一开始,不管是论文还是网上的博客,我看的都挺懵的。大部分博客就是先用文字把模型的每一部分拆解开,说说着一层是干什么的,有什么创新点,最后大篇幅给出代码。但不给代码看就总感觉只是泛泛而谈,该不懂的还是不懂。知乎等地方上看的博客确实很棒,原理解释的很透彻;也看了一篇国外小哥写的 Transformer 的源码解析,它的描述思路非常好,先给出代码的大框架,然后一点一点往下走。
关于 Transformer 的原理,参考文章以及网络上已经有很多解读了。简单来说就是 Transformer 是第一个完全依赖于 self-attention 机制的 NLP 模型,而且性能和计算效率比 RNN 和 CNN 都强,出自 Google 的论文 “Attention is All You Need“。 本文主要在模型原理和代码方面,总结多篇文章的探究。
1 Transformer 总体结构
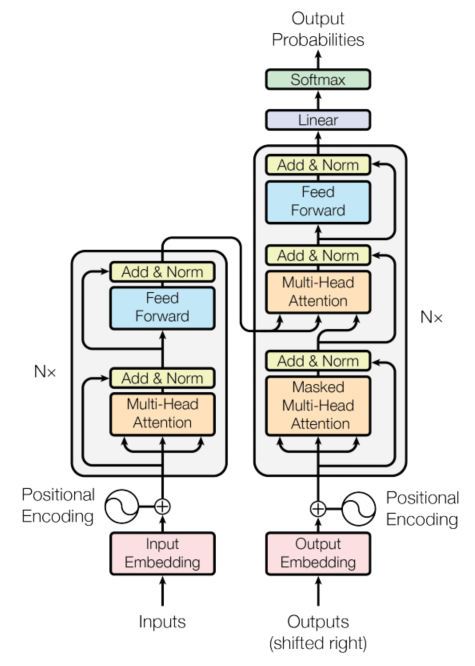
图1.1 Transformer 内部结构(摘自原论文)
Transformer 也是 Encoder-Decoder 结构,上图左侧的 Nx 部分是 encoder,右侧 Nx 部分是 decoder。模型整体的 encoder 是由 6 个完全相同的左侧 Nx 堆起来的,decoder 也是由 6 个完全相同的右侧 Nx 堆起来的。这里 Nx 就是 x 个相同 N 堆叠起来的意思,在论文中用的是 x=6 。的部分在模型的最后,也就是最后一个 decoder 的输出经过 Linear 层和 Softmax 层就可以接损失函数啦。模型总体结构: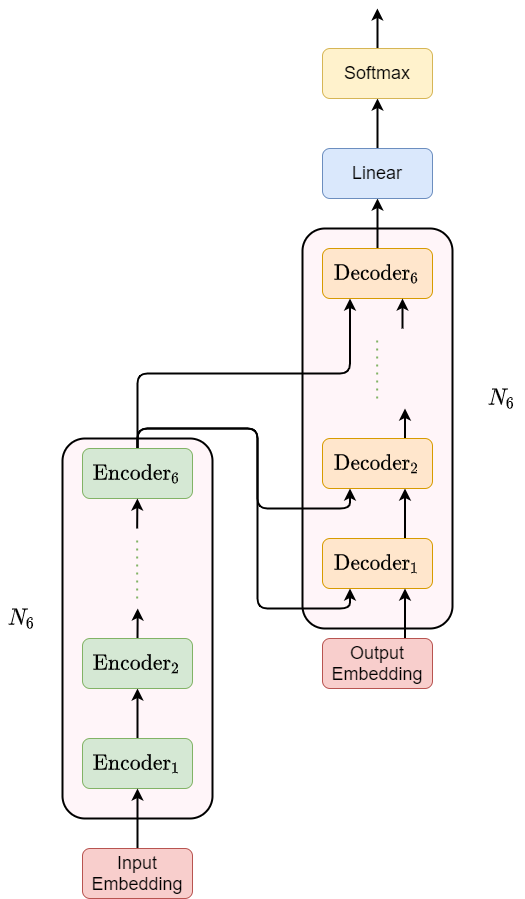
图1.2 Transformer 总体结构
剩下的,就一边看代码,一遍搞吧。
2 内部细节与代码详解
主要参考 Harvard 大学文章与知乎文章代码。代码部分基本是抄的,多加了点注释,同时解释部分更详细。
2.1 Model Architecture
我们按照 Encoder-Decoder 的整体框架来构建 Transformer,这个框架就留出了接口,以后不管是拼 Transformer 还是其他的 Encoder-Decoder 模型就只是把内部实现改一改就好。
Encoder-Decoder 就是三部分:Encoder + Decoder + 输出层(Generator):
class EncoderDecoder(nn.Module):"""通用 Encoder-Decoder 框架. 我们可以基于此类构建其他Encoder-Docoder 模型."""def __init__(self, encoder, decoder, src_embed, tgt_embed, generator):""":Args:`encoder`: Encoder 模块, 需要自定义.`decoder`: Decocder 模块, 需要自定义.`src_embed`: 输入 embedding 模块, 对输入 sequence 做 embedding.`tgt_embed`: 输出(目标)embedding 模块, 对应论文模型图中的 'Output Embedding'.`generator`: 目标任务生成器, 如果是分类问题可以是全连接层 + Softmax..."""super(EncoderDecoder, self).__init__()self.encoder = encoderself.decoder = decoderself.src_embed = src_embedself.tgt_embed = tgt_embedself.generator = generatordef forward(self, src, tgt, src_mask, tgt_mask):"""前向传播(正向计算)PyTorch 模块计算调用函数.:Args:`src`: 输入 token 序列.`tgt`: 输出 (目标) token 序列.`src_mask`: 输入 mask 的张量.`tgt_mask`: 输出 mask 的张量."""return self.decode(self.encode(src, src_mask),src_mask, tgt, tgt_mask)def encode(self, src, src_mask):return self.encoder(self.src_embed(src), src_mask)def decode(self, memory, src_mask, tgt, tgt_mask):""":Args:`memory`: 连接 encoder 和 decoder 的语义向量, 在 Attention 机制下就是 Attention score."""return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
class Generator(nn.Module):"""定义标准 Linear 层和 Softmax."""def __init__(self, dim_model, dim_vocab):""":Args:`dim_model`: Decoder 输出维度.`dim_vocab`: vocab 维度,即模型最后输出维度."""super(Generator, self).__init__()self.proj = nn.Linear(dim_model, dim_vocab)def forward(self, x):return F.log_softmax(self.proj(x), dim=-1)
关于 mask 是什么:NLP 中的 Mask 全解
2.2 Encoder
2.2.1 一整个 encoder 结构
Encoder 包含了  个完全相同的层。我们首先定义生成
个完全相同的层。我们首先定义生成  个相同层的函数:
个相同层的函数:
def clones(module, N):"""生成 N 个相同的层.:Return:`nn.ModuleList`: 存储 N 个层的模型列表."""return nn.ModuleList([copy.deepcopy(module) for _ in range(N)])
class Encoder(nn.Module):"""模型的 Encoder 部分包含了 N 个相同的 encode 层."""def __init__(self, layer, N):super(Encoder, self).__init__()self.layers = clones(layer, N)self.norm = LayerNorm(layer.size)def forward(self, x, mask):"""将输入和 mask 依次传递给每一层."""for layer in self.layers:x = layer(x, mask)return self.norm(x)
2.2.2 每一个 encode 层结构
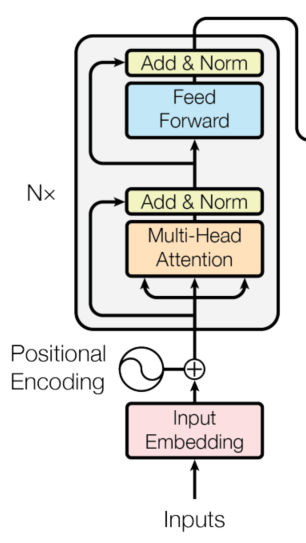
图2.1 每一层 Encoder 的结构
每一个 encode 层由两部分构成,下面我们先预定义这么个类,然后再细究其中的细节。
每一个 encode 层首先对前面一部分对输入进行了 Multi-Header Attention,与输入  做了残差连接并使用 Layer Normalization 进行归一化;后面一部分是 Feed Forward + LN 以及残差连接。这些可能都是生词儿,在下面具体实现的时候再议。上面两部分抽象一下,都是一个 sublayer + LN + 残差连接,首先我们将这部分写成一个类
做了残差连接并使用 Layer Normalization 进行归一化;后面一部分是 Feed Forward + LN 以及残差连接。这些可能都是生词儿,在下面具体实现的时候再议。上面两部分抽象一下,都是一个 sublayer + LN + 残差连接,首先我们将这部分写成一个类 SublayerConnection 。
class SublayerConnection(nn.Module):"""残差连接后面跟一个 layer norm."""def __init__(self, dim_model, drop_prob):""":Args:`drop_prob`: dropout 层的 dropout 概率."""super(SublayerConnection, self).__init__()self.norm = nn.LayerNorm(dim_model)self.dropout = nn.Dropout(drop_prob)def forward(self, x, sublayer):""":Args:`sublayer`: 残差连接前面的层."""return self.norm(x + self.dropout(sublayer(x)))
关于残差网络:
关于 Layer Normalization:先了解一下 Batch Normalization。BN 是在 batch 这个维度进行的归一化,而 LN 是在向量维度进行归一化。比如我们喜欢将样本(输入)矩阵写成 (B, D) 的形式,其中 B 是 batch size, 而 D 是每一个特征向量的维度。LN 就是对 batch 中每一个特征向量这 D 个数作归一化。
先实现 encode 层的主体类:用 Multi-Head Attention 以及 Feed Forward 层分别作为 SublayerConnection 的 sublayer 参数。
class EncoderLayer(nn.Module):"""每一个 Encoder 层由 self-attention 和 feed forawrd 两部分组成."""def __init__(self, dim_model, self_attn, feed_forward, drop_prob):""":Args:`self_attn`: Self-Attention 层, Multi-Head Attention 由多个 self-attn 构成.`feed_forward`: Feed Forward 层."""super(EncoderLayer, self).__init__()self.dim_model = dim_modelself.self_attn = self_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(dim_model, drop_prob), 2)def forward(self, x, mask):# 这里 lambda 用的非常精髓!x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))return self.sublayer[1](x, self.feed_forward)
Encoder 整体结构就定义完了,接下来就要深入模型内部,也是 Transformer encoder 部分的核心了:Multi-Head Attention 以及 Feed Forward。
2.2.3 Multi-Head Attention
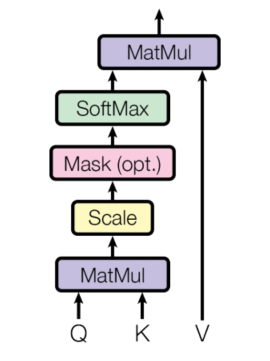
图2.2 Scaled Dot-Product Attention
Multi-Head Attention 是 Attention 派生出来的,所以先看基本的 Attention 是怎么回事儿。Google 的这篇论文中也说了,Attention 就是通过度量 query 和 key 的相似程度来确定每个 value 的权重。 Transformer 首先给出了 Scaled Dot-Product Attention,就是在 Dot-Product Attention 的基础上加了一个缩放因子(scaled factor):

其中  ,
, ,
, 。
。 分别的 query, key 以及 value 集中的元素个数,后面
分别的 query, key 以及 value 集中的元素个数,后面  就是代表每个元素的向量维度了。一般
就是代表每个元素的向量维度了。一般  ,为了方便计算。至于这个缩放因子的作用,论文中是这么解释的:当
,为了方便计算。至于这个缩放因子的作用,论文中是这么解释的:当  也就是每一个 key 向量的维度很大的时候,dot-product 得到的结果数值非常大,就会导致样本落到了 softmax 函数梯度较小的区域,所以需要除以一个缩放因子
也就是每一个 key 向量的维度很大的时候,dot-product 得到的结果数值非常大,就会导致样本落到了 softmax 函数梯度较小的区域,所以需要除以一个缩放因子  。
。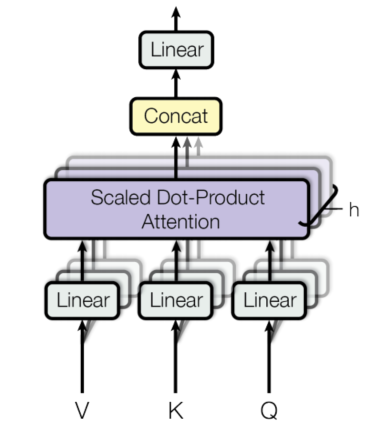
图2.3 Multi-Head Attention
然后就是 Multi-Head Attention 了,理解了 Attention 这个也比较简单。假设之前  中每一个向量都是
中每一个向量都是  维的,Multi-Head 就是把这每一个向量平均拆成若干份,每一份就是一个 head。比如论文中使用的是 heads 数量
维的,Multi-Head 就是把这每一个向量平均拆成若干份,每一份就是一个 head。比如论文中使用的是 heads 数量  ,拿
,拿  这个矩阵来说,就是按照
这个矩阵来说,就是按照  这个维度进行拆分:
这个维度进行拆分:

同理将  和
和  也分成多个 head。Multi-Head Attention 整体上是先对
也分成多个 head。Multi-Head Attention 整体上是先对  做线性映射,然后分成若干个 head ,并对这些 head 分别做 Attention(当然 Transformer 中就是 Scaled Dot-Product Attention 了),最后将所有的 head 在最后一个维度 上连接(concatenate),连接的结果再做一次线性变换就得到了 Multi-Head Attention 的输出。公式如下:
做线性映射,然后分成若干个 head ,并对这些 head 分别做 Attention(当然 Transformer 中就是 Scaled Dot-Product Attention 了),最后将所有的 head 在最后一个维度 上连接(concatenate),连接的结果再做一次线性变换就得到了 Multi-Head Attention 的输出。公式如下:

其中 
其中  ,
, ,
, ,
, 。在论文中 ,
。在论文中 , 。
。
其实这个 Multi-Head 就是把以前同样的东西拆成好几份,每一份用不同的线性映射(不同的权重参数)来训练,感觉很像 CNN 中用多个卷积核的想法。论文中说也是把 通过一个线性映射后分成  份,每一份做 Scaled Dot-Product Attention,拼接起来的效果更好。
份,每一份做 Scaled Dot-Product Attention,拼接起来的效果更好。
在 Transformer 中,Multi-Head Attention 中的 相同,即 Self Attention。
但说了半天,感觉还是看代码实在一点,首先是 Scaled Dot-Product Attention:
def attention(query, key, value, mask=None, dropout=None):"""Compute 'Scaled Dot-Product Attention'.:Args:`mask`: Mask Tensor.`dropout`: nn.Dropout layer."""d_k = query.size(-1)# 计算得分.scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)if mask is not None:# 在 mask = 0 的位置, 将原值替换为 -1e9, 在 softmax 中输出 0# 即被 mask 掉了. 关于 mask 后面详解.scores = scores.masked_fill(mask == 0, -1e9)attn = F.softmax(scores, dim=-1)if dropout:scores = dropout(attn)return torch.matmul(attn, value), attn
然后是 Multi-Head Attention:
class MultiHeadedAttention(nn.Module):def __init__(self, num_heads, dim_model, drop_prob=0.1):""":Args:`num_heads`: Head 的数量, 论文中的 'h'.`dim_model`: 论文中的 'd_model'."""super(MultiHeadedAttention, self).__init__()assert dim_model % num_heads == 0# 假定 d_k 与 d_v 相等.self.d_k = dim_model // num_headsself.num_heads = num_headsself.linears = clones(nn.Linear(dim_model, dim_model), 4)self.attn = Noneself.dropout = nn.Dropout(drop_prob)def forward(self, query, key, value, mask=None):if mask is not None:# 对所有 heads 使用相同的 mask.mask = mask.unsqueeze(1)batch_size = query.size(0)# 1) 对所有的 query, key, value 做线性映射,然后分成多个 heads.# query: (b, h, l_q, d_k), key: (b, h, l_k, d_k), value: (b, h, l_v, d_v).query, key, value = \[l(x).view(batch_size, -1, self.num_heads, self.d_k).transpose(1, 2)for l, x in zip(self.linears, (query, key, value))]# 2) 按 batch 对线性映射后的向量做 attention.# x: (b, h, l_q, d_k), attn: (b, h, l_q, l_k).x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout)# 3) 连接各个 head, 并作最后一层线性变换.x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.num_heads * self.d_k)return self.linears[-1](x)
2.2.4 Position-wise Feed-Forward Networks
Encode 层的第二大部分是 Position-wise Feed-Forward Network 就是一个全连接网络,包含两个线性变换和一个非线性函数(这里用的是 ReLU)。个人认为,全连接层就是作特征提取的,毕竟 Multi-Head Self Attention 只解决的长距离以来的问题,而没有做特征提取。这个全连接层的公式如下:

其中  ,
, ,
, ,
, 。在论文中
。在论文中  。
。
class PositionwiseFeedForward(nn.Module):"""FFN 的实现."""def __init__(self, d_model, d_ff, drop_prob=0.1):super(PositionwiseFeedForward, self).__init__()self.w_1 = nn.Linear(d_model, d_ff)self.w_2 = nn.Linear(d_ff, d_model)self.dropout = nn.Dropout(drop_prob)def forward(self, x):return self.w_2(self.dropout(F.relu(self.w_1(x))))
至此,encoder 部分的模型就算是搭建完了。但是从图1 中我们还可以看到,左侧 encoder 部分还有一个地方没有处理:对输入 token 序列进行预处理的 Positional Encoder & Input Embedding。
2.2.5 Input Embedding
这里 Input Embedding 很简单,就是构建一个二维浮点矩阵,形状为  ,其中
,其中  为字典中词的个数。这个 Embedding 中每一个词向量都是可训练的参数。在 Transformer 中,词向量最后要乘以一个标量因子
为字典中词的个数。这个 Embedding 中每一个词向量都是可训练的参数。在 Transformer 中,词向量最后要乘以一个标量因子  。
。
class Embeddings(nn.Module):def __init__(self, dim_model, vocab_size):super(Embeddings, self).__init__()self.embedding = nn.Embedding(vocab_size, dim_model)self.dim_model = dim_modeldef forward(self, x):return self.embedding(x) * math.sqrt(self.dim_model)
2.2.6 Positional Encoding
Positional Encoding 的目的就是我们在做 encoding 的时候,不仅仅考虑每一个词的词向量(word embedding),而且还要考虑词与词之间的关系,及上下文关系。毕竟 Transformer 即没有使用 RNN 的循环结构,也没有使用 CNN 的卷积结构,所以要对序列中的 tokens 的位置进行编码。
论文中 Positional Encoding 使用正余弦函数:


其中  为当前 token 在序列中的位置,
为当前 token 在序列中的位置, 代表当前计算的是 positional embedding 的第 个维度。可以看出,在偶数位置使用正弦编码,在奇数位置使用余弦编码。
代表当前计算的是 positional embedding 的第 个维度。可以看出,在偶数位置使用正弦编码,在奇数位置使用余弦编码。
同时,给定 token 的位置 ,得到的  为
为  维度的向量,并且每一个维度对应了一条正弦曲线,所有维度的曲线的波长构成一个从
维度的向量,并且每一个维度对应了一条正弦曲线,所有维度的曲线的波长构成一个从  到
到  的等比数列。
的等比数列。
上面的位置编码是绝对位置编码,即每一个 token 的 positional encoding 只关心自己在序列中的位置。但词语的相对位置也非常重要,这就是选择三角函数的原因:


上面的公式说明,对应 token 之间的位置偏移  ,
, 可以由
可以由  线性表示,相当于 embedding 有了可以表达相对位置的能力。代码这块,Harvard 的代码将公式中的分母转换到了对数空间进行计算,没大看懂。
线性表示,相当于 embedding 有了可以表达相对位置的能力。代码这块,Harvard 的代码将公式中的分母转换到了对数空间进行计算,没大看懂。
class PositionalEncoding(nn.Module):def __init__(self, dim_model, drop_prob, max_len=5000):super(PositionalEncoding, self).__init__()self.dropout = nn.Dropout(drop_prob)# 在对数空间中计算 positional encodings.pe = torch.zeros(max_len, dim_model, requires_grad=False)position = torch.arange(0, max_len).unsqueeze(1)div_term = torch.exp(torch.arange(0, dim_model, 2) *-(math.log(100000.0) / dim_model))pe[:, 0::2] = torch.sin(position * div_term)pe[:, 1::2] = torch.cos(position * div_term)pe = pe.unsqueeze(0)self.register_buffer('pe', pe)def forward(self, x):""":Args:`x`: input word embedding (batch_size, seq_len, dim_model)."""x = x + self.pe[:, :x.size(1)]return self.dropout(x)
下面是 Harvard 给的一个将 positional encoding 画出正弦波的图:在每一个维度上三角函数的频率和相位都不同。 注意:同一维度上不同 pos 的 PE 值在同一条正弦曲线上。
plt.figure(figsize=(15, 5))pe = PositionalEncoding(20, 0)y = pe.forward(torch.zeros(1, 100, 20))plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())plt.legend(["dim {}".format(p) for p in [4,5,6,7]])
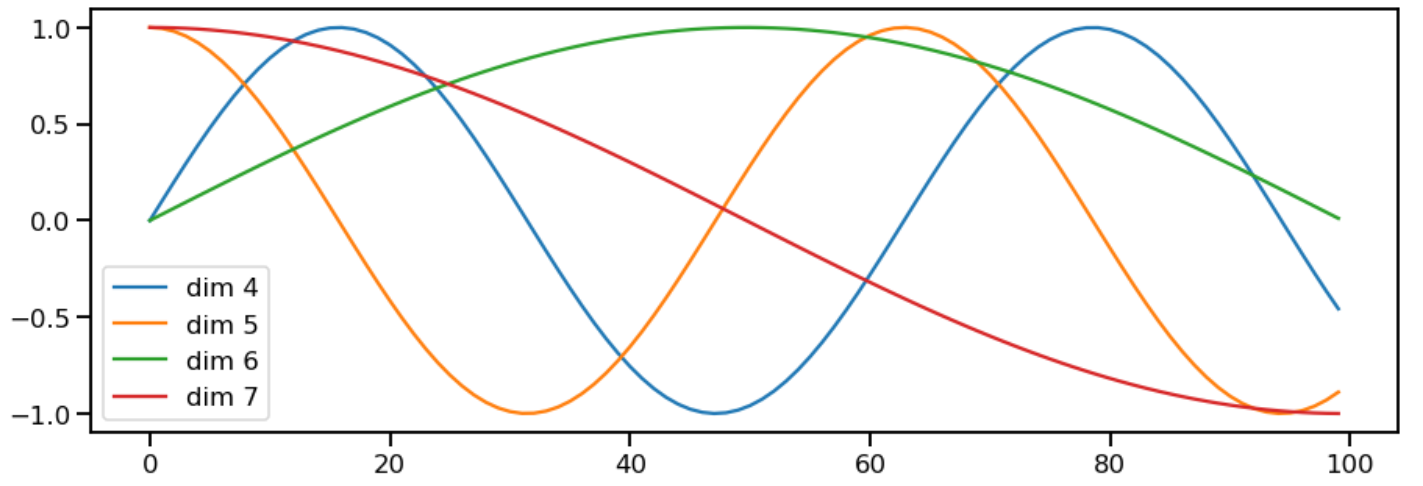
图2.4 Positional Encoding 构成正弦曲线
至此,encoder 部分就真的弄完了。
2.3 Decoder
Decoder 大部分内容在 2.2 Encoder 部分已经定义好了,所以就在搭 decoder 框架的时候顺便补充一点 encoder 没有提及的东西。
前面也说了,总的 decoder 包括 6 个完全相同的层,首先定义框架:
class Decoder(nn.Module):def __init__(self, layer, N):super(Decoder, self).__init__()self.layers = clones(layer, N)self.norm = nn.LayerNorm(layer.size)def forward(self, x, memory, src_mask, tgt_mask):for layer in self.layers:x = layer(x, memory, src_mask, tgt_mask)return self.norm(x)
然后还是回归图1,每一层 decoder 也是三部分构成,并且也是一个模块加上残差连接与 LayerNorm 构成,所以同样可以使用 3 个 2.2.2 节定义的 SublayerConnection 来完成:
class DecoderLayer(nn.Module):"""Decoder 由 self-attention, context-attention 以及 feed forward 三部分构成其中 context-attention 就是每一个 decode 层的中间部分. 在 Harvard代码中称为src-attn, 这里我们沿用这一命名."""def __init__(self, self_attn, src_attn, feed_forward, drop_prob):super(DecoderLayer, self).__init__()self.self_attn = self_attnself.src_attn = src_attnself.feed_forward = feed_forwardself.sublayer = clones(SublayerConnection(size, drop_prob), 3)def forward(self, x, memory, src_mask, tgt_mask):""":Args:`x`: 前一个 decode 层的输出.`memory`: encoder 的输出.`src_mask`: 对 encoder 输出的 mask.`tgt_mask`: 输出(目标)句子的 mask."""m = memoryx = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))return self.sublayer[2](x, self.feed_forward)
关于 mask,在 2.1 节有,不再赘述。
2.4 Transformer
接下来定义一个函数,它接受指定的超参数,并搭建一个完整的 Transformer:
def make_model(src_vocab, tgt_vocab, N=6, dim_model=512,dim_ff=2048, h=8, drop_prob=0.1):c = copy.deepcopyattn = MultiHeadedAttention(h, dim_model)ff = PositionwiseFeedForward(dim_model, dim_ff, drop_prob)pos_encoding = PositionalEncoding(dim_model, drop_prob)model = EncoderDecoder(Encoder(EncoderLayer(dim_model, c(attn), c(ff), drop_prob), N),Decoder(DecoderLayer(dim_model, c(attn), c(attn), c(ff), drop_prob), N),nn.Sequential(Embeddings(dim_model, src_vocab), c(pos_encoding)),nn.Sequential(Embeddings(dim_model, tgt_vocab), c(pos_encoding)),Generator(dim_model, tgt_vocab))for p in model.parameters():if p.dim() > 1:nn.init.xavier_uniform(p)return model
References
[1] 一文理解 Transformer
[2] 聊聊 Transformer
[3] 《Attention is All You Need》浅读
[4] Transformer 的 PyTorch 实现
[5] The Illustrated Transformer —- Transformer 可视化,强推
[6] The Annotated Transformer —- Harvard 大学代码

若有收获,就点个赞吧
0 人点赞
