控制Pod调度的需求
- 集群中有些机器的配置高,希望把核心的业务服务运行在上面
- 某两个服务的网络传输很频繁,希望他们最好在同一台服务器上
- ……
实现方法
1. NodeSelector
**lable**是**Kubernetes**中一个非常重要的概念,用户可以非常灵活的利用label来管理集群中的资源,Pod的调度就可以通过节点的label标签进行特定的部署。
首先我们为Node规划标签,然后在创建部署的时候,通过使用nodeSelector标签来指定Pod运行在哪些节点上。
# 查看节点的标签kubectl get nodes --show-labels# 给节点打标签kubectl label node NODE_NAME LABEL_NAME=LABEL_VALUE
在yaml资源清单配置文件中的spec字段中添加nodeSelector字段,指定需要调度到的节点label即可;
2. 节点亲和性与反亲和性
Node affinity 是 Kubernetes 1.2版本后引入的新特性,类似于nodeSelector,允许我们指定一些Pod在Node间调度的约束。支持两种形式:requiredDuringSchedulingIgnoredDuringExecution和preferredDuringSchedulingIgnoredDuringExecution,可以认为前一种是必须满足,如果不满足则不进行调度,后一种是倾向满足,不满足的情况下会调度的不符合条件的Node上。IgnoreDuringExecution表示如果在Pod运行期间Node的标签发生变化,导致亲和性策略不能满足,则继续运行当前的Pod。
节点亲和性可以进行一些简单的逻辑组合,不只是简单的相等匹配。分为两种,**软策略**和**硬策略**。
- 软策略:
- preferredDuringSchedulingIgnoredDuringExecution
如果集群没有满足这个策略要求的节点的话,Pod就会忽略这条规则,继续完成调度。说白了就是满足条件最好了,没有满足就忽略掉。
- 硬策略:
- requiredDuringSchedulingIgnoredDuringExecution
如果没有满足条件的节点的话,就不断的重试知道满足条件位置。说白了就是你必须满足我的要求,不然我就不会调度Pod。
kubectl explain pod.spec.affinity.nodeAffinity
- yaml配置文件如下:
# 要求1: pod不能运行在128和132两个节点上 # 要求2: 如果某个节点满足label标签为 disktype=ssd的话就调度到这个节点上 ... spec: containers: - name: guangzai-demo image: 10.1.1.100:5000/guangzai/guangzai-web affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: # 硬策略 nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hosname operator: NotIn values: - 192.168.21.128 - 192.168.21.132 preferredDuringSchedulingIgnoredDuringExecution: # 软策略 - weight: 1 preference: matchExpressions: - key: disktype operator: In values: - ssd - sas如果
**nodeSelectorTerms**下面有多个选项的话,满足任何一个条件就可以;如果**matchExpressions**有多个选项的话,则必须同时满足这些条件才能正常调度Pod。
这里匹配逻辑是label的值在某个列表中,Kubernetes提供的操作符有下面几种:
- In: label的值在某个列表中
- NotIn: label的值不在某个列表中
- Gt: label的值大于某个值
- Lt: lable的值小于某个值
- Exists: 某个label存在
- DoesNotExist: 某个label不存在
3. Pod间的亲和性与反亲和性 inter-pod affinity/anti-affinity
这个特性是允许用户通过已经运行的Pod上的标签来决定调度策略,用文字描述就是“如果Node X上运行了一个或多个满足Y条件的Pod,那么这个Pod在Node应该运行在Pod X”,因为Node没有命名空间,Pod有命名空间,这样就允许管理员在配置的时候指定这个亲和性策略适用于哪个命名空间,可以通过topologyKey来指定。topology是一个范围的概念,可以是一个Node、一个机柜、一个机房或者是一个区域(如北美、亚洲)等,实际上对应的还是Node上的标签。
有两种类型
- requiredDuringSchedulingIgnoredDuringExecution,刚性要求,必须精确匹配
- preferredDuringSchedulingIgnoredDuringExecution,软性要求
4. 污点(Taints)与容忍(tolerations)
对于**nodeAffinity**而言,无论是硬策略还是软策略,都是调度Pod的预期的节点上,而**Taints**恰好相反,如果一个节点标记为Taints,Pod一般是不会被调度到taint标记过的节点上的,除非Pod也被标记为可以容忍污点节点。
污点Taints是Node的一个属性,Node设置了污点Taints后,因为有了污点,所以Kubernetes是不讲pod调度到这个Node上的。于是Kubernetes就给Pod设置了一个容忍属性**Tolerations**,如果Pod容忍Node上的污点,就可以忽略污点把Pod调度过去。
kubectl taint node node_name taint_name=taint_value:可取值
可取值有三个
NoSchedule: 一定不能被调度 PreferNoSchedule: 尽量不要调度 NoExecute: 不仅不会调度,还会驱逐Node上已有的Pod
例如:
kubectl taint node k8s-node-1 monitoringSystem=prometheus:NoSchedule
- **去除污点**
```bash
# 2. 去除污点
去除污点taint_name:可取值-,后面跟个“-”号就可以了,或者taint_name-
# 例如:
kubectl taint node k8s-node-1 monitoringSystem:NoSchedule-
或
kubectl taint node k8s-node-1 monitoringSystem-
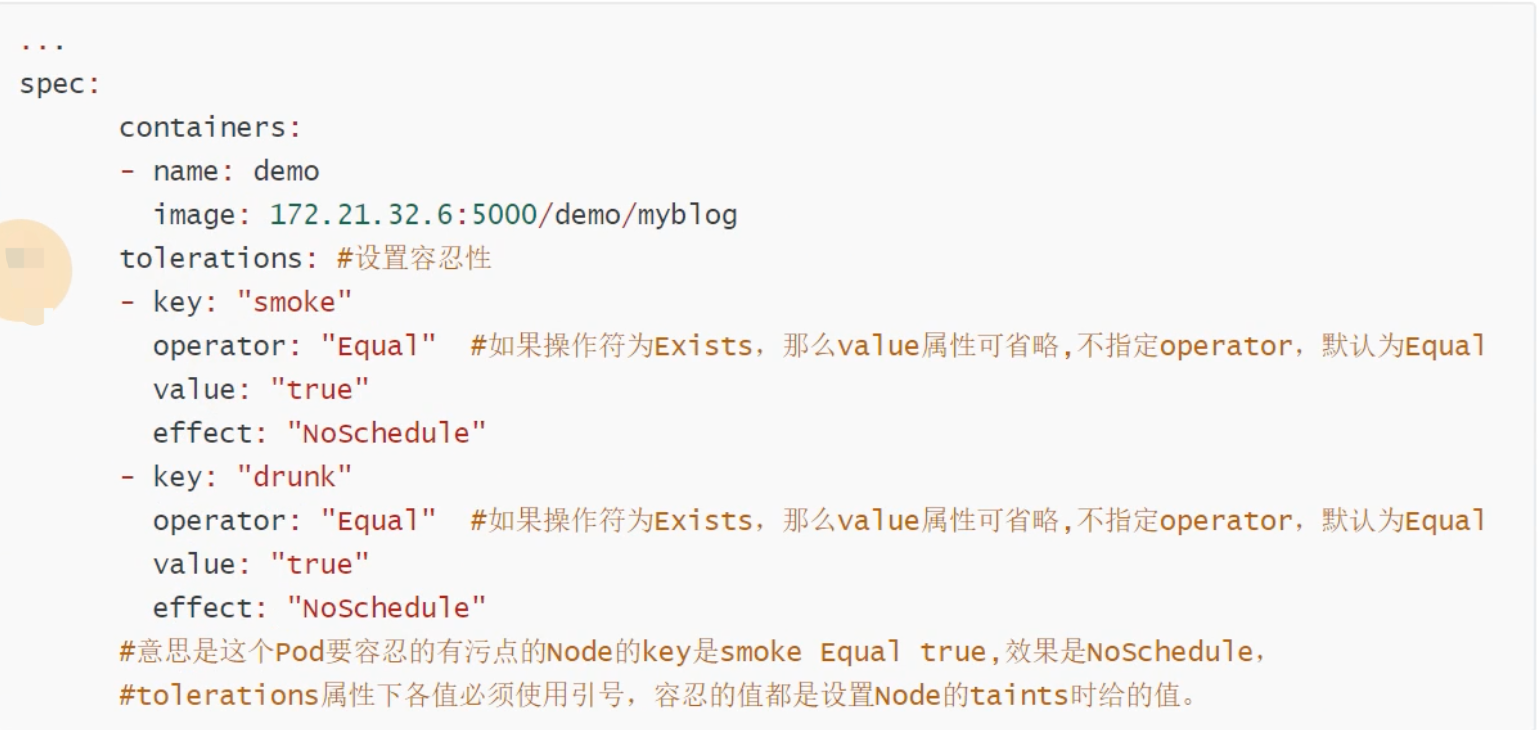
注意⚠️ : 如果节点设置了污点,就说明这个节点是有专门用途的,所以不是随便设置污点的,因为除非你在资源配置清单中的**spec.containers**下的容器列表里明确给出容忍属性**tolerations**,不然Pod是不会被调度到有污点的节点上的。

若有收获,就点个赞吧
0 人点赞
