1.浅看大数据
1.1大数据的定义
最早提出“大数据”这一概念的是全球知名咨询公司麦肯锡,他是这样定义大数据的:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型以及价值密度四大特征。
研究机构Gartner是这样定义大数据的:“大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流转优化能力来适应海量、高增长率和多样化的信息资产。
若从技术角度来看,大数据的战略意义不在于掌握庞大的数据,而在于对这些含有意义的数据进行专业化处理,换言之,如果把大数据比作一种产业,那么这种产业盈利的关键在于提高对数据的“加工能力”,通过“加工”实现数据的“增值”。
随着云时代的来临,大数据(Big data)也吸引了越来越多的关注。分析师团队认为,大数据(Big data)通常用来形容一个公司创造的大量非结构化数据和半结构化数据,这些数据在下载到关系型数据库用于分析时会花费过多时间和金钱。大数据分析常和云计算联系到一起,因为实时的大型数据集分析需要像MapReduce一样的框架来向数十、数百或甚至数千的电脑分配工作。 大数据需要特殊的技术,以有效地处理大量的容忍经过时间内的数据。适用于大数据的技术,包括大规模并行处理(MPP)数据库、数据挖掘、分布式文件系统、分布式数据库、云计算平台、互联网和可扩展的存储系统。1.2 大数据的特征
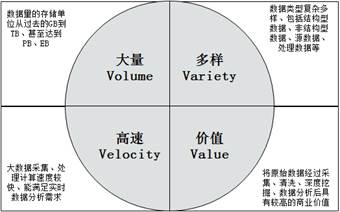
Volume(数据量大)
大数据的特征首先就是数据规模大。随着互联网、物联网、移动互联技术的发展,人和事物的所有轨迹都可以被记录下来,数据呈现出爆发性增长。数据相关计量单位的换算关系
最小的基本单位是bit,按顺序给出所有单位:bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB。 它们按照进率1024(2的十次方)来计算: 1 Byte =8 bit 1 KB = 1,024 Bytes = 8192 bit 1 MB = 1,024 KB = 1,048,576 Bytes 1 GB = 1,024 MB = 1,048,576 KB 1 TB = 1,024 GB = 1,048,576 MB 1 PB = 1,024 TB = 1,048,576 GB 1 EB = 1,024 PB = 1,048,576 TB 1 ZB = 1,024 EB = 1,048,576 PB 1 YB = 1,024 ZB = 1,048,576 EB 1 BB = 1,024 YB = 1,048,576 ZB 1 NB = 1,024 BB = 1,048,576 YB 1 DB = 1,024 NB = 1,048,576 BBVariety(类型繁多)
数据来源的广泛性,决定了数据形式的多样性。大数据可以分为三类,一是结构化数据,如财务系统数据、信息管理系统数据、医疗系统数据等,其特点是数据间因果关系强;二是非结构化的数据,如视频、图片、音频等,其特点是数据间没有因果关系;三是半结构化数据,如HTML文档、邮件、网页等,其特点是数据问的因果关系弱。有统计显示,目前结构化数据占据整个互联网数据量的75%以上,而产生价值的大数据,往往是这些非结构化数据。
Velocity(速度快、时效高)
数据的增长速度和处理速度是大数据高速性的重要体现。与以往的报纸、书信等传统数据载体生产传播方式不同,在大数据时代,大数据的交换和传播主要是通过互联网和云计算等方式实现的,其生产和传播数据的速度是非常迅速的。另外,大数据还要求处理数据的响应速度要快,例如,上亿条数据的分析必须在几秒内完成。数据的输入、处理与丢弃必须立刻见效,几乎无延迟。
Value(价值密度低)
大数据的核心特征是价值,其实价值密度的高低和数据总量的大小是成反比的,即数据价值密度越高数据总量越小,数据价值密度越低数据总量越大。任何有价值的信息的提取依托的就是海量的基础数据,当然目前大数据背景下有个未解决的问题,如何通过强大的机器算法更迅速的在海量数据中完成数据的价值提纯。
Veracity(真实性)
数据的质量较高
1.3大数据的应用
大数据技术已逐渐成熟并广泛应用于各个领域,随着5G时代的到来,以数据为基础的企业运营已成为企业优化产业结构、提高服务质量的基础,在数据时代,数据量迅速膨胀,数据维度不断提高,数据分析的指导作用更加明显。
2.Hadoop的简介
Hadoop是一个由Apache基金会开发的开源的、可靠的、可扩展的、用于分布式计算的分布式系统基础架构。
2.1Hadoop的由来与发展
2.1.1由来
Hadoop起源于Apache Nutch项目,始于2002年,是Apache Lucene的子项目之一 [2] 。2004年,Google在“操作系统设计与实现”(Operating System Design and Implementation,OSDI)会议上公开发表了题为MapReduce:Simplified Data Processing on Large Clusters(Mapreduce:简化大规模集群上的数据处理)的论文之后,受到启发的Doug Cutting等人开始尝试实现MapReduce计算框架,并将它与NDFS(Nutch Distributed File System)结合,用以支持Nutch引擎的主要算法 [2] 。由于NDFS和MapReduce在Nutch引擎中有着良好的应用,所以它们于2006年2月被分离出来,成为一套完整而独立的软件,并被命名为Hadoop。到了2008年年初,hadoop已成为Apache的顶级项目,包含众多子项目,被应用到包括Yahoo在内的很多互联网公司 [2] 。 Hadoop的项目创始人道格·卡廷。
2.1.2发展
https://blog.csdn.net/u012926411/article/details/82756100#t3
2.2Hadoop生态圈
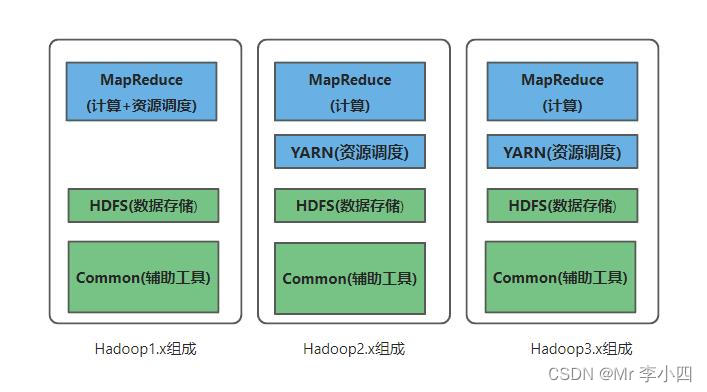
通常说到的hadoop包括两部分,一是Hadoop核心技术(或者说狭义上的hadoop),对应为apache开源社区的一个项目,主要包括三部分内容:hdfs,mapreduce,yarn。其中hdfs用来存储海量数据,mapreduce用来对海量数据进行计算,yarn是一个通用的资源调度框架(是在hadoop2.0中产生的)。
另一部分指广义的,广义上指一个生态圈,泛指大数据技术相关的开源组件或产品,如hbase、hive、spark、pig、zookeeper、kafka、flume、phoenix、sqoop等。
生态圈中的这些组件或产品相互之间会有依赖,但又各自独立。比如habse和kafka会依赖zookeeper,hive会依赖mapreduce。
Hadoop技术生态圈的一个大致组件分布图
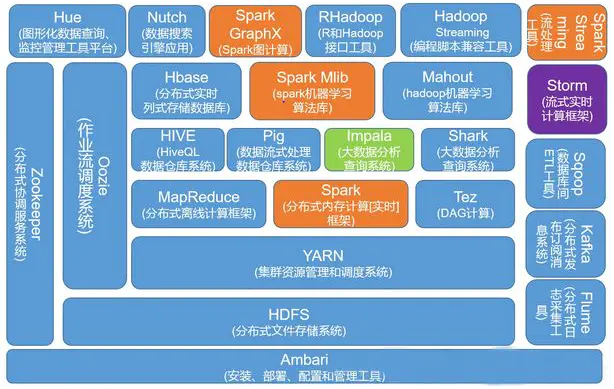
狭义上说Hadoop就是一个软件。
2.3历史版本发行版本
2.3.0历史版本
0.x系列版本:hadoop当中最早的一个开源版本,在此基础上演变而来的1.x以及2.x的版本1.x版本系列:hadoop版本当中的第二代开源版本,主要修复0.x版本的一些bug等
2.x版本系列:架构产生重大变化,引入了yarn平台等许多新特性
Hadoop有三大发行版本:Apache、Cloudera、Hortonworks。
2.3.1Apache
Apache版本最原始(最基础)的版本,对于入门学习最好。2006
2.3.2Cloudera
Cloudera内部集成了很多大数据框架,对应产品CDH。2008
2.3.3Hortonworks
Hortonworks文档较好,对应产品HDP。2011
Hortonworks现在已经被Cloudera公司收购,推出新的品牌CDP。
2.4Hadoop的优缺
2.4.1优
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。
- 高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖 。
- 高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
- 高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
- 高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
- 低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
2.4.2缺
- Hadoop不适用于低延迟数据访问。
- Hadoop不能高效存储大量小文件。
- Hadoop不支持用户写入并任意修改文件。
2.5Hadoop的三大核心
2.5.1HDFS架构概述
适合运行在通用硬件(commodity hardware)上的分布式文件系统(Distributed File System)
- NameNode(nn):存储文件的元数据,如文件名、文件目录结构,文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等。
- DataNode(dn):在本地文件系统存储文件块数据,以及块数据的校验和。
- Secondary NameNode(2nn):每隔一段时间对NameNode元数据备份。

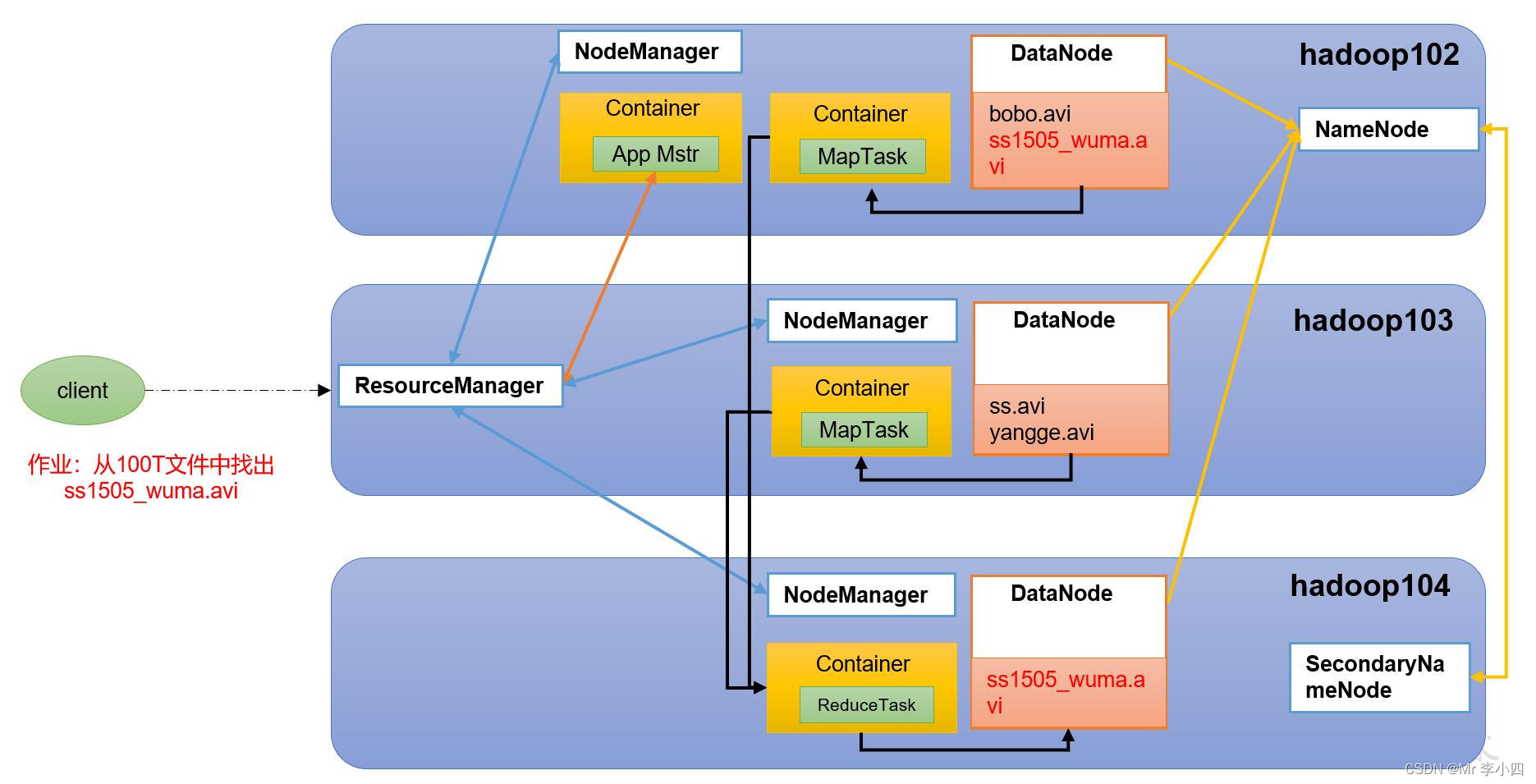
2.5.2MapReduce架构概述
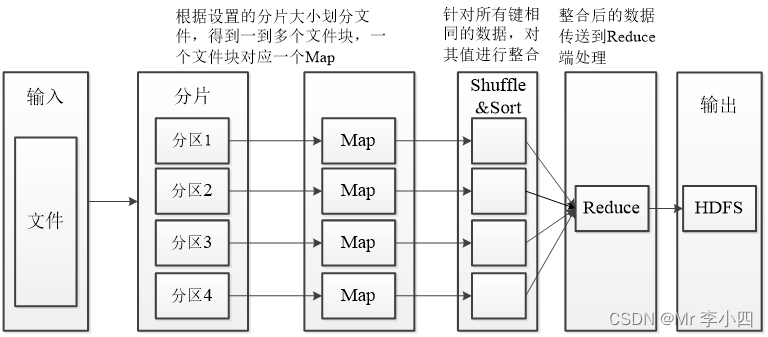
一个完整的MapReduce过程包含数据的输入与分片、Map阶段数据处理、Shuffle&Sort阶段数据整合、Reduce阶段数据处理、数据输出等阶段。- 读取输入数据:从HDFS分布式文件系统中读取的,根据所设置的分片大小对文件重新分片(Split)。
- Map阶段:数据将以键值对的形式被读入,键的值一般为每行首字符与文件最初始位置的偏移量,即中间所隔字符个数,值为该行的数据记录。根据具体的需求对键值对进行处理,映射成新的键值对,将新的键值对传输至Reduce端。
- Shuffle&Sort阶段:将同一个Map中输出的键相同的数据先进行整合,减少传输的数据量,并且在整合后将数据按照键进行排序。
- Reduce阶段:针对所有键相同的数据,对数据进行规约,形成新的键值对。
- 输出阶段:将数据文件输出至HDFS,输出的文件个数和Reduce的个数一致,如果只有一个Reduce,那么输出的只有一个数据文件,默认命名为“part-r-00000”。
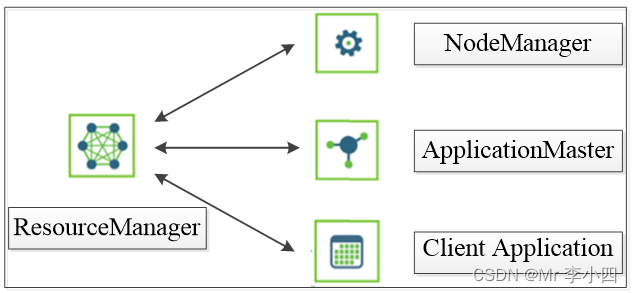
2.5.3YARN架构概述
YARN是Hadoop的资源管理器,使得Hadoop数据处理能力超越MapReduce- ResourceManager(RM):一个全局的资源管理器,负责整个系统的资源管理和分配,ResourceManager主要由两个组件构成,即调度器(Scheduler)和应用程序管理器(Applications Manager,ASM)。
- NodeManager(NM):每个节点上的资源和任务管理器。
- ApplicationMaster(AM):与ResourceManager调度器协商以获取资源(用Container表示)。
- Client Application:Client Application是客户端应用程序,客户端将应用程序提交到RM时,首先将创建一个Application上下文件对象,再设置AM必需的资源请求信息,最后提交至RM。
- HDFS、YARN、MapReduce三者关系
2.5.4Hadoop其他组件
Sqoop、Flume、Kafka、Spark、Flink、Oozie、ZooKeeper
Hbase:HBase是一个针对非结构化数据的可伸缩、高可靠、高性能、分布式和面向列的动态模式数据库。提供了对大规模数据的随机、实时读写访问。保存的数据可以使用MapReduce进行处理。将数据存储和并行计算很好地结合在一起。
Hive:Hive是建立在Hadoop上的数据仓库基础构架。提供了一系列的工具,可存储、查询和分析存储在Hadoop中的大规模数据。 定义了一种类SQL语言为HQL(Hive Query Language),HQL语句在Hive的底层将被转换为复杂的MapReduce程序,运行在Hadoop大数据平台上。

若有收获,就点个赞吧
0 人点赞
