GC 简介
GC 的全称是 garbage collection,它其实是一种自动内存管理机制,一般会由对应语言实现的垃圾回收器,在某些触发条件下对当前程序不再使用的对象内存进行回收处理。
在 Node.js 中则是由 V8 引擎负责 GC 操作,但是默认状态下相关的日志信息是关闭的,我们可以通过设置一系列 flag 来实时获取到不同级别的 V8 GC 日志信息:
—trace_gc: 一行日志简要描述每次 GC 时的时间、类型、堆大小变化和产生原因
—trace_gc_verbose: 结合 —trace_gc 一起开启的话会展示每次 GC 后每个 V8 堆空间的详细状况
—trace_gc_nvp: 每一次 GC 的一些详细键值对信息,包含 GC 类型,暂停时间,内存变化等信息
GC 日志目前是文本格式输出的形式,需要大家获取到以后进行对应的按行解析处理,也可以使用 v8-gc-log-parser 直接进行解析处理,对这一块有兴趣的同学可以看 @joyeeCheung 在 JS Interactive 的分享: Are Your V8 Garbage Collection Logs Speaking To You?。
今天的这个案例其实正是在 Node.js 性能平台 上借助于解析和展现 V8 的 GC 日志来进行不更改代码业务逻辑下的性能调优。
压测现象
事情源于我们的一位客户在项目上线进行压测时,CPU 100% 时单进程 QPS 在 100 上下浮动,想进行一些进一步的优化。首先想到的就是接入 Node.js 性能平台 并且在压测试做 CPU Profile 观察系统 CPU 耗费在什么地方:
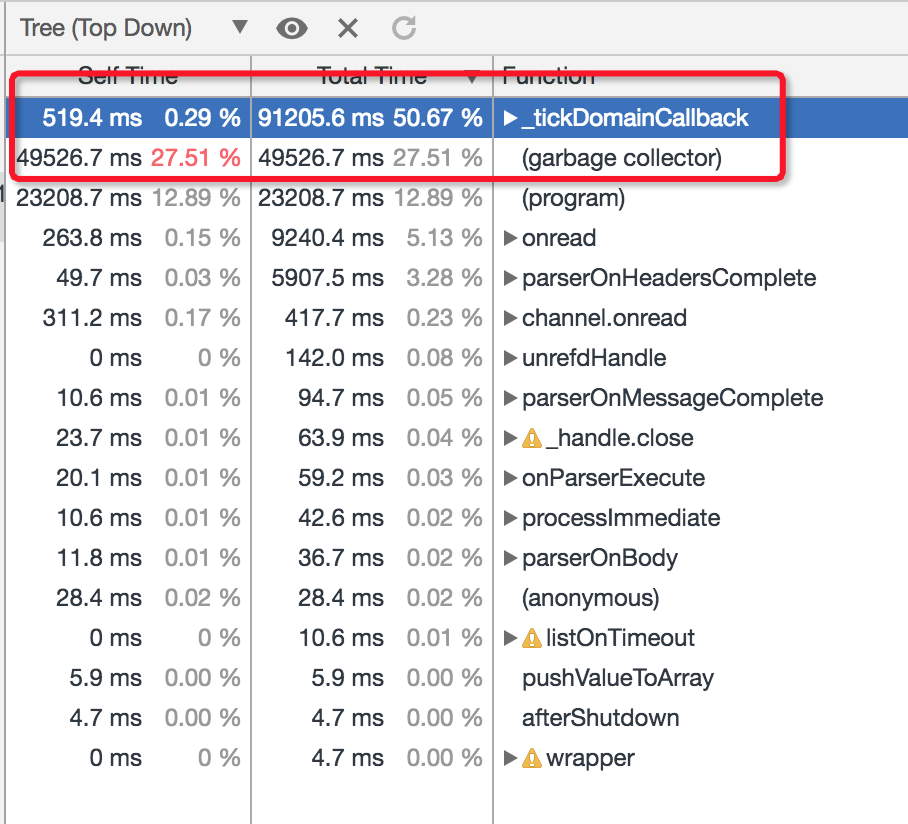
可以看到 _tickDomainCallback 和 garbage collector 在 CPU 的占比加起来高达 83%,而经过和用户沟通,发现 _tickDomainCallback 内部的耗费 CPU 高的逻辑分别是 typeorm 和自己的 controller 逻辑,typeorm 方面因为 api 变动的原因不太方便升级,controller 逻辑则是已经优化过了暂时没有提升的空间。
因此很自然的,我们会把进一步提升项目性能的目光放到 GC 阶段。这里在 3min 的 CPU 采样期间,GC 阶段的调用占比高达 27.5%,结合当时的性能平台监控数据,我们可以看到绝大部分都是 scavenge 阶段,此时继续进行线上压测,同时做 GC Trace 来获取更多 GC 阶段的详细信息:
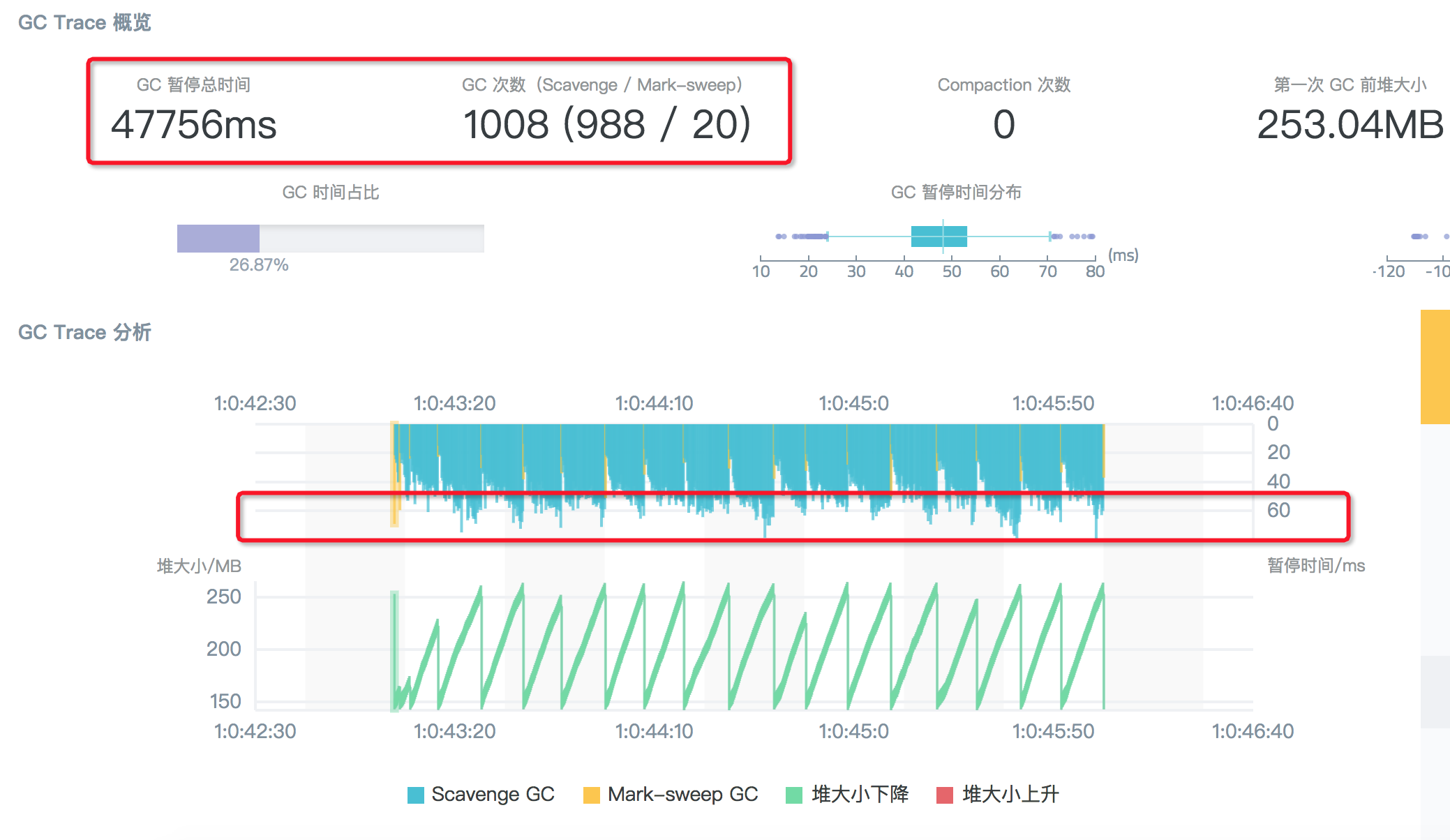
在 GC Trace 结果分析图中,可以看到红圈起来的几个重要信息:
GC 总暂停时间高达 47.8s,大头是 scavenge
3min 的 GC 追踪日志里面,总共进行了 988 次的 scavenge 回收
每次 scavenge 耗时均值在 50 ~ 60ms 之间
进一步分析
上面对 GC Trace 结果的分析中,可以看到此次 GC 优化的点集中在 scavenge 回收阶段,即新生代的内存回收。那么通过翻阅 V8 的 scavenge 回收逻辑可以知道,这个阶段触发回收的条件是:semi space allocation failed。
这样就可以推测,用户的应用在压测期间应该是在新生代频繁生成了大量的小对象,导致默认的 semi space 总是处于很快被填满从而触发 flip 的状态,这才会出现在 GC 追踪期间这么多的 scavenge 回收和对应的 CPU 耗费。面对这样的情况,我们是不是可以通过调整默认的 semi space 的值来进行优化呢?
尝试优化
V8 的代码查看后发现默认的 semi space 的值为 16M(alinode-v3.11.3/node-v8.11.3),经过和用户沟通,我们打算分别调整为 64M、128M 和 256M 来进行观察,可以通过在 Node 启动应用时加上 —max_semi_space_size 的 flag 来生效。
I. semi space 设置为 64M
将 semi space 调整为 64M 后,进行线上压测,并且在压测期间获取 CPU Profile 和 GC Trace,如下图所示:
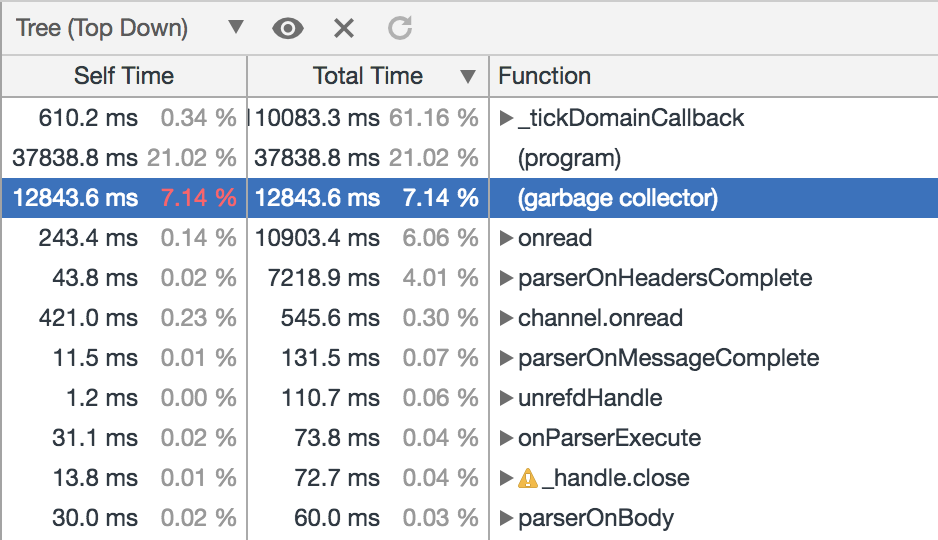
可以看到 garbage collector 阶段 CPU 耗费占比下降到 7% 左右,再观察下 GC 追踪结果:
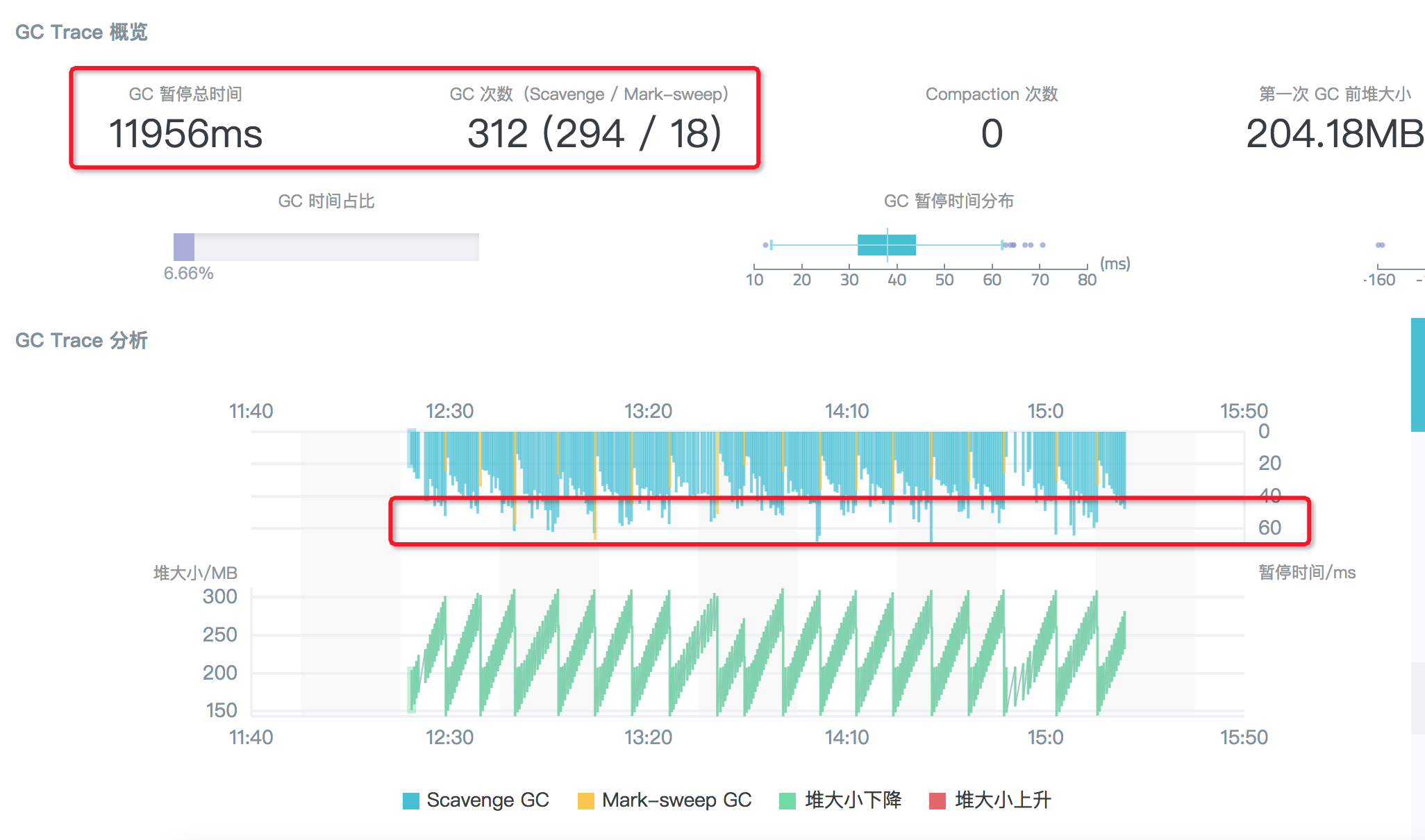
显然,semi space 调大为 64M 后,scavenge 次数从近 1000 次降低到 294 次,但是这种状况下每次的 scavenge 回收耗时没有明显增加,还是在 50 ~ 60ms 之间波动,因此 3min 的 GC 追踪总的停顿时间从 48s 下降到 12s,相对应的,业务的 QPS 提升了约 10% 左右。
II. semi space 设置为 128M
进一步调大 semi space 的值为 128M 时,观察 CPU Profile 结果:
此时 garbage collector 耗费下降相比上面的设置为 64M 并不是很明显,同样观察 GC 追踪结果:
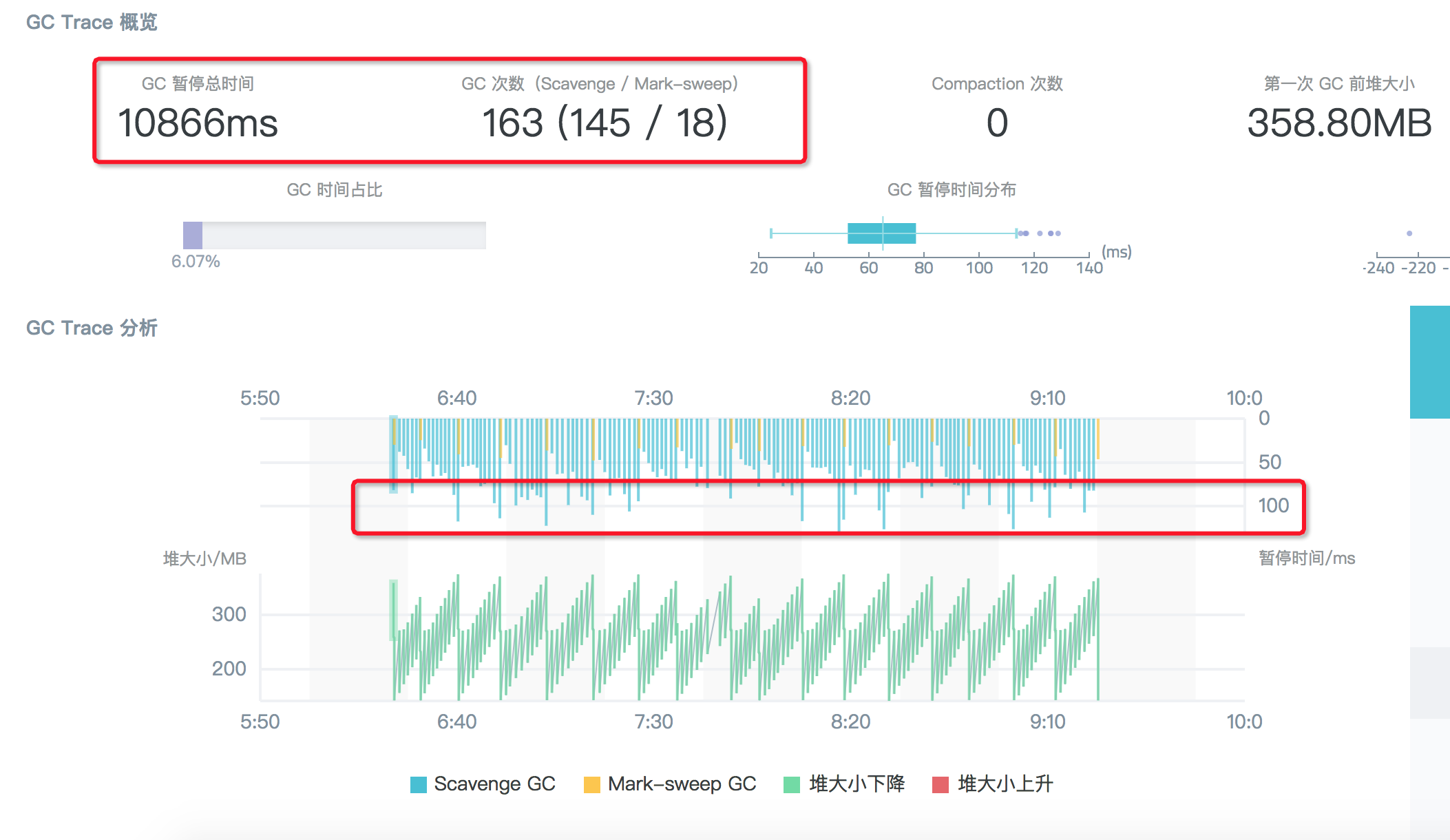
很明显,造成相比设置为 64M 时 GC 占比提升不大的原因是:虽然此时进一步调大了 semi space 至 128M,并且 scavenge 回收的次数从 294 次下降到 145 次,但是每次算法回收耗时近乎翻倍了,因此总收益并不明显。
III. semi space 设置为 256M
进一步将 semi space 调整为 256M 后测试,结果其实和 128M 时非常类似:相对 64M 的情况,此时 3min 内 scavenge 次数从 294 次下降到 72 次,但是相对的每次算法回收耗时波动到了 150ms 左右,因此整体性能并没有显著提升,入下图所示:
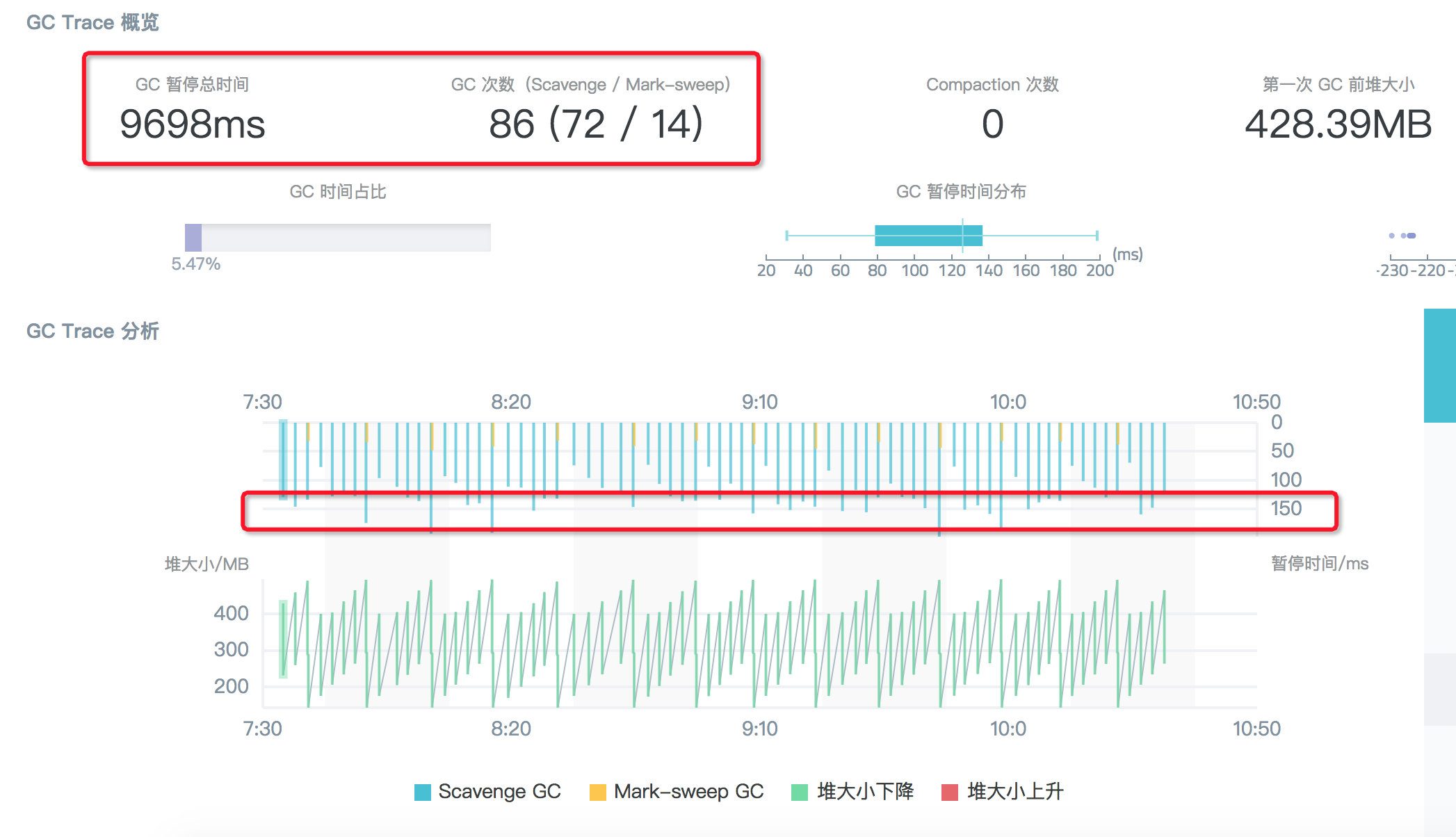
IV. 小结
通过以上的测试改进 semi space 的值后,可以看到从默认的 16M 设置到 64M 时,Node 应用的整体 GC 性能是有显著提升的,并且反映到压测 QPS 上大约提升了 10%;但是进一步将 semi space 增大到 128M 和 256M 时,收益确并不明显,而且 semi space 本身也是作用于新生代对象快速内存分配,本身不宜设置的过大,因此这次优化最终选取对此项目最优的运行时 semi space 的值为 64M。
写在最后
通过 GC 方面的运行时调优来提升我们的项目性能是一种大家不那么常用的方式,这也有很大一部分原因是应用运行时 GC 状态本身不直接暴露给开发者。通过上面这个客户案例,我们可以看到借助于 Node.js 性能平台,实时感知 Node 应用 GC 状态以及进行对应的优化,使得不改一行代码提升项目性能变成了一件非常容易的事情。

若有收获,就点个赞吧
0 人点赞
