Redis的应用场景
- 做缓存,减轻数据库的压力,提高并发量和系统的响应时间
- 做session存储,将多台机器的session统一管理,在redis(集群)中存储。通过网络和IO进行session复制,会极大的影响了系统的性能,session存储到redis很好的解决了这一问题
- 做分布式锁,以后写
Redis为什么是单线程的?(必考)
一个关键的瓶颈就是,系统中通常会存在多个线程同时访问共享的数据资源的情况,比如一个共享的数据结构,这时多个线程不免会发生竞争。对于数据库而言,很能造成数据的读写冲突,造成数据误写误读的情况。要想解决这一情况,就必须采用加锁等机制,来保证数据的安全性,然而这个而外的机制也会带来而外的开销。因此多线程未必会优于单线程。
并发访问控制一直是多线程开发中的一个难点问题,如果没有精细的设计,比如说,只是简单地采用一个粗粒度互斥锁,就会出现不理想的结果:即使增加了线程,大部分线程也在等待获取访问共享资源的互斥锁,并行变串行,系统吞吐率并没有随着线程的增加而增加。
而且,采用多线程开发一般会引入同步原语来保护共享资源的并发访问,这也会降低系统代码的易调试性和可维护性。为了避免这些问题,Redis直接采用了单线程模式。
redis是基于内存的,cpu不是redis的瓶颈,redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现且安全,而且CPU不会成为瓶颈,那就顺利成章地采用单线程的方案了。
单线程Redis为什么那么快?
- 数据存储在内存中,读取的时候不需要进行磁盘的 I/O
- Redis 是单线程的,所有的读写操作都在一个线程上,避免了线程上下文切换的开销
- 高效的数据结构,哈希表,跳表等
- Redis采用了多路复用机制(下方具体讲),使其在网络IO操作中能并发处理大量的客户端请求,实现高吞吐率
- 合理的数据编码
- 其他优化, 6.0之后支持多线程更快
- 深入学习一文揭秘单线程的Redis为什么这么快?
基于多路复用的高性能I/O模型
Linux下 epoll(level-triggered),没有epoll用select。
IO多路复用机制是指一个线程处理多个IO流,就是我们经常听到的select/epoll机制。简单来说,在Redis只运行单线程的情况下,该机制允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给Redis线程处理,这就实现了一个Redis线程处理多个IO流的效果。
下图就是基于多路复用的Redis IO模型。图中的多个FD就是刚才所说的多个套接字。Redis网络框架调用epoll机制,让内核监听这些套接字。此时,Redis线程不会阻塞在某一个特定的监听或已连接套接字上,也就是说,不会阻塞在某一个特定的客户端请求处理上。正因为此,Redis可以同时和多个客户端连接并处理请求,从而提升并发性。
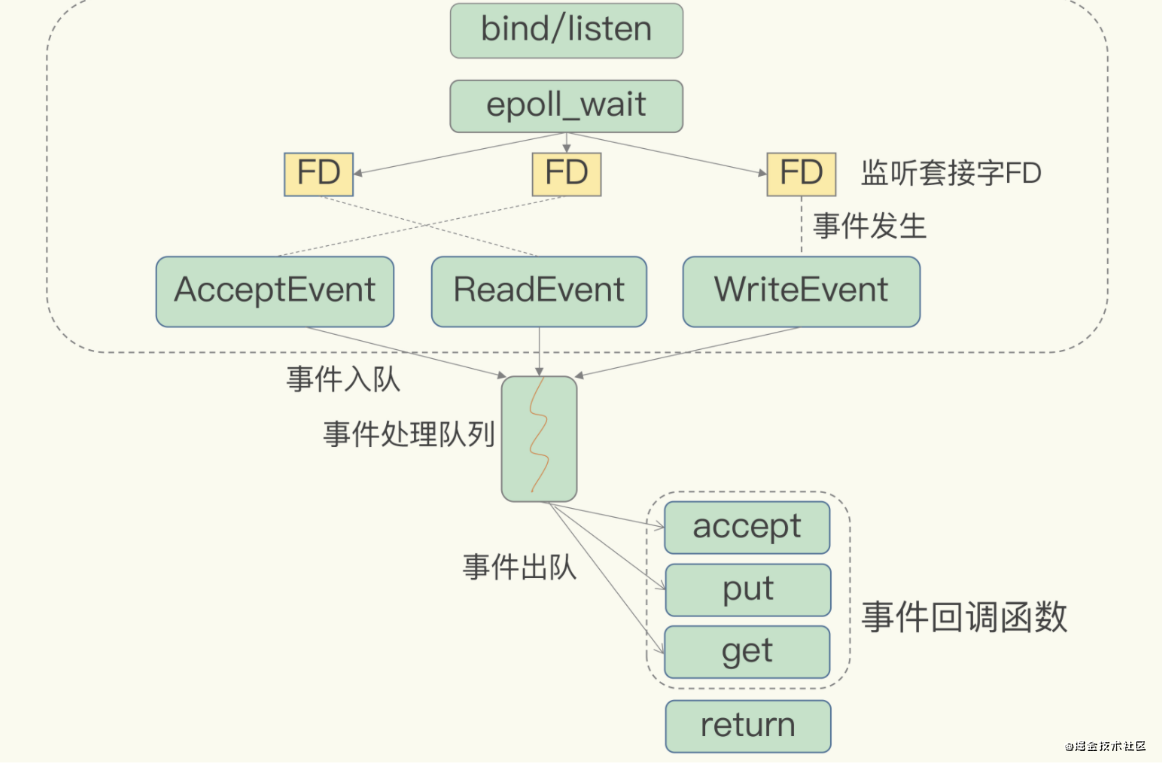
为了在请求到达时能通知到Redis线程,select/epoll提供了基于事件的回调机制,即针对不同事件的发生,调用相应的事件处理函数。
这些事件会被放进一个事件队列,Redis单线程对该事件队列不断进行处理。这样一来,Redis无需一直轮询是否有请求实际发生,这就可以避免造成CPU资源浪费。同时,Redis在对事件队列中的事件进行处理时,会调用相应的事件回调处理函数,这就实现了基于事件的回调。因为Redis一直在对事件队列进行处理,所以能及时响应客户端请求,不会因为一个连接阻塞掉,提升Redis的响应性能。
例子理解:两个请求分别对应Accept事件和Read事件,Redis分别对这两个事件注册accept和get回调函数。当Linux内核监听到有连接请求或读数据请求时,就会触发Accept事件和Read事件,此时,内核就会回调Redis相应的accept和get函数进行处理。
需要注意的是,即使你的应用场景中部署了不同的操作系统,多路复用机制也是适用的。因为这个机制的实现有很多种,既有基于Linux系统下的select和epoll实现,也有基于FreeBSD的kqueue实现,以及基于Solaris的evport实现,这样,你可以根据Redis实际运行的操作系统,选择相应的多路复用实现。
来源:掘金

若有收获,就点个赞吧
0 人点赞
