3-1 使用 Eureka 作为服务注册中心
什么是 Eureka
在本地启动一个简单的 Eureka 服务
Starter
- spring-cloud-dependencies
- spring-cloud-starter-nextflix-eureka-starter
声明
@EnableEurekaServer
注意事项
- 默认端口号为 8761
如果是启动单节点的 Eureka Server,那么注意自己不要注册到 Eureka 上了
# 不向 Eureka 注册中心注册当前服务eureka.client.register-with-eureka=false# 不从 Eureka 注册中心获取服务列表eureka.client.fetch-registry=false
将服务注册到 Eureka Server
Starter
spring-cloud-starter-netflix-eureka-client
声明
@EnableDiscoveryClient@EnableEurekaClient
以上两个注解,都能够让注册中心发现服务。不同点是,@EnableEurekaClient 只适用于 Eureka 作为注册中心,而 @EnableDiscoveryClient 则是 Spring Cloud 提供的抽象 DiscoveryClient 的注解,适用于所有的注册中心,譬如:Zookeeper,Consul 等。我们知道 Eureka 2.x 已经停止维护了,Consul 会逐渐成为主流,所以,建议使用前者,也就是 @EnableDiscoveryClient 。
一些配置项
- eureka.client.service-url.defaultZone
eureka.client.instance.prefer-ip-address
关于 Bootstrap 属性
Bootstrap 属性
启动引导阶段加载到属性
- bootstrap.properties | .yml
- spring.cloud.bootstrap.name = bootstrap
常用配置
- spring.application.name = 应用
-
Eureka 核心功能
通过上文我们也知道了,Eureka 的核心功能主要有两个:
Service Registry (服务注册)
-
Eureka 基本架构
Eureka 由三个角色组成:
Eureka Server,其功能为提供服务注册与发现
- Service Provider,服务提供方,将自身的服务注册到 Eureka Server 上,从而让 Eureka Server 持有服务的元信息,让其他的服务消费方能够找到当前服务
- Service Consumer,服务消费方,从 Eureka Server 上获取注册服务列表,从而能够消费服务
Eureka 的基本架构如图所示: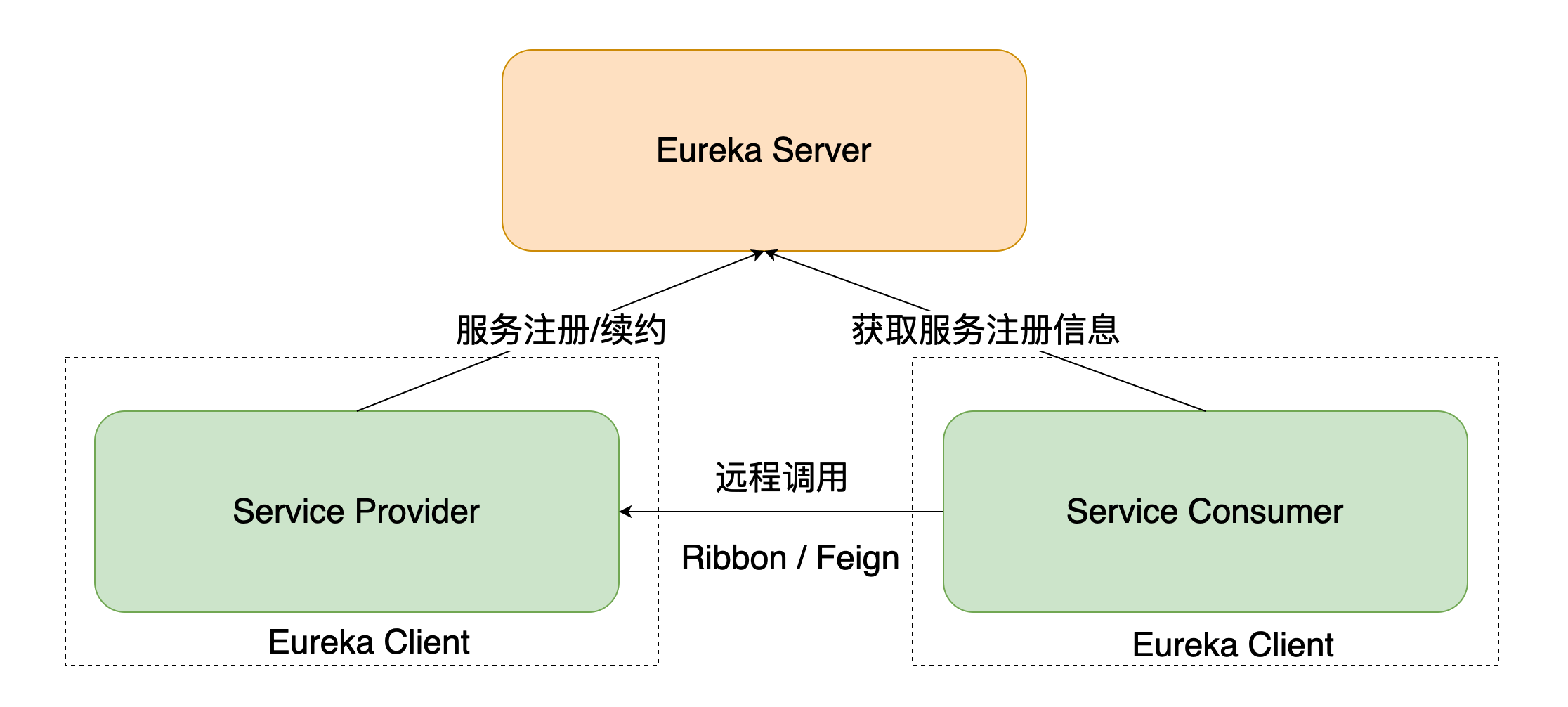
无论是 Service Consumer 还是 Service Provider 相对于 Server 都叫做 Eureka Client。
3-2 Eureka Server 的高可用
问题说明:
但节点的 Eureka Server 虽然能够实现基本的服务注册与发现功能,但是存在单节点故障的问题,不能实现高可用。因为 Eureka Server 中存储了整个系统中所有微服务的元数据信息,单节点一旦挂掉,所有的服务信息都会丢失,造成整个系统的瘫痪。
解决方法:
搭建 Eureka Server 集群,让各个 Server 节点之间互相注册,从而实现微服务元数据的复制/备份。这样一来,即便是单个节点失效,其他的 Server 节点仍然可以继续提供服务。
Eureka Server 集群架构如图所示:
配置文件 application.yml 如下所示(三节点):
# /etc/hosts 文件中配置:
# 127.0.0.1 server1
# 127.0.0.1 server2
# 127.0.0.1 server3
# eureka-server 集群配置的原理就是不同的 eureka-server 互相注册
---
# server 1
spring:
application:
name: ad-eureka-server
profiles: server1
server:
port: 8000
eureka:
instance:
hostname: server1
prefer-ip-address: false
client:
service-url:
defaultZone: http://server2:8001/eureka/,http://server3:8002/eureka/
---
# server 2
spring:
application:
name: ad-eureka-server
profiles: server2
server:
port: 8001
eureka:
instance:
hostname: server2
prefer-ip-address: false
client:
service-url:
defaultZone: http://server1:8000/eureka/,http://server3:8002/eureka/
---
# server 3
spring:
application:
name: ad-eureka-server
profiles: server3
server:
port: 8002
eureka:
instance:
hostname: server3
prefer-ip-address: false
client:
service-url:
defaultZone: http://server1:8000/eureka/,http://server2:8001/eureka/
# 启动命令
# 首先需要到父工程目录下执行命令:mvn clean package -Dmaven.test.skip=true
# 然后到 ad-eureka-server 子工程的 target 目录下 执行如下命令
# java -jar ad-eureka-server-0.0.1-SNAPSHOT.jar --spring.profiles.active=server1
# java -jar ad-eureka-server-0.0.1-SNAPSHOT.jar --spring.profiles.active=server2
# java -jar ad-eureka-server-0.0.1-SNAPSHOT.jar --spring.profiles.active=server3
3-3 Eureka 的相关问题与解答
问题一:Eureka Server 维护了系统中服务的元信息,这些元信息是什么?
Eureka 的元信息有两种:
- 标准元数据
- 自定义元数据
标准元数据包括:主机名,IP 地址,端口号,状态页和健康检查等信息,这些信息都会被发布在服务注册表中,用于服务之间的调用。
自定义元数据可以通过 eureka.instance.metadata-map 属性进行配置,为 K/V 的存储格式,这些元数据在远程客户端中进行访问。
当一个 Eureka Client 向 Eureka Server 发起注册时,会调用 DiscoveryClient#register 方法:
/**
* Register with the eureka service by making the appropriate REST call.
*/
boolean register() throws Throwable {
logger.info(PREFIX + "{}: registering service...", appPathIdentifier);
EurekaHttpResponse<Void> httpResponse;
try {
httpResponse = eurekaTransport.registrationClient.register(instanceInfo);
} catch (Exception e) {
logger.warn(PREFIX + "{} - registration failed {}", appPathIdentifier, e.getMessage(), e);
throw e;
}
if (logger.isInfoEnabled()) {
logger.info(PREFIX + "{} - registration status: {}", appPathIdentifier, httpResponse.getStatusCode());
}
return httpResponse.getStatusCode() == Status.NO_CONTENT.getStatusCode();
}
这里面的 instanceInfo 就是 Eureka Server 维护的元数据。
问题二:元信息是如何存储的?
Eureka Server 是如何存储 Client 的元信息的呢?
首先,Client 会向 Server 发起注册(Http 请求),ApplicationResource#addInstance方法实现了服务注册的功能(Server 端):
@POST
@Consumes({"application/json", "application/xml"})
public Response addInstance(InstanceInfo info,
@HeaderParam(PeerEurekaNode.HEADER_REPLICATION) String isReplication) {
// 校验 instanceinfo 中是否包含必须的属性
if (isBlank(info.getId())) {
return Response.status(400).entity("Missing instanceId").build();
} else if (isBlank(info.getHostName())) {
return Response.status(400).entity("Missing hostname").build();
}
......
// 注册信息校验
......
// 通过 PeerAwareInstanceRegistry 的 register 方法完成 Client 的注册
registry.register(info, "true".equals(isReplication));
return Response.status(204).build();
}
继续来看 AbstractInstanceRegistry 的 register 方法:
public void register(InstanceInfo registrant, int leaseDuration, boolean isReplication) {
try {
read.lock();
// registry 存储了注册信息, 它是一个两层的 Map 结构
// ConcurrentHashMap<String, Map<String, Lease<InstanceInfo>>> registry
Map<String, Lease<InstanceInfo>> gMap = registry.get(registrant.getAppName());
REGISTER.increment(isReplication);
if (gMap == null) {
final ConcurrentHashMap<String, Lease<InstanceInfo>> gNewMap = new ConcurrentHashMap<String, Lease<InstanceInfo>>();
gMap = registry.putIfAbsent(registrant.getAppName(), gNewMap);
if (gMap == null) {
gMap = gNewMap;
}
}
Lease<InstanceInfo> existingLease = gMap.get(registrant.getId());
......
Lease<InstanceInfo> lease = new Lease<InstanceInfo>(registrant, leaseDuration);
if (existingLease != null) {
lease.setServiceUpTimestamp(existingLease.getServiceUpTimestamp());
}
gMap.put(registrant.getId(), lease);
......
} finally {
read.unlock();
}
}
InstanceInfo 也就是元数据信息存储在一个 ConcurrentHashMap 对象中。Eureka Server 使用两层 Map 结构进行存储:第一层的 Key 用来存储服务名,对应 InstanceInfo 中的 appName 属性;第二层的 Key 用来存储实例名,对应 InstanceInfo 中的 instanceId 属性。
3-4 微服务架构及网关组件介绍
微服务架构及其应用场景
微服务架构主要分为两种:
- 点对点方式
- API-网关方式
点对点方式
点对点的方式为:服务之间直接调用,每个微服务都开放 REST API,并调用其他微服务接口。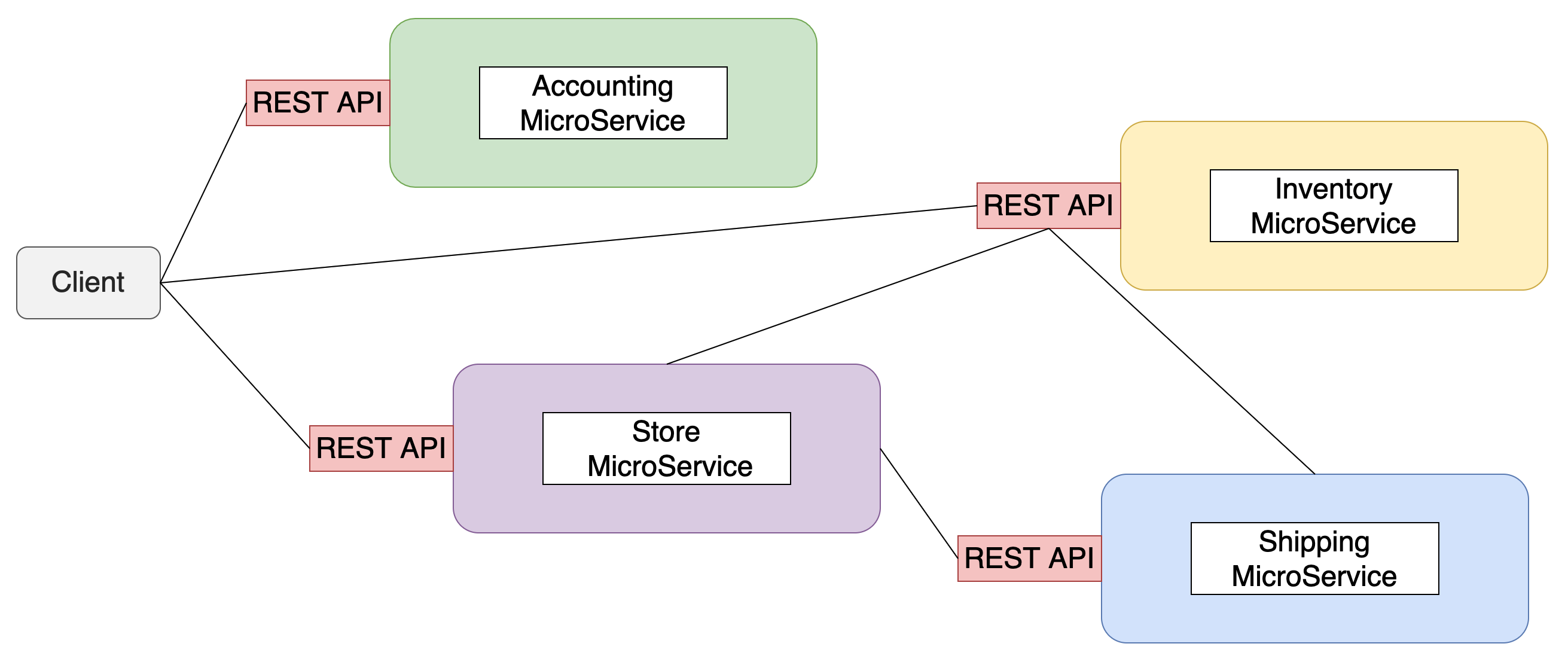
API-网关方式
API-网关方式为:业务接口通过 API 网关暴露,是所有客户端接口的唯一入口,微服务之间的通信业通过 API 网关。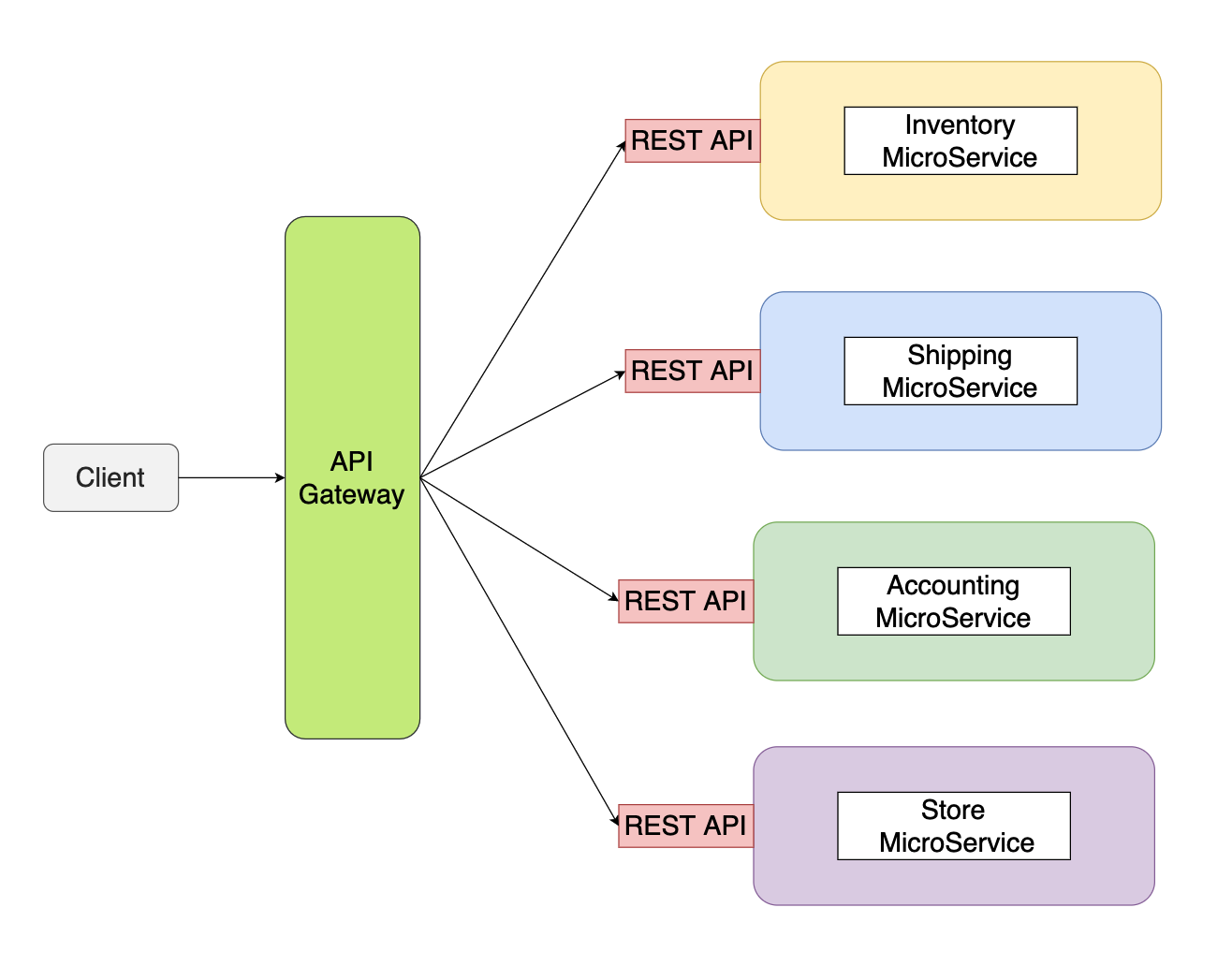
点对点方式带来的最大问题是 REST API 一旦发生了改变,那么客户端的代码就要进行修改,业务和处理微服务之间调用产生了高耦合;而 API 网关则可以屏蔽内部微服务的微小变动,保持整个系统的稳定性。
Zuul 是 Spring Cloud 中微服务的 API 网关的一种实现。
Zuul 提供了服务网关的功能,可以实现负载均衡,反向代理,动态路由,请求转发等功能。Zuul 大部分功能都是通过过滤器实现的,Zuul 中定义了四种标准的过滤器类型,同时,还支持自定义过滤器。
Zuul 的生命周期
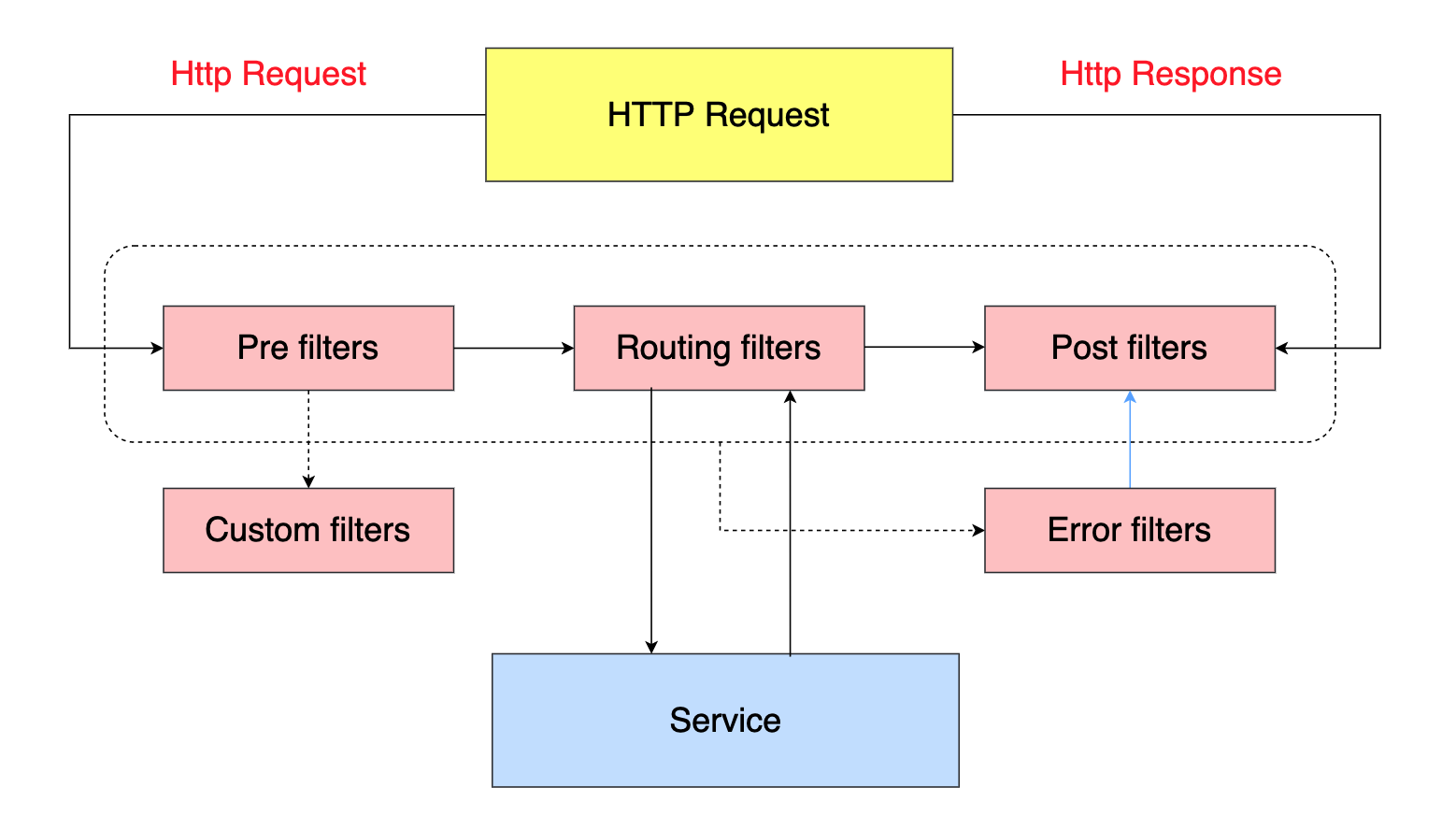
Pre filters 在请求被路由之前调用,我们可以利用这种过滤器进行身份验证等功能;Routing filters 在路由请求时被调用,负责将请求路由到微服务,它的主要功能是构造发送给微服务的请求;Post filters 在 route 和 error 过滤器之后被调用,这种过滤器可以用来为响应添加 HTTP Header,收集统计信息和指标,将响应从微服务发送给客户端等等功能;Error filters 是当请求发生错误时执行的过滤器。
除了默认的过滤器,Zuul 也支持自定义过滤器(Custom filters)。
实现一个过滤器,其功能为记录请求的延迟时间:
PreRequestFilter
/**
* 记录一次请求开始的时间
*/
@Slf4j
@Component
public class PreRequestFilter extends ZuulFilter {
/**
* 这是一个 pre 类型的过滤器,会在请求被路由之前调用
*
* @return
*/
@Override
public String filterType() {
return FilterConstants.PRE_TYPE;
}
@Override
public int filterOrder() {
return 0;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() throws ZuulException {
RequestContext ctx = RequestContext.getCurrentContext();
ctx.set("startTime", System.currentTimeMillis());
return null;
}
}
PostRequestFilter
/**
* 计算一次请求的响应时间;其作用为记录延迟
*/
@Component
@Slf4j
public class PostRequestFilter extends ZuulFilter {
@Override
public String filterType() {
return FilterConstants.POST_TYPE;
}
/**
* 定义执行顺序为最后执行
*
* @return
*/
@Override
public int filterOrder() {
return FilterConstants.SEND_RESPONSE_FILTER_ORDER - 1;
}
@Override
public boolean shouldFilter() {
return true;
}
@Override
public Object run() throws ZuulException {
RequestContext ctx = RequestContext.getCurrentContext();
HttpServletRequest request = ctx.getRequest();
Long startTime = (Long) ctx.get("startTime");
String uri = request.getRequestURI();
long duration = System.currentTimeMillis() - startTime;
log.info("uri : {}, duration : {}", uri, duration / 100 + "ms");
return null;
}
}
3-5 Zuul 的相关问题与解答
问题一:如果要给我们的系统接入用户模块(用户和权限),放在网关里面做合适么?
答:
Zuul 作为网关,是所有请求的公共入口,那么,所有前置(不牵扯到 Controller,Service 中的业务逻辑都被称为前置功能)功能的都应该放在网关层去完成。所以,这里面的用户模块,只涉及到用户和权限,是可以放在网关里面实现的。用户的请求会带有用户的信息,网关里面通过 Feign 调用用户微服务的功能,来判断请求是否继续下发或拦截。

若有收获,就点个赞吧
0 人点赞
