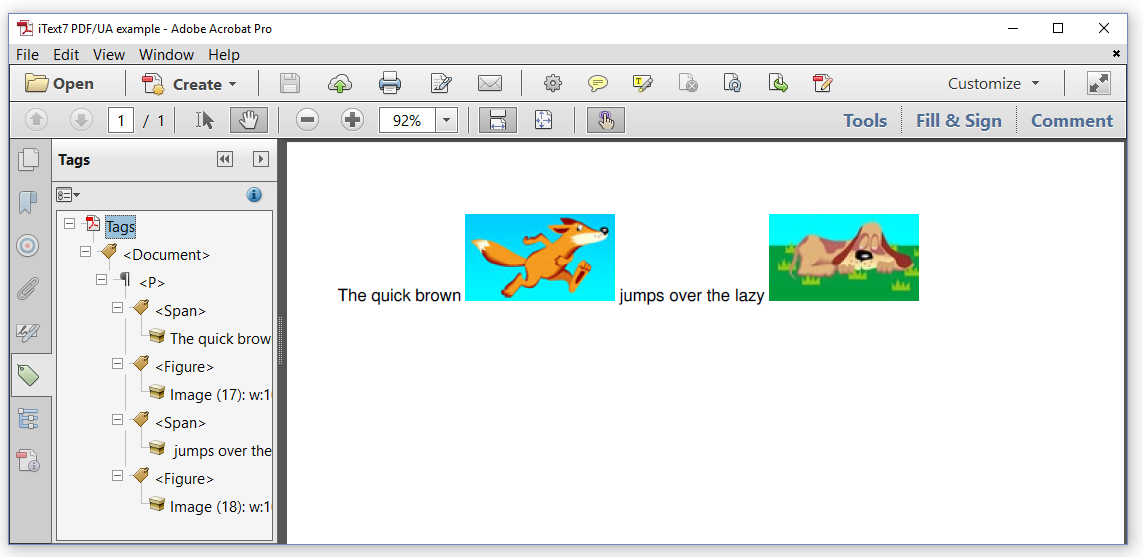
图7.1:一个PDF/UA文档及它的结构
我们看到
We see that the
aragraph that is composed of four parts, two s and two
创建长期保存的PDF(一)
ISO 19005的第1部分于2005年发布。它被定义为Adobe PDF版本1.4的一个子集(当时还不是ISO标准)。 ISO 19005-1引入了一系列义务和限制:
该文件需要自包含:所有字体需要嵌入;外部电影,声音或其他二进制文件是不允许的。
该文档需要包含可扩展元数据平台(XMP)格式的元数据:ISO 16684(XMP)描述了如何将XML元数据嵌入到二进制文件中,以便不知道如何解释二进制数据格式的软件仍然可以提取文件的元数据。
不允许面向未来的功能:PDF不能包含任何JavaScript,并且可能不会被加密。
Part 1 of ISO 19005 was released in 2005. It was defined as a subset of version 1.4 of Adobe’s PDF specification (which, at that time, wasn’t an ISO standard yet). ISO 19005-1 introduced a series of obligations and restrictions:
The document needs to be self-contained: all fonts need to be embedded; external movie, sound or other binary files are not allowed.
The document needs to contain metadata in the eXtensible Metadata Platform (XMP) format: ISO 16684 (XMP) describes how to embed XML metadata into a binary file, so that software that doesn’t know how to interpret the binary data format can still extract the file’s metadata.
Functionality that isn’t future-proof isn’t allowed: the PDF can’t contain any JavaScript and may not be encrypted.
ISO 19005-1:2005(PDF / A-1)定义了两个一致性等级:
B级(“基本”):确保文件的外观长期保存。
A级(“可访问”):确保文档的视觉外观长期保存,同时引入结构和语义特性。 PDF需要是一个标签PDF。
QuickBrownFox_PDFA_1b示例显示了我们如何创建符合PDF / A-1b的“Quick brown fox”PDF。
ISO 19005-1:2005 (PDF/A-1) defined two conformance levels:
Level B (“basic”): ensures that the visual appearance of a document will be preserved for the long term.
Level A (“accessible”): ensures that the visual appearance of a document will be preserved for the long term, but also introduces structural and semantic properties. The PDF needs to be a Tagged PDF.
The QuickBrownFox_PDFA_1b example shows how we can create a “Quick brown fox” PDF that complies to PDF/A-1b.
//Initialize PDFA document with output intentPdfADocument pdf = new PdfADocument(new PdfWriter(dest),PdfAConformanceLevel.PDF_A_1B,new PdfOutputIntent("Custom", "", "http://www.color.org","sRGB IEC61966-2.1", new FileInputStream(INTENT)));Document document = new Document(pdf);//Fonts need to be embeddedPdfFont font = PdfFontFactory.createFont(FONT, PdfEncodings.WINANSI, true);Paragraph p = new Paragraph();p.setFont(font);p.add(new Text("The quick brown "));Image foxImage = new Image(ImageFactory.getImage(FOX));p.add(foxImage);p.add(" jumps over the lazy ");Image dogImage = new Image(ImageFactory.getImage(DOG));p.add(dogImage);document.add(p);document.close();
跳转到眼前的第一件事就是我们不再使用PdfDocument实例。相反,我们创建一个PdfADocument实例。 PdfADocument构造函数需要一个PdfWriter作为它的第一个参数,而且还需要一致性级别(在本例中为PdfAConLevel.PDF_A_1B)和一个PdfOutputIntent。这个输出意图告诉文档如何解释将在文档中使用的颜色。在第10行中,我们确保我们使用的字体是嵌入的。
The first thing that jumps to the eye, is that we are no longer using a PdfDocument instance. Instead, we create a PdfADocument instance. The PdfADocument constructor needs a PdfWriter as its first parameter, but also a conformance level (in this case PdfAConformanceLevel.PDF_A_1B) and a PdfOutputIntent. This output intent tells the document how to interpret the colors that will be used in the document. In line 10, we make sure that the font we’re using is embedded.
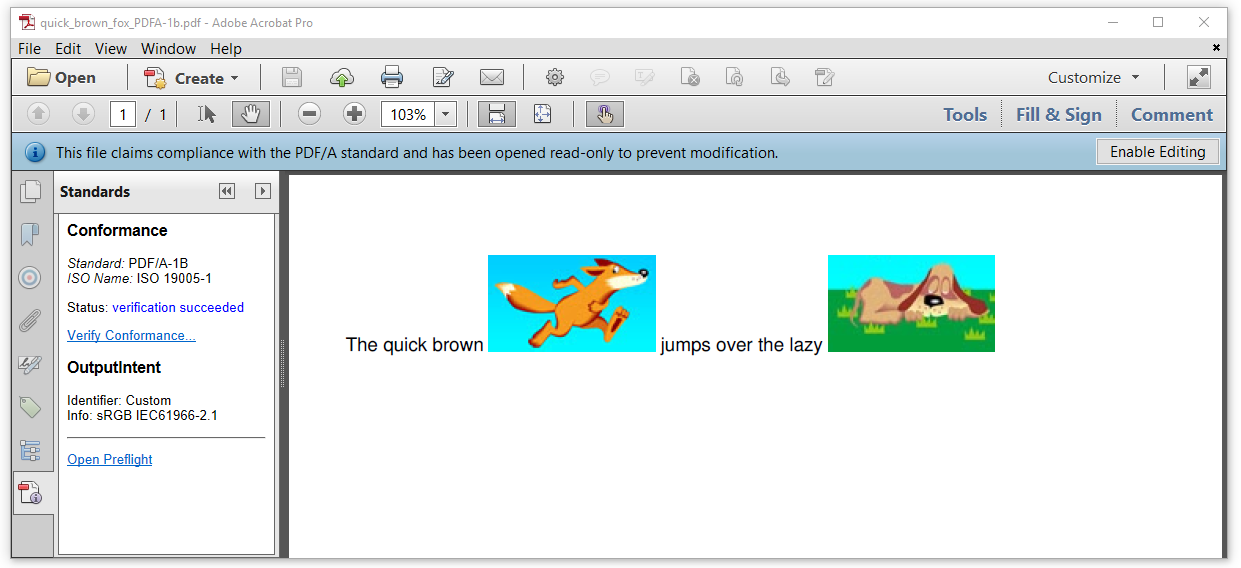
图7.2:一个PDF/A-1的B级文档
查看图7.2所示的PDF文件,我们看到一个蓝色的带子,上面写着“该文件声明符合PDF / A标准,并且已经以只读方式打开以防止修改”。请允许我解释关于这句话的两件事情:
1.这并不意味着PDF实际上符合PDF / A标准。它只是声称它是。可以肯定的是,您需要在Adobe Acrobat中打开“标准”面板。当您单击“验证一致性”链接时,Acrobat将验证文档是否是自称的。在这种情况下,我们读取“状态:验证成功”;我们已经成功创建了符合PDF / A-1B的文件。
2.文档已经以只读方式打开,并不是因为不允许修改(PDF / A不能保护PDF不被修改),而是Adobe Acrobat以只读的方式显示,因为任何修改都可能会改变将PDF转换为不再符合PDF / A标准的PDF。在不破坏PDF / A状态的情况下更新PDF / A并不是微不足道的。
让我们修改我们的示例,并使用QuickBrownFox_PDFA_1a示例创建一个PDF / A-1级别的文档。
Looking at the PDF shown in Figure 7.2, we see a blue ribbon with the text “This file claims compliance with the PDF/A standard and has been opened read-only to prevent modification.” Allow me to explain two things about this sentence:
This doesn’t mean that the PDF is, in effect, compliant with the PDF/A standard. It only claims it is. To be sure, you need to open the Standards panel in Adobe Acrobat. When you click on the “Verify Conformance” link, Acrobat will verify if the document is what it claims to be. In this case, we read “Status: verification succeeded”; we have successfully created a document complying with PDF/A-1B.
The document has been opened read-only, not because you are not allowed to modify it (PDF/A is not a way to protect a PDF against modification), but Adobe Acrobat presents it as read-only because any modification might change the PDF into a PDF that is no longer compliant to the PDF/A standard. It’s not trivial to update a PDF/A without breaking its PDF/A status.
Let’s adapt our example, and create a PDF/A-1 level A document with the QuickBrownFox_PDFA_1a example.
//Initialize PDFA document with output intentPdfADocument pdf = new PdfADocument(new PdfWriter(dest),PdfAConformanceLevel.PDF_A_1A,new PdfOutputIntent("Custom", "", "http://www.color.org","sRGB IEC61966-2.1", new FileInputStream(INTENT)));Document document = new Document(pdf);//Setting some required parameterspdf.setTagged();//Fonts need to be embeddedPdfFont font = PdfFontFactory.createFont(FONT, PdfEncodings.WINANSI, true);Paragraph p = new Paragraph();p.setFont(font);p.add(new Text("The quick brown "));Image foxImage = new Image(ImageFactory.getImage(FOX));//Set alt textfoxImage.getAccessibilityProperties().setAlternateDescription("Fox");p.add(foxImage);p.add(" jumps over the lazy ");Image dogImage = new Image(ImageFactory.getImage(DOG));//Set alt textdogImage.getAccessibilityProperties().setAlternateDescription("Dog");p.add(dogImage);document.add(p);document.close();
我们已经在第3行中将PdfAConformanceLevel.PDF_A_1B更改为PdfAConformanceLevel.PDF_A_1A。我们已经使PdfADocument成为标签PDF(第8行),并且为图像添加了一些替代文本。图7.3有些混乱。
We’ve changed PdfAConformanceLevel.PDF_A_1B into PdfAConformanceLevel.PDF_A_1A in line 3. We’ve made the PdfADocument a Tagged PDF (line 8) and we’ve added some alt text for the images. Figure 7.3 is somewhat confusing.
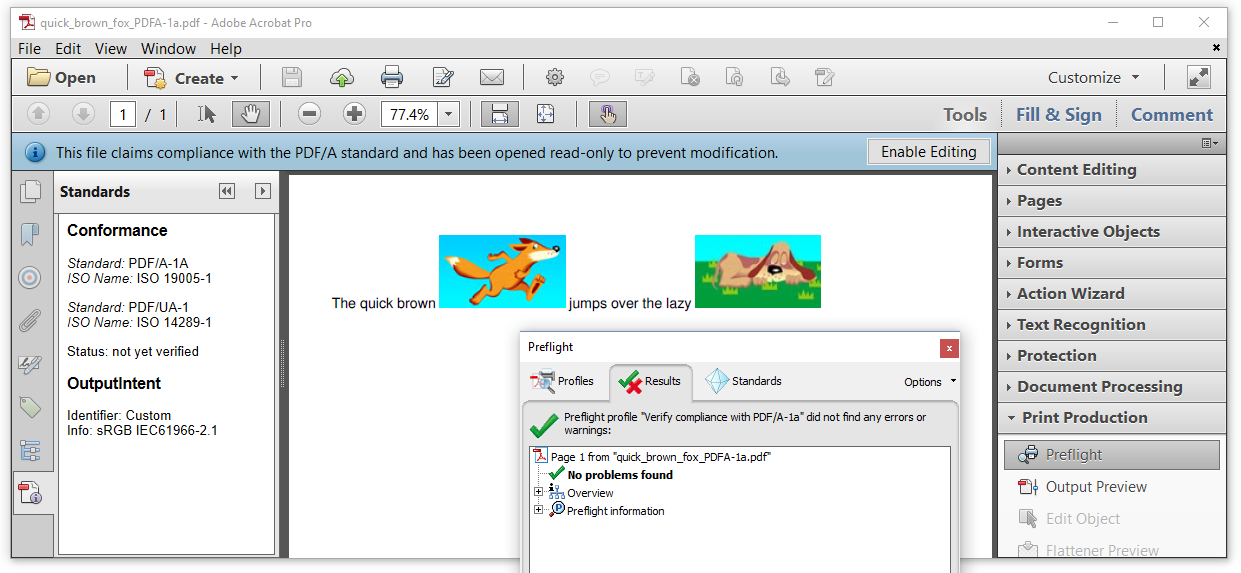
图7.3: 一个PDF/A-1的A级文档
当我们看标准面板时,我们看到文档认为它符合PDF / A-1A和PDF / UA-1。我们没有“验证一致性”链接,所以我们必须使用预检。在执行“验证PDF / A-1a符合性”配置文件时,预检通知我们“没有发现问题”。我们无法验证PDF / UA合规性,因为PDF / UA涉及一些无法通过计算机验证的要求。例如:如果我们将狐狸形象的描述与狗的形象描述切换,机器就不会注意到。这将使文件无法访问,因为文件会根据屏幕阅读器向人们传播虚假信息。无论如何,我们知道我们的文档不符合PDF / UA标准,因为我们省略了一些基本要素(如语言)。
从一开始就确定ISO 19005的认可部分永远不会失效。新的,后续的部分只会定义新的有用的功能。第二部分和第三部分创建时就是这样。
When we look at the Standards panel, we see that the document thinks it conforms to PDF/A-1A and to PDF/UA-1. We don’t have a “Verify Conformance” link, so we have to use Preflight. Preflight informs us that there were “No problems found” when executing the “Verify compliance with PDF/A-1a” profile. We can’t verify the PDF/UA compliance because PDF/UA involves some requirements that can’t be verified by a machine. For instance: a machine wouldn’t notice if we switched the description of the image of the fox with the description of the image of the dog. That would make the document inaccessible as the document would spread false information to people depending on screen-readers. In any case, we know that our document doesn’t comply to the PDF/UA standard because we omitted a number of essential elements (such as the language).
From the start, it was determined that approved parts of ISO 19005 could never become invalid. New, subsequent parts would only define new, useful features. That’s what happened when part 2 and part 3 were created.
为长期保存创建PDF(二、三)
ISO 19005-2:2011(PDF / A-2)引入了基于ISO标准(ISO 32000-1)而不是Adobe PDF规范的PDF / A标准。 PDF / A-2还增加了一些在PDF 1.5,1.6和1.7中引入的功能:
有用的补充包括:支持JPEG2000,集合,对象级XMP和可选内容。
有用的改进包括:更好地支持透明度,评论类型和注释以及数字签名。
PDF / A-2还定义了除A级和B级之外的额外级别:
- U级(“Unicode”):确保文档的可视外观长期保存,并且所有文本都以UNICODE存储。
ISO 19005-3:2012(PDF / A-3)与PDF / A-2几乎完全相同。与PDF / A-2只有一个区别:在PDF / A-3中,附件不需要是PDF / A。您可以将任何文件附加到PDF / A-3,例如:一个包含在文档中使用结果的计算的XLS文件,用于创建PDF文档的原始Word文档等等。文件本身需要符合PDF / A规范的所有义务和限制,但这些义务和限制不适用于其附件。
在UnitedStates_PDFA_3a示例中,我们将创建一个符合PDF / UA以及PDF / A-3A的文档。我们选择PDF / A3,因为我们将添加用作创建PDF的源文件的CSV文件。
ISO 19005-2:2011 (PDF/A-2) was introduced to have a PDF/A standard that was based on the ISO standard (ISO 32000-1) instead of on Adobe’s PDF specification. PDF/A-2 also adds a handful of features that were introduced in PDF 1.5, 1.6 and 1.7:
Useful additions include: support for JPEG2000, Collections, object-level XMP, and optional content.
Useful improvements include: better support for transparency, comment types and annotations, and digital signatures.
PDF/A-2 also defines an extra level besides Level A and Level B:
- Level U (“Unicode”): ensures that the visual appearance of a document will be preserved for the long term, and that all text is stored in UNICODE.
ISO 19005-3:2012 (PDF/A-3) was an almost identical copy of PDF/A-2. There was only one difference with PDF/A-2: in PDF/A-3, attachments don’t need to be PDF/A. You can attach any file to a PDF/A-3, for instance: an XLS file containing calculations of which the results are used in the document, the original Word document that was used to create the PDF document, and so on. The document itself needs to conform to all the obligations and restrictions of the PDF/A specification, but these obligations and restrictions do not apply to its attachments.
In the UnitedStates_PDFA_3a example, we’ll create a document that complies with PDF/UA as well as with PDF/A-3A. We choose PDF/A3, because we’re going to add the CSV file that was used as the source for creating the PDF.
PdfADocument pdf = new PdfADocument(new PdfWriter(dest),PdfAConformanceLevel.PDF_A_3A,new PdfOutputIntent("Custom", "", "http://www.color.org","sRGB IEC61966-2.1", new FileInputStream(INTENT)));Document document = new Document(pdf, PageSize.A4.rotate());//Setting some required parameterspdf.setTagged();pdf.getCatalog().setLang(new PdfString("en-US"));pdf.getCatalog().setViewerPreferences(new PdfViewerPreferences().setDisplayDocTitle(true));PdfDocumentInfo info = pdf.getDocumentInfo();info.setTitle("iText7 PDF/A-3 example");//Add attachmentPdfDictionary parameters = new PdfDictionary();parameters.put(PdfName.ModDate, new PdfDate().getPdfObject());PdfFileSpec fileSpec = PdfFileSpec.createEmbeddedFileSpec(pdf, Files.readAllBytes(Paths.get(DATA)), "united_states.csv","united_states.csv", new PdfName("text/csv"), parameters,PdfName.Data, false);fileSpec.put(new PdfName("AFRelationship"), new PdfName("Data"));pdf.addFileAttachment("united_states.csv", fileSpec);PdfArray array = new PdfArray();array.add(fileSpec.getPdfObject().getIndirectReference());pdf.getCatalog().put(new PdfName("AF"), array);//Embed fontsPdfFont font = PdfFontFactory.createFont(FONT, true);PdfFont bold = PdfFontFactory.createFont(BOLD_FONT, true);// Create contentTable table = new Table(new float[]{4, 1, 3, 4, 3, 3, 3, 3, 1});table.setWidthPercent(100);BufferedReader br = new BufferedReader(new FileReader(DATA));String line = br.readLine();process(table, line, bold, true);while ((line = br.readLine()) != null) {process(table, line, font, false);}br.close();document.add(table);//Close documentdocument.close();
我们来看看这个例子的不同部分。
- 1-5行:我们创建一个PDF文档(PdfAConformanceLevel.PDF_A_3A)和一个文档。
*第7行:使PDF成为标签PDF是PDF / UA以及PDF / A-3A的必备条件。
*第8-12行:设置语言,文档标题和查看者偏好以显示标题是PDF / UA的要求。
*第14-20行:我们使用PDF / A-3A所需的特定参数添加文件附件。
*第26-27行:我们嵌入PDF / UA和PDF / A要求的字体。
*第28-38行:我们已经在第1章的美国示例中看到过这个代码(包括process()方法)。
*第40行:我们关闭文件。
图7.4演示了如何将Cell类对象作为标题单元格添加到Table类中,并将Cell对象作为普通单元格添加,从而生成一个使PDF文档可访问的结构树。
Let’s examine the different parts of this example.
Line 1-5: We create a PdfADocument (PdfAConformanceLevel.PDF_A_3A) and a Document.
Line 7: Making the PDF a Tagged PDF is a requirement for PDF/UA as well as for PDF/A-3A.
Line 8-12: Setting the language, the document title and the viewer preference to display the title is a requirement for PDF/UA.
Line 14-20: We add a file attachment using specific parameters that are required for PDF/A-3A.
Line 26-27: We embed the fonts which is a requirement for PDF/UA as well as for PDF/A.
Line 28-38: We’ve seen this code before in the UnitedStates example in chapter 1 (including the process() method).
Line 40: We close the document.
Figure 7.4 demonstrates how using the Table class with Cell objects added as header cells, and Cell objects added as normal cells, resulted in a structure tree that makes the PDF document accessible.
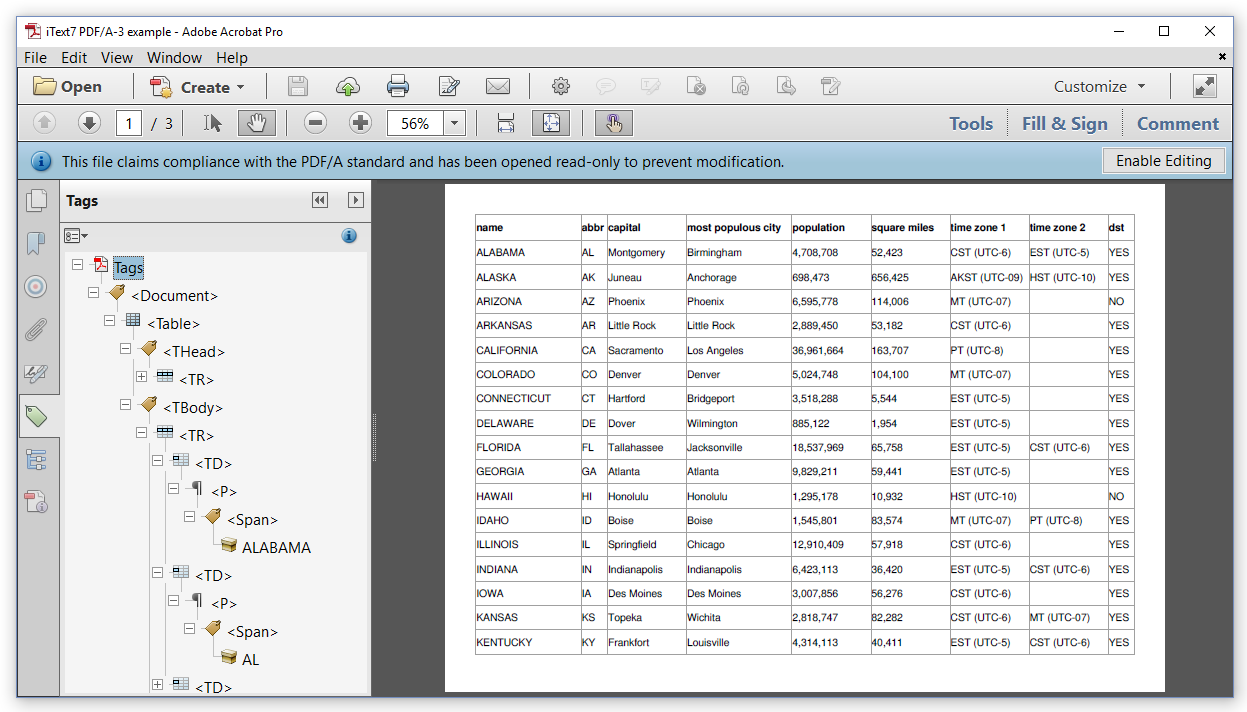
图7.4:一个PDF/A-3的A级文档
当我们打开附件面板如图7.5所示时,我们看到了我们可以从PDF中轻松提取的原始的united_states.csv文件。
When we open the Attachments panel as shown in Figure 7.5, we see our original united_states.csv file that we can easily extract from the PDF.
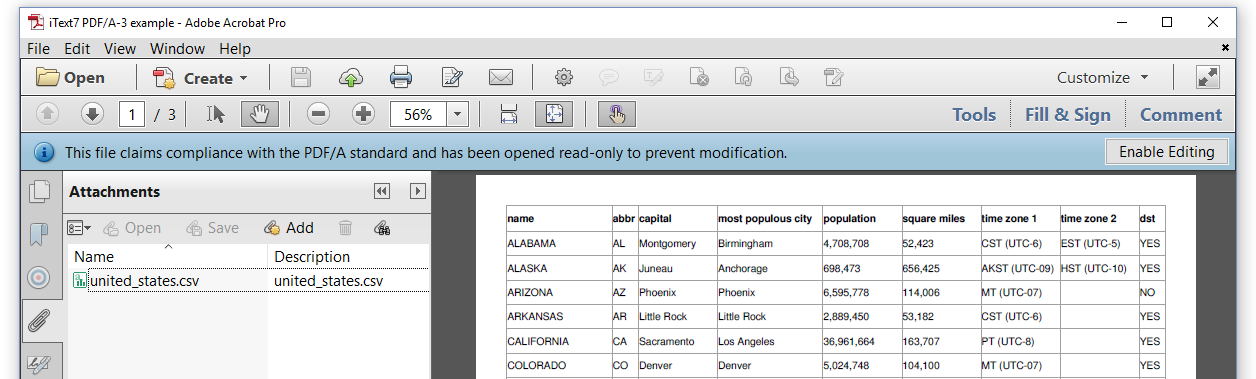
图7.5:一个PDF/A-3的A级文档及附件
本章中的例子告诉我们,与普通PDF相比,PDF / UA或PDF / A文档需要额外的要求。 “我们可以使用iText将现有PDF转换为PDF / UA或PDF / A文档”是经常在邮件列表或用户论坛上发布的问题。我希望这一章解释iText不能自动完成这个。
如果您的文件有狐狸和狗的图片,iText不能为这些图片添加任何缺失的替代文字,因为iText不能看到狐狸和那只狗。 iText只能看像素,不能解释图像。
如果您使用的是未嵌入的字体,iText不知道该字体是什么样的。如果你没有提供相应的字体程序,iText不能嵌入该字体。
这些只是两个很好的例子,解释了为什么将一个普通的PDF转换成PDF / A或PDF / UA不是微不足道的。改变PDF文件非常简单,因为它显示了一个蓝色的条,表示文档符合PDF / A,但是这并不是那么正确。
当我们合并现有的PDF / A文档时,我们也需要注意。
The examples in this chapter taught us that PDF/UA or PDF/A documents involve extra requirements when compared to ordinary PDFs. “Can we use iText to convert an existing PDF to a PDF/UA or PDF/A document” is a question that is posted frequently on mailing-lists or user forums. I hope that this chapter explains that iText can’t do this automatically.
If you have a document that has a picture of a fox and a dog, iText can’t add any missing alt text for those images, because iText can’t see that fox nor that dog. iText only sees pixels, it can’t interpret the image.
If you are using a font that isn’t embedded, iText doesn’t know what that font looks like. If you don’t provide the corresponding font program, iText can never embed that font.
These are only two examples of many that explain why converting an ordinary PDF to PDF/A or PDF/UA isn’t trivial. It’s very easy to change the PDF so that it shows a blue bar saying that the document complies to PDF/A, but that doesn’t many that claim is true.
We also need to pay attention when we merge existing PDF/A documents.
合并PDF/A文档
合并PDF / A文档时,添加到PdfMerger中的每个文档都已经是PDF / A文档,这一点非常重要。您不能将PDF / A文档和普通PDF文档混合到一个PDF中,并希望得到的结果将是PDF / A文档。将PDF / A级别文档与PDF / A级别B文档混合也是如此。一个是结构树,另一个是没有的;你不能期望得到的PDF是一个PDF / A级别的文件。
图7.6显示了我们如何合并我们在前面章节中创建的两个PDF / A级别的文档。
When merging PDF/A documents, it’s very important that every single document that you are adding to PdfMerger is already a PDF/A document. You can’t mix PDF/A documents and ordinary PDF documents into one single PDF and hope the result will be a PDF/A document. The same is true for mixing a PDF/A level A document with a PDF/A level B document. One has a structure tree, the other hasn’t; you can’t expect the resulting PDF to be a PDF/A level A document.
Figure 7.6 shows how we merged the two PDF/A level A documents we created in the previous sections.
图7.6:合并2个PDF/A的A级文档
当我们看标签的结构时,我们看到
aragraph现在跟着一个
。 MergePDFADocuments显示如何完成。When we look at the structure of the tags, we see that the
aragraph is now followed by a
PdfADocument pdf = new PdfADocument(new PdfWriter(dest),PdfAConformanceLevel.PDF_A_1A,new PdfOutputIntent("Custom", "", "http://www.color.org","sRGB IEC61966-2.1", new FileInputStream(INTENT)));//Setting some required parameterspdf.setTagged();pdf.getCatalog().setLang(new PdfString("en-US"));pdf.getCatalog().setViewerPreferences(new PdfViewerPreferences().setDisplayDocTitle(true));PdfDocumentInfo info = pdf.getDocumentInfo();info.setTitle("iText7 PDF/A-1a example");//Create PdfMerger instancePdfMerger merger = new PdfMerger(pdf);//Add pages from the first documentPdfDocument firstSourcePdf = new PdfDocument(new PdfReader(SRC1));merger.addPages(firstSourcePdf, 1, firstSourcePdf.getNumberOfPages());//Add pages from the second pdf documentPdfDocument secondSourcePdf = new PdfDocument(new PdfReader(SRC2));merger.addPages(secondSourcePdf, 1, secondSourcePdf.getNumberOfPages());//Mergemerger.merge();//Close the documentsfirstSourcePdf.close();secondSourcePdf.close();pdf.close();
这个例子是用我们以前见过的两个例子的一部分来组装的:
*第1到第11行几乎与我们在前一节中使用的UnitedStates_PDFA_3a示例的第一部分相同,只是我们现在使用PdfAConLevel.PDF_A_1A,并且我们不需要Document对象。
*第12至25行与前一章的88th_Oscar_Combine示例的最后一部分相同。请注意,我们使用PdfDocument实例而不是PdfADocument; PdfADocument将检查源文件是否符合。
关于PDF / UA和PDF / A还有更多要说的,甚至关于其他的子标准。例如:有一个名为ZUGFeRD的德国开票标准,建立在PDF / A-3的基础之上,但是我们将其另存为另一个教程。
This example is assembled using parts of two examples we’ve already seen before:
Lines 1 to 11 are almost identical to the first part of the UnitedStates_PDFA_3a example we’ve used in the previous section, except that we now use PdfAConformanceLevel.PDF_A_1A and that we don’t need a Document object.
Lines 12 to 25 are identical to the last part of the 88th_Oscar_Combine example of the previous chapter. Note that we use a PdfDocument instance instead of a PdfADocument; the PdfADocument will check if the source documents comply.
There’s a lot more to be said about PDF/UA and PDF/A, and even about other sub-standards. For instance: there’s a German standard for invoicing called ZUGFeRD that is built on top of PDF/A-3, but let’s save that for another tutorial.
总结
在这一章中,我们发现PDF的内容远不止于眼前。我们已经学会了如何将结构引入到我们的文档中,以便盲人和视障人士可以使用它们。我们还确保我们的PDF是自包含的,例如通过嵌入字体,以便我们的文档可以长期存档。
我们还需要其他几个教程来更深入地介绍本教程中涵盖的功能,但这七章应该已经给您一个关于iText 7可以做什么的好印象。
In this chapter, we’ve discovered that there’s more to PDF than meets the eye. We’ve learned how to introduce structure into our documents so that they are accessible for the blind and the visually impaired. We’ve also made sure that our PDFs were self-contained, for instance by embedding fonts, so that our documents can be archived for the long term.
We’ll need several other tutorials to cover the functionality covered in this tutorial in more depth, but these seven chapters should already give you a good impression of what you can do with iText 7.

若有收获,就点个赞吧
0 人点赞
