垃圾收集算法
1. 标记清除算法 Mark Sweep
2. 复制算法
3. 标记整理算法
4. 分代收集
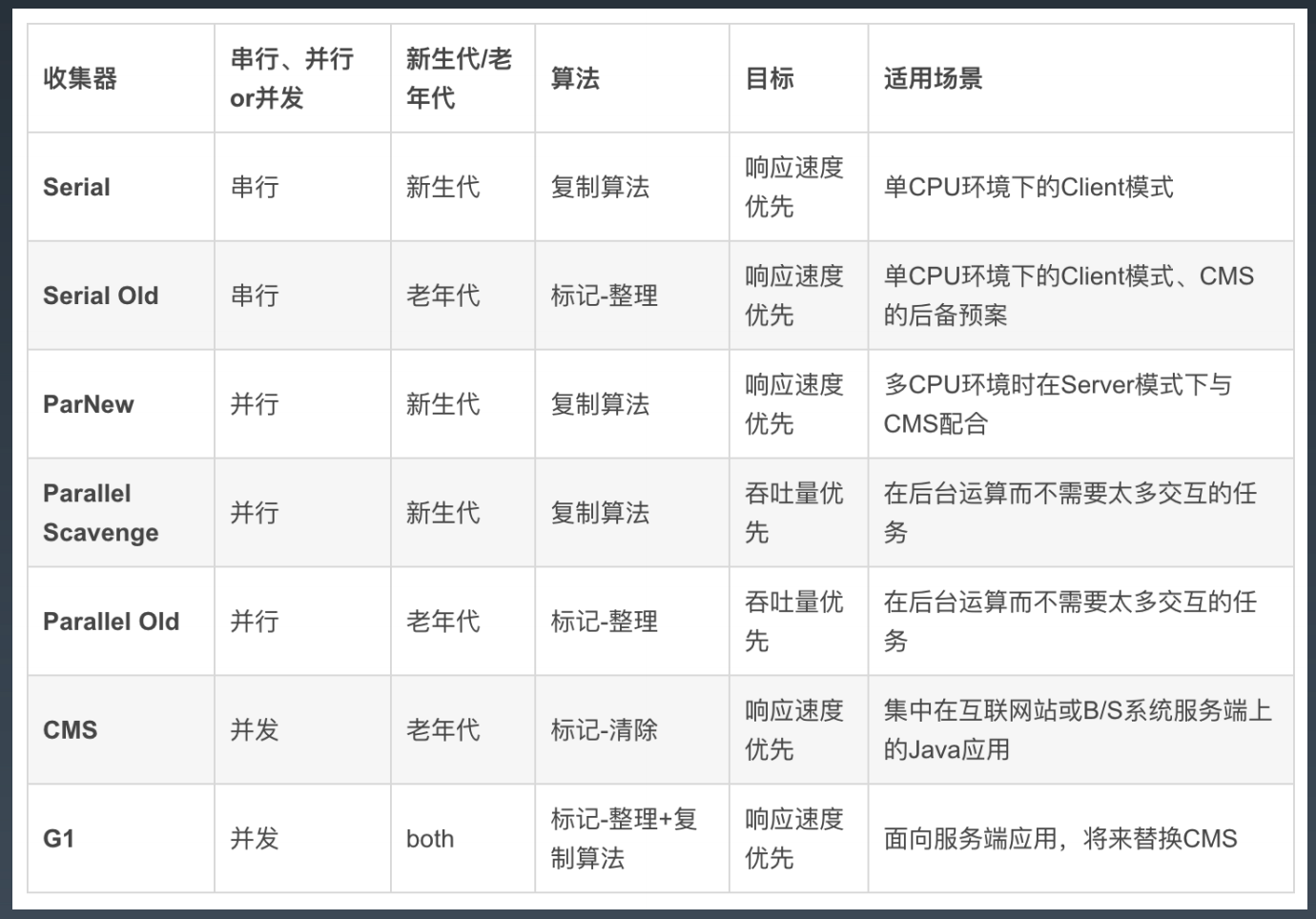
串行 GC(Serial GC)/ParNewGC -XX:
- +UseSerialGC 配置串行 GC 串行 GC
- 对年轻代使用 mark-copy(标记-复制) 算法,对老年代使用 mark-sweep-compact (标记-清除-整理)算法。
- 两者都是单线程的垃圾收集器,不能进行并行处理,所以都会触发全线暂停(STW),停止所 有的应用线程。
- 因此这种 GC 算法不能充分利用多核 CPU。不管有多少 CPU 内核,JVM 在垃圾收集时都只能使 用单个核心。
- CPU 利用率高,暂停时间长。简单粗暴,就像老式的电脑,动不动就卡死。
- 该选项只适合几百 MB 堆内存的 JVM,而且是单核 CPU 时比较有用。 想想 why?
-XX:+UseParNewGC 改进版本的 Serial GC,可以配合 CMS 使用。
并行 GC(Parallel GC)
-XX:+UseParallelGC
-XX:+UseParallelOldGC
-XX:+UseParallelGC -XX:+UseParallelOldGC年轻代和老年代的垃圾回收都会触发 STW 事件。
- 在年轻代使用 标记-复制(mark-copy)算法,在老年代使用 标记-清除-整理(mark-sweep-compact)算法。
- -XX:ParallelGCThreads=N 来指定 GC 线程数, 其默认值为 CPU 核心数。
并行垃圾收集器适用于多核服务器,主要目标是增加吞吐量。因为对系统资源的有效使用,能达到 更高的吞吐量:
-XX:+UseConcMarkSweepGC
- 其对年轻代采用并行 STW 方式的 mark-copy (标记-复制)算法,对老年代主要使用并发 marksweep (标记-清除)算法。
- CMS GC 的设计目标是避免在老年代垃圾收集时出现长时间的卡顿,主要通过两种手段来达成此 目标:
- 不对老年代进行整理,而是使用空闲列表(free-lists)来管理内存空间的回收。
- 在 mark-and-sweep (标记-清除) 阶段的大部分工作和应用线程一起并发执行。
- 也就是说,在这些阶段并没有明显的应用线程暂停。但值得注意的是,它仍然和应用线程争抢 CPU 时间。默认情况下,CMS 使用的并发线程数等于 CPU 核心数的 1/4。
- 如果服务器是多核 CPU,并且主要调优目标是降低 GC 停顿导致的系统延迟,那么使用 CMS 是 个很明智的选择。进行老年代的并发回收时,可能会伴随着多次年轻代的 minor GC。
- 思考:并行 Parallel 与并发 Concurrent 的区别?
处理步骤
- G1 的全称是 Garbage -First,意为垃圾优先,哪 一块的垃圾最多就优先清理它。
- G1 GC 最主要的设计目标是:将 STW 停顿的时间 和分布,变成可预期且可配置的。
- 事实上,G1 GC 是一款软实时垃圾收集器,可以为 其设置某项特定的性能指标。为了达成可预期停顿 时间的指标,G1 GC 有一些独特的实现。
- 首先,堆不再分成年轻代和老年代,而是划分为多个(通常是 2048 个)可以存放对象的 小块堆区域 (smaller heap regions)。每个小块,可能一会被 定义成 Eden 区,一会被指定为 Survivor区或者 Old 区。在逻辑上,所有的 Eden 区和 Survivor 区合起来就是年轻代,所有的 Old 区拼在一起那 就是老年代
- -XX:+UseG1GC -XX:MaxGCPauseMillis=50
- 最大GC停顿时间 MaxGCpauseMillis 默认值200ms
- 这样划分之后,使得 G1 不必每次都去收集整 个堆空间,而是以增量的方式来进行处理: 每次只处理一部分内存块,称为此次GC的回收集(collection set)。每次 GC 暂停都会收集所 有年轻代的内存块,但一般只包含部分老年代 的内存块 。
- G1 的另一项创新是,在并发阶段估算每个小堆块存活对象的总数。
- 构建回收集的原则是: 垃圾最多的小块会被优先收集。这也是 G1名称的由来。
处理步骤
JVM参数
- -XX:+UseG1GC:启用 G1 GC;
- -XX:G1NewSizePercent:初始年轻代占整个 Java Heap 的大小,默认值为 5%;
- -XX:G1MaxNewSizePercent:最大年轻代占整个 Java Heap 的大小,默认值为 60%; -XX:G1HeapRegionSize:设置每个 Region 的大小,单位 MB,需要为 1,2,4,8,16,32 中的某个值,默 认是堆内存的 1/2000。如果这个值设置比较大,那么大对象就可以进入 Region 了。
- -XX:ConcGCThreads:与Java应用一起执行的 GC 线程数量,默认是 Java 线程的 1/4,减少这个参数的数值可 能会提升并行回收的效率,提高系统内部吞吐量。如果这个数值过低,参与回收垃圾的线程不足,也会导致并行回收机制耗时加长。
- -XX:+InitiatingHeapOccupancyPercent(简称 IHOP):G1 内部并行回收循环启动的阈值,默认为 Java Heap 的 45%。这个可以理解为老年代使用大于等于 45% 的时候,JVM 会启动垃圾回收。这个值非常重要,它决定了在什么时间启动老年代的并行回收。
- -XX:G1HeapWastePercent:G1停止回收的最小内存大小,默认是堆大小的 5%。GC 会收集所有的 Region 中 的对象,但是如果下降到了 5%,就会停下来不再收集了。就是说,不必每次回收就把所有的垃圾都处理完,可以 遗留少量的下次处理,这样也降低了单次消耗的时间。
- -XX:G1MixedGCCountTarget:设置并行循环之后需要有多少个混合 GC 启动,默认值是 8 个。老年代 Regions 的回收时间通常比年轻代的收集时间要长一些。所以如果混合收集器比较多,可以允许 G1 延长老年代的收集时间。
- -XX:+G1PrintRegionLivenessInfo:这个参数需要和 -XX:+UnlockDiagnosticVMOptions 配合启动,打印 JVM 的调试信 息,每个 Region 里的对象存活信息。
- -XX:G1ReservePercent:G1 为了保留一些空间用于年代之间的提升,默认值是堆空间的 10%。因为大量执行回收的地方在 年轻代(存活时间较短),所以如果你的应用里面有比较大的堆内存空间、比较多的大对象存活,这里需要保留一些内存。
- -XX:+G1SummarizeRSetStats:这也是一个 VM 的调试信息。如果启用,会在 VM 退出的时候打印出 Rsets 的详细总结信 息。如果启用 -XX:G1SummaryRSetStatsPeriod 参数,就会阶段性地打印 Rsets 信息。
- -XX:+G1TraceConcRefinement:这个也是一个 VM 的调试信息,如果启用,并行回收阶段的日志就会被详细打印出来。
- -XX:+GCTimeRatio:这个参数就是计算花在 Java 应用线程上和花在 GC 线程上的时间比率,默认是 9,跟新生代内存的分 配比例一致。这个参数主要的目的是让用户可以控制花在应用上的时间,G1 的计算公式是 100/(1+GCTimeRatio)。这样 如果参数设置为 9,则最多 10% 的时间会花在 GC 工作上面。Parallel GC 的默认值是 99,表示 1% 的时间被用在 GC 上面, 这是因为 Parallel GC 贯穿整个 GC,而 G1 则根据 Region 来进行划分,不需要全局性扫描整个内存堆。
- -XX:+UseStringDeduplication:手动开启 Java String 对象的去重工作,这个是 JDK8u20 版本之后新增的参数,主要用于 相同 String 避免重复申请内存,节约 Region 的使用。
- -XX:MaxGCPauseMills:预期 G1 每次执行 GC 操作的暂停时间,单位是毫秒,默认值是 200 毫秒,G1 会尽量保证控制在 这个范围内。
其他
GC收集器的对比
常用的 GC 组合(重点) 常用的组合为:
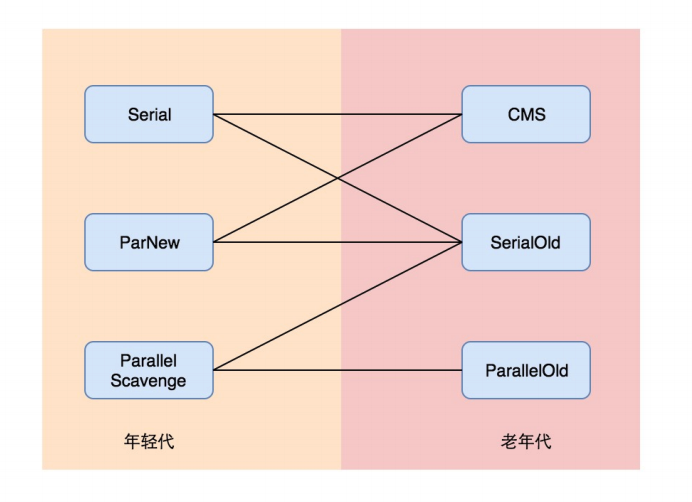
(1)Serial+Serial Old 实现单线程的低延迟 垃圾回收机制;
(2)ParNew+CMS,实现多线程的低延迟垃 圾回收机制;
(3)Parallel Scavenge和Parallel Scavenge Old,实现多线程的高吞吐量垃圾 回收机制;
如何选择
选择正确的 GC 算法,唯一可行的方式就是去尝试,一般性的指导原则:
- 如果系统考虑吞吐优先,CPU 资源都用来最大程度处理业务,用 Parallel GC;
- 如果系统考虑低延迟有限,每次 GC 时间尽量短,用 CMS GC;
- 如果系统内存堆较大,同时希望整体来看平均 GC 时间可控,使用 G1 GC。 对于内存大小的考量:
ZGC/Shenandoah GC
ZGC
- ZGC(Z Garbage Collector): 通过着色指针和读屏障,实现几乎全部的并发执行,几毫 秒级别的延迟,线性可扩展;
-XX:+UnlockExperimentalVMOptions -XX:+UseZGC -Xmx16g
**
- ZGC最主要的特点包括:
- GC 最大停顿时间不超过 10ms
- 堆内存支持范围广,小至几百 MB 的堆空间,大至 4TB 的超大堆 内存(JDK13 升至 16TB)
- 与 G1 相比,应用吞吐量下降不超过 15%
- 当前只支持 Linux/x64 位平台,JDK15 后支持 MacOS 和 Windows 系统
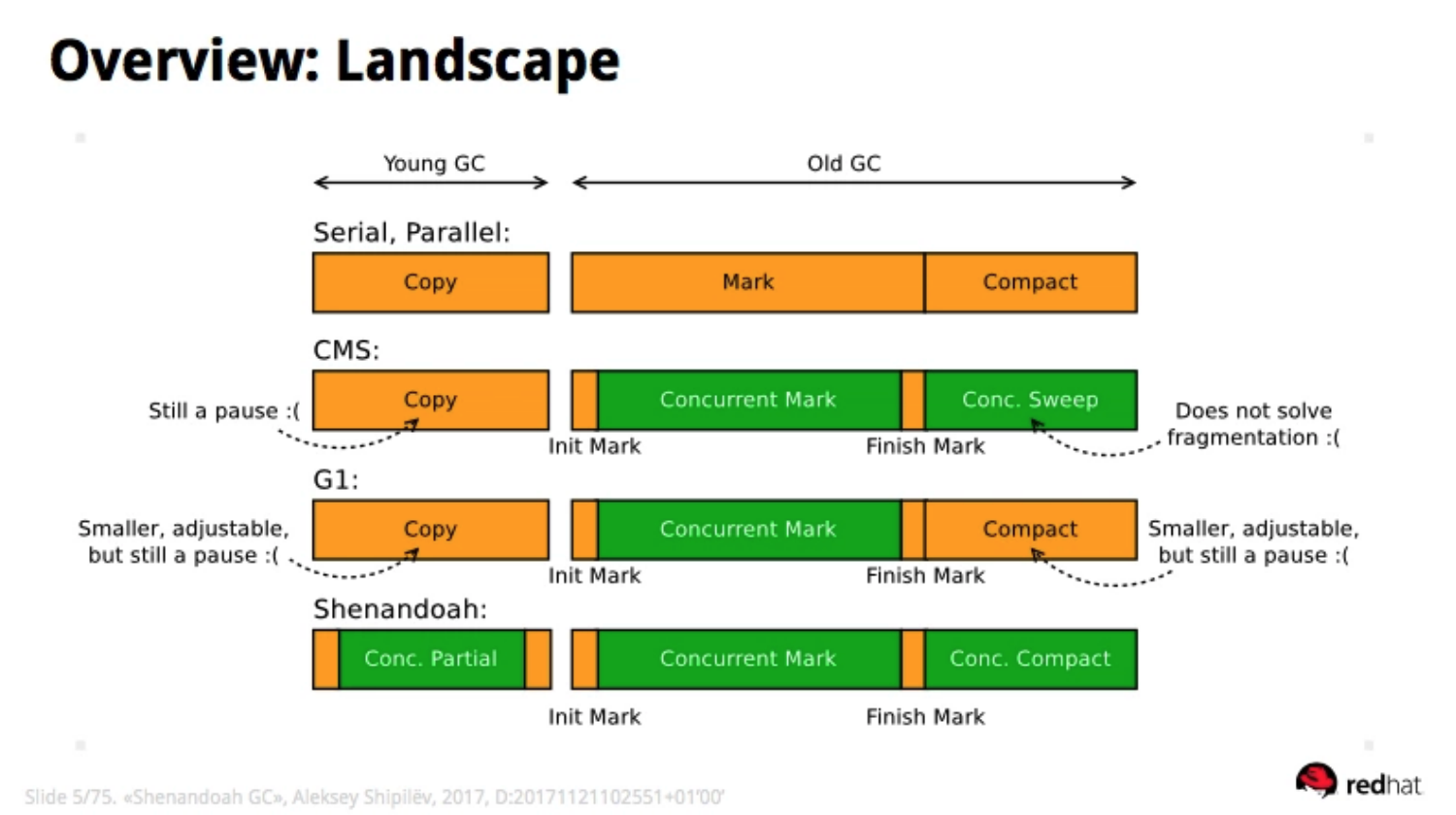
处理过程
Shenandoah GC 立项比 ZGC 更早,设计为 GC 线程与应用线程并发执行的方式,通过 实现垃圾回收过程的并发处理,改善停顿时 间,使得 GC 执行线程能够在业务处理线程 运行过程中进行堆压缩、标记和整理,从而 消除了绝大部分的暂停时间。
- Shenandoah 团队对外宣称 Shenandoah GC 的暂停时间与堆大小无关,无论是 200 MB 还是 200 GB的堆内存,都可以保障具有 很低的暂停时间(注意:并不像 ZGC 那样保 证暂停时间在 10ms 以内)。
jvm参数-verbose:gc和-XX:+PrintGC有区别?
-XX:+PrintGC 与 -verbose:gc 是一样的,可以认为-verbose:gc 是 -XX:+PrintGC的别名.
-XX:+PrintGCDetails 在启动脚本可以自动开启
-XX:+PrintGC , 如果在命令行使用jinfo开启的话,不会自动开启-XX:+PrintGC
在官方文档中有说明:两者功能一样,都用于垃圾收集时的信息打印。

若有收获,就点个赞吧
0 人点赞
