第02讲:Hadoop:集群的操作系统
在上个课时中我们提到,Google 在 2004~2006 年发表了被称为 Google 三驾马车的 3 篇论文,这在开源社区可谓是一石激起千层浪。很快,基于论文的开源实现就问世了,其中第 1 篇论文的 GFS 和第 2 篇论文的 MapReduce 开源实现为 HDFS 与 MapReduce,统称为 Hadoop,第 3 篇 Bigtable 论文开源实现为 HBase,本课时不展开讨论。
Hadoop 的出现,对于坐拥数据而苦于无法分析的用户来说,无疑是久旱逢甘霖,加之那段时间移动互联网的流行,数据呈几何倍数增长,Hadoop 在很大程度上解决了数据处理的痛点。在很长的一段时间里,Hadoop 是大数据处理的事实标准,直到现在,很多公司的大数据处理架构也是围绕 Hadoop 而建的。
基于此,本课时主要讨论以下几个问题:
- Hadoop 1.0
- Hadoop 2.0
- Hadoop 生态圈与发行版
- Hadoop 大数据平台
- Hadoop 的趋势
Hadoop 1.0
Hadoop 从问世至今一共经历了 3 个大版本,分别是 1.0、2.0 与最新的 3.0,其中最有代表性的是 1.0 与 2.0,3.0 相比于 2.0 变化不大。Hadoop 1.0 的架构也比较简单,基本就是按照论文中的框架实现,其架构如下图所示:

其中,下层是 GFS 的开源实现 HDFS(Hadoop 分布式文件系统),上层则是分布式计算框架 MapReduce,这样一来,分布式计算框架基于分布式文件系统,看似非常合理。但是,在使用的过程中,这个架构还是会出现不少问题,主要有 3 点:
- 主节点可靠性差,没有热备;
- 提交 MapReduce 作业过多的情况下,调度将成为整个分布式计算的瓶颈;
- 资源利用率低,并且不能支持其他类型的分布式计算框架。
第 1 点是小问题,涉及到对系统可用性方面的改造,但是第 2 点与第 3 点提到的问题就比较犀利了。
第 2 个问题在于,Hadoop 1.0 的分布式计算框架 MapReduce 并没有将资源管理和作业调度这两个组件分开,造成当同时有多个作业提交的时候,资源调度器会不堪重负,导致资源利用率过低;第 3 个问题则是不支持异构的计算框架,这是什么意思呢?其实当时 Spark 已经问世了,但是如果这个集群部署了 Hadoop 1.0,那么想要运行 Spark 作业就必须另外再部署一个集群,这样无疑是对资源的浪费,很不合理,不过这也没办法,因为这属于直接套用论文造成的历史遗留问题。
Hadoop 2.0
基于这些问题,社区开始着手 Hadoop 2.0 的开发,Hadoop 2.0 最大的改动就是引入了资源管理与调度系统 YARN,代替了原有的计算框架,而计算框架则变成了类似于 YARN 的用户,如下图:

YARN 将集群内的所有计算资源抽象成一个资源池,资源池的维度有两个:CPU 和内存。同样是基于 HDFS,我们可以认为 YARN 管理计算资源,HDFS 管理存储资源。上层的计算框架地位也大大降低,变成了 YARN 的一个用户,另外,YARN 采取了双层调度的设计,大大减轻了调度器的负担,我会在后续课程详细讲解,这里不展开讨论。
Hadoop 2.0 基本上改进了 Hadoop 的重大缺陷,此外 YARN 可以兼容多个计算框架,如 Spark、Storm、MapReduce 等,HDFS 也变成了很多系统底层存储,Hadoop 以一种兼收并蓄的态度网罗了一大批大数据开源技术组件,逐渐形成了一个庞大的生态圈,如下图所示(该图只展示了一部分组件)。在当时,如果你要想搭建一个大数据平台,绝对无法绕过 Hadoop。
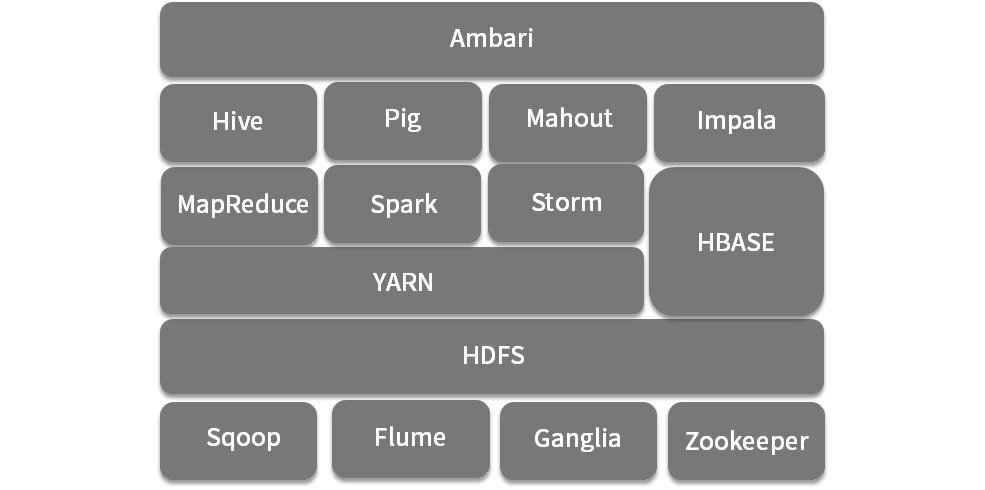
Hadoop 生态圈与发行版
Hadoop 生态圈的各个组件包含了 Hadoop 的核心组件,如 HDFS、YARN。在计算层也有了更多的选择,如支持 SQL 的 Hive、Impala,以及 Pig、Spark、Storm 等。还有些工具类的组件,比如负责批量数据抽取的 Sqoop,负责流式数据传输的 Flume,负责分布式一致性的 Zookeeper。此外,还有一些运维类组件,例如负责部署的 Ambari、集群监控的 ganglia 等。这些组件看似繁杂,但都是一个生产环境的所必需的。所以在当时,将如此多的组件集成到一个平台,会有很多各式各样的问题。
很快有公司注意到了这个问题中的商机,其中做的最好的是 Cloudera 和 Hortonworks 这两家公司,它们核心产品就是将上述 Hadoop 生态圈中最常用到的开源组件打包为一个 Hadoop 发行版,Clouera 的叫 CDH,Hortonworks 的叫 HDP,这个发行版中的所有组件不会有兼容性等其他莫名其妙的问题,供用户免费使用,当然也为那些技术实力不强的公司准备了收费版。
在 Hadoop 最鼎盛的阶段,几乎所有公司的大数据平台都使用了这两家公司的 Hadoop 发行版,Cloudera 也得到了资本市场的认可,一度估值 50 亿美金,但随着 Hadoop 的没落,Cloudera 在上市后,股价一直缩水,最后与同样是上市公司的 Hortonworks 进行了合并,合并后的股价仅有 20 亿美金。值得一提的是,Hadoop 之父 Doug Cutting 也是是Cloudera 公司的成员。


Hadoop 大数据平台
学习大数据的时候,你可能习惯把 Hadoop 与原有的应用开发那一套进行类比,但会发现没办法完全对应上,例如Hadoop确实能够用来存储数据,那么Hadoop就是数据库了吗?而很多文章在提到Hadoop的时候,有时会用大数据平台、数据仓库、分布式数据库、分布式计算框架等字眼,看似合理,但又不完全正确,让人非常迷惑。
这里,我对 Hadoop 做一个简单的解释。举例来说,在做传统应用开发的时候,我们不会过多的关注磁盘驱动器,这是因为文件系统已经帮我们进行了抽象,我们只需要使用文件系统 API 就可以操作磁盘驱动器。
同样的,我们在开发应用时也无需关注 CPU 的使用时间,操作系统和编程语言已经帮我们做好了抽象和隔离。所以在提到大数据平台的时候,我们要知道它首先是一个分布式系统,换言之底层是由一组计算机构成的,也就是一个集群。所谓大数据平台,相当于把这个集群抽象成一台计算机,而隔离了底层的细节,让用户使用这个平台时,不会感觉到自己在使用一个分布式系统,而像是在使用一台计算机,很轻松地就可以让整个集群为他所用。为了加深印象,我们可以来对比下两条命令:
hadoop dfs -ls /ls /
第一条条命令是浏览 Hadoop 文件系统(HDFS)的根目录,第二条命令是浏览 Linux 本地文件系统的根目录,如果不进行说明的话,无法看出第一条命令基于分布式文件系统,此外,这么对比的话,可以看到基于集群,Hadoop 为用户提供了一套类似 Liunx 的环境。
因此,Hadoop 可以理解为是一个计算机集群的操作系统,而 Spark、MapReduce 只是这个操作系统支持的编程语言而已,HDFS 是基于所有计算机文件系统之上的文件系统抽象。同理,YARN 是基于所有计算机资源管理与调度系统之上的资源管理与调度系统抽象,Hadoop 是基于所有计算机的操作系统之上的操作系统抽象。所以如果你一定要进行比较的话,Hadoop 应该和操作系统相比较。
Hadoop 的趋势
在 Hadoop 2.0 时期,Hadoop 的存在感还是非常强的,但是就像普通计算机一样,编程语言的热度始终要大于操作系统。随着计算框架的百花齐放,一些新的资源管理与调度系统问世,例如 Kubernets 和 Mesos,Hadoop 的存在感越来越低,在大数据平台中越来越底层,有些大数据平台甚至只采用 HDFS,其余都按照需求选取其他技术组件。
此外,一些计算框架本身就自带生态,如 Spark 的 BDAS,这就逐渐造成了一种现象:Hadoop 的热度越来越低,而分布式计算框架的热度越来越高,就像 Java 的热度肯定比 Linux 高,这也符合计算机的发展规律。
在现在的环境下,采用 HDFS+YARN 的方式作为自己底层大数据平台,仍然能满足绝大多数需求,也是最方便的解决方案。在十年前,Hadoop 就让大家享受到了阿姆达尔定律的红利,它的功劳还是需要被大家所铭记。在后面很长一段时间里,Hadoop 在大数据技术领域里仍然会占有一席之地。
总结
本节课主要讲解了 Hadoop 的架构及其一些关键组件等概念性的东西,但最后的比喻很有意思,作为集群的操作系统,Hadoop 短时间不会,未来也很难退出大数据的舞台。
(资料来源:拉勾教育 - 即学即用的Spark实战44讲)

若有收获,就点个赞吧
0 人点赞
