1. 算法简介
我们平时常用的导航软件大家应该不陌生,只要输入开始地点及结束地点就会立即显示较优的行走路径。如果单纯地使用 BFS(Breath First Search) 广度优先算法暴力遍历的方式获取最短路径必然使得计算时间过长,使得用户期待的结果久久未能出现,体验未免太差了。
由此我们借助迪杰斯特拉(Dijkstra)算法又名为最短路径算法计算图中两个顶点(Vertex)的最短路径,这是基于一种有权有向图实现的算法。当然,实际的导航软件要比这里的算法复杂得多,且包含产品设计和业务要求,而且常用的是 A* 算法,不过我们今天主要讲解的是迪杰斯特拉(Dijkstra)算法。
2. 算法原理
2.1. 算法基础
- Heap (小顶堆)
- Map
- Graph
- BFS (Breath First Search)
2.2. 算法图解
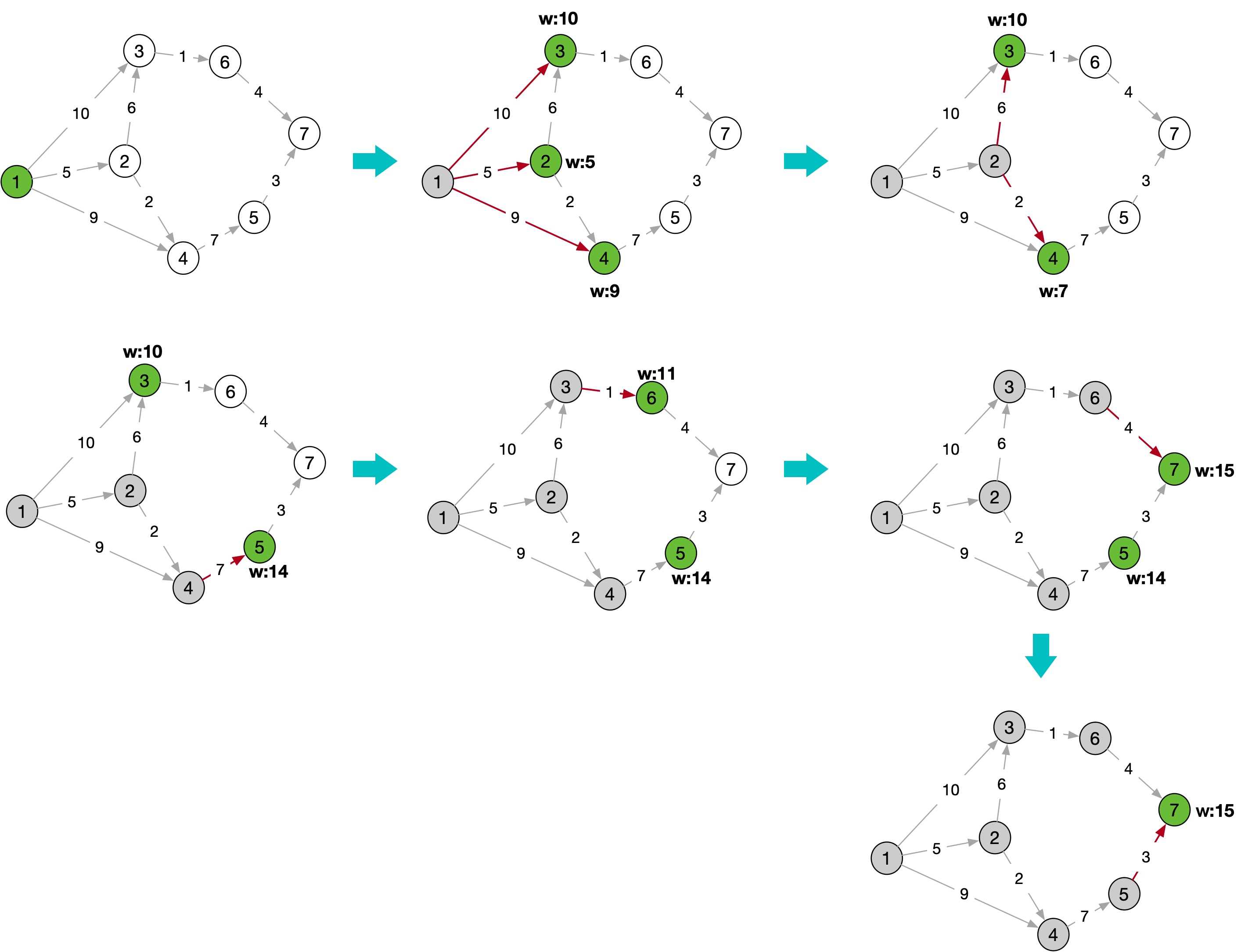
2.3. 图解说明
- 上图 1 中是从顶点 [1] 到顶点 [7] 的最短路径示意图
- 首先我们申请一个小顶堆并添加顶点 [1]
- 顶点 [1] 出度对应的顶点为 [3] [2] [4], 在小顶堆中的堆顶元素是按照权重选择。而顶点 [2] 的权重为 5 最小,因此成为堆顶元素
- 获取并删除堆顶元素对应顶点 [2] 并使得对应出度的两个顶点 [3] [4] 带着与之前不同的权重(顶点 [3][w:11] / 顶点 [2][w:7])并重新进入堆中,而因为只有权重小的才能成为堆顶元素,所以重复进入小顶堆的顶点元素仅权重小的将会优先成为堆顶元素
- 为了避免重复顶点进入小顶堆中造成额外的开销,所以引入
visited变量记录已经访问过的顶点。对于重复进入小顶堆的顶点,权重小的会被优先访问,而权重大的则可以通过visited变量进行去重校验 - 重复
#3和#4的过程,当堆顶元素对应顶点为 [7] 出堆时的权重则为最短路径
3. 复杂度分析
原理分析后,我们再来看一下迪杰斯特拉(Dijkstra)算法效率的高低,这就取决于它的复杂度,所以我们来分析一下其时间复杂度及空间复杂度。
我们利用 V 表示顶点 Vertex 个数的缩写,E 表示边 Edge 个数的缩写。
3.1. 时间复杂度
通过图解,我们发现每经过一条边 E 就会将一个顶点 V 新增到小顶堆中,所以将边对应顶点入堆的操作时间复杂度为 O(logE),总的边数为 E,则时间复杂度表示为 O(E*logE) 。但你可能会发现,为了避免相同的顶点 V 存在重复进堆的情况,我们引入了 visited 变量判重。所以准确来说,入堆的元素是与顶点个数 V 相关,所以堆操作的时间复杂度为 O(logV),最终的时间复杂度为 O(E*logV)。
3.2. 空间复杂度
空间复杂度分析需要一些技巧,我们知道每一个顶点进入小顶堆记作 O(1),共 V 个顶点则表示为 O(V)。但在图解说明中,我们发现存在重复进入小顶堆的顶点,而进入小顶堆的对象个数则与边数相关,表示为 O(E),但起始位置的顶点 [1] 是不存在入度的边,那么我们可以通过 +1 表示为 O(E+1),由于复杂度计算可以忽略常量,所以最终的空间复杂度为 O(E)。
4. 代码实现
LeetCode 743. Network Delay Time
we send a signal from a certain node K. How long will it take for all nodes to receive the signal? If it is impossible, return -1.
具体翻译为:从节点 K 开始到达所有节点的最小网络延迟时间(注意这里是所有节点,并非单个节点)
class Solution {public int networkDelayTime(int[][] times, int N, int K) {// 以邻接表的数据结构保存图数据Map<Integer, List<int[]>> adjacencyList = new HashMap<>();for (int i = 0; i < times.length; i++) {List<int[]> outdegrees = adjacencyList.get(times[i][0]);if (outdegrees == null) {outdegrees = new LinkedList<>();adjacencyList.put(times[i][0], outdegrees);}outdegrees.add(new int[]{times[i][1], times[i][2]});}// 小顶堆,每次可从小顶堆中获取权重最小的节点PriorityQueue<int[]> queue = new PriorityQueue<>(N, new Comparator<int[]>() {public int compare(int[] o1, int[] o2) {return o1[1] - o2[1];}});queue.add(new int[]{K, 0});// 用以保存已访问节点Set<Integer> visited = new HashSet<>(N);int[] last = null;while (!queue.isEmpty()) {int[] current = queue.poll(); // 获取堆顶元素(权重最小)if (!visited.add(current[0])) continue; // 避免重复处理last = current;List<int[]> outdegrees = adjacencyList.get(current[0]);if (outdegrees == null) continue;for (int[] v : outdegrees) {if (!visited.contains(v[0])) { // 避免重复入堆queue.add(new int[]{v[0], v[1] + current[1]});}}}return visited.size() == N && last != null ? last[1] : -1;}}

若有收获,就点个赞吧
0 人点赞
