1. 概念
1.1. 大端模式
- 高位字节排放在内存的低地址端,低位字节排放在内存的高地址端,即正序排列,高尾端;
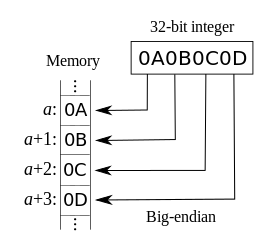
1.2. 小端模式
- 低位字节排放在内存的低地址端,高位字节排放在内存的高地址端,即逆序排列,低尾端;
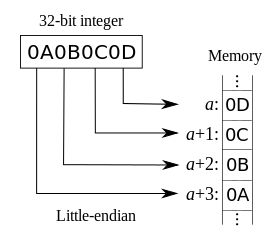
1.3. 具体例子
16bit宽的数
0x1234在两种模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
| 内存地址 | 小端模式存放内容 | 大端模式存放内容 | | —- | —- | —- | | 0x4000 | 0x34 | 0x12 | | 0x4001 | 0x12 | 0x34 |32bit宽的数
0x12345678在两种模式CPU内存中的存放方式(假设从地址0x4000开始存放)为:
| 内存地址 | 小端模式存放内容 | 大端模式存放内容 | | —- | —- | —- | | 0x4000 | 0x78 | 0x12 | | 0x4001 | 0x56 | 0x34 | | 0x4002 | 0x34 | 0x56 | | 0x4003 | 0x12 | 0x78 |
2. 如何判断机器的字节序(*)
int main (void) { union{ short i; char a[2]; }u;//联合体u
u.a[0] = 0x11; u.a[1] = 0x22;
printf (“0x%x\n”, u.i); //0x2211 为小端 0x1122 为大端 return 0; }
- union 型数据所占的空间等于其最大的成员所占的空间。对 union 型的成员的存取都是相对于该联合体基地址的偏移量为 0 处开始,也就是联合体的访问不论对哪个变量的存取都是从 union 的首地址位置开始。- 联合是一个在同一个存储空间里存储不同类型数据的数据类型。这些存储区的地址都是一样的,联合里不同存储区的内存是重叠的,修改了任何一个其他的会受影响。那么通过强制类型转换,判断其实存储位置,也可以测试大小端了:```c#include <stdio.h>int main (void) {short i = 0x1122;char *a = (char*)(&i);printf ("0x%x\n", *(a + 0)); //大端为 0x11 小端为 0x22printf ("0x%x\n", *(a + 1));return 0;}
3. 常见的字节序
一般操作系统都是小端,通讯协议是大端的(网络协议常见)
3.1. 常见CPU的字节序
- Big Endian : PowerPC、IBM、Sun
- Little Endian : x86、DEC
- ARM既可以工作在大端模式,也可以工作在小端模式
3.2. 常见文件的字节序
| Adobe PS | Big Endian | | —- | —- | | BMP | Little Endian | | DXF(AutoCAD) | Variable | | GIF | Little Endian | | JPEG | Big Endian | | MacPaint | Big Endian | | RTF | Little Endian | | Java和所有的网络通讯协议 | Big-Endian |
4. 学习资料

若有收获,就点个赞吧
0 人点赞
