
DOM是文档对象模型,全称为Document Object Model。DOM用一个逻辑树来表示一个文档,树的每个分支终点都是一个节点,每个节点都包含着对象。DOM提供了对文档结构化的表述,通过绑定不同的事件可以改变文档的结构、样式和内容,从而能实现“动态”的页面。
DOM选择器
传统原生JavaScript选择器
getElementById()
通过id定位元素,返回匹配到id的第一个元素。当具有相同id的元素时,除了第一个元素能被匹配到外,其他元素都会被忽略。
getElementsByClassName()
通过类名定位元素,返回由匹配到的元素构成的HTMLCollection对象,它是一个类数组结构。
<li class="one">节点1</li>
<li class="one">节点2</li>
document.getElementsByClassName('one');
// HTMLCollection(2) [li.one, li.one]
// - 0: li.one
// - 1: li.one
// - length: 2
// - __proto__: HTMLCollection
getElementsByTagName()
通过元素标签名定位元素,返回由匹配到的元素构成的HTMLCollection对象。
document.getElementsByTagName('li');
// HTMLCollection(2) [li, li]
// - 0: li
// - 1: li
// - length: 2
// - __proto__: HTMLCollection
getElementsByName()
通过元素的name属性进行定位,返回由匹配到的元素构成的NodeList对象,它是一个类数组结构。
<li name="node">节点1.</li>
<li name="node">节点2</li>
document.getElementsByName('node');
// NodeList(3) [li, li, li]
// - 0: li
// - 1: li
// - 2: li
// - length: 3
// - __proto__: NodeList
新型选择器
使用传统的id、name、class等选择器来查找元素时,只能调用document具有的函数,在查找特定元素的子元素时不太方便。querySelector选择器和querySelectorAll选择器是在W3C DOM4中新增的。
querySelector选择器
querySelector选择器返回的是整个文档里匹配到的并且属于基准元素的后代元素里的第一个元素。
语法:element = baseElement.querySelector(selectors);
参数:baseElement基准元素,返回的元素必须是匹配到的基准元素的第一个子元素。该基准元素可以为Document,也可以为基本的Element,要想使用基本的Element,则必须先用Document获取到。selectors标准的CSS选择器,而且必须是合法的选择器,否则会引起语法错误。element为匹配到的第一个子元素。匹配的过程中不仅仅针对基准元素的后代元素,实际上会遍历整个文档结构,包括基准元素和它的后代元素以外的元素。优先在整个文档里匹配到selectors,判断每个元素是否为基准元素的后代元素,第一个属于基准元素的后代元素将会被返回。
<div>
<h5>Original content</h5>
<span>outside span</span>
<p class="content">
inside paragraph
<span>inside span</span>
inside paragraph
</p>
</div>
<script>
// 获取p元素的第一个span元素
document.querySelector('p span').innerText; // inside span
// 获取class为content的元素的第一个span元素
document.querySelector('.content span').innerText; // inside span
// 获取第一个span或者h5元素
document.querySelector('h5, span').innerText // Original content
var element = document.querySelector("p");
// p标签里没有div标签,但优先在整个文档里匹配div标签里的span标签,所以最后返回同属于p标签里的span标签
console.log(element.querySelector("div span").innerText); // inside span
</script>
querySelectorAll选择器
querySelectorAll选择器会返回基准元素下匹配到的所有子元素的集合。
<div id="my-id">
<img id="inside">
<div class="lonely"></div>
<div class="outer">
<div class="inner"></div>
</div>
</div>
<script>
var firstArr = document.querySelectorAll('#my-id div div');
var secondArr = document.querySelector('#my-id').querySelectorAll('div div');
console.log(firstArr);
//NodeList(1)
// 0: div.inner
// length: 1
// __proto__: NodeList
console.log(secondArr);
// NodeList(3)
// 0: div.lonely
// 1: div.outer
// 2: div.inner
// length: 3
// __proto__: NodeList
</script>
代码解析:secondArr的基准元素是id为“my-id”的元素,然后执行CSS选择器,选择器的内容是匹配div元素中的子div元素:
- id为“my-id”的div元素的第一个子节点。
<div class="lonely"></div> - id为“my-id”的div元素的第二个子节点。
<div class="outer">...</div> - class为“outer”的div元素的第一个子节点。
<div class="inner"></div>
getElementById与querySelectorAll不同点:如果出现了相同的id,getElementById()函数获取到除第一个元素以外的元素。但是querySelectorAll可以获取多个匹配的元素。但是,不允许一个页面出现相同id的元素。
HTMLCollection对象与NodeList对象
<div id="main">
<p class="first">first</p>
<p class="second">second<span>content</span></p>
</div>
<script>
var main = document.getElementById("main");
console.log(main.children);
// HTMLCollection(2) [p.first, p.second]
// - 0: p.first
// - 1: p.second
// - length: 2
// - __proto__: HTMLCollection
console.log(main.childNodes);
// NodeList(5) [text, p.first, text, p.second, text]
// - 0: text
// - 1: p.first
// - 2: text
// - 3: p.second
// - 4: text
// - length: 5
// - __proto__: NodeList
</script>
对getElementById()调用children属性,返回的是HTMLCollection对象,调用childNodes属性,返回的是NodeList对象。
HTMLCollection对象
HTMLCollection对象具有length属性,返回集合的长度,可以通过item ()函数和namedItem()函数来访问特定的元素。
item()函数
HTMLCollection对象可以调用item()函数,通过序号来获取特定的某个节点,超过索引则返回“null”。
<div id="main">
<p class="first">first</p>
<p class="second">second</p>
<p class="third">third</p>
<p class="four">four</p>
</div>
<script>
var main = document.getElementById("main").children;
console.log(main.item(0)); // <p class="first">first</p>
console.log(main.item(2)); // <p class="third">third</p>
</script>
namedItem()函数
namedItem()函数用来返回一个节点。首先通过id属性去匹配,然后如果没有匹配到则使用name属性匹配,如果还没有匹配到则返回“null”。当出现重复的id或者name属性时,只返回匹配到的第一个值。
<form id="main">
<input type="text" id="username">
<input type="text" name="username">
<input type="text" name="password">
</form>
<script>
var main = document.getElementById("main").children;
console.log(main.namedItem('username')); // <input type="text" id="username">
</script>
NodeList对象
NodeList对象也具有length属性,返回集合的长度,只具有item()函数,通过索引定位子元素的位置。
实时性
HTMLCollection对象和NodeList对象并不是历史文档状态的静态快照,而是具有实时性的。对DOM树新增或者删除一个相关节点,都会立刻反映在HTMLCollection对象与NodeList对象中。
HTMLCollection对象与NodeList对象都只是类数组结构,并不能直接调用数组的函数。而通过call()函数和apply()函数处理为真正的数组后,它们就转变为一个真正的静态值了,不会再动态反映DOM的变化。
<form id="main">
<input type="text" id="username">
<input type="text" name="password">
</form>
<script>
// 获取HTMLCollection
var mainChildren = document.getElementById('main').children;
console.log(mainChildren.length); // 2
// 新增一个input元素
var newInput = document.createElement('input');
console.log("🚀 ~ main", main)
main.appendChild(newInput);
console.log(mainChildren.length); // 3
// 通过call()函数处理成数组结构
mainChildren = Array.prototype.slice.call(mainChildren, 0);
mainChildren.splice(1, 1);
console.log(mainChildren.length); // 2
// 再新增一个input元素
var newInput2 = document.createElement('input');
main.appendChild(newInput2);
console.log(mainChildren.length); // 2
</script>
通过querySelectorAll()函数获取的NodeList对象不是实时的,必须要重新获取才是最新的值。
HTMLCollection和NodeList异同
(1)相同点
- 都是类数组对象,有length属性,可以通过call()函数或apply()函数处理成真正的数组。
- 都有item()函数,通过索引定位元素。
- 都是实时性的,DOM树的变化会及时反映到HTMLCollection对象和NodeList对象上,只是在某些函数调用的返回结果上会存在差异。
(2)不同点
- HTMLCollection对象比NodeList对象多个namedItem()函数,可以通过id或者name属性定位元素。
HTMLCollection对象只包含元素的集合(Element),即具有标签名的元素;而NodeList对象是节点的集合,既包括元素,也包括节点,例如text文本节点。
常用的DOM操作
文档结构树中的节点类型众多,但是操作的主要节点类型为元素节点、属性节点和文本节点。
元素节点是拥有一对开闭合标签的元素整体,例如常见的div、ul、li标签都是元素节点。
- 属性节点是元素节点具有的属性,例如a标签的href属性、元素的样式class。
- 文本节点是DOM中用于呈现文本内容的节点,例如图5-1中h1标签内部的“我的标题”。
其中元素节点和文本节点存在父子关系,而元素节点与属性节点并不存在父子关系。
新增节点
新增节点其实包括两个步骤,首先是新建节点,然后将节点添加至指定的位置。
主要方法:**createElement**、**setAttribute**(createAttribute、setAttributeNode)、**createTextNode**、**appendChild**、**insertBefore**
// 获取指定元素
var container = document.querySelector('#container');
// 1. 新创建一个元素节点
var newLiOne = document.createElement('li');
// 2.新创建一个属性节点,并设置值
var newLiAttr = document.createAttribute('class');
newLiAttr.value = 'last';
// 3.将属性节点绑定在元素节点上
newLiOne.setAttributeNode(newLiAttr);
// 第2、3步简化:
newLiOne.setAttribute('class', 'last');
// 4.新创建一个文本节点
var newTextOne = document.createTextNode('新增文本1');
// 5.将文本节点作为元素节点的子元素
newLiOne.appendChild(newTextOne);
// 6.使用appendChild()函数将新增元素节点添加至末尾。
container.appendChild(newLiOne);
// 7.新创建第二个文本节点
var newTextTwo = document.createTextNode('新增文本2');
// 8.将文本节点作为元素节点的子元素
newLiTwo.appendChild(newTextTwo);
// 9.使用insertBefore()函数将节点添加至第一个新增节点的前面。
container.insertBefore(newLiTwo, newLiOne);
删除节点
删除节点的操作实际包含删除元素节点、删除属性节点和删除文本节点这3个操作
<ul id="main">
<li>文本1</li>
<li>文本2</li>
<li>文本3</li>
</ul>
<a id="link" href="http://www.mianshiting.com">面试厅</a>
<script>
// 1. 删除ul的第一个li元素节点
// 获取该元素的父元素
var main = document.querySelector("#main");
// 获取第一个元素节点,应该使用firstElementChild属性。
// firstChild属性实际是取childNodes属性返回的NodeList对象中的第一个值,在此例中为一个换行符
var firstChild = main.firstElementChild;
// 通过父节点,调用removeChild()函数删除该节点。
main.removeChild(firstChild);
// 2. 删除a标签的href属性
// 获取该元素
var link = document.querySelector("#link");
// 通过元素节点,调用removeAttribute()函数删除指定属性节点。
link.removeAttribute("href");
// 3. 删除ul最后一个li元素的文本节点(更推荐使用设置innerHTML属性为空的方法)
// 获取元素节点
var lastChild = main.lastElementChild;
// 获取文本节点
// 在获取文本节点时,需要使用的是childNodes属性,然后取返回的NodeList对象的第一个值。不能使用children属性,因为children属性返回的是HTMLCollection对象,表示的是元素节点,不包括文本节点内容。
var textNode = lastChild.childNodes[0];
// 通过元素节点,调用removeChild()函数删除指定的文本节点。
lastChild.removeChild(textNode);
// 关于删除文本节点还有一种比较简单的处理方法,那就是将元素节点的innerHTML属性设置为空。
lastChild.innerHTML = "";
</script>
修改节点
修改节点主要包括修改元素节点、修改属性节点和修改文本节点。
<div id="main">
<!-- 测试修改元素节点 -->
<div id="div1">替换之前的元素</div>
<!-- 测试修改属性节点 -->
<div id="div2" class="classA" style="color: green">这是修改属性的节点</div>
<!-- 测试修改文本节点 -->
<div id="last">这是最后一个节点内容</div>
</div>
<script>
// 1. 修改元素节点 修改元素节点的操作一般是直接将节点元素替换为另一个元素,可以使用replaceChild()函数来实现。
// 获取父元素与待替换的元素
var main = document.querySelector("#main");
var div1 = document.querySelector("#div1");
// 创建新元素
var newDiv = document.createElement("div");
var newText = document.createTextNode("这是新创建的文本");
newDiv.appendChild(newText);
// 使用新元素替换旧的元素
main.replaceChild(newDiv, div1);
// 2. 修改属性节点
// 修改属性节点有两种处理方式:一种是通过getAttribute()函数和setAttribute()函数获取和设置属性节点值;
// 另一种是直接修改属性名。直接修改的属性名与元素节点中的属性名不一定是一致的。就像class这个属性,因为它是JavaScript中的关键字,是不能直接使用的,所以需要使用className来代替。
var div2 = document.querySelector("#div2");
// 方法1: 通过setAttribute()函数设置
div2.setAttribute("class", "classB");
// 方法1: 通过setAttribute()函数设置
div2.setAttribute("style", "color: red;");
// 方法2: 直接修改属性名,注意不能直接用class,需要使用className
div2.className = "classC";
// 方法2: 直接修改属性名
div2.style.color = "blue";
// 3. 修改文本节点
// 修改文本节点与删除文本节点一样,将innerHTML属性修改为需要的文本内容即可。
var last = document.querySelector("#last");
// 直接修改innerHTML属性
last.innerHTML = "这是修改后的文本内容";
//如果设置的innerHTML属性值中包含HTML元素,则会被解析
last.innerHTML = '<p style="color: red">这是修改后的文本内容</p>';
//在浏览器中渲染后,可以看到“这是修改后的文本内容”为红色
</script>
事件流
一个完整的事件流实际包含了3个阶段:事件捕获阶段>事件目标阶段>事件冒泡阶段。
(1)事件捕获阶段
事件捕获阶段的主要表现是不具体的节点先接收事件,然后逐级向下传播,最具体的节点最后接收到事件
(2)事件目标阶段
事件目标阶段表示事件刚好传播到用户产生行为的元素上,可能是事件捕获的最后一个阶段,也可能是事件冒泡的第一个阶段。
(3)事件冒泡阶段
事件冒泡阶段的主要表现是最具体的元素先接收事件,然后逐级向上传播,不具体的节点最后接收事件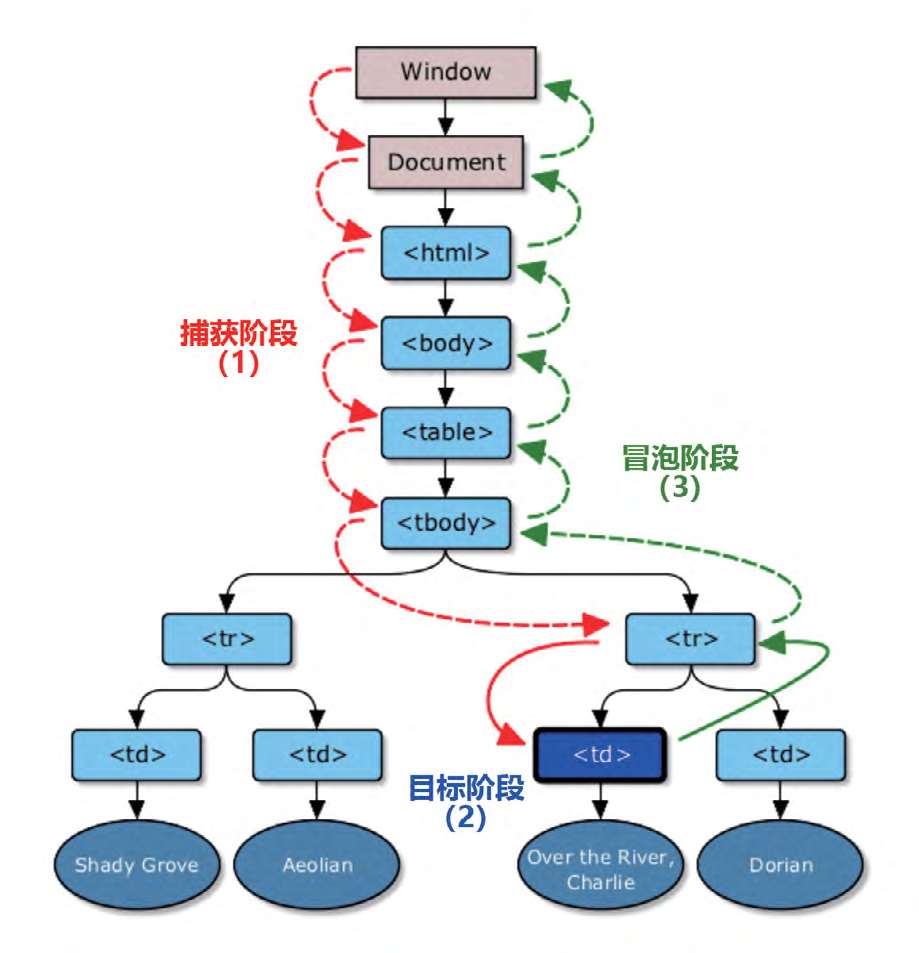
① 使用addEventListener()函数绑定的事件,默认情况下即第三个参数默认为false时,按照冒泡型事件流处理。设置为true,按照捕获型事件流处理。
②完整的事件流是按照事件捕获阶段>事件目标阶段>事件冒泡阶段依次进行的。如果有混合型事件流,则会优先于冒泡类型事件而先执行:
// 事件捕获
table.addEventListener('click', function () {
console.log('table触发');
}, true);
// 事件冒泡
tbody.addEventListener('click', function () {
console.log('tbody触发');
}, false);
// 事件捕获
tr.addEventListener('click', function () {
console.log('tr触发');
}, true);
// 事件冒泡
td.addEventListener('click', function () {
console.log('td触发');
}, false);
// table触发;
// tr触发;
// td触发;
// tbody触发;
// 事件冒泡
table.addEventListener('click', function () {
console.log('table触发');
}, false);
// 事件捕获
tbody.addEventListener('click', function () {
console.log('tbody触发');
}, true);
// 事件捕获
tr.addEventListener('click', function () {
console.log('tr触发');
}, true);
// 事件冒泡
td.addEventListener('click', function () {
console.log('td触发');
}, false);
// tbody触发;
// tr触发;
// td触发;
// table触发;
事件处理程序
根据W3C DOM标准,事件处理程序分为DOM0、DOM2、DOM3这3种级别的事件处理程序。由于在DOM1中并没有定义事件的相关内容,因此没有所谓的DOM1级事件处理程序。
DOM0级事件处理程序
DOM0级事件处理程序是将一个函数赋值给一个事件处理属性,有两种表现形式。
第一种是先通过JavaScript代码获取DOM元素,再将函数赋值给对应的事件属性。
var btn = document.getElementById("btn");
btn.onclick = function(){}
第二种是直接在html中设置对应事件属性的值,值有两种表现形式,一种是执行的函数体,另一种是函数名,然后在script标签中定义该函数。
<button onclick="alert('面试厅');">单击</button>
<button onclick="clickFn()">单击</button>
<script>
function clickFn() {
alert('面试厅');
}
</script>
如需删除元素绑定的事件,只需要将对应的事件处理程序设置为null即可。
btn.onclick = null;
需要注意的是,DOM0级事件处理程序只支持事件冒泡阶段。
优点:简单且可以跨浏览器。
缺点:一个事件处理程序只能绑定一个函数。两种DOM0级事件处理程序同时存在时,第一种在JavaScript中定义的事件处理程序会覆盖掉后面在html标签中定义的事件处理程序。
DOM2级事件处理程序
在DOM2级事件处理程序中,当事件发生在节点时,目标元素的事件处理函数就会被触发,而且目标元素的每个祖先节点也会按照事件流顺序触发对应的事件处理程序。DOM2级事件处理方式规定了添加事件处理程序和删除事件处理程序的方法。
DOM2级事件处理程序两种实现方式:主要分为IE浏览器和非IE浏览器。
在IE10及以下版本中,只支持事件冒泡阶段。在IE11中同时支持事件捕获阶段与事件冒泡阶段。在IE10及以下版本中,可以通过
**attachEvent()**函数添加事件处理程序,通过**detachEvent()**函数删除事件处理程序。element.attachEvent("on"+ eventName, handler); //添加事件处理程序 element.detachEvent("on"+ eventName, handler); //删除事件处理程序在IE11及其他非IE浏览器中,同时支持事件捕获和事件冒泡两个阶段,可以通过
**addEventListener()**函数添加事件处理程序,通过**removeEventListener()**函数删除事件处理程序。其中的useCapture参数表示是否使用事件捕获,true表示支持事件捕获,false表示支持事件冒泡,默认状态为false。addEventListener(eventName, handler, useCapture); //添加事件处理程序 removeEventListener(eventName, handler, useCapture); //删除事件处理程序两种实现方式的共同点:
① 在DOM2级事件处理程序中,不管是IE浏览器还是非IE浏览器都支持对同一个事件绑定多个处理函数。 ```javascript单击我触发事件
var wrap = document.getElementById(‘wrap’);
wrap.addEventListener(‘click’, function() { console.log(‘123’); }, false);
wrap.addEventListener(‘click’, function () { console.log(‘456’); }, false);
② 在需要删除绑定的事件时,不能删除匿名函数,因为添加和删除的必须是同一个函数。下面这种同时绑定和取消handler()函数的情况,可以删除掉绑定的事件。
```javascript
var wrap = document.getElementById('wrap');
var handler = function () {
console.log('789');
};
// 第一种方式绑定和取消的是同一个函数,因此可以取消绑定的事件
wrap.addEventListener('click', handler, false);
wrap.removeEventListener('click', handler);
// 使用匿名函数的形式,无法取消绑定的事件
wrap.addEventListener('click', function () {
console.log('123');
}, false);
wrap.removeEventListener('click', function () {});
不同点:
① 在IE浏览器中,使用attachEvent()函数为同一个事件添加多个事件处理函数时,会按照添加的相反顺序执行。
var btn=document.getElementById("mybtn");
btn.attachEvent("onclick",function(){
console.log("clicked");
});
btn.attachEvent("onclick",function(){
console.log("hello world!");
});
// 在单击button按钮时,会先输出“helloworld”,后输出“clicked”
② 在IE浏览器下,使用attachEvent()函数添加的事件处理程序会在全局作用域中运行,因此this指向全局作用域window。在非IE浏览器下,使用addEventListener()函数添加的事件处理程序在指定的元素内部执行,因此this指向绑定的元素。
<button id="mybtn">单击</button>
<script>
var btn = document.getElementById("mybtn");
// IE浏览器
btn.attachEvent("onclick", function () {
alert(this); // 指向window
});
// 非IE浏览器
btn.addEventListener("click", function () {
alert(this); // 指向绑定的元素
});
</script>
因为浏览器的差异性,针对不同的浏览器做兼容性处理:
var EventUtil = {
addEventHandler: function (element, type, handler) {
if (element.addEventListener) {
element.addEventListener(type, handler)
} else if (element.attachEvent) {
element.attachEvent("on" + type, handler)
} else {
element["on" + type] = handler
}
},
removeEventHandler: function (element, type, handler) {
if (element.addEventListener) {
element.removeEventListener(type, handler)
} else if (element.detachEvent) {
element.detachEvent("on" + type, handler)
} else {
element["on" + type] = null
}
}
}
DOM3级事件处理程序
DOM3级事件处理程序是在DOM2级事件的基础上重新定义了事件,也添加了一些新的事件。最重要的区别在于DOM3级事件处理程序允许自定义事件。
自定义事件由**createEvent("CustomEvent")**函数创建,返回的对象有一个**initCustomEvent()**函数,通过传递对应的参数可以自定义事件。**initCustomEvent()**接收以下4个参数:
- type:字符串、触发的事件类型、自定义,例如“keyDown”“selectedChange”。
- bubble(布尔值):表示事件是否可以冒泡。
- cancelable(布尔值):表示事件是否可以取消。
- detail(对象):任意值,保存在event对象的detail属性中。
创建完成的自定义事件,可以通过**dispatchEvent()**函数去手动触发。
场景:在页面初始化时创建一个自定义事件myEvent,页面上有个div监听这个自定义事件myEvent,同时有一个button按钮绑定了单击事件;当我们单击button时,触发自定义事件,由div监听到,然后做对应的处理。
<div id="watchDiv">监听自定义事件的div元素</div>
<button id="btn">单击触发自定义事件</button>
<script>
// 1.创建自定义事件
var customEvent;
(function () {
// 在创建自定义事件之前,需要判断浏览器是否支持DOM3级事件处理程序
if (document.implementation.hasFeature("CustomEvents", "3.0")) {
var detailData = { name: "kingx" };
customEvent = document.createEvent("CustomEvent");
customEvent.initCustomEvent("myEvent", true, false, detailData);
}
})();
// 2.监听自定义事件
var div = document.querySelector("#watchDiv"); // 获取元素
// 监听myEvent事件
div.addEventListener("myEvent", function (e) {
console.log("div监听到自定义事件的执行, 携带的参数为: ", e.detail);
});
// 3.触发自定义事件
var btn = document.querySelector("#btn"); // 获取元素
// 绑定click事件,触发自定义事件
btn.addEventListener("click", function () {
div.dispatchEvent(customEvent);
});
</script>
Event对象
事件在浏览器中是以Event对象的形式存在的,每触发一个事件,就会产生一个Event对象。
该对象包含所有与事件相关的信息,包括事件的元素、事件的类型及其他与特定事件相关的信息。
Event对象在不同浏览器中的实现是有差异性的。
获取Event对象
获取Event对象的方式有以下两种:
- 在事件处理程序中,Event对象会作为参数传入,参数名为event。
- 在事件处理程序中,通过window.event属性获取Event对象。 ```javascript var btn = document.querySelector(‘#btn’);
btn.addEventListener(‘click’, function (event) { // 方式1:event作为参数传入 console.log(event); // 方式2:通过window.event获取 var winEvent = window.event; console.log(winEvent); // 判断两种方式获取的event是否相同 console.log(event == winEvent); }); // Chrome浏览器和Safari浏览器同时支持两种方式获取event对象,而Firefox浏览器只支持这种将event作为参数传入的方式。 // 兼容方式: var EventUtil = { // 获取事件对象 getEvent: function (event) { return event || window.event; } };
<a name="Iu0vB"></a>
## 获取事件的目标元素
<a name="pHWYq"></a>
### srcElement与target
在IE浏览器中,event对象使用`**srcElement**`属性来表示事件的目标元素;而在非IE浏览器中,event对象使用`**target**`属性来表示事件的目标元素,为了提供与IE浏览器下event对象相同的特性,某些非IE浏览器也支持srcElement属性。
```javascript
btn.addEventListener('click', function (event) {
// 获取event对象
var event = EventUtil.getEvent(event);
// 使用两种属性获取事件的目标元素
var NoIETarget = event.target;
var IETarget = event.srcElement;
console.log(NoIETarget);
console.log(IETarget);
});
// Chrome浏览器和Safari浏览器同时支持两种属性来获取事件目标元素,而Firefox浏览器只支持event.target属性来获取事件目标元素。
// 兼容方式:
var EventUtil = {
...
// 获取事件目标元素
getTarget: function (event) {
return event.target || event.srcElement;
}
};
target属性与currentTarget属性
区别:
- target属性在事件目标阶段,理解为真实操作的目标元素。
- currentTarget属性在事件捕获、事件目标、事件冒泡这3个阶段,理解为当前事件流所处的某个阶段对应的目标元素。 ```javascript // 获取target属性和currentTarget属性的元素标签名 function getTargetAndCurrentTarget(event, stage) { var event = EventUtil.getEvent(event) var stageStr if (stage === ‘bubble’) { stageStr = ‘事件冒泡阶段’ } else if (stage === ‘capture’) { stageStr = ‘事件捕获阶段’ } else { stageStr = ‘事件目标阶段’ } console.log(stageStr, ‘target:’ + event.target.tagName.toLowerCase(), ‘currentTarget: ‘ + event.currentTarget.tagName.toLowerCase()) }
// 事件捕获 table.addEventListener(‘click’, function (event) { getTargetAndCurrentTarget(event, ‘capture’) }, true)
// 事件捕获 tbody.addEventListener(‘click’, function (event) { getTargetAndCurrentTarget(event, ‘capture’) }, true)
// 事件捕获 tr.addEventListener(‘click’, function (event) { getTargetAndCurrentTarget(event, ‘capture’) }, true)
// 事件捕获 td.addEventListener(‘click’, function (event) { getTargetAndCurrentTarget(event, ‘target’) }, true)
// 事件冒泡 table.addEventListener(‘click’, function (event) { getTargetAndCurrentTarget(event, ‘bubble’) }, false)
// 事件冒泡 tbody.addEventListener(‘click’, function (event) { getTargetAndCurrentTarget(event, ‘bubble’) }, false)
// 事件冒泡 tr.addEventListener(‘click’, function (event) { getTargetAndCurrentTarget(event, ‘bubble’) }, false)
// 事件冒泡 td.addEventListener(‘click’, function (event) { getTargetAndCurrentTarget(event, ‘target’) }, false)
// 事件捕获阶段 target: td currentTarget: table // 事件捕获阶段 target: td currentTarget: tbody // 事件捕获阶段 target: td currentTarget: tr // 事件目标阶段 target: td currentTarget: td // 事件目标阶段 target: td currentTarget: td // 事件冒泡阶段 target: td currentTarget: tr // 事件冒泡阶段 target: td currentTarget: tbody // 事件冒泡阶段 target: td currentTarget: table
<a name="ODQ50"></a>
### 阻止事件冒泡
**方法:event.stopPropagation()、stopImmediatePropagation()**
- stopPropagation()函数仅会阻止事件冒泡,其他事件处理程序仍然可以调用。
- stopImmediatePropagation()函数不仅会阻止冒泡,也会阻止其他事件处理程序的调用。
```javascript
var li = document.querySelector('li')
var btn = document.querySelector('#btn')
li.addEventListener('click', function (event) {
// 真实操作,使用console来代替
console.log('单击了li,做对应的处理')
})
// 第一个事件处理程序
btn.addEventListener('click', function (event) {
// 真实操作,使用console来代替
console.log('button的第一个事件处理程序,做对应的处理')
})
// 第二个事件处理程序
btn.addEventListener('click', function (event) {
var event = EventUtil.getEvent(event)
// 阻止事件冒泡
event.stopPropagation()
// 真实操作,使用console来代替
console.log('button的第二个事件处理程序,做对应的处理')
})
// 第三个事件处理程序
btn.addEventListener('click', function (event) {
// 真实操作,使用console来代替
console.log('button的第三个事件处理程序,做对应的处理')
})
// button的第一个事件处理程序,做对应的处理
// button的第二个事件处理程序,做对应的处理
// button的第三个事件处理程序,做对应的处理
// stopPropagation结论:事件冒泡被阻止,但绑定的3个事件处理程序都被触发执行。
// 将第二个事件处理程序中的stopPropagation()函数替换为stopImmediatePropagation()函数
btn.addEventListener('click', function (event) {
var event = EventUtil.getEvent(event);
// 阻止事件冒泡
event.stopImmediatePropagation();
// 真实操作,使用console来代替
console.log('btn的第二个事件处理程序,做对应的处理');
});
// button的第一个事件处理程序,做对应的处理
// button的第二个事件处理程序,做对应的处理
// stopImmediatePropagation结论:不仅会阻止冒泡,也会阻止其他事件处理程序的调用。
阻止默认行为
方法:event.preventDefault()
例如:
- a标签,在单击后默认行为会跳转至href属性指定的链接中。
- 复选框checkbox,在单击后默认行为是选中的效果。
- 输入框text,在获取焦点后,键盘输入的值会对应展示到text输入框中。
场景描述:限制用户输入的值只能是数字和大小写字母,其他的值则不能输入,如输入其他值则给出提示信息,提示信息在两秒后消失。
<input type="text" id="text" />
<div id="tip"></div>
<script>
var text = document.querySelector("#text");
var tip = document.querySelector("#tip");
text.addEventListener("keypress", function (event) {
// 浏览器的兼容性问题,Event对象提供了多种不同的属性来获取键的Unicode编码
var charCode = event.keyCode || event.which || event.charCode;
// 满足输入数字
var numberFlag = charCode <= 57 && charCode >= 48;
// 满足输入大写字母
var lowerFlag = charCode <= 90 && charCode >= 65;
// 满足输入小写字母
var supperFlag = charCode <= 122 && charCode >= 97;
if (!numberFlag && !lowerFlag && !supperFlag) {
// 阻止默认行为,不允许输入
event.preventDefault();
tip.innerText = "只允许输入数字和大小写字母";
}
// 设置定时器,清空提示语
setTimeout(function () {
tip.innerText = "";
}, 2000);
});
</script>
事件委托
原理:利用事件冒泡原理,管理某一类型的所有事件,利用父元素来代表子元素的某一类型事件的处理方式。
场景:假如页面上有一个ul标签,里面包含1000个li子标签,我们需要在单击每个li时,输出li中的文本内容。
<ul>
<li>文本1</li>
<li>文本2</li>
<li>文本3</li>
<li>文本4</li>
<li>文本5</li>
<li>文本6</li>
<li>文本7</li>
<li>文本8</li>
<li>文本9</li>
</ul>
<script>
// 1.获取所有的li标签
var children = document.querySelectorAll("li");
// 2.遍历添加click事件处理程序
for (var i = 0; i < children.length; i++) {
children[i].addEventListener("click", function () {
console.log(this.innerText);
});
}
</script>
弊端:上述的方法对浏览器的性能是一个很大的挑战,主要包含以下两方面原因:
- 事件处理程序过多导致页面交互时间过长。假如有1000个li元素,则需要绑定1000个事件处理程序,而事件处理程序需要不断地与DOM节点进行交互,因此引起浏览器重绘和重排的次数也会增多,从而会延长页面交互时间。
- 事件处理程序过多导致内存占用过多。在JavaScript中,一个事件处理程序其实就是一个函数对象,会占用一定的内存空间。假如页面有10000个li标签,则会有10000个函数对象,占用的内存空间会急剧上升,从而影响浏览器的性能。
解决:事件委托机制的主要思想是将事件绑定至父元素上,然后利用事件冒泡原理,当事件进入冒泡阶段时,通过绑定在父元素上的事件对象来判断当前事件流target元素。如果和期望的元素相同,则执行相应的事件代码。
// 1.获取父元素
var parent = document.querySelector('ul');
// 2.父元素绑定事件
parent.addEventListener('click', function (event) {
// 3.获取事件对象
var event = EventUtil.getEvent(event);
// 4.获取目标元素
var target = EventUtil.getTarget(event);
// 5.判断当前事件流所处的元素
if (target.nodeName.toLowerCase() === 'li') {
// 6.与目标元素相同,做对应的处理
console.log(target.innerText);
}
});
通过上面的代码可以看出,事件是绑定在父元素ul上的,不管子元素li有多少个,也不会影响到页面中事件处理程序的个数,因此可以极大地提高浏览器的性能。在上面的场景中,同一个ul下的所有li所做的操作都是一样的,使用事件委托即可处理。对不同的元素所做的处理也一样,只要获取其父元素并对其绑定事件处理程序。
优点:
- 提高性能:每一个函数都会占用内存空间,只需添加一个事件处理程序代理所有事件,所占用的内存空间更少。
- 动态监听:使用事件委托可以自动绑定动态添加的元素,即新增的节点不需要主动添加也可以一样具有和其他元素一样的事件。
事件委托对于元素事件的处理,尤其是处理多个元素时具有天然优势,同样也很好地解决了不同元素不同处理的情况。
contextmenu右键事件
```html <!DOCTYPE html>
-
first content
-
second content
-
third content
-
fourth content
-
fifth content
-
<a name="N8a24"></a>
# 文档加载完成事件
在DOM中,文档加载完成有两个事件,一个是load事件,在原生JavaScript和jQuery中均有实现;另一个是jQuery提供的ready事件。
- onload事件的触发表示页面中包含的图片、flash等所有元素都加载完成。
- ready事件的触发表示文档结构已经加载完成,不包含图片、flash等非文字媒体内容。
<a name="gwrRT"></a>
## load事件
load事件会在页面、脚本或者图片加载完成后触发。其中,支持onload事件的标签有`**body**`、`**frame**`、`**frameset**`、`**iframe**`、`**img**`、`**link**`、`**script**`。如果load事件用于页面初始化,则有两种实现方式。第一种方式是在body标签上使用onload属性,类似于onclick属性的设置,其实就是DOM0级事件处理程序。
```html
<!-- 使用onload属性 -->
<body onload="bodyLoad()">
<script>
function bodyLoad() {
console.log('文档加载完成,执行onload方法');
}
</script>
</body>
第二种方式是设置window对象的onload属性,属性值为一个函数。
<script>
window.onload = function () {
console.log('文档加载完成,执行onload方法');
};
</script>
需要注意的是,在load事件的两种实现方式中,第一种方式的优先级会高于第二种方式,如果同时采用两种方式,则只有第一种方式会生效。
jQuery实现:$(window).load(function(){...}),需要特别注意的是load()函数是jQuery绑定在window对象上的,而不是document对象上,$(document).load(function(){...}); // 不会生效。
jQuery的**load()**函数相比**window.onload()函数**与**body标签中使用onload属性**的两大优点:
- 可以同时绑定多个$(window).load()函数。而window.load()函数只能绑定一个事件处理程序。不过在body标签中使用onload属性可以达到这个目的
<body onload="fn1(),fn2(),fn3()"></body> - 使用$(window).load()函数可以将JavaScript代码与HTML代码进行分离,而设置body标签的onload属性不可以将JavaScript代码与HTML代码进行完全隔离。一旦代码冗余在一起,后续的代码维护将会变得越来越困难。
ready事件
概述:ready事件不同于load事件,ready事件只需要等待文档结构加载完成就可以执行。
使用场景:针对一个图片网站,使用ready事件,我们只需要等待HTML中的所有的img标签加载完成就可以执行初始化操作,而不需要等到img标签的src属性完全加载出来。这样将节省很长的等待时间,对性能来说是一大提升。
注意:ready事件并不是原生JavaScript所具有的,而是在jQuery中实现的,ready事件挂载在**document**对象上。
语法:**$(document).ready(function () {...});**因为ready()函数仅能用于当前文档,无须选择器,所以可以省略掉document而简写:**$().ready(function () {...});**又因为$默认的事件为ready事件,所以ready()函数也可以省略,从而更加精简**$(function () {...})**。加载完成事件的执行顺序
1. 将script标签写在head标签中: ```html <!DOCTYPE html>
**2. 将script标签写在body标签中:**
```html
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>ready与load事件执行顺序</title>
</head>
<body onload="bodyOnLoad()">
<script src="https://cdnjs.cloudflare.com/ajax/libs/jquery/1.9.0/jquery.min.js"></script>
<script>
// 方式1: $(document).ready()
$(document).ready(function () {
console.log('执行方式1: $(document).ready()');
});
// 方式2: $(function(){})
$(function () {
console.log('执行方式2: $(function(){})');
});
// 方式3: $(window).load()
$(window).load(function () {
console.log('执行方式3: $(window).load()');
});
// 方式4: window.onload
window.onload = function () {
console.log('执行方式4: window.onload');
};
// 方式5: body标签的onload属性
function bodyOnLoad() {
console.log('执行方式5: body标签的onload属性');
}
</script>
</body>
</html>
<!-- 执行方式1: $(document).ready()
执行方式2: $(function(){})
执行方式4: window.onload
执行方式3: $(window).load() -->
结论:
① 使用jQuery的ready事件总会比load事件先执行,jQuery提供的ready事件的两种形式其实是等效的,定义在前面的会先执行。
② load事件的执行顺序,是谁先定义则谁先执行。
③ 写在body标签中的onload属性优先级会高于window.onload属性。
浏览器的重排和重绘
浏览器渲染HTML的过程大致可以分为4步: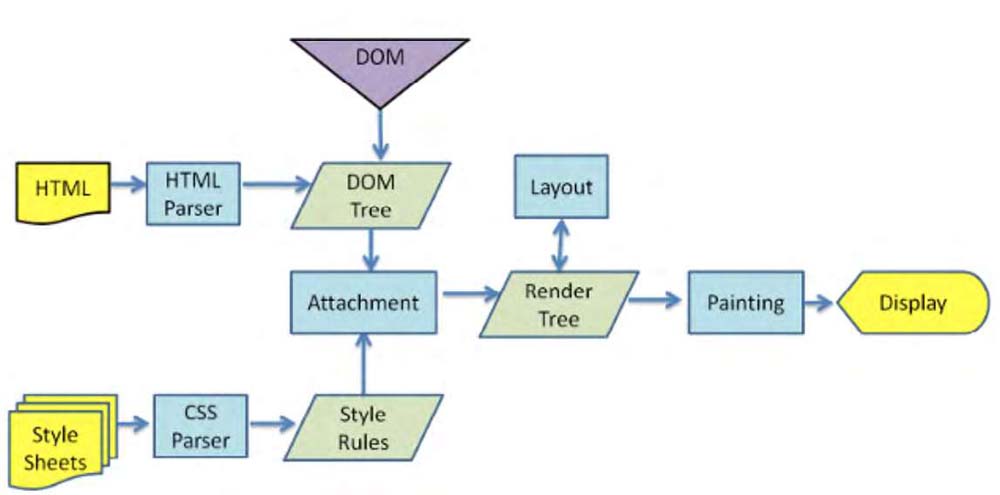
- HTML文件被HTML解析器解析成对应的DOM树,CSS样式文件被CSS解析器解析生成对应的样式规则集。
- DOM树与CSS样式集解析完成后,附加在一起形成一个渲染树。
- 节点信息的计算,即根据渲染树计算每个节点的几何信息。
- 渲染绘制,即根据计算完成的节点信息绘制整个页面。
重排
浏览器渲染页面默认采用的是流式布局模型。对某一个DOM节点信息进行修改时,就需要对该DOM结构进行重新计算,实际为从上到下、从左到右依次遍历元素,计算出各自渲染对象的几何信息,例如DOM元素的位置、尺寸、大小等,然后将其安置在界面中正确的位置。
该DOM结构的修改会决定周边DOM结构的更改范围,主要分为全局范围和局部范围:
- 全局范围就是从页面的根节点html标签开始,对整个渲染树进行重新计算。例如,当我们改变窗口的尺寸或者修改了根元素的字体大小时。
- 局部范围只会对渲染树的某部分进行重新计算。例如要改变页面中某个div的宽度,只需要重新计算渲染树中与该div相关的部分即可。
引起重排的操作:
- 页面首次渲染。在页面首次渲染时,HTML页面的各个元素位置、尺寸、大小等信息均是未知的,需要通过与CSS样式规则集才能确定各个元素的几何信息。这个过程中会产生很多元素几何信息计算的过程,所以会产生重排操作。
- 浏览器窗口大小发生改变。页面渲染完成后,就会得到一个固定的渲染树。如果此时对浏览器窗口进行缩放或者拉伸操作,渲染树中从根元素html标签开始的所有元素,都会重新计算其几何信息,从而产生重排操作。
- 元素尺寸或位置发生改变。
- 元素内容发生变化。
- 元素字体发生变化。
- 添加或删除可见的DOM元素。如果添加或者删除可见的DOM元素,则当前元素之前的元素不会受到影响;而当前元素之后的元素均会重新计算几何信息,渲染树也需要重新构建修改后的节点,从而产生重排操作。
- 获取某些特定的属性。浏览器不会针对每个JS操作都进行一次重排,而是维护一个会引起重排操作的队列,等队列中的操作达到了一定的数量或者到了一定的时间间隔时,浏览器才会去flush一次队列,进行真正的重排操作。虽然浏览器会有这个优化,但我们写的一些代码可能会强制浏览器提前flush队列,例如我们获取以下这些样式信息的时候:
· width:宽度 · height:高度 · margin:外边距 · padding:内边距 · display:元素显示方式 · border:边框 · position:元素定位方式 · overflow:元素溢出处理方式 · clientWidth:元素可视区宽度 · clientHeight:元素可视区高度 · clientLeft:元素边框宽度 · clientTop:元素边框高度 · offsetWidth:元素水平方向占据的宽度 · offsetHeight:元素水平方向占据的高度 · offsetLeft:元素左外边框至父元素左内边框的距离 · offsetTop:元素上外边框至父元素上内边框的距离 · scrollWidth:元素内容占据的宽度 · scrollHeight:元素内容占据的高度 · scrollLeft:元素横向滚动的距离 · scrollTop:元素纵向滚动的距离 · scrollIntoView():元素滚动至可视区的函数 · scrollTo():元素滚动至指定坐标的函数 · getComputedStyle():获取元素的CSS样式的函数 · getBoundingClientRect():获取元素相对于视窗的位置集合的函数 · scrollIntoViewIfNeeded():元素滚动至浏览器窗口可视区的函数。(非标准特性,谨慎使用) // 当我们请求以上这些属性时,浏览器为了返回最精准的信息,需要flush队列,因为队列中的某些操作可能会影响到某些值的获取。因此,即使你获取的样式信息与队列中的操作无关,浏览器仍然会强制flush队列,从而引起浏览器重排的操作。重绘
重绘只是改变元素在页面中的展现样式,而不会引起元素在文档流中位置的改变。例如更改了元素的字体颜色、背景色、透明度等,浏览器均会将这些新样式赋予元素并重新绘制。
重排一定会引起重绘的操作,而重绘却不一定会引起重排的操作。因为在元素重排的过程中,元素的位置等几何信息会重新计算,并会引起元素的重新渲染,这就会产生重绘的操作。而在重绘时,只是改变了元素的展现样式,而不会引起元素在文档流中位置的改变,所以并不会引起重排的操作。· color:颜色 · border-style:边框样式 · visibility:元素是否可见 · background:元素背景样式,包括背景色、背景图、背景图尺寸、背景图位置等 · text-decoration:文本装饰,包括文本加下画线、上划线、贯穿线等 · outline:元素的外轮廓的样式,在边框外的位置 · border-radius:边框圆角 · box-shadow:元素的阴影。 // 在修改以上常见的属性时,会引发重绘的操作性能优化
浏览器的重排与重绘是比较消耗性能的操作,所以我们应该尽量地减少重排与重绘的操作,这也是优化网页性能的一种方式。
1. 将多次改变样式的属性操作合并为一次 ```html
**2. 将需要多次重排的元素设置为绝对定位**<br />需要进行重排的元素都是处于正常的文档流中的,如果这个元素不处于文档流中,那么它的变化就不会影响到其他元素的变化,这样就不会引起重排的操作。常见的操作就是设置其position为absolute或者fixed。假如一个页面有动画元素,如果它会频繁地改变位置、宽高等信息,那么最好将其设置为绝对定位。<br />**3. 在内存中多次操作节点,全部完成后再添加至DOM树中,而不是一次次操作添加到DOM树**<br />比如在获取表格数据显示时,每次获取一行数据就添加到文档树,都会引发一次浏览器重排和重绘的操作,如果表格的数据很大,则会对渲染造成很大的影响。而在内存中一次性构造出完整的HTML代码段,再通过一次操作去渲染表格,这样只会引起一次浏览器重排和重绘的操作,从而带来很大的性能提升。<br />**4. 将要进行复杂处理的元素处理为display属性为none,处理完成后再进行显示**<br />因为display属性为none的元素不会出现在渲染树中,所以对其进行处理并不会引起其他元素的重排。当我们需要对一个元素做复杂处理时,可以将其display属性设置为none,操作完成后,再将其显示出来,这样就只会在隐藏和显示的时候引发两次重排操作。<br />**5. 将频繁获取会引起重排的属性缓存至变量**<br />在获取一些特定属性时,会引发重排或者重绘的操作。因此在获取这些属性时,我们应该通过一个变量去缓存,而不是每次都直接获取特定的属性。
```javascript
var ele = document.querySelector('#ele');
// 先获取width属性,缓存至变量
var width = ele.style.width;
// 判断条件1
if(true) {
width = '200px';
}
// 判断条件2
if(true) {
width = '300px';
}
// 判断条件3
if(true) {
width = '400px';
}
// 最后执行一次width属性赋值
ele.style.width = width;
// 这种写法只会在开始时获取一次width属性,判断条件执行结束后进行一次width属性的赋值,所以不管中间执行了多少次逻辑处理,始终只会有两次重排的操作。
6. 尽量减少使用table布局
如果table中任何一个元素触发了重排的操作,那么整个table都会触发重排的操作,尤其是当一个table内容比较庞大时,更加不推荐使用table布局。如果不得已使用了table,可以设置table-layout:auto或者是table-layout:fixed。这样可以让table一行一行地渲染,这种做法也是为了限制重排的影响范围。
7. 使用事件委托绑定事件处理程序
在对多个同级元素做事件绑定时,推荐使用事件委托机制进行处理。使用事件委托可以在很大程度上减少事件处理程序的数量,从而提高性能。
8. 利用**DocumentFragment**操作DOM节点
DocumentFragment是一个没有父级节点的最小文档对象,它可以用于存储已经排好版或者尚未确定格式的HTML片段。DocumentFragment最核心的知识点在于它不是真实DOM树的一部分,它的变化不会引起DOM树重新渲染的操作,也就不会引起浏览器重排和重绘的操作,从而带来性能上的提升。
- 将需要变更的DOM元素放置在一个新建的DocumentFragment中,因为DocumentFragment不存在于真实的DOM树中,所以这一步操作不会带来任何性能影响。
- 将DocumentFragment添加至真正的文档树中,这一步操作处理的不是DocumentFragment自身,而是DocumentFragment的全部子节点。对DocumentFragment的操作来说,只会产生一次浏览器重排和重绘的操作,相比于频繁操作真实DOM元素的方法,会有很大的性能提升。
<script> var ul = document.querySelector('#ul'); // 1.创建新的DocumentFragment对象 var fragment = document.createDocumentFragment(); for (var i = 0; i < 100; i++) { var li = document.createElement('li'); var text = document.createTextNode('节点' + i); li.append(text); // 2.将新增的元素添加至DocumentFragment对象中 fragment.append(li); } // 3.处理DocumentFragment对象 ul.append(fragment); </script> // 使用DocumentFragment()函数处理DOM元素时,只有在最终append的时候才会去真正处理真实的DOM元素,因此只会引发一次重排操作,从而提升了浏览器渲染的性能。

若有收获,就点个赞吧
0 人点赞
