副本控制协议指按照特定的协议流程控制副本的读写行为,是的副本满足一定的可用性和一致性要求的分布式协议。本章将讨论两大类型的副本控制协议:中心化副本控制协议和去中心化副本控制协议
中心化副本控制协议
中心化副本控制协议的特点是由一个中心节点控制副本数据的更新、维护副本间的一致性
优点:
- 协议相对简单,跟副本有关的操作都交给中心节点完成
缺点:
- 系统的可用性过于依赖中心节点,中心节点异常时会导致服务不可用
一个中心化副本控制模型如下: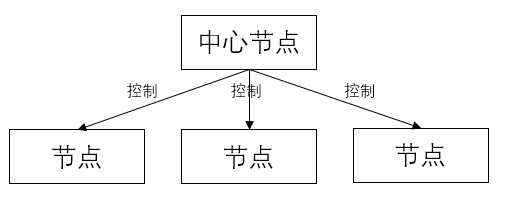
本节着重介绍一种常用的 primary-secondary (也称 primary-backup)的中心化副本控制协议,在该协议中,副本被分为;两大类,其中有且仅用一个作为 primary 副本,除 primary 副本为都作为 secondary 副本。维护 paimary 副本的节点称为中心节点,中心节点负责维护数据的更新、并发控制、协调副本的一致性
primary-secondary 类型协议一般要解决四大问题:
- 数据更新流程
- 数据读取方式
- primary 副本的确定和切换
- 数据同步
数据更新流程
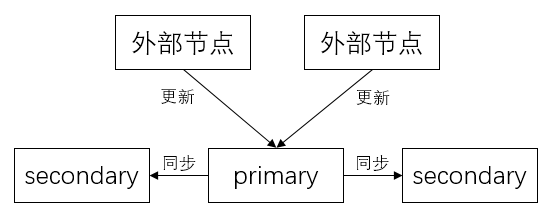
- 外部节点将数据更新操作发给 primary 节点,数据更新操作都由 primary 节点完成
- primary 节点进行并发控制,确定更新的先后顺序
- primary 节点将更新操作发给各个节点
- primary 节点根据各个节点的反馈将更新结果返回给外部应用
基本更新流程如下图所示:
在工程实践中,如果由 priamry 节点将数据同时发送给N个副本,则 secondary 的更新速度受限于 primary 的网络出口带宽,最大为 1/N。为了解决这个问题,有些系统(例如:GFS)采用接力的方式,即 primary 发给第一个 secondary 副本,第一个 secondary 发给第二个 secondary 系统,以此类推。第3步可能在某些副本上成功,在某些副本失败,在某些副本上超时,不同的副本控制协议对该步的处理方式不同。如提供最终一致性协议的系统,允许 secondary 与 primary 不一致,只要最后慢慢同步成一致即可。后面会介绍一种称为 Quorum 的副本控制机制,这里不做展开。第4步依赖于第3步的结果,这里也先不做讨论
数据读取方式
数据读取也与一致性密切相关,需要满足下列一致性时要做的处理
- 最终一致性:读取任意副本即可
- 会话一致性:给副本设置版本好即可,每次更新后递增版本号,保证读到的数据再会话中单调递增
- 强一致性:
- 只读 primary 副本。此时 secondary 将不提供读服务。如果副本不与机器绑定,而是以数据段为单位分布在各个节点上,那么只由 primary 副本提供读服务很多情况下不会造成资源浪费
- 由 primary 节点控制 secondary 节点的可用性。当某个 secondary 副本更新失败时,primary 标记该节点不可用,直到更新成功再恢复
- 基于 Quorum 机制
primary 副本的确定和切换
在 primary-secondary 类型的协议中,如何确定 primary 副本是另一个核心问题。尤其是在 primary 副本宕机时,如何选择一个 secondary 副本成为新的 primary 副本
通常的,在 primary-secondary 类型的分布式系统中,哪个副本是 primary 这一信息属于元数据信息,由专门的元数据服务器维护。执行更新操作时,会先查询元数据服务器获取 primary 信息,再更新副本
切换副本的难点在于两方面:
- 如何确定节点状态以发现原 primary 节点异常(后面会介绍 Lease 机制确定节点状态的方法)
- 切换 primary 节点不能影响副本一致性。一种简单的方法是切换的新的 primary 副本上的数据需要与原 primary 的数据相同,然而当 primary 宕机时,如何确定 secondary 上的数据与原 primary 上的数据相同又成了一个新的问题,这与上节中从一个 secondary 副本读取最新的数据是个等价问题。后面会介绍 Quorum 机制来确定新的 primary
由于分布式系统中发现节点异常是需要一定探测时间的,这样的探测时间一般是10s级别,这就导致 primary 异常时,最多需要10s的时间来发现节点异常并切换新的 primary,如果是从 primary 读取新数据的方式,会导致这10s无法提供读服务。从这可以看到,primary-secondary 协议最大的问题是切换 primary 会带来一定的停服务时间
数据同步
primary-secondary 型协议都会遇到 primary 与 secondary 数据不一致的问题,通常有下面三种情形:
- 由于网络分化等问题,secondary 上的数据落后于 primary 的数据。这种情形下,通常采用回放日志的形式来同步落后的数据(通常是redo日志,后面会详细讨论日志技术)
- 某些协议下,secondary 上存在脏数据。脏数据指 secondary 执行多余的更新操作产生的副本错误数据。一般较好的做法是设计不产生脏数据的分布式协议,如果不可避免,则尽可能降低概率,使得产生脏数据时能简单的丢弃有脏数据的版本,从而使其变成一个没有数据的新副本。另外,也可以使用undo日志来删除脏数据
- secondary 是一个新增的副本,完全没有数据。常见的做法是直接从 primary 拷贝数据,如果此时需要 primary 继续提供服务,则需要 primary 副本能够提供快照(snapshot)功能,即对某一刻的副本数据形成快照,然后拷贝快照,拷贝完成后使用 redo 日志同步快照点后的新数据
去中心化副本控制协议
去中心化副本控制协议没有中心节点,所有节点都是对等的,节点之间通过协商达到一致
优点:
- 去中心化副本控制协议不会带来由于中心节点异常而导致服务中断的问题
缺点:
- 协议相对复杂
- 性能和效率较中心化副本控制协议低
各类去中心化的协议各有各的巧妙,本节先不做介绍。Paxos 协议是唯一在工程中得到应用的强一致性去中心化副本控制协议,后续会做详细介绍
工程投影
这里简要介绍几种典型分布式系统在副本控制协议方面的特点。工程中大量的副本控制协议都是 primary-secondary 协议。
GFS
GFS 系统的副本控制协议是典型的 Primary-Secondary 型协议,Primary 副本由 Master 指定,Primary 副本决定并发更新操作的顺序。虽然在 GFS 中,更新操作的数据由客户端提交,并在各个副本之间流式的传输,及由上一个副本传递到下一个副本,每个副本都即接受其他副本的更新,也向下更新另一个副本,但是数据的更新过程完全是由 primary 控制的,所以也可以认为数据是由primary 副本同步到 secondary 副本的
PNUTS
PNUTS 的副本控制协议也是典型的 primary-secondary 型协议。Primary 副本负责将更新操作向YMB 中提交,当更新记录写入 YMB 则认为更新成功。YMB 本身是一个分布式的消息发布、订阅系统,其具有多副本、高可用、跨地域等特性。Secondary 副本向 YMB 订阅 primary 发布的更新操,当收到更新操作后,secondary 副本更新本地数据。从而,数据的更新过程也完全是由 primary副本进行控制的
Niobe
Dynamo/Cassandra 使用基于一致性哈希的去中心化协议。虽然 Dynamo 尝试通过引入 Quorum机制和 vector clock 机制解决读取数据的一致性问题,但其一致性模型依旧是一个较大的问题。由于缺乏较好的一致性,应用在编程时的难度被大大增加了。后面会详细分析 Dynamo 的一致性模型及其优缺点
Dynamo/Cassandra
Dynamo/Cassandra 使用基于一致性哈希的去中心化协议。虽然 Dynamo 尝试通过引入 Quorum机制和 vector clock 机制解决读取数据的一致性问题,但其一致性模型依旧是一个较大的问题。由于缺乏较好的一致性,应用在编程时的难度被大大增加了。后面会详细分析 Dynamo 的一致性模型及其优缺点
Chubby/Zookeeper
Chubby Zookeeper 使用了基于 Paxos 的去中心化协议选出 primary 节点,但完成 primary 节点的选举后,这两个系统都转为中心化的副本控制协议,即由 primary 节点负责同步更新操作到secondary 节点
Megastore
虽然都使用了 Paxos 协议,但与 Chubby 和 Zookeeper 不同的是,Megastore 中每次数据更操作都基于一个改进的 Paxos 协议的实例,而不是利用 paxos 协议先选出 primary 后,再转为中心化的primary-secondary 方式
Mola/Armor/Big Pipe
Mola/Armor和 Big Pipe也无一例外的使用了 Primary-secondary 协议控制副本

若有收获,就点个赞吧
0 人点赞
