HDFS
HDFS 代表 Hadoop 分布式文件系统,主要是Hadoop的存储,用于海量数据存储。具有高容错的特点,提供高吞吐率的数据访问。
HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode或以上(HA:一个NameNode处于active状态,另一个处于standby状态)和若干个DataNode组成的。
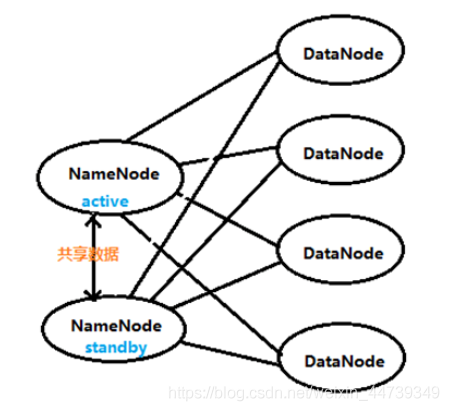
1.Namenode
是整个文件系统的管理节点。它维护着1.整个文件系统的文件目录树,2.文件/目录的元信息和每个文件对应的数据块列表。3.接收用户的操作请求。文件包括:(hdfs-site.xml的dfs.namenode.name.dir属性)
内部机制是将一个文件分割成一个或多个块,这些块被存储在一组数据节点中。名字节点用来操作文件命名空间的文件或目录操作,如打开,关闭,重命名等等。它同时确定块与数据节点的映射。数据节点负责来自文件系统客户的读写请求。数据节点同时还要执行块的创建,删除,和来自名字节点的块复制指令。
2.Datanode
提供真实文件数据的存储服务(以block形式存储)。
心跳机制
HDFS的标准: NameNode如果连续10次没有收到DataNode的汇报。 那么NameNode就会认为该DataNode存在宕机的可能。
timeout = 10 心跳间隔时间 + 2 检查一次消耗的时间
心跳间隔时间:dfs.heartbeat.interval 心跳时间:3s检查一次消耗的时间:heartbeat.recheck.interval checktime : 5min
安全机制
HDFS启动时会进入安全模式(只读),启动完成会退出。
hdfs dfsadmin -safemode
数据访问
运行在HDFS之上的应用程序必须流式地访问它们的数据集。HDFS被设计成适合批量处理的,而不是用户交互式的。重点是在数据吞吐量,而不是数据访问的反应时间。
HDFS不适合的场景
低延迟访问;
并发写入/修改文件;
轻量级小文件存储(占用内存大);
HDFS上传下载常用命令(hadoop fs\hdfs fs)
mkdir 创建目录
创建目录/bin/hadoop fs -mkdir /maliang创建多级目录 加上 -p/bin/hadoop fs –mkdir -p /a/b/c
put 文件
/bin/hadoop fs -put /app/hadoop/vin_data.txt /maliang
rm 删除目录或者文件
创建目录/bin/hadoop fs -rm /vin_data.txt创建多级目录 加上 -p/bin/hadoop fs –mkdir -p /a/b/c
ls 显示目录下的所有文件或者文件夹
显示目录下文件夹/bin/hadoop fs -ls /显示目录下所有文件 加上 -R/bin/hadoop fs -ls -R /
cat 查看文件内容
/bin/hadoop fs -cat /maliang/vin_data.txt
get 下载文件到本地
/bin/hdfs dfs -get /maliang/vin_data.txt /app/hadoop
HDFS管理常用命令
-report
查看文件系统的基本信息和统计信息/bin/hdfs dfsadmin -report
-safemode 安全模式命令
enter | leave | get | wait/bin/hdfs dfsadmin -safemode enter
-refreshNodes
重新读取hosts和exclude文件,使新的节点或需要退出集群的节点能够被NameNode重新识别。这个命令在新增节点或注销节点时用到/bin/hdfs dfsadmin -refreshNodes
HDFS数据块
- 数据块
数据块 : Block是HDFS物理上把数据分成一个块Block。默认块大小 : 128M数据切分 : 数据切片只是在逻辑上对输入进行分片,并不会在磁盘上分片存储。eg:切片大小设置为 : 100M默认物理块大小 : 128M如文末文件206M,那么逻辑上会分3片,而物理上只有2块。
块的大小设置
- 通过如下命令查看:
$HADOOP_HOME/bin/hdfs fsck -*
$HADOOP_HOME/bin/hadoop fs –stat [format] - c查看 hdfs-site.xml 配置:
dfs.blocksize
268435456
HDFS文件系统块大小;可以配置以m,g等后缀结尾的值 512m
(1)HDFS的块设置太小,会增加寻址时间,程序一直在找块的开始位置;
(2)如果块设置的太大,从磁盘传输数据的时间会明显大于定位这个块开始位置所需的时间。导致程序在处理这块数据时,会非常慢。
HDFS块的大小设置主要取决于磁盘传输速率。
HDFS副本存放策略
设置备份数
配置文件hdfs-site.xml
```dfs.replication 3
- 命令修改
/bin/hadoop fs -setrep -R 1 /
**副本存放位置:**(网上所查,需了解机架感知机制)- 默认的同一份数据的副本,默认3个,优先读取本地副本(降低带宽消耗和读取延时)
第一份:存放到本机器的HDFS目录下
第二份:存放到不同于第一份所在的机柜的另外一个机架上的某台服务器上
第三份:存放在不同机柜的某个节点上
更多的副本:选择任意一台服务器上进行存储 ```
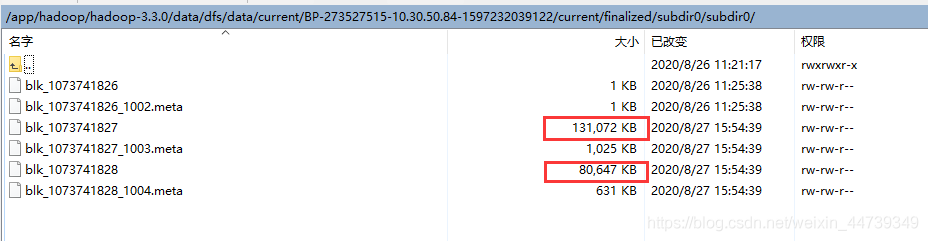
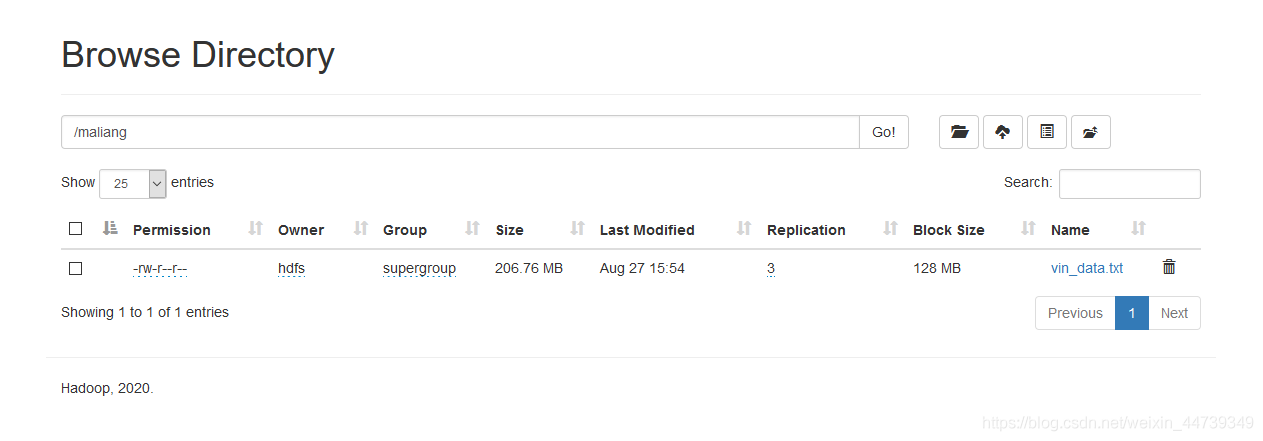
测试结果:
206M文件,按默认值128M分块,分为两个块,存储3副本(未做机架感知配置做测试)。

若有收获,就点个赞吧
0 人点赞
