1:对象基本概念:成员与初始化
Java 是一种面向对象的语言程序设计语言 (Object Oriented Programming : OOP)。
类与对象
类是具备某些共同特征的实体的集合,它是一种抽象的数据类型,也是对所具有相同特征实体的抽象。
在面向对象的程序设计语言中,类是对一类 “事物” 的属性与行为的抽象。
对象则是类的实例,创建对象最简单的方式就是使用 new 关键字。
示例:
比如,Person 是一个类,那么具体的某个人 “张三” 就是 Person 这个类的对象。而 “姓名,身高,体重” 这些信息就是对象的属性,人的行为比如 “吃饭,睡觉” 等就是对象的方法。
Person 类
public class Person {private String name;private int height;private int weight;public Person() {}public Person(String name,int height,int weight) {this.name = name;this.height = height;this.weight = weight}public void eat(){System.out.println("eating...");}public void sleep(){System.out.println("sleeping...");}}
创建 Person 类的对象 “zhangsan”
// 调用了 Person 的全参构造器Person zhangsan = new Person("张三",175,130);// 调用方法zhangsan.eat();zhangsan.sleep();
Java 中 new 一个对象发生了什么
当 JVM 遇到一条 new 指令时,首先会去检查该指令的参数是否能在常量池中定位到一个类的符号引用(Symbolic Reference),并检查这个符号引用代表的类是否已经被加载,解析,初始化过,即验证是否是第一次使用该类。如果该类是第一次被使用,那么就会执行类的加载过程。
注:符号引用是指,一个类中引入了其他的类,可是 JVM 并不知道引入其他类在什么位置,所以就用唯一的符号来代替,等到类加载器去解析时,就会使用符号引用找到引用类的具体地址,这个地址就是直接引用
第一步:类加载
类从被加载到 JVM 到卸载出内存,整个生命周期如图所示:
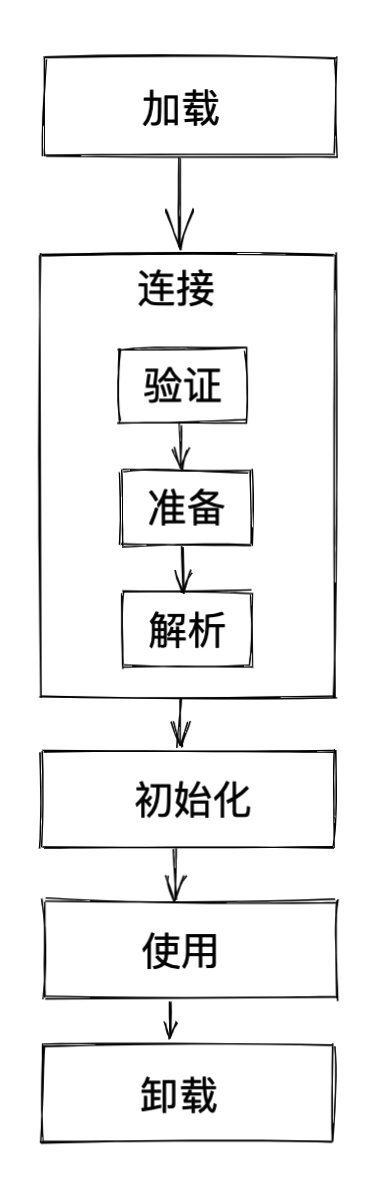
加载 -> 连接(验证 -> 准备 -> 解析) -> 初始化 ->使用 -> 卸载
各个阶段的主要功能为:
- 加载:查找并加载类文件的二进制数据
- 连接:将已经读入内存的类的二进制数据合并到 JVM 运行时环境中去,包含如下几个步骤:
- 验证:确保被加载类的正确性
- 准备:为类的静态变量分配内存,赋默认值;例如:
public static int a = 1;在准备阶段对静态变量 a 赋默认值 0 - 解析:把常量池中的符号引用转换成直接引用
- 初始化:为类的静态变量赋初始值,这个时候才对静态变量 a 赋初始值 1
我们可以看到,类的静态成员在类加载过程中就已经被加载到内存中了!
那么类是如何被加载的呢?答案是:类加载器
类加载器
Java 虚拟机自带的加载器包括如下几种:( JDK9 开始)
- 启动类加载器(BootstrapClassLoader)
- 平台类加载器(PlatformClassLoader)
- 应用程序类加载器(AppClassLoader)
JDK8 虚拟机自带的加载器:
- BootstrapClassLoader
- ExtensionClassLoader
- AppClassLoader
除了虚拟机自带的类加载器外,用户也可以自定义类加载器。
类加载器之间的层级关系:
- UserClassLoader (用户自定义类加载器)的父级为 AppClassLoader
- AppClassLoader 的父级为 PlatformClassLoader
- PlatformClassLoader 的父级为 BootstrapClassLoader
关系图如下所示:
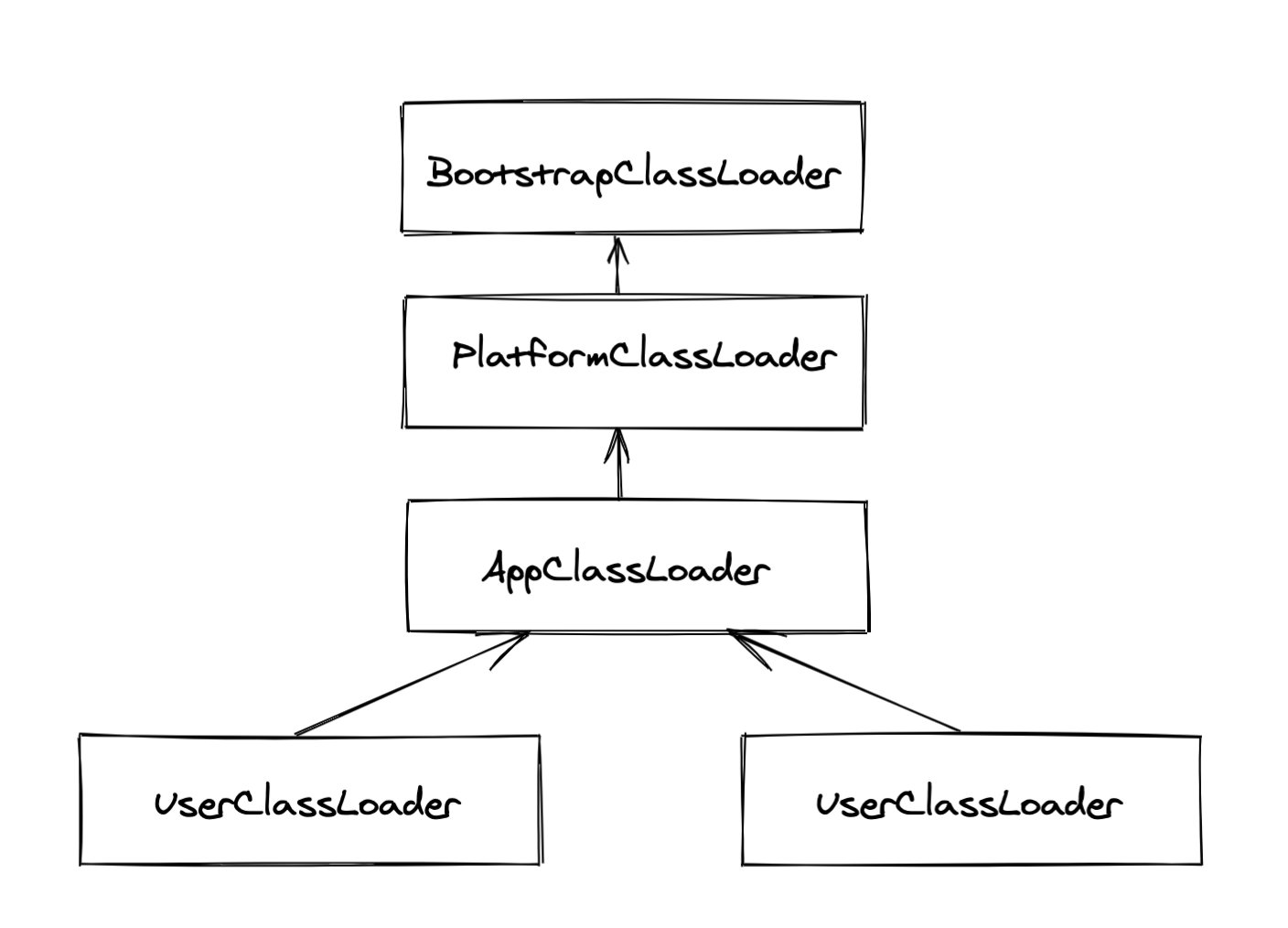
双亲委派模型
JVM 中的 ClassLoader 采用双亲委派模型的方式加载一个类:
那么什么是双亲委派模型呢?
双亲委托模型就是:如果一个类加载器(ClassLoader)收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委托给父类加载器去完成,每一个层次的类加载器都是如此,因此所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父类加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需要加载的类)时,子加载器才会尝试自己去加载。
使用双亲委托机制的好处是:能够有效确保一个类的全局唯一性,当程序中出现多个限定名相同的类时,类加载器在执行加载时,始终只会加载其中的某一个类。
在类加载完成后,JVM 就可以完全确定 new 出来的对象的内存大小了,接下来,JVM 会执行为该对象分配内存的工作。
第二步: 为对象分配内存空间
为对象分配空间的任务等同于把一块确定大小的内存从 JVM 堆中划分出来,目前常用的有两种方式(根据使用的垃圾收集器的不同而使用不同的分配机制):
- Bump the Pointer(指针碰撞)
- Free List(空闲列表)
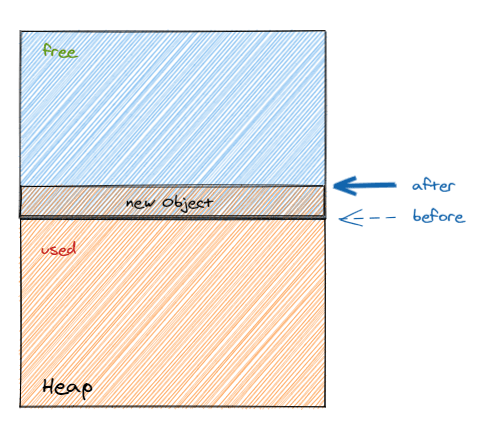
指针碰撞
所谓的指针碰撞是指:假设 JVM 堆内存是绝对规整的,所有用过的内存都放在一边,空闲的内存放在另一半,中间有一个指针指向分界点,那新的对象分配的内存就是把那个指针向空闲空间挪动一段与对象大小相等的距离。
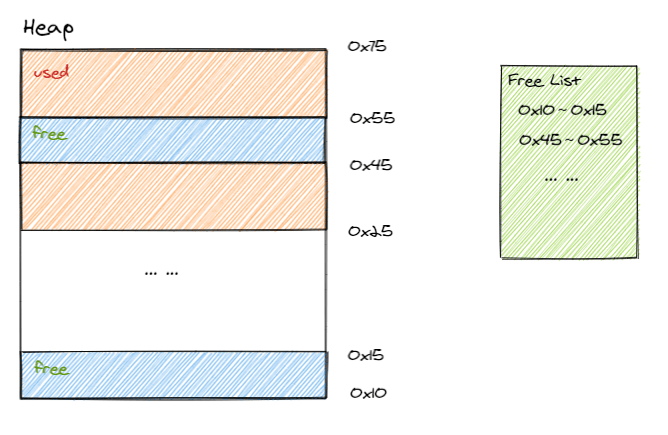
空闲列表
如果 JVM 堆内存并不是规整的,即:已用内存空间与空闲内存相互交错,JVM 会维护一个空闲列表,记录那些内存块是可用的,在为该对象分配空间时,JVM 会从空闲列表中找到一块足够大的空间划分给对象使用。
第三步:完善对象内存布局的信息
在我们为对象分配好内存空间后,JVM 会设置对象的内存布局的一些信息。
对象在内存中存储的布局(以 HotSpot虚拟机为例)分为:对象头,实例数据以及对齐填充。
- 对象头
对象头包含两个部分:- Mark Word:存储对象自身的运行数据,如:Hash Code,GC 分代年龄,锁状态标志等等
- 类型指针:对象指向它的类的元数据的指针
- 实例数据
- 实例数据是真正存放对象实例的地方
对齐填充
- 这部分不一定存在,也没有什么特别含义,仅仅是占位符。因为HotSpot要求对象起始地址都是8字节的整数倍,如果不是就对齐
JVM 会为所有实例数据赋零值(默认值),即:将方法区内对实例变量的定义拷贝一份到堆区,然后赋默认值,例如整型的默认值为 0,引用类型的默认值为 null 等等。
并且,JVM 会为对象头进行必要的设置,例如这个对象是哪个类的实例,如何才能找到类的元数据信息,对象的 Hash Code,对象的 GC 分带年龄等等,这些信息都存放在对象的对象头中。
第四步:调用对象的实例化方法 <init>
在 JVM 完善好对象内存布局的信息后,会调用对象的 <init> 方法,根据传入的属性值为对象的变量赋值。
我们在上文介绍了类加载的过程(加载 -> 连接 -> 初始化),在初始化这一步骤,JVM 为类的静态变量显示赋值,并且执行了静态代码块。实际上这一步骤是由 JVM 生成的 <clinit> 方法完成的。
<clinit> 的执行的顺序为:
- 父类静态变量初始化
- 父类静态代码块
- 子类静态变量初始化
- 子类静态代码块
而我们在创建实例 new 一个对象时,会调用该对象类构造器进行初始化,这里面就会执行 <init> 方法。
<init>的执行顺序为:
- 父类变量初始化
- 父类普通代码块
- 父类构造函数
- 子类变量初始化
- 子类普通代码块
- 子类构造函数
关于<init> 方法:
- 有多少个构造器就会有多少个
<init>方法 <init>具体执行的内容包括非静态变量的赋值操作,非静态代码块的执行,与构造器的代码- 非静态代码赋值操作与非静态代码块的执行是从上至下顺序执行,构造器在最后执行
关于 <clinit> 与 <init> 方法的差异:
<clinit>方法在类加载的初始化步骤执行,<init>在进行实例初始化时执行<clinit>执行静态变量的赋值与执行静态代码块,而<init>执行非静态变量的赋值与执行非静态代码块以及构造器
第五步:在栈中新建对象的引用,并指向堆中新建的对象实例
这一点没什么好解释的,我们是通过操作栈的引用来操作一个对象的。
拓展:对象的访问定位
在描述完 new 一个对象后,我们再来简单看一下如何去访问这个对象。
在 JVM 规范中只规定了 reference 类型是一个指向对象的引用,但没有规定这个引用具体如何去定位,访问堆中对象,因此对象的访问取决于 JVM 的具体实现,目前主流的访问对象的方式有两种:句柄间接访问 与 直接指针访问。
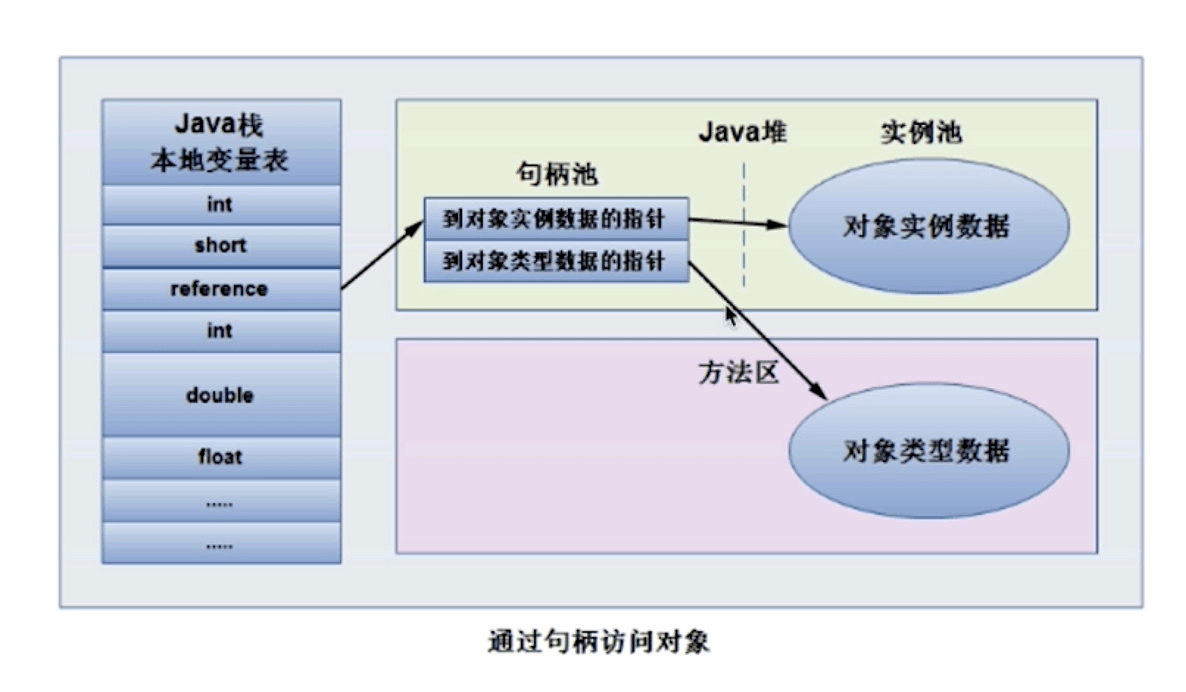
句柄
JVM 堆中会划分一块内存来作为句柄池,reference 中存储句柄的地址,句柄中则存储对象的实例数据何类的元数据的地址:
直接指针
直接指针的方式为:JVM 堆中会存放访问访问类的元数据的地址,reference存储的是对象实例的地址:
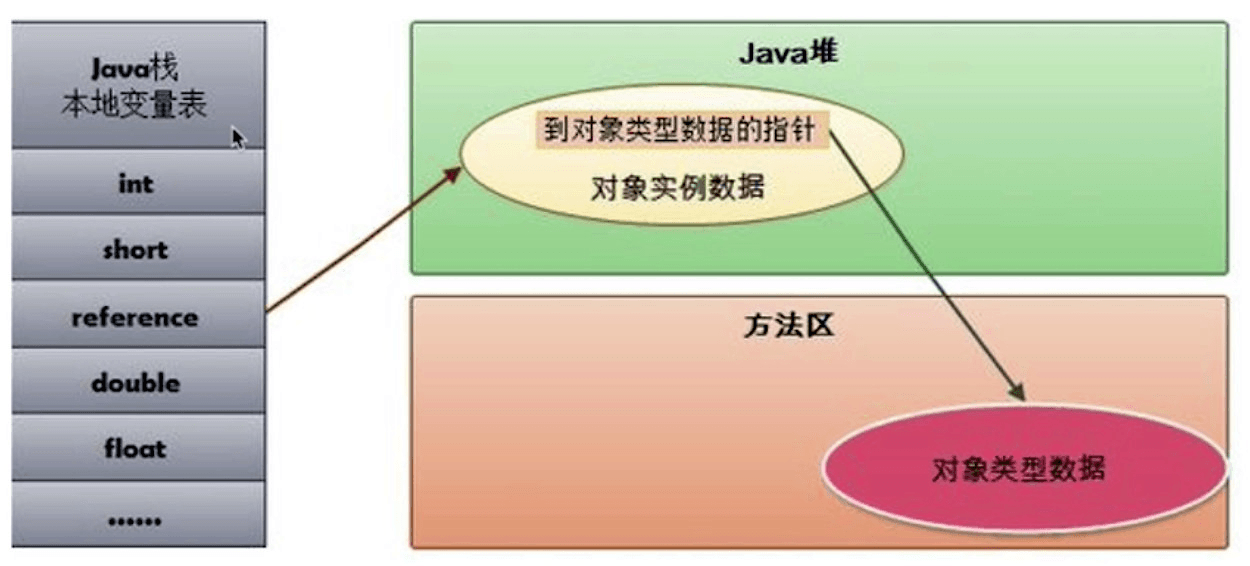
通过句柄访问对象是一种间接引用(2次引用)的方式来进行访问堆内存的对象,它导致的缺点是运行的速度稍微慢一些;通过指针的方式则速度快一些,因为它少了一次指针定位的开销,所以,当前最主流的 JVM: HotSpot 采用的就是直接指针的方式。
一个关于类初始化机制和顺序的面试题
MyTestClass
public class MyTestClass {private static MyTestClass myTestClass = new MyTestClass();private static int a = 0;private static int b;private MyTestClass() {a++;b++;}public static MyTestClass getInstance() {return myTestClass;}public int getA() {return a;}public int getB() {return b;}}
Test
public class Test {public static void main(String[] args) {MyTestClass myTestClass = MyTestClass.getInstance();System.out.println("myTestClass.a : " + myTestClass.getA());System.out.println("myTestClass.b : " + myTestClass.getB());}}
请问程序输出的结果?
这个问题涉及到了类的初始化顺序
先来看看答案:
myTestClass.a : 0myTestClass.b : 1
为什么出现这样的结果呢?
我们再次回顾下类的加载过程:
加载 -> 连接(验证 -> 准备 -> 解析) -> 初始化 -> 使用 -> 卸载
首先在连接的准备阶段,JVM 会为类的静态变量分配内存,并赋缺省值,即:
myTestClass = null;
a = 0;
b = 0;
接着,在类的初始化阶段,会为这些静态变量赋初始值
myTestClass = new MyTestClass();
这句话会回调构造器
private MyTestClass() {
a++;
b++;
}
让a++,b++;导致 a 和 b 的结果均为 1
然后代码执行到:
a = 0;
b;
这个时候,执行对 a 和 b 真正的初始化赋值
又将 a 变为了 0 ;而 b 则没有赋值结果仍然是 1;所以输出结果为
myTestClass.a : 0
myTestClass.b : 1
我们再来看一个变形题目:
MyTestClass2
public class MyTestClass2 {
private static int a = 0;
private static int b;
private MyTestClass2(){
a++;
b++;
}
private static final MyTestClass2 myTestClass2 = new MyTestClass2();
public static MyTestClass2 getInstance(){
return myTestClass2;
}
}
Test
public class Test {
public static void main(String[] args) {
MyTestClass2 myTestClass2 = MyTestClass2.getInstance();
System.out.println("myTestClass2.a : " + myTestClass2.getA());
System.out.println("myTestClass2.b : " + myTestClass2.getB());
}
}
那么这个程序运行的结果为多少呢?
结果为:
myTestClass2.a : 1
myTestClass2.b : 1
我们再次按照类的初始化顺序进行分析:
首先在连接的准备阶段,JVM 会为类的静态变量分配内存,并赋缺省值,即:
a = 0;
b = 0;
myTestClass2 = null;
然后,在类的初始化阶段,会为这些静态变量赋初始值
首先,代码执行到:
a = 0;
b;
a 赋初始值为 0,然后 b 没有赋值,其结果还是 0
接着,执行到语句:
myTestClass = new MyTestClass();
这句话会回调构造器
private MyTestClass() {
a++;
b++;
}
执行:a++,b++,导致 a 和 b 的结果均为 1,所以最终程序输出的结果为:
myTestClass2.a : 1
myTestClass2.b : 1
Java 创建对象的几种方式
本部分内容可以等到学习过 Java IO 流和反射之后再进行深入阅读!
Java 中创建对象有四种方式:
- 使用
new关键字 - 反射
- 使用
clone()方法 - 序列化与反序列化
1. 使用new关键字创建对象
public class Person {
private String name;
private int age;
public Person() {
this.name = "default";
this.age = 0;
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public void info() {
System.out.println("My name is " + name + ", I'm " + age + "years old.");
}
public static void main(String[] args) {
Person p1 = new Person("Jack",30);
p1.info();
}
}
程序输出结果:
My name is Jack, I'm 30 years old.
2. 使用反射创建对象
反射创建对象的方式还可以具体划分为
- 使用
Class类的newInstance方法 - 使用
Constructor类的newInstance方法
使用**Class**类的**newInstance**方法创建对象
这个方法会调用无参构造器来创建对象
public class Person {
private String name;
private int age;
public Person() {
this.name = "default";
this.age = 0;
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public void info() {
System.out.println("My name is " + name + ", I'm " + age + " years old.");
}
public static void main(String[] args) throws ClassNotFoundException, IllegalAccessException, InstantiationException {
Person p2 = (Person)Class.forName("test.Person").newInstance();
Person p3 = Person.class.newInstance();
p2.info();
p3.info();
}
}
程序输出结果:
My name is default, I'm 0 years old.
My name is default, I'm 0 years old.
使用**Constructor**类的**newInstance**方法创建对象
和Class类的newInstance方法很像,java.lang.reflect.Constructor类里也有一个newInstance方法可以创建对象。我们可以通过这个newInstance方法调用有参数的和私有的构造函数。
import java.lang.reflect.InvocationTargetException;
public class Person {
private String name;
private Integer age;
public Person() {
this.name = "default";
this.age = 18;
}
public Person(String name){
this(name,18);
}
// 私有构造器
private Person(String name, Integer age) {
this.name = name;
this.age = age;
}
public void info() {
System.out.println("My name is " + name + ", I'm " + age + " years old.");
}
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, IllegalAccessException, InvocationTargetException, InstantiationException {
Person p4 = (Person) Class.forName("test.Person").getConstructor(String.class).newInstance("Tracy");
p4.info();
Person p5 = (Person) Class.forName("test.Person").getDeclaredConstructor(String.class,Integer.class).newInstance("James",25);
p5.info();
}
}
程序运行结果:
My name is Tracy, I'm 18 years old.
My name is James, I'm 25 years old.
3. 使用clone()方法创建对象
关于clone()方法,有几个需要特别注意的点:
- 一个类,需要实现
Cloneable接口,才能调用Object的clone()方法,否则会报CloneNotSupportedException clone()并不会调用被复制实例的构造函数clone()方法实际上为浅拷贝,在《Core Java》中提到了这一点:应该完全避免使用clone()方法,而使用其他方法达到拷贝的目的,例如工厂模式,或者序列化等等。
我们来看如下程序:
public class Person implements Cloneable {
private int age;
private String name;
public Person(int age,String name){
this.age = age;
this.name = name;
}
public int getAge(){
return this.age;
}
public String getName(){
return this.name;
}
@Override
public Object clone(){
Person p = null;
try {
p = (Person) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return p;
}
public static void main(String[] args) {
Person p1 = new Person(26,"kim");
Person p2 = (Person)p1.clone();
System.out.println(p1.getName() == p2.getName() ? "shallow copy" : "deep copy");
}
}
该程序运行的结果为:
shallow copy
我们来看下本程序的内存分配图:

从本图中就可以看出,clone()方法只是field-to-field-copy,也就是它的本质是浅拷贝
而真正的深拷贝则应该是这样的:

4. 使用序列化与反序列化创建对象
所谓的序列化是指:将对象通过流的方式存储到磁盘中;
反序列化则是将磁盘上的对象信息转换到内存中
使用序列化,首先要实现Serializable接口,如果我们想要序列化的对象的类没有实现Serializable接口,那么就会抛出NotSerializableException异常;其次要求:
- 对象中的所有属性也都是可以序列化才能被序列化,
static变量无法序列化 - 如果某个属性不想序列化,可以在属性上加
transient关键字
程序示例如下:
序列化
import java.io.*;
public class Person implements Serializable {
private int age;
private String name;
public Person(int age, String name) {
this.age = age;
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public void info() {
System.out.println("My name is " + name + ", I'm " + age + " years old.");
}
public static void main(String[] args) throws IOException {
File file = new File("src\\test\\file.txt");
ObjectOutputStream o = new ObjectOutputStream(new FileOutputStream(file));
Person p = new Person(30,"Jack");
o.writeObject(p);
}
}
反序列化
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
public class Test {
public static void main(String[] args) throws IOException, ClassNotFoundException {
File file = new File("src\\test\\file.txt");
ObjectInputStream o = new ObjectInputStream(new FileInputStream(file));
Person p = (Person) o.readObject();
p.info();
}
}
序列化与反序列化的方式创建对象不会调用类的构造器,并且序列化反序列化方式创建对象的本质是深拷贝。
2:方法的重载
什么是方法的重载?
重载(overload)是指我们可以定义一些名称相同的方法,通过定义不同的输入参数来区分这些方法,然后在调用方法的时候,JVM会根据不同的参数样式来选择合适的方法执行。
示例程序:
public class Overload {
public void info(String name, int age) {
System.out.println("my name is "
+ name
+ ",I'm " + age + " years old");
}
public void info(String name, int age, String hobby) {
System.out.println("my name is "
+ name
+ ",I'm " + age + " years old,"
+ "and My hobby is " + hobby);
}
public static void main(String[] args) {
Overload overload = new Overload();
overload.info("Kim",27);
overload.info("Kim",27,"football");
}
}
该程序输出结果:
my name is Kim,I'm 27 years old.
my name is Kim,I'm 27 years old,and My hobby is football
方法重载和重写的区别
首先,方法重载和重写没有任何关系
重载我们已经介绍过了,什么是重写呢?重写(override)是应用在 Java 多态中,让子类表现出和父类不同特点的一种能力;子类重写的新方法将覆盖父类原有的方法。这一部分我们会在 Java 继承部分着重讲解。
重写的示例程序:
public class Polymorphic {
public static void main(String[] args) {
// 父类的引用指向子类的对象
Animal cat = new Cat();
cat.speak(); // 重写父类的speak方法
}
}
class Animal {
public void speak(){
System.out.println("我是一个动物");
}
}
class Cat extends Animal{
@Override
public void speak() {
System.out.println("我是一只猫");
}
}
为什么不能根据返回类型区分重载
我们能否根据返回类型区分重载呢?答案是否定的。
因为在调用时,如果不指定返回类型信息,编译器不知道你要调用哪一个函数。
假设,可以根据返回类型区分方法重载
示例程序:
float max(int a,int b){...};
int max(int a,int b){...};
当我们没有用变量去接收函数返回值,仅仅调用max(1,2)时,编译器是无法确定调用的具体是哪一个方法,单从这一点上来说,仅返回值类型不同的重载是不应该允许的。
所以,重载设计成方法名相同,标签不同(参数的个数或类型不同)才是合理的。
重载的优先级匹配
重载方法参数匹配优先级顺序为:
- 匹配直接能够匹配到的类型
- 匹配“最近的”自动转换类型
- 匹配装箱类型
- 匹配接口实现
- 匹配父类
- 匹配变长参数
我们来看一个示例程序:
import java.io.Serializable;
public class Reload {
// 直接匹配到的类型
public static void test(char arg) {
System.out.println("char");
}
// 自动转换类型 char -> int
public static void test(int arg) {
System.out.println("int");
}
// 自动转换类型 char -> long
public static void test(long arg) {
System.out.println("long");
}
// 装箱类型
public static void test(Character arg) {
System.out.println("Character");
}
// 匹配接口
public static void test(Serializable arg) {
System.out.println("Serializable");
}
// 匹配父类
public static void test(Object obj) {
System.out.println("Object");
}
// 匹配变长参数
public static void test(char... arg) {
System.out.println("char...");
}
public static void main(String[] args) {
test('a');
}
}
将重载方法从上至下依次注释掉,我们获得的结果依次为:
char
int
long
Character
Serializable
Object
char...
3:对象的初始化顺序
在没有继承的条件下,实例化一个对象初始化的顺序为:
- 静态成员的初始化
- 静态初始化块
- 成员的初始化
- 初始化块
- 构造器
这里面需要注意的是【静态部分只在类加载时初始化一次】
如果有继承关系,那么实例化子类对象的初始化顺序为:
- 父类静态成员的初始化
- 父类静态代码块初始化
- 子类静态成员的初始化
- 子类静态代码块初始化
- 父类成员的初始化
- 父类初始化块
- 父类构造器
- 子类成员的初始化
- 子类初始化块
- 子类构造器
我们来看两道题目加深下理解。
题目一:
请说出该程序的输出结果?
class Test {
{
System.out.println("非静态代码块1");
}
{
System.out.println("非静态代码块2");
}
static {
System.out.println("静态代码块1");
}
static {
System.out.println("静态代码块2");
}
public Solution(){
System.out.println("构造器");
}
public static void main(String[] args) {
new Test();
new Test();
}
}
答案:
程序的输出结果为:
静态代码块1
静态代码块2
非静态代码块1
非静态代码块2
构造器
非静态代码块1
非静态代码块2
构造器
解析:
静态代码块:在虚拟机加载类的时候就会加载执行,并且只执行一次;所有的静态代码块按照书写的顺序进行加载执行,所以静态代码块会最先按顺序输出,并且只输出了一次。
非静态代码块(或者叫做初始化块)与构造器在每次生成实例(对象)的时候都会执行一次;非静态代码块会在构造器前执行,且非静态代码块按照书写顺序依次执行。
题目二:
题目二涉及到了继承,学完继承之后,可以回过头再看本题加深理解。
请说出该程序的输出结果?
class A {
public A() {
System.out.println("class A constructor");
}
{
System.out.println("class A block");
}
static {
System.out.println("class A static block");
}
}
public class B extends A {
public B() {
System.out.println("class B constructor");
}
{
System.out.println("class B block");
}
static {
System.out.println("class B static block");
}
public static void main(String[] args) {
new B();
}
}
答案:
class A static block
class B static block
class A block
class A constructor
class B block
class B constructor
我们通过有继承关系实例化子类对象的初始化顺序就可以分析出答案,就不再赘述整个过程了。
4:对象的生命周期
在 JVM 运行空间中,对象的整个生命周期大致可以分为七个阶段:
- 创建阶段(Creation)
- 应用阶段(Using)
- 不可视阶段(Invisible)
- 不可达阶段(Unreachable)
- 可收集阶段(Collected)
- 终结阶段(Finalized)
- 释放阶段(Free)
创建阶段
一个对象想要进入创建阶段,前提是它的类文件必须已经加载到内存中,并且已经创建了 Class 对象,这样才能根据类信息进行创建
在对象的创建阶段,系统通过以下步骤完成对象的创建过程:
- 为对象在堆内存中分配空间
- 构造对象。从最顶层的父类开始对局部变量进行赋值
- 从最顶层的父类开始往下调用构造方法
应用阶段
当对象创建阶段结束之后,通常就会进入到对象的应用阶段。这个阶段是对象得以表现自身能力的阶段。也就是说对象的应用阶段是对象整个生命周期中证明自身“存在价值”的时期。在对象的应用阶段,对象具备下列特征:
- 系统至少维护着对象的一个强引用(Strong Reference)
- 所有对该对象的引用全部是强引用(除非我们显式地使用了:软引用(Soft Reference)、弱引用(Weak Reference)或虚引用(Phantom Reference))
不可视阶段
不可视阶段中,对象存在且被引用,但是这个引用在接下来的代码中并没有被使用到,这就造成了内存的冗余。
例如代码:
public void process() {
try {
MyObject obj = new MyObject();
obj.doSomething();
}catch (Exception e) {
e.printStackTrace();
}
while (true) {
// 该代码块对 obj 对象来说已经是不可视的
// 因此下面代码在编译时会引发错误
obj.doSomething();
}
}
如果一个对象已经使用完毕,并且在可视区域内不再使用,那么应该主动将其设置为 null。这样做的意义是,可以帮助 JVM 及时地发现这个垃圾对象,并且可以及时地回收该对象所占用的系统资源。
不可达阶段
当一个对象没有再被强引用时,就会进入不可达阶段,在这个阶段中,对象随时会被回收,这由 JVM 中的垃圾回收器(GC)来决定
可收集阶段、终结阶段与释放阶段
对象生命周期的最后一个阶段是可收集阶段、终结阶段与释放阶段。当对象处于这个阶段的时候,可能处于下面三种情况:
- 垃圾回收器发现该对象已经不可到达
- finalize 方法已经被执行
- 对象空间已被重用
当对象处于上面三种情况时,该对象就处于可收集阶段、终结阶段与释放阶段了。虚拟机就可以直接将该对象回收了。
JVM 如何判断哪个对象没有被用到
JVM 通过 GC Roots 来判断对象是否“存活”。
这是 GC 算法中的一种,叫做根搜索算法。
从根(GC Roots)节点向下搜索对象节点,搜索走过的路径称为引用链,当一个对象到根之间没有连通的话,则该对象不可用。
根搜索算法示意图:

可以作为 GC Roots 的对象包括:
- 虚拟机栈(栈帧局部变量)中引用的对象
- 方法区类静态属性引用的对象
- 方法区中常量( final )引用的对象
- 本地方法栈中 JNI 引用的对象

若有收获,就点个赞吧
0 人点赞
