自身业务
业务oa跳转平台
同步用户的信息(涉密不同步)到平台
业务oa登录后,跳转平台式生成token,token内携带用户的信息(包括唯一id等)
平台校验token,解析,生成session信息放到redis
直接登录平台,平台跳转业务oa
同步用户的信息(涉密不同步)到平台,
用户平台登录,生成token,调用oa的用户校验接口
oa校验token,解析,校验,返回校验结果
返回true,生成session信息放到redis
二维码跳转
- 扫码二维码本质是访问二维码携带对应链接
- 部分app对相关二维码可以定制一定的规范,比如用丰*App扫定制二维码,会打开对应微服务(H5)指定页面
-
网址码(二维码)
网址码跳转原理
二维码的内容本质上是一串字符串,
扫码设备或应用软件先通过识别二维码图案,读取这个字符串,
然后识别到这串字符带上了Http或Https协议,认为这是一串“可跳转的网址”,
并且没有触发该应用的跳转限制,就会跳转打开该网页。跳转限制
可能会由于扫码应用的不同或限制,而无法实现最终的跳转。
比如说微信的扫一扫功能,识别到二维码内容是未带上Http或Https协议的字符串(如www.baidu.com),就只会显示出这个内容,不会做页面跳转,
- 而手机的主流浏览器扫码识别后,一般会自动为这类字符串加上Http或Https协议,从而可以实现跳转。
以及一部分扫码应用软件会在识别到特定网址时做限制跳转,如微信识别到二维码要跳转的网址包含淘宝域名,会无法直接跳转。
一码多用:扫描一个二维码自动跳转支付宝/微信小程序、安卓/iosAPP
四种不同渠道
如果要实现一码多用,我们就需要一个中转页,进入中转页之后,根据根据不同的条件,然后跳转到不同的app渠道.
在跨平台、浏览器、移动设备兼容的时候,要根据设备、浏览器做特定调整,所以我们经常会用到navigator.userAgent.toLowerCase()来进行判断.先来解释一下意思,navigator是HTML中的内置对象,包含浏览器的信息;
- userAgent是navigator的属性方法,可以返回由客户机发送服务器的头部的值,作用其实就是就是返回当前用户所使用的是什么浏览器;
- toLowerCase()是将转换为小写.
var ua = navigator.userAgent.toLowerCase();if (ua.match(/MicroMessenger/i) == "micromessenger") {return 'wx';} else if (ua.match(/alipayclient/i) == "alipayclient") {return "zfb";} else {if (ua.match(/android/i) == "android") {return 'android'} else if(ua.match(/iphone/i) == "iphone" || ua.match(/ipad/i) == "ipad"){return 'ios'}}
跳转
二维码也可以穿参数,只要协议制定好就可以
支付宝和小程序都是经过加密之后的短连接,支付宝通过,location.href=’支付宝短连接地址’可以直接跳转到支付宝小程序,
但是微信是不可以的,我们可以当微信扫描的时候,弹出微信小程序的二维码让用户长按识别自动跳转
注:如跳转微信公共号,只能传一个参数,因为多个参数,后面的参数微信会过滤掉,如果需要传多参,可以这样,比如?id=i&name=2换种规则 id_name=1_2.这样,之后再解析.
页面重定向
获取参数问题:判断此时打开微服务方式(正常打开还是扫码打开)
- 解决办法:调用window.location获取url信息,再根据window.location.search //(返回url查询部分)获取参数。
参数带@ * / : 等特殊符号问题:url参数带特殊符号会使得参数丢失或者获取参数失败。
- 解决办法:encodeURIComponent(url)对参数进行加密,转换特殊字符,获取参数解码调用decodeURIComponent(url)解码。
页面重定向问题:获取Url参数,解码参数Url后,前端进行页面重定向
解决办法:直接在解码后的url拼接参数调用window.location.href=url方法跳转。
短链接原理
短链接
短链接即是长度较短的网址。通过短链接技术,我们可以将长度较长的链接压缩成较短的链接。并通过跳转的方式,将用户请求由短链接重定向到长链接上去。
短链接主要用在诸如微博,BBS等对帖子字数有限制的网站,
通过使用短链接,用户可以把注意力放在帖子的内容上,而不是在担心链接超长的问题。以百度的 dwz.cn 短链接服务为例
我们使用百度搜索”hello world”,链接为 https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=baidu&wd=hello%20world&rsv_pq=8487bffe00068c60&rsv_t=a9e0f5b6haiMQwAi4N2y8PHDv37rM6sjjKrHJb6KdMGg2dQuUjAnmSEnXtE&rqlang=cn&rsv_enter=1&rsv_sug3=10&rsv_sug1=9&rsv_sug7=100,统计了一下,这条链接长度为230。
如此长的链接占据微博篇幅不说,也会影响微博的美观度。这个时候我们可以使用百度短链接服务压缩一下上面的长链接,压缩后的链接为:http://dwz.cn/5DDXhH。可以看到,压缩后的链接长度比原链接明显变短了。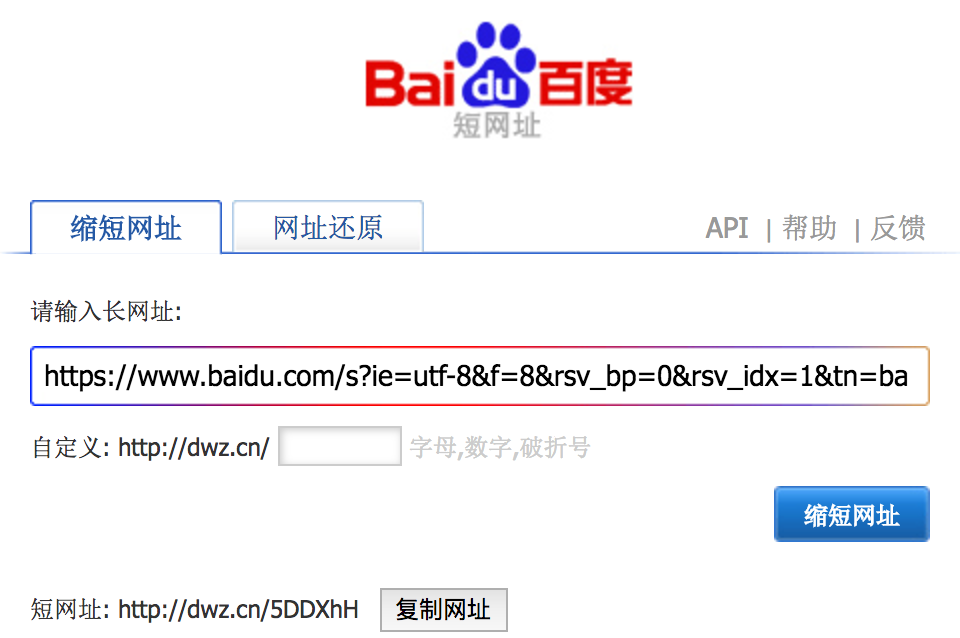
常见的短链接压缩算法
常见的短链接压缩算法有两种,
第一种是对 URL 进行hash运算,在得到的hash值上做进一步运算,得到一个较短的hash值。hash运算简单易实现,但是有一定的冲突率。随着 URL 压缩数量的增加,冲突数也会增加,最终导致一部分用户跳转到错误的地址上,影响用户体验
第二种是通过数据库自增ID或分布式key-value系统模拟发号器进行发号压缩URL
- 发号器发号压缩 URL 优缺点恰好和hash压缩算法相反,优点是不存在冲突问题。缺点是,实现上稍复杂,要协调发号器取初始号。
使用发号策略压缩URL
发号
发号策略是这样的,当一个新的链接过来时,发号器发一个号与之对应。往后只要有新链接过来,发号器不停发号就好。举个例子,第一个进来的链接发号器发0号,对应的短链接为 xx.xxx/0,第二个进来的链接发号器发1号,对应的短链接为 xx.xxx/1,以此类推。压缩
发号器发出的10进制号需要转换成62进制,这样可以大大缩短号码转换成字符串后的长度。比如发号器发出 10,000,000,000 这个号码,如果不转换成62进制,直接拼接在域名后面,得到这样一个链接 xx.xxx/10000000000。将上面的号码转换成62进制,结果为AOYKUa,长度只有6位,拼接得到的链接为 xx.xxx/AOYKUa。可以看得出,进制转换后得到的短链接长度变短了一些。6位62进制数,对应的号码空间为626,约等于568亿。也就是说发号器可以发568亿个号,这个号码空间应该能够满足多数项目的需求了,所以基本上不用担心发号器无号可发的情况。
上述是发号策略压缩URL的原理,实际在写代码的过程中还需要考虑很多细节,比如缓存,存储等。本文对应的项目使用的缓存是 Guava 工具包中提供的缓存模块,数据库使用的是 MySQL。基于上述两个工具以及其他一些第三方库,项目实现了URL压缩,还原以及跳转功能三个基础的功能。
几个细节问题
同一长链接,每次转成的短链接是否一样
A:同一长链接,每次转成的短链接不一定一样,
原因在于如果查询缓存时,如果未命中,发号器会发新号给这个链接。
- 需要说明的是,缓存应该缓存经常转换的热门链接,假设设定缓存过期时间为一小时,如果某个链接很活跃的话,缓存查询命中后,缓存会刷新这个链接的存活时间,重新计时,这个链接就会长久存在缓存中。
- 对于一些生僻链接,从存入缓存开始,在存活时间内很可能不会被再次访问,存活时间结束缓存会删除记录。下一次转换这个生僻链接,缓存不命中,发号器会重新发号。
思考:这样一来会导致一条长链接对应多条短链接的情况出现,不仅浪费存储空间,又浪费发号器资源。那么是否有办法解决这个问题呢?
是不是可以考虑建立一个长链接-短链接的key-value表,将所有的长链接和对应的短链接都存入其中,这样一来就实现了长短链接一一对应的了。但是想法是美好的,现实是不行的,原因在于,将所有的长链接-短链接对存入这样的表中,本身就需要耗费大量的存储空间,相对于生僻链接可能会对应多条短链接浪费的那点空间,这样做显然就得不偿失了。
短链接使用301跳转还是302跳转
A:301和302的跳转在短链接服务使用场景下的区别:
301:用户第一次访问某个短链接后,如果服务器返回301状态码,则这个用户在后续多次访问同一短链接时,浏览器会直接请求跳转地址,而不是短链接地址,这样一来服务器端就无法收到用户的请求。
- 从语义上来说,301跳转更为合适,因为是永久跳转,不会每次都访问服务端,还可以减小服务端压力。但如果使用301跳转,服务端就无法精确搜集用户的访问行为了。
302:如果服务器返回302状态码,且告知浏览器不缓存短链接请求,那么用户每次访问短链接,都会先去短链接服务端取回长链接地址,然后在跳转。
- 相反302跳转会导致服务端压力增大,但服务端此时就可精确搜集用户的访问行为。基于用户的访问行为,可以做一些分析,得出一些有意思的结论。比如可以根据用户IP地址得出用户区域分布情况,根据User-Agent消息头分析出用户使用不同的操作系统以及浏览器比例等等。

若有收获,就点个赞吧
0 人点赞
