前段时间,团队有个同学在用 Serverless 实时处理日志时遇到了一个问题:每次处理结果都是相同的。后来问过我之后才发现是由于函数执行过程可能存在执行上下文重用,导致每次拉取到的都是同一份数据。归根究底是因为他对 Serverless 应用的运行原理理解得不够深入,而这也是很多刚开始学 Serverless 的同学经常遇到的共性问题,所以我准备了这节课,希望能让你有所收获。
这一讲,我会先介绍一下案例背景,然后再针对这个案例讲解 Serverless 的运行原理。这样一来,当你学完这一讲之后,就能知道案例的问题所在,并在今后的工作中学会避免这个问题。
案例回顾
当时我们的用户访问日志是存储在日志服务中的,每次有用户请求,都会记录一条日志。由于日志量巨大,直接从原始日志查询每分钟、每小时的用户 PV、UV 速度极慢。所以团队小伙伴打算以一分钟为时间窗口,查询一分钟内的用户 PV、UV 并存入 MySQL,这样很方便分析。
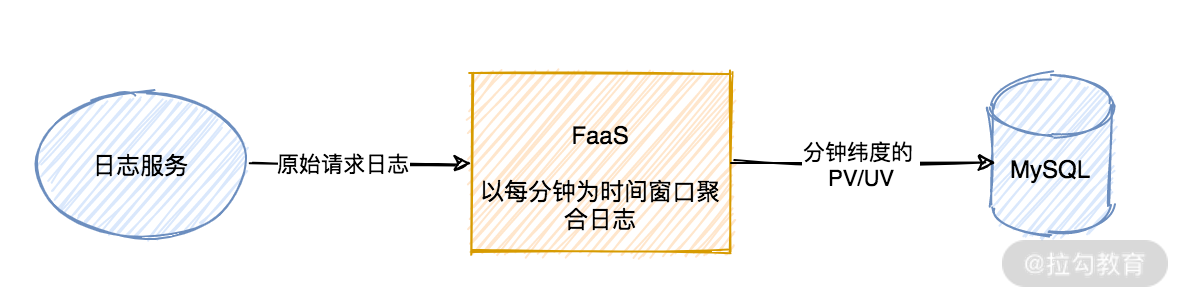
日志处理流程
当时的代码大致如下:
// 获取当前时间, 例如 2020-12-01 12:01:05constnewDate// 取前一分钟的整点时间作为开始时间,例如 2020-12-01 12:00:00const// 取当前分钟的整点时间作为开始时间,例如 2020-12-01 12:01:00const// 日志服务 Client 实例,可以用来查询日志constnew// 数据库实例constnew// 计算前一分钟内的 PVasyncfunction countPV() constSELECT COUNT(*) FROM log WHERE time >=${start_time} AND time < ${end_time}returnawait// 计算前一分钟的 UVasyncfunction countUV() constSELECT COUNT(DISTINCT user_id) FROM log WHERE time >=${start_time} AND time < ${end_time}returnawait// 将 UV 和 PV 信息存入数据库asyncfunction saveDataToDB() constawaitconstawaitconst’INSERT INTO user(uv, pv) values(?, ?)’await// 入口函数(event, callback) =>() =>null```
now = format( ());
start_time = getStartTime(now);
end_time = getEndTime(now);
client = Client();
db = DB();
{ sql = ; client.query(sql); }
{ sql = ; client.query(sql); }
{ pv = countPV(); uv = countUV(); sql = ; db.query(sql, [uv, pv]); }
exports.handler = { saveDataToDB() .then( callback()) .catch(callback(error)); }
看到这份代码的时候,我还是比较欣慰的,因为团队小伙伴已经掌握了 Serverless 应用开发的一些最佳实践,比如把业务逻辑拆分到入口函数之外。而且这段代码的逻辑也很清晰:首先获取当前时间,然后计算出一个时间区间(即 start_time 和 end_time)。然后再以这个时间区间为参数,查询一分钟内的 UV、PV,将其存入数据库。然后为函数设置一个定时触发器,每分钟执行一次,这样就能以每分钟为时间窗口对 UV 、PV 做聚合了。这段代码在本地运行是没有问题的,每次执行函数,都会获取一个新的时间,然后查询数据。但在 Serverless 中就存在两个比较严重的问题:-函数并发限制;-执行上下文重用。这是为什么呢?要弄清楚其中缘由,就需深入理解 Serverless 的运行原理。要知道,Serverless 应用本质上是由一个个 FaaS 函数组成的,Serverless 应用的每一次运行,其实是单个或多个函数的运行,**所以 Serverelss 的运行原理,本质上就是函数的运行原理。** 为了让你了解得更透彻,我将从函数的调用链路、调用方式、生命周期三个角度,讲解 Serverelss 的运行原理。<a name="ba16a33d"></a>### 函数调用链路:事件驱动函数执行在案例中,我们设置了一个定时触发器,所以函数每分钟都会执行一次。这是因为定时触发器会产生一个事件,FaaS 平台会接收各种事件,当事件来临时,就根据事件属性去执行函数。**这个过程就叫“事件驱动”。**这个词儿是不是很熟悉?比如浏览器是事件驱动的、Node.js 也是事件驱动的。其实 Serverless 的“事件驱动” 与其他技术中的“事件驱动”思想是一样的,本质上都是将用户的操作抽象为事件,由事件监听器监听事件,然后驱动程序执行。只是不同技术的事件模型的实现不同而已。对于 FaaS 函数来说,一方面可以通过事件来触发执行,另一方面也可以直接调用 API 来执行。FaaS 平台都提供了执行函数的 API。函数调用链路<a name="38eba8a0"></a>### 函数调用方式 :同步调用与异步调用从函数调用链路的图中,你可以看到函数支持同步调用和异步调用,这正是 FaaS 函数的两种调用方式。同步调用指的是客户端发起调用后,需要等到函数执行完毕并得到执行结果。FaaS 平台收到同步调用后,会立即为函数分配运行环境并执行函数。同步调用下面是使用函数计算 [Node.js SDK](https://github.com/aliyun/fc-nodejs-sdk) 来同步调用函数的一个示例:constnew'<account id>'accessKeyID'<access key id>'accessKeySecret'<access key secret>'region'cn-shanghai'headers'x-fc-invocation-type''Sync'await'event'
client = FCClient(, { : , : , : , : { : } }); client.invokeFunction(serviceName, funcName, );
其中 headers 中的 x-fc-invocation-type 用来表示同步或异步,Sync 是同步,Async 是异步 。event 是事件对象,使用 SDK 时,你可以自定义事件对象。同步执行结果如下,会直接在 data 中返回函数执行结果。headers'x-fc-request-id''ed2248a1-eaa4-487f-8402-67fa9355a3df''content-length''11'// ...data'hello world'
{ : { : : ,
}, : }
而异步调用是指客户端发起调用后,FaaS 会将事件放在内部队列中而不是立即执行。异步调用时,FaaS 会直接返回,不需要等待函数执行完毕。这意味着异步调用无法直接获取返回结果,所以它适用于运行时间比较长的场景。**对于函数计算来说,定时触发器就是异步调用的。** 此外,OSS 触发器、MNS 消息触发器也是异步的。当然,你也可以通过 API 实现异步调用。异步调用只需要把 x-fc-invocation-type 设置为 Async 就行了。异步调用的返回结果如下:
{ headers: { ‘x-fc-request-id’: ‘db7a27d8-189d-42c5-82b5-8e159f148d4c’, ‘content-length’: ‘0’ }, data: ‘’ } ```
可以看到,异步调用只返回了 requestId。
函数如果是同步调用,调用失败后,你可以立即知道调用结果,这时就可以针对失败进行重试。那异步调用怎么重试呢? 异步调用如果失败了,FaaS 平台一般会默认帮你进行有限次数的重试(比如函数计算会帮你重试三次,当然你也可以自己设置重试次数)。但大部分情况下,你不能只依靠 FaaS 提供的重试功能。对于异步调用,如果你关心调用结果的正确性,就可以为函数配置“异步调用目标”,将调用结果发送到消息队列或其他服务中,这样你就可以通过监听消息判断得到异步执行结果了。
不管函数是同步还是异步执行,都会有一个默认超时时间,FaaS 平台不会让函数永久执行下去。不然的话,如果你写了个死循环函数就会一直运行,导致持续产生费用,而对于 FaaS 平台来说,持续运行的函数也会一直占用资源无法释放。所以 FaaS 平台都会对函数设置一个执行超时时间,一般是 60s,你也可以自己设置。
讲到这儿,我们再来思考一下刚刚的案例。 在函数中需要去查询日志,如果一分钟内的日志量也非常大,导致查询时间很长,进而造成函数执行时间需要 3 分钟甚至更长,你要怎么办呢?你肯定想到为函数设置更长的超时时间,比如 10 分钟。那问题又来了,函数是每分钟执行一次,但函数本身执行需要 3 分钟,那运行中的函数岂不是会越来越多?
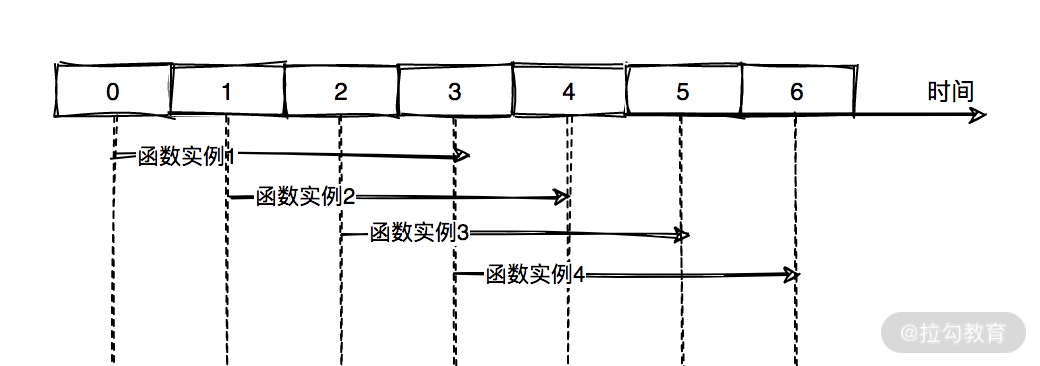
确实是这样,但 FaaS 平台不会让你的函数实例无限生成下去,一般会默认最多只会存在 100 个运行中的实例。超过限制后,事件队列就需要等待其他函数实例执行完毕后,再生成新的函数实例。
所以对于本节课中的案例,由于函数并发的限制,如果函数执行时间过长,则使用 new Date() 获取时间就会有问题。可能你以为函数将在 12:00:00 执行,结果函数实际是在 12:10:00 执行。要解决这个问题,就不能直接去获取当前函数执行时间,而应该使用 event.triggerTime ,这个时间是函数被触发的时间。另一方面,因为定时触发器是异步调用的,所以需要为函数设置调用目标,并对异常的调用结果进行处理。
不过由于这个问题需要函数并发超过限制时才会出现,所以团队小伙伴也没有第一时间发现。但这却给未来埋下了隐患,如果这个问题不解决,则很可能处理的数据就是不准确的。
现在你已经知道了函数并发限制是怎么造成的了,那函数上下文重用又是怎么回事呢?这就涉及函数的生命周期了。
函数生命周期:冷启动与热启动
在 FaaS 平台中,函数默认是不运行的,也不会分配任何资源。甚至 FaaS 中都不会保存函数代码。只有当 FaaS 接收到触发器的事件后,才会启动并运行函数。整个函数的运行过程可以分为四个阶段。
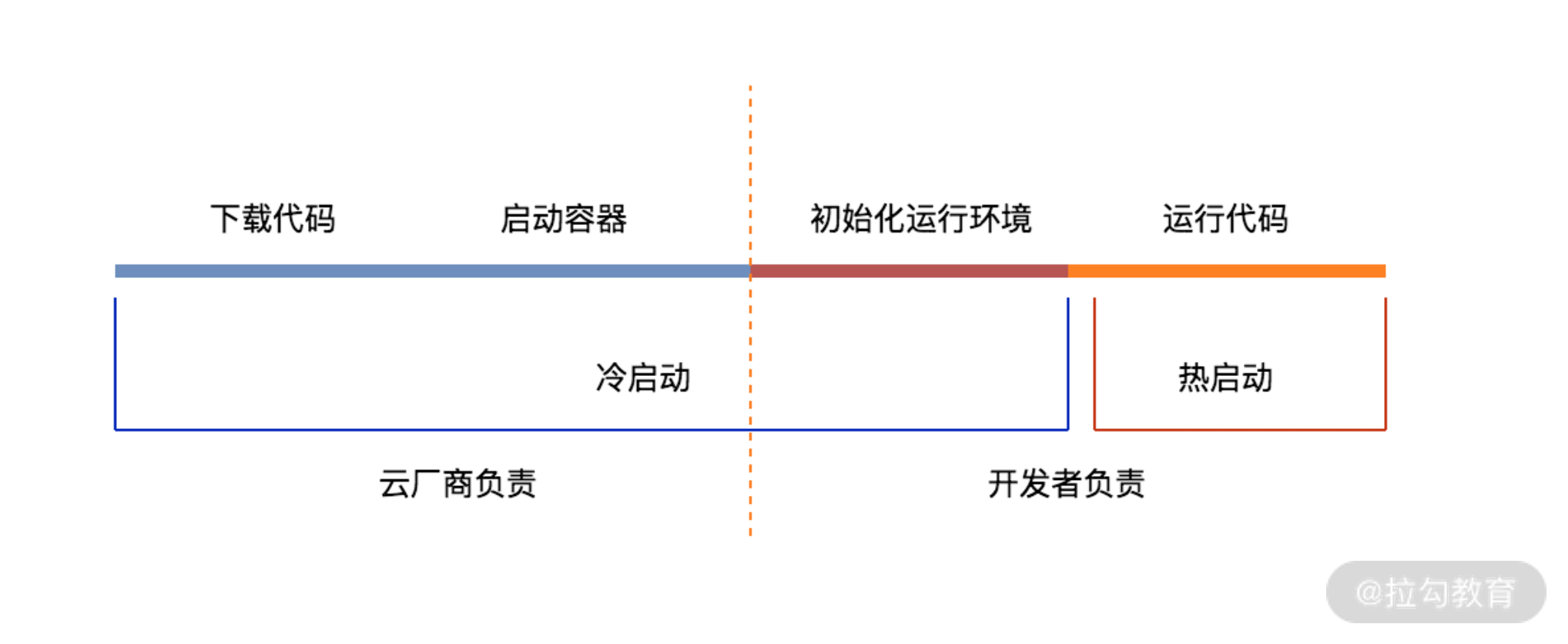
函数启动过程
下载代码: FaaS 平台本身不会存储代码,而是将代码放在对象存储中,需要执行函数的时候,再从对象存储中将函数代码下载下来并解压,因此 FaaS 平台一般都会对代码包的大小进行限制,通常代码包不能超过 50MB。
启动容器: 代码下载完成后,FaaS 会根据函数的配置,启动对应容器,FaaS 使用容器进行资源隔离。
初始化运行环境: 分析代码依赖、执行用户初始化逻辑、初始化入口函数之外的代码等。
运行代码: 调用入口函数执行代码。
当函数第一次执行时,会经过完整的四个步骤,前三个过程统称为“冷启动”,最后一步称为 “热启动”。
整个冷启动流程耗时可能达到百毫秒级别。函数运行完毕后,运行环境会保留一段时间,可能 2 ~ 5 分钟,这和具体云厂商有关。如果这段时间内函数需要再次执行,则 FaaS 平台就会使用上一次的运行环境,这就是“执行上下文重用”,函数的这个启动过程也叫“热启动”。“热启动” 的耗时就完全是启动函数的耗时了。当一段时间内没有请求时,函数运行环境就会被释放,直到下一次事件到来,再重新从冷启动开始初始化。
下面是一个函数的请求示意图,其中 “请求1” “请求3” 是冷启动,“请求2” 是热启动。
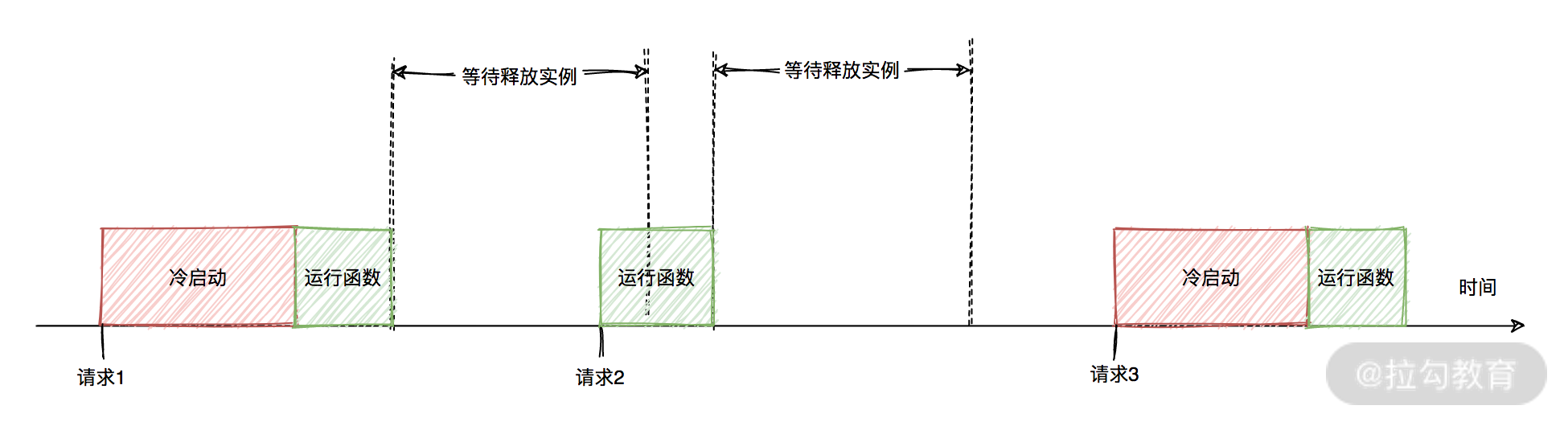
函数执行完毕后销毁运行环境,虽然对首次函数执行的性能有损耗,但极大提高了资源利用效率,只有需要执行代码的时候才初始化环境、消耗硬件资源。并且如果你的应用请求量比较大,则大部分时候函数的执行可能都是热启动。
从函数运行的生命周期中你可以发现,如果函数每分钟都执行,则函数几乎都是热启动的,也就是会重复使用之前的执行上下文。执行上下文就包括函数的容器环境、入口函数之外的代码。但在本节课实时处理日志的案例中,就会存在问题了。 由于执行上下文重用,所以代码中的入口函数 handler 之外的其他代码,const now = format(new Date()) 等,只会在函数第一次冷启动的时候执行,后面函数执行都会使用第一次执行时已经初始化完毕的值。这也就是为什么函数每次处理到的都是同一份数据了。
那如何解决这个问题呢?方法就是让处理时间的代码不被初始化就行了,实现就是将处理时间的代码放在 handler 入口函数中。
总结
这一讲,我通过一个案例为你介绍了 Serverless 应用的运行原理。
相比而言,传统应用部署在服务器上后是持续在线的,这样的好处是请求到来时,可以直接进行处理,无须启动应用;坏处则是需要一直消耗硬件资源,如果应用很长时间都没有请求,那大部分时间资源都是浪费的。
如果传统应用想要实现按需启动,则需要先启动一个虚拟机、再初始化应用运行环境、然后再启动应用,整个过程耗时达到分钟级,对业务而言显然不可接受。这也正是 Serverless 的优势: 基于函数开发应用,实现了应用的百毫秒启动,并且基于运行环境的重用,能够实现毫秒级的热启动,实现了资源利用率和业务性能的平衡。
关于本节课的内容,我想强调这几个点:
组成 Serverless 应用的函数是事件驱动的,但你也可以直接同 API 调用函数;
函数可以同步调用或异步调用,定时触发器函数是异步调用的,异步调用函数建议主动记录并处理异步调用结果;
函数的启动过程分为下载代码、启动容器、启动运行环境、执行代码四个步骤,前三个步骤称为冷启动,最后一个步骤称为热启动;
执行上下文重用可以提高 Serverless 应用性能,但在编写代码时要注意执行上下文重用带来的风险。
相信通过本节课的学习,你已经知道了本文实时处理日志这个案例存在的两个问题,一个是函数并发限制导致函数执行时间延迟,另一个是执行上下文重用导致每次处理的都是同一份数据。那么今天的作业,就是修改这份代码的 Bug,让它成为一个真正可线上运行的 Serverless 应用吧。

若有收获,就点个赞吧
0 人点赞
