1.原理
底层基于Lucene,面向文档的,并且是使用json作为文档的序列化格式的。
2.安装
这里采用docker安装的方式
搜索elasticSearch镜像
docker search elasticSearch
下载安装镜像
docker pull elasticsearch
启动
因为这个启动要占2G的内存,而我的 服务器没有2g内存,所以设置 -e ES_JAVA_OPTS=”-Xms256m -Xmx256m”
docker run -e ES_JAVA_OPTS="-Xms256m -Xmx256m" -d -p 9200:9200 -p 9300:9300 --name ES01 6f8bf0ce76ea
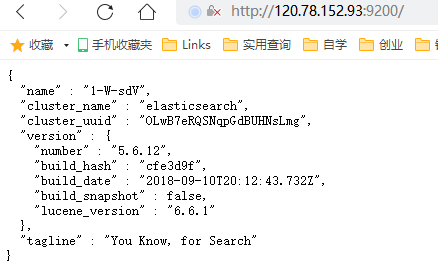
- 验证
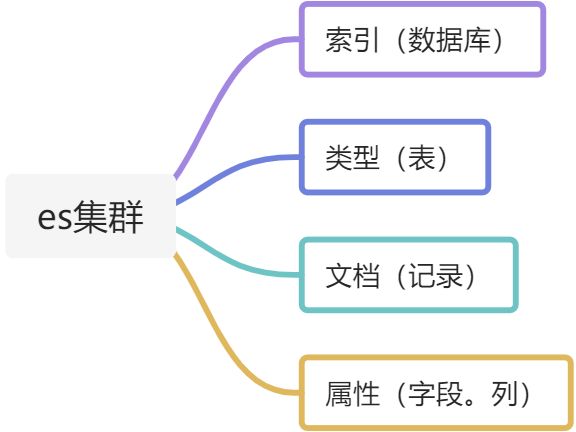
3.相关概念
4.快速入门
官方中文文档:https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
4.1增(插入数据 )
- 每个员工索引一个文档,文档包含该员工的所有信息。
- 每个文档都将是 employee 类型 。
- 该类型位于 索引 megacorp 内。
- 该索引保存在我们的 Elasticsearch 集群中。
以下插入了三个员工
PUT /megacorp/employee/1{"first_name" : "John","last_name" : "Smith","age" : 25,"about" : "I love to go rock climbing","interests": [ "sports", "music" ]}PUT /megacorp/employee/2{"first_name" : "Jane","last_name" : "Smith","age" : 32,"about" : "I like to collect rock albums","interests": [ "music" ]}PUT /megacorp/employee/3{"first_name" : "Douglas","last_name" : "Fir","age" : 35,"about": "I like to build cabinets","interests": [ "forestry" ]}
4.2删
4.3改
4.4查
4.4.1查某个id的详情
GET /megacorp/employee/1
返回结果包含了文档的一些元数据,以及 _source 属性,内容是 John Smith 雇员的原始 JSON 文档。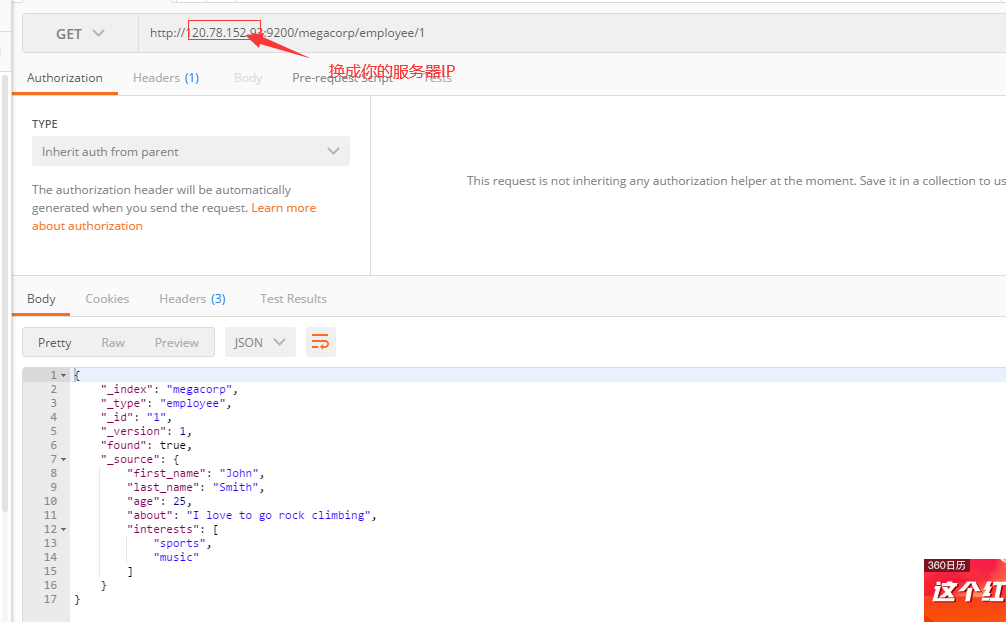
4.4.2查所有的
GET /megacorp/employee/_search
4.4.3条件查询
搜索姓氏为 Smith 的雇员
查询字符串的方式
GET /megacorp/employee/_search?q=last_name:Smith
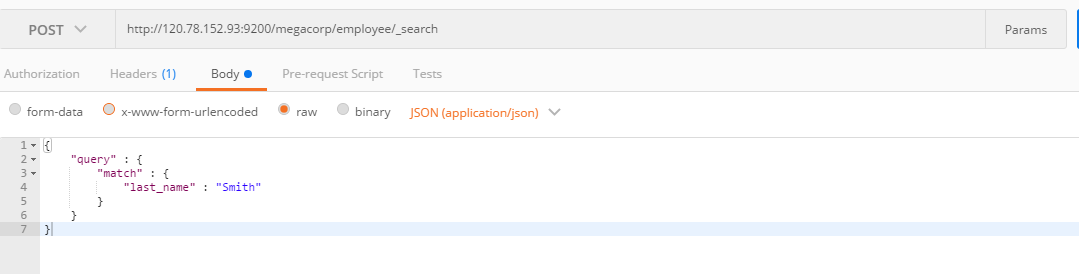
查询表达式的方式
GET /megacorp/employee/_search{"query" : {"match" : {"last_name" : "Smith"}}}
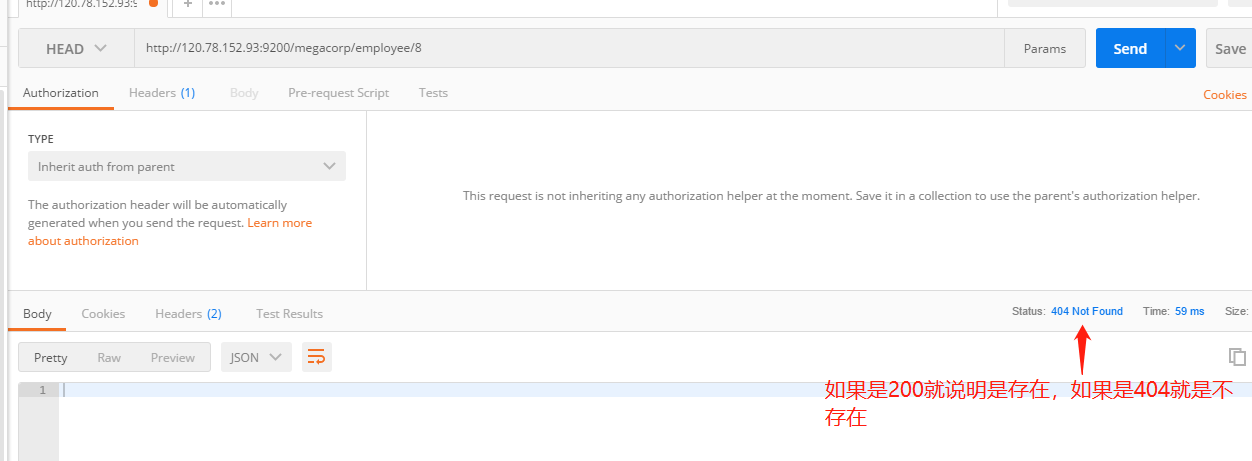
4.5检查是否存在
4.6复杂查询
同样搜索姓氏为 Smith 的员工,但这次我们只需要年龄大于 30 的。查询需要稍作调整,使用过滤器 filter ,它支持高效地执行一个结构化查询。
GET /megacorp/employee/_search{"query" : {"bool": {"must": {"match" : {"last_name" : "smith"}},"filter": {"range" : {"age" : { "gt" : 30 }}}}}}
4.7全文检索
搜索下所有喜欢攀岩(rock climbing)的员工:
GET /megacorp/employee/_search{"query" : {"match" : {"about" : "rock climbing"}}}
结果如下:
"hits": {"total": 2,"max_score": 0.53484553,"hits": [{"_index": "megacorp","_type": "employee","_id": "1","_score": 0.53484553,"_source": {"first_name": "John","last_name": "Smith","age": 25,"about": "I love to go rock climbing","interests": ["sports","music"]}},{"_index": "megacorp","_type": "employee","_id": "2","_score": 0.26742277,"_source": {"first_name": "Jane","last_name": "Smith","age": 32,"about": "I like to collect rock albums","interests": ["music"]}}]}
备注:_score就是相关性得分
Elasticsearch 默认按照相关性得分排序,即每个文档跟查询的匹配程度。第一个最高得分的结果很明显:John Smith 的 about 属性清楚地写着 “rock climbing” 。
但为什么 Jane Smith 也作为结果返回了呢?原因是她的 about 属性里提到了 “rock” 。因为只有 “rock” 而没有 “climbing” ,所以她的相关性得分低于 John 的。4.8短语搜索
找出一个属性中的独立单词是没有问题的,但有时候想要精确匹配一系列单词或者短语 。 比如, 我们想执行这样一个查询,仅匹配同时包含 “rock” 和 “climbing” ,并且 二者以短语 “rock climbing” 的形式紧挨着的雇员记录。
为此对 match 查询稍作调整,使用一个叫做 match_phrase 的查询:GET /megacorp/employee/_search{"query" : {"match_phrase" : {"about" : "rock climbing"}}}
4.9高亮搜索
许多应用都倾向于在每个搜索结果中 高亮 部分文本片段,以便让用户知道为何该文档符合查询条件。在 Elasticsearch 中检索出高亮片段也很容易。
再次执行前面的查询,并增加一个新的 highlight 参数:
GET /megacorp/employee/_search{"query" : {"match_phrase" : {"about" : "rock climbing"}},"highlight": {"fields" : {"about" : {}}}}
当执行该查询时,返回结果与之前一样,与此同时结果中还多了一个叫做 highlight 的部分。这个部分包含了 about 属性匹配的文本片段,并以 HTML 标签 封装:
"hits": {"total": 1,"max_score": 0.53484553,"hits": [{"_index": "megacorp","_type": "employee","_id": "1","_score": 0.53484553,"_source": {"first_name": "John","last_name": "Smith","age": 25,"about": "I love to go rock climbing","interests": ["sports","music"]},"highlight": {"about": ["I love to go <em>rock</em> <em>climbing</em>"]}}]}

若有收获,就点个赞吧
0 人点赞
