创建线程
std::thread 提供了两种创建方式,都非常简单
- 方式一:使用 thread::spawn 可以创建线程,它接收一个参数、一个 FnOnce 闭包或函数。Rust 会启动一个新线程来运行该闭包或函数的代码。这个新线程是一个真实的操作系统线程,有自己的栈
use std::thread;use std::time::Duration;fn main() {thread::spawn(|| {for i in 1..10 {println!("hi number {} from the spawned thread!", i);thread::sleep(Duration::from_millis(1));}});for i in 1..5 {println!("hi number {} from the main thread!", i);thread::sleep(Duration::from_millis(1));}}
main 线程一旦结束,程序就立刻结束,因此需要保持它的存活,直到其它子线程完成自己的任务。thread::sleep 会让当前线程休眠指定的时间,随后其它线程会被调度运行,因此就算你的电脑只有一个 CPU 核心,该程序也会表现的如同多 CPU 核心一般,这就是并发

如果多运行几次,你会发现好像每次输出会不太一样,因为:虽说线程往往是轮流执行的,但是这一点无法被保证!线程调度的方式往往取决于你使用的操作系统。总之,千万不要依赖线程的执行顺序
输出锁定( Output Locking )
println 宏调用 std::io::Stdout::lock() 来确保其输出不会被中断。println!() 表达式将等待任何并发运行的表达式完成,然后再写入任何输出。如果不是这种情况,我们可以获得更多的交错输出
- 方式二:使用第二种方式创建线程,它比第一种方式稍微复杂一点,因为功能强大一点,可以在创建之前设置线程的名称和堆栈大小
use std::thread;fn main() {// 创建一个线程,线程名称为 thread1, 堆栈大小为 4klet new_thread_result = thread::Builder::new().name("thread1".to_string()).stack_size(4*1024*1024).spawn(move || { println!("I am thread1.") });// 等待新创建的线程执行完成new_thread_result.unwrap().join().unwrap();}// 执行上面这段代码,将会看到下面的输出结果I am thread1.
- Thread ID:Rust 标准库为每个线程分配了一个唯一的标识符。这个标识符可以通过 Thread::id() 访问,其类型为 ThreadId 。除了复制它并检查是否相等之外,对 ThreadId 能做的并不多。不能保证这些 ID 是连续分配的,只能保证它们对每个线程都是不同的
- Thread Builder:std::thread::spawn 函数实际上只是 std::thread::Builder::new()::spawn.unwrap() 的一个方便的简写。 std::thread::Builder 允许你再生成新线程之前为它添加一些设置。您可以使用它来配置新线程的堆栈大小并为新线程命名。线程的名称可通过 std::thread::current().name() 获得,将在恐慌消息中使用,并将在大多数平台的监控和调试工具中可见。此外, Builder 的 spawn 函数返回一个 std::io::Result ,允许您处理生成新线程失败的情况。如果操作系统内存不足,或者如果您的程序应用了资源限制,则可能会发生这种情况。如果 std::thread::spawn 函数无法生成新线程,它就会发生恐慌
等待子线程的结束
上面的代码你不但可能无法让子线程从 1 顺序打印到 10,而且可能打印的数字会变少,因为主线程会提前结束,导致子线程也随之结束,更过分的是,如果当前系统繁忙,甚至该子线程还没被创建,主线程就已经结束了。因此我们需要一个方法,让主线程安全、可靠地等所有子线程完成任务后,再 kill self
use std::thread;use std::time::Duration;fn main() {let handle = thread::spawn(|| {for i in 1..10 {println!("hi number {} from the spawned thread!", i);thread::sleep(Duration::from_millis(1));}});handle.join().unwrap();for i in 1..5 {println!("hi number {} from the main thread!", i);thread::sleep(Duration::from_millis(1));}}
通过调用 handle.join ,可以让当前线程阻塞,直到它等待的子线程的结束,在上面代码中,由于 main 线程会被阻塞,因此它直到子线程结束后才会输出自己的 1..5

如果你将 handle.join 放置在 main 线程中的 for 循环后面,那就是另外一个结果:两个线程交替输出
关于跨线程错误处理
.join() 方法为我们做了两件漂亮事
- 首先, handle.join() 返回一个 std::thread::Result ,如果子线程诧异则是一个错误。相比之下,这就让 Rust 中的线程代码比 C++ 中可靠多了。在 C++ 中,越界访问数组是未定义行为,没有任何保证系统其他部分不受该行为影响的措施。而在 Rust 中,诧异是安全且局限于每个线程的。线程之间的边界构成诧异的防火墙,即诧异不会自动从一个线程传播到依赖它的其他线程。相反,一个线程的诧异在其他线程中会体现为包含错误的 Result 。程序整体上很容易恢复。不过在我们的程序中,并没有任何多余的诧异处理代码。我们只是在 Result 上立即调用了.unwrap() ,断言它是一个 Ok 结果,而不是 Err 结果。假如某个子线程确定诧异了,那么这个断言会失败,因而父线程也会诧异。这里相当于显式将诧异从子线程传播到父线程
- 其次, handle.join() 把子线程返回的值传给了父线程。我们传给 spawn 的闭包的返回类型是 io::Result<()> ,也就是 process_files 返回值的类型。这个返回值不会被丢弃。在子线程完成时,其返回值会被保存,而 JoinHand1e::join() 会将该值传送到父线程。在这个程序中,handle.join() 返回的完整类型是 std::thread::Result
这些看起来好像还挺复杂的。但毕竞只是一行代码,因此可以跟其他语言比较一下。Java 和 C# 的默认行为是将子线程的异常抛到终端,然后就不管了。在 C++ 中,默认行为是中断进程。而在 Rust 中,错误是一种 Rust 值(数据),而不是异常(控制流)。可以像其他任何值一样跨线程传送它们。不论何时,只要编写使用低级线程 API 的代码,就必须仔细编写错误处理代码。既然必须要编写错误处理代码,那么使用 Result 没错
在线程闭包中使用 move
首先,来看看在一个线程中直接使用另一个线程中的数据会如何

以上代码在子线程的闭包中捕获了环境中的 v 变量,来看看结果
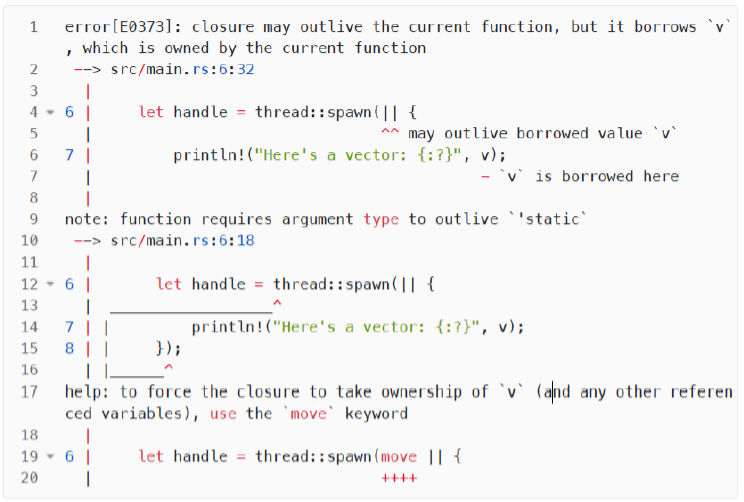
其实代码本身并没有什么问题,问题在于 Rust 无法确定新的线程会活多久(多个线程的结束顺序并不是固定的),所以也无法确定新线程所引用的 v 是否在使用过程中一直合法

大家要记住,线程的启动时间点和结束时间点是不确定的,因此存在一种可能,当主线程执行完, v 被释放掉时,新的线程很可能还没有结束甚至还没有被创建成功,此时新线程对 v 的引用立刻就不再合法。好在报错里进行了提示

让我们使用 move 关键字拿走 v 的所有权即可
use std::thread;fn main() {let v = vec![1, 2, 3];let handle = thread::spawn(move || {println!("Here's a vector: {:?}", v);});handle.join().unwrap();// 下面代码会报错 borrow of moved value: `v`// println!("{:?}",v);}
如上所示,很简单的代码,而且 Rust 的所有权机制保证了数据使用上的安全: v 的所有权被转移给新的线程后, main 线程将无法继续使用:最后一行代码将报错
线程是如何结束的(阻塞与循环)
之前我们提到 main 线程是程序的主线程,一旦结束,则程序随之结束,同时各个子线程也将被强行终止。那么有一个问题,如果父线程不是 main 线程,那么父线程的结束会导致什么?自生自灭还是被干掉?在编程系统中,操作系统提供了直接杀死线程的接口,简单粗暴,但是 Rust 并没有提供这样的接口,原因在于,粗暴地终止一个线程可能会导致资源没有释放,状态混乱等不可预期的结果,一向以安全自称的 Rust,自然不会砸自己的饭碗。那么 Rust 中线程是如何结束的呢?答案很简单:线程的代码执行完,线程就会自动结束。但是如果线程中的代码不会执行完呢?那么情况可以分两种进行讨论
- 线程的任务是一个循坏 I/O 读取,任务流程类似:IO阻塞,等待读取新的数据 -> 读取到数据,处理完成 -> 继续阻塞等待 … -> 收到 socket 关闭的信号 -> 结束进程,在此过程中,绝大部分时间线程都处于阻塞的状态,因此虽然看上去是循坏,CPU 占用其实很小,也是网络服务中最常见的模型
- 线程的任务是一个循环,里面没有任何阻塞,包括休眠这种操作也没有,此时 CPU 很不幸的会被跑满,而且你如果没有设置终止条件,该线程将持续跑满一个 CPU 核心,并且不会被终止,直到 main 线程的结束
第一情况很常见,我们来模拟看看第二种情况

以上代码中,main 线程创建了一个新的线程 A,同时该新线程又创建了一个新的线程 B,可以看到 A 线程在创建完 B 线程后就立即结束了,而 B 线程则在不停地循环输出。从之前的线程结束规则,我们可以猜测程序将这样执行:A 线程结束后,由它创建的 B 线程仍在疯狂输出,直到 main 线程在 100 毫秒后结束。如果你把该时间增加到几十秒,就可以看到你的 CPU 核心 100% 的盛况了。为什么线程内代码阻塞不会跑满CPU,而线程内代码循环会跑满CPU核心,这是因为阻塞和循环的执行方式不同
- 线程内代码阻塞
- 当线程内的代码执行过程中遇到IO操作(如网络请求、磁盘读写等)时,线程会被阻塞,进入等待状态,直到IO操作完成才能继续执行
- 在等待期间,线程不会占用CPU资源,因此不会浪费CPU资源
- 阻塞式 IO 操作通常由操作系统自动处理,通过轮询或事件通知等方式,避免了 CPU 资源的浪费
- 线程内代码循环
- 当线程内执行一个无限循环或耗时操作时,线程会持续占用CPU资源,导致 CPU 资源被耗尽
- 循环操作会导致线程一直处于运行状态,不断地执行相同的指令,无法释放 CPU 资源给其他线程使用
- 这种情况下,CPU 资源被过度使用,可能会导致系统性能下降,甚至造成死循环等问题
因此,为了避免线程内代码循环耗尽CPU资源,应该避免在循环中执行耗时操作,或者使用定时器、中断等方式控制循环的执行时间,避免无限循环。同时,可以使用多线程技术将耗时操作分配到不同的线程中执行,提高系统并发性能
作用域线程(Scoped Threads)
如果我们确定生成的线程肯定不会超过某个作用域,那么该线程可以安全地借用那些不会永远存在的东西,例如局部变量。Rust 标准库提供了 std::thread::scope 函数来生成这样的作用域线程。它允许我们生成不能超过我们传递给该函数的闭包作用域的线程(创建的线程的作用域,不超过 scope 函数总闭包的作用域),从而可以安全地借用局部变量

- 我们用闭包调用 std::thread::scope 函数。我们的闭包被直接执行,并得到一个代表范围的参数 s
- 我们使用 s 来生成线程。闭包可以借用局部变量,如 numbers
- 当作用域结束时,所有尚未 join 的线程都会自动 join
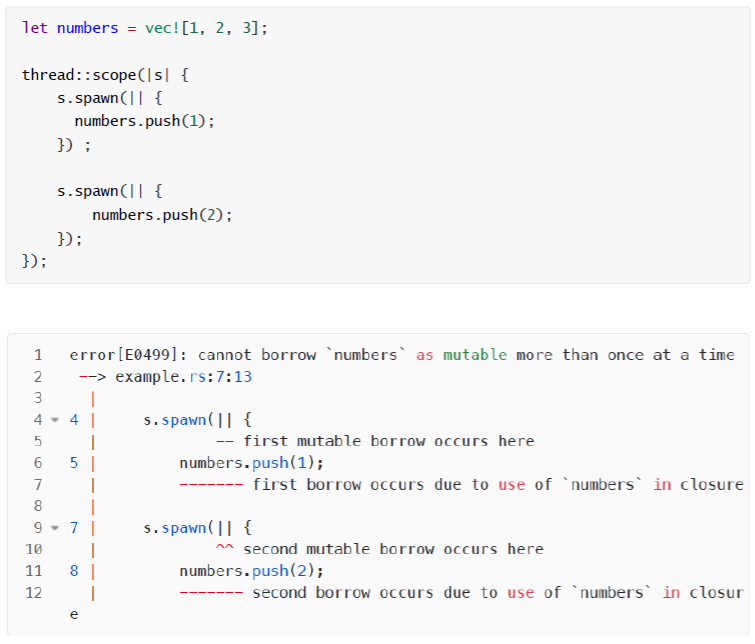
此模式保证作用域内生成的线程都不会超过作用域。因此,这个作用域 spawn 方法在其参数类型上没有绑定 ‘static ,允许我们引用任何超出作用域的东西,例如 numbers。在上面的示例中,两个新线程都并发访问 numbers 。这很好,因为它们都没有修改它。如果我们把第一个线程改为修改 numbers ,如下所示,编译器就不允许我们生成另一个也使用 numbers 的线程
多线程的性能
- 创建线程的性能:据不精确估算,创建一个线程大概需要 0.24 毫秒 ,随着线程的变多,这个值会变得更大,因此线程的创建耗时并不是不可忽略的,只有当真的需要处理一个值得用线程去处理的任务时,才使用线程,一些鸡毛蒜皮的任务,就无需创建线程了
- 创建多少线程合适
- 因为CPU的核心数限制,当任务是CPU密集型时,就算线程数超过了CPU核心数,也并不能帮你获得更好的性能,因为每个线程的任务都可以轻松让CPU的某个核心跑满,既然如此,让线程数等于CPU核心数是最好的
- 但是当你的任务大部分时间都处于阻塞状态时,就可以考虑增多线程数量,这样当某个线程处于阻塞状态时,会被切走,进而运行其它的线程,典型就是网络I/O操作,我们可以为每个进来的用户连接创建一个线程去处理,该连接绝大部分时间都是处于I/O读取阻塞状态,因此有限的CPU核心完全可以处理成百上千的用户连接线程
- 但事实上,对于这种网络I/O情况,一般都不再使用多线程的方式了,毕竟操作系统的线程数是有限的,意味着并发数也很容易达到上限,而且过多的线程也会导致线程上下文切换的代价过大,使用 async/await 的 M:N 并发模型,就没有这个烦恼
- 多线程的开销:下面的代码是一个无锁实现 CAS 的 Hashmap 在多线程下的使用
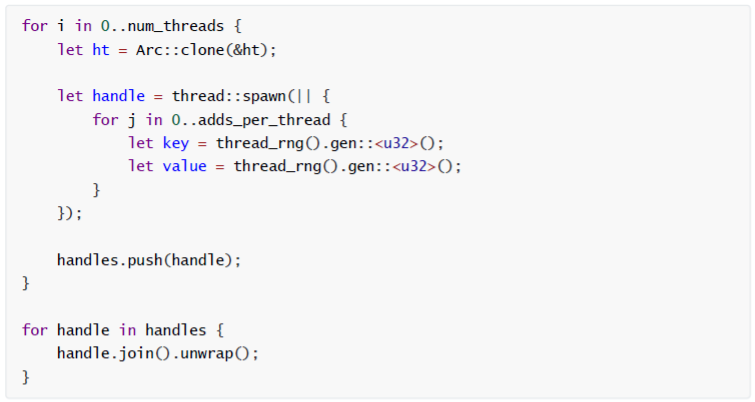
按理来说,既然是无锁实现了 ,那么锁的开销应该几乎没有,性能会随着线程数的增加接近线性增长,但是真的是这样吗?下图是该代码在 48 核机器上的运行结果
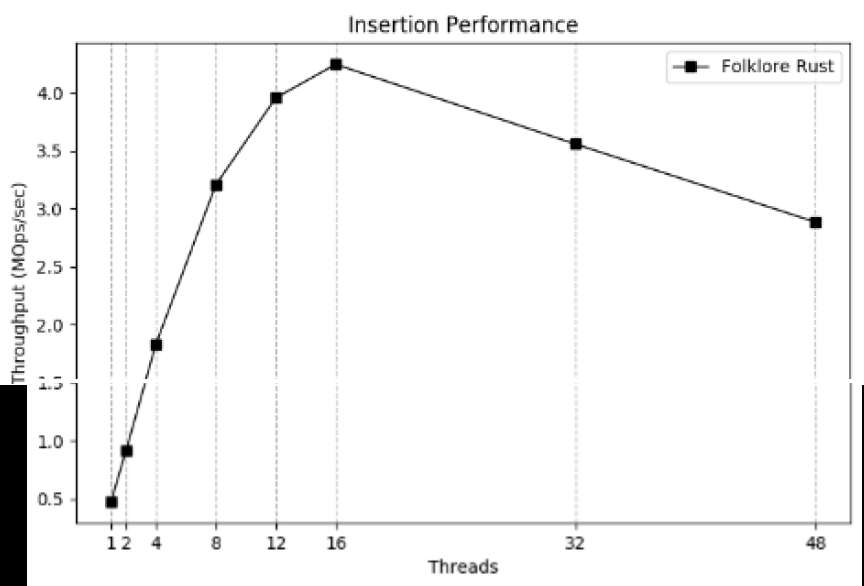
从图上可以明显的看出:吞吐并不是线性增长,尤其从16 核开始,甚至开始肉眼可见的下降,这是为什么呢?限于书本的篇幅有限,只能给出大概的原因
- 虽然是无锁,但是内部是 CAS 实现,大量线程的同时访问,会让 CAS 重试次数大幅增加- 线程过多时,CPU 缓存的命中率会显著下降,同时多个线程竞争一个 CPU Cache-line 的情况也会经常发生- 大量读写可能会让内存带宽也成为瓶颈- 读和写不一样,无锁数据结构的读往往可以很好地线性增长,但是写不行,因为写竞争太大
线程屏障(Barrier)
在 Rust 中,可以使用 Barrier 让多个线程都执行到某个点后,才继续一起往后执行

上面代码,我们在线程打印出 before wait 后增加了一个屏障,目的就是等所有的线程都打印出 before wait 后,各个线程再继续执行

线程局部变量(Thread Local Variable)
对于多线程编程,线程局部变量在一些场景下非常有用,而 Rust 通过标准库和三方库对此进行了支持
标准库 thread_local
使用 thread_local 宏可以初始化线程局部变量,然后在线程内部使用该变量的 with 方法获取变量值

上面代码中, FOO 即是我们创建的线程局部变量,每个新的线程访问它时,都会使用它的初始值作为开始,各个线程中的 FOO 值彼此互不干扰。注意 FOO 使用 static 声明为生命周期为 ‘static 的静态变量。可以注意到,线程中对 FOO 的使用是通过借用的方式,但是若我们需要每个线程独自获取它的拷贝,最后进行汇总,就有些强人所难了。你还可以在结构体中使用线程局部变量

或者通过引用的方式使用它

三方库 thread-local
除了标准库外,一位大神还开发了 thread-local 库,它允许每个线程持有值的独立拷贝

该库不仅仅使用了值的拷贝,而且还能自动把多个拷贝汇总到一个迭代器中,最后进行求和,非常好用
用条件控制线程的挂起和执行
条件变量( Condition Variables )经常和 Mutex 一起使用,可以让线程挂起,直到某个条件发生后再继续执行

上述代码流程如下
- main 线程首先进入 while 循环,调用 wait 方法挂起等待子线程的通知,并释放了锁 started
- 子线程获取到锁,并将其修改为 true,然后调用条件变量的 notify_one 方法来通知主线程继续执行
让函数在多线程环境下只调用一次
有时,我们会需要某个函数在多线程环境下只被调用一次,例如初始化全局变量,无论是哪个线程先调用函数来初始化,都会保证全局变量只会被初始化一次,随后的其它线程调用就会忽略该函数
use std::thread;use std::sync::Once;static mut VAL: usize = 0;static INIT: Once = Once::new();fn main() {let handle1 = thread::spawn(move || {INIT.call_once(|| {unsafe { VAL = 1; }});});let handle2 = thread::spawn(move || {INIT.call_once(|| {unsafe { VAL = 2; }});});handle1.join().unwrap();handle2.join().unwrap();println!("{}", unsafe { VAL });}
代码运行的结果取决于哪个线程先调用 INIT.call_once (虽然代码具有先后顺序,但是线程的初始化顺序并无法被保证!因为线程初始化是异步的,且耗时较久),若 handle1 先,则输出1,否则输出2
- call_once 方法:执行初始化过程一次,并且只执行一次。如果当前有另一个初始化过程正在运行,线程将阻止该方法被调用。当这个函数返回时,保证一些初始化已经运行并完成,它还保证由执行的闭包所执行的任何内存写入都能被其他线程在这时可靠的观察到
附加:全局变量详解
在从编译期初始化及运行期初始化两个类别来介绍下全局变量有哪些类型及该如何使用
编译期初始化
我们大多数使用的全局变量都只需要在编译期初始化即可,例如静态配置、计数器、状态值等等
- 静态常量:全局常量可以在程序任何一部分使用,当然,如果它是定义在某个模块中,你需要引入对应的模块才能使用。常量,顾名思义它是不可变的,很适合用作静态配置

- 常量与普通变量的区别
- 关键字是 const 而不是 let
- 定义常量必须指明类型(如 i32 )不能省略
- 定义常量时变量的命名规则一般是全部大写
- 常量可以在任意作用域进行定义,其生命周期贯穿整个程序的声明周期。编译时编译器会尽可能将其内联到代码中,所以在不同地方对同一常量的引用并不能保证引用到相同的内存地址
- 常量的赋值只能是常量表达式/数学表达式,也就是说必须是在编译期就能计算出的值,如果需要在运行时才能得出结果的值比如函数,则不能赋值给常量表达式
- 对于变量出现重复的定义(绑定)会发生变量遮盖,后面定义的变量会遮盖前面定义的变量,常量则不允许出现重复的定义
- 静态变量:静态变量允许声明一个全局的变量,常用于全局数据统计,例如我们希望用一个变量来统计程序当前的总请求数

Rust 要求必须使用 unsafe 语句块才能访问和修改 static 变量,因为这种使用方式往往并不安全,其实编译器是对的,当在多线程中同时去修改时,会不可避免的遇到脏数据。只有在同一线程内或者不在乎数据的准确性时,才应该使用全局静态变量。和常量相同,定义静态变量的时候必须赋值为在编译期就可以计算出的值(常量表达式/数学表达式),不能是运行时才能计算出的值(如函数)
- 原子类型


运行期初始化
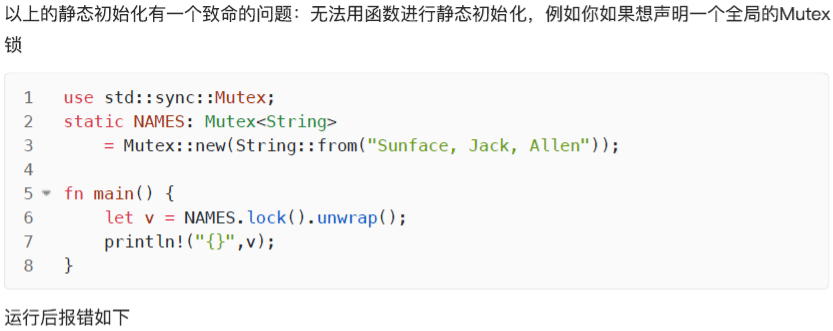
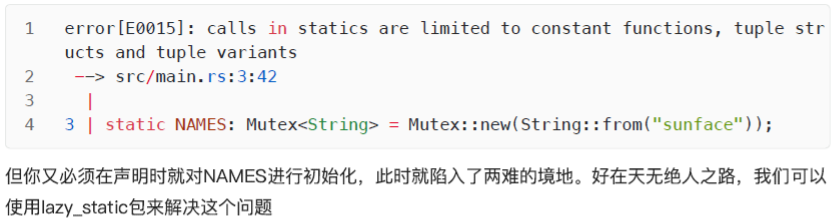
lazy_static
lazy_static 是社区提供的非常强大的宏,用于懒初始化静态变量,之前的静态变量都是在编译期初始化的,因此无法使用函数调用进行赋值,而 lazy_static 允许我们在运行期初始化静态变量

当然,使用 lazy_static 在每次访问静态变量时,会有轻微的性能损失,因为其内部实现用了一个底层的并发原语 std::sync::Once ,在每次访问该变量时,程序都会执行一次原子指令用于确认静态变量的初始化是否完成。lazy_static 宏,匹配的是 static ref ,所以定义的静态变量都是不可变引用。可能会问,为何需要在运行期初始化一个静态变量,除了上面的全局锁,你会遇到最常见的场景就是:一个全局的动态配置,它在程序开始后,才加载数据进行初始化,最终可以让各个线程直接访问使用。再来看一个使用 lazy_static 实现全局缓存的例子
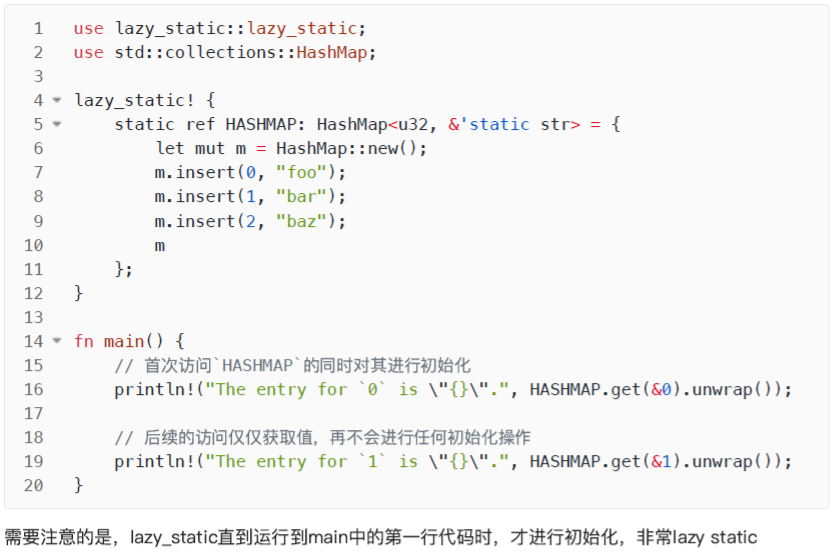
Box::leak
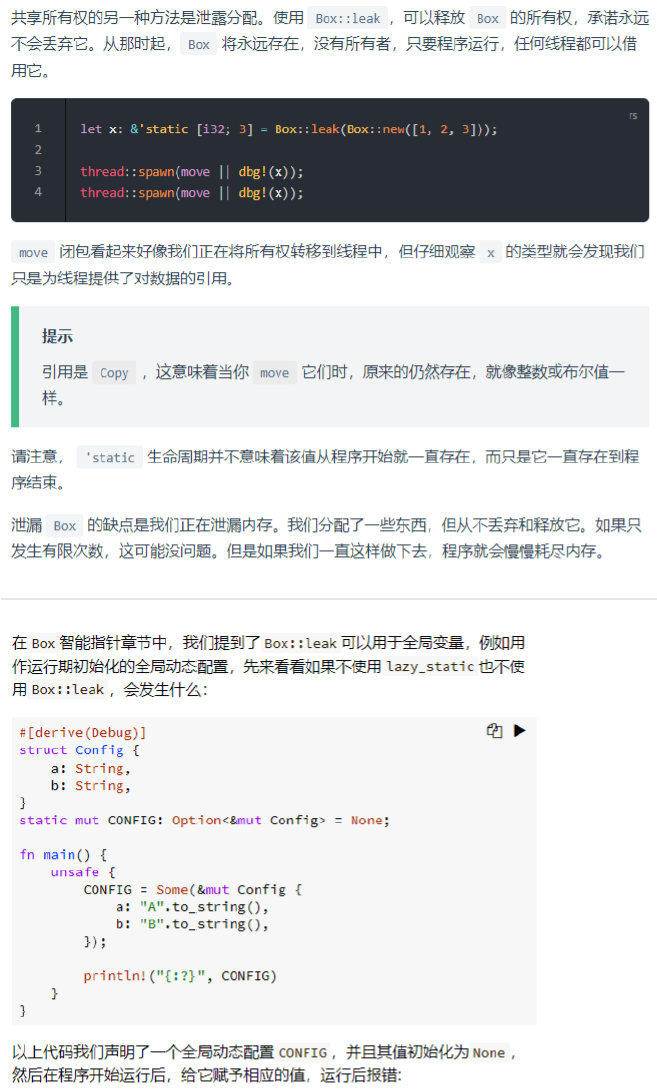

从函数中返回全局变量

标准库中的 OnceCell

总结
在 Rust 中有很对方式可以创建一个**全局变量**,本章也只是介绍了其中一部分,更多的还等待大家自己去挖掘学习。简单来说,全局变量可以分为两种
- 编译期初始化的全局变量, const 创建常量,static 创建静态变量,Atomic 创建原子类型
- 运行期初始化的全局变量, lazy_static 用于懒初始化, Box::leak 利用内存泄漏将一个变量的生命周期变为 ‘static

若有收获,就点个赞吧
0 人点赞
