- 了解Reids集群三种模式
- Docker-redis集群+混合持久化搭建
- 搭建3主3从 共6节点
- 定义slave多久(秒)ping一次master,如果超过repl-timeout指定的时长都没有收到响应,则认为master挂了
- cluster-announce-ip 192.168.XX.XX
- redis密码
- 表示m秒内数据集存在n次修改时,自动触发bgsave
- 手动执行save该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。
- 显然该命令对于内存比较大的实例会造成长时间阻塞,这是致命的缺陷,为了解决此问题,Redis提供了第二种方式——bgsave
- 执行bgsave命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
- 基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
- 执行执行 flushall 命令,也会产生dump.rdb文件,但里面是空的.
- 关闭RDB功能的话,配置这个即可以,其他save要注释掉
- save 300 10
- dbfilename dump.rdb
- appendfilename appendonly.aof
- 文件达到64m时进行重写,然后如果文件大小增长了一倍,也会触发重写。
- 后台运行 —— docker中使用后台运行将无法启动容器(应该是容器无法检测后台运行进程)
- daemonize yes
- 修改第一个匹配到的port 6379 为 port $port
- Dokcer-redis集群新增节点
- Redis持久化
- 循环插入数据测试脚本参考
- 问题记录
了解Reids集群三种模式
主从复制模式
通过持久化功能,Redis保证了即使在服务器重启的情况下也不会丢失(或少量丢失)数据,因为持久化会把内存中数据保存到硬盘上,重启会从硬盘上加载数据。 但是由于数据是存储在一台服务器上的,如果这台服务器出现硬盘故障等问题,也会导致数据丢失。
为了避免单点故障,通常的做法是将数据库复制多个副本以部署在不同的服务器上,这样即使有一台服务器出现故障,其他服务器依然可以继续提供服务。
为此, Redis 提供了复制(replication)功能,可以实现当一台数据库中的数据更新后,自动将更新的数据同步到其他数据库上。
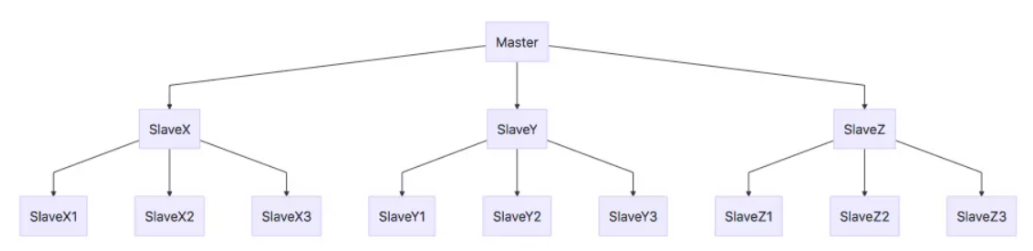
在复制的概念中,数据库分为两类,一类是主数据库(master),另一类是从数据库(slave)。主数据库可以进行读写操作,当写操作导致数据变化时会自动将数据同步给从数据库。而从数据库一般是只读的,并接受主数据库同步过来的数据。一个主数据库可以拥有多个从数据库,而一个从数据库只能拥有一个主数据库。
总结:引入主从复制机制的目的有两个
- 一个是读写分离,分担 “master” 的读写压力
-
主从复制原理
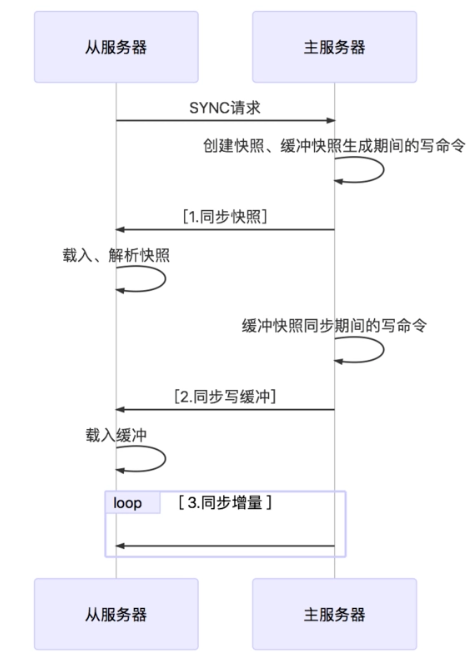
从数据库启动成功后,连接主数据库,发送 SYNC 命令;
- 主数据库接收到 SYNC 命令后,开始执行 BGSAVE 命令生成 RDB 文件并使用缓冲区记录此后执行的所有写命令;
- 主数据库 BGSAVE 执行完后,向所有从数据库发送快照文件,并在发送期间继续记录被执行的写命令;
- 从数据库收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主数据库快照发送完毕后开始向从数据库发送缓冲区中的写命令;
- 从数据库完成对快照的载入,开始接收命令请求,并执行来自主数据库缓冲区的写命令;(从数据库初始化完成)
- 主数据库每执行一个写命令就会向从数据库发送相同的写命令,从数据库接收并执行收到的写命令(从数据库初始化完成后的操作)
- 出现断开重连后,2.8之后的版本会将断线期间的命令传给重数据库,增量复制。
主从刚刚连接的时候,进行全量同步;全同步结束后,进行增量同步。当然,如果有需要,slave 在任何时候都可以发起全量同步。Redis 的策略是,无论如何,首先会尝试进行增量同步,如不成功,要求从机进行全量同步。
主从复制优缺点
主从复制优点
支持主从复制,主机会自动将数据同步到从机,可以进行读写分离;
- 为了分载 Master 的读操作压力,Slave 服务器可以为客户端提供只读操作的服务,写服务仍然必须由Master来完成;
- Slave 同样可以接受其它 Slaves 的连接和同步请求,这样可以有效的分载 Master 的同步压力;
- Master Server 是以非阻塞的方式为 Slaves 提供服务。所以在 Master-Slave 同步期间,客户端仍然可以提交查询或修改请求;
Slave Server 同样是以非阻塞的方式完成数据同步。在同步期间,如果有客户端提交查询请求,Redis则返回同步之前的数据;
主从复制缺点
Redis不具备自动容错和恢复功能,主机从机的宕机都会导致前端部分读写请求失败,需要等待机器重启或者手动切换前端的IP才能恢复(也就是要人工介入);
- 主机宕机,宕机前有部分数据未能及时同步到从机,切换IP后还会引入数据不一致的问题,降低了系统的可用性;
- 如果多个 Slave 断线了,需要重启的时候,尽量不要在同一时间段进行重启。因为只要 Slave 启动,就会发送sync 请求和主机全量同步,当多个 Slave 重启的时候,可能会导致 Master IO 剧增从而宕机。
Redis 较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂;
哨兵模式(Sentinel)
第一种主从同步/复制的模式,当主服务器宕机后,需要手动把一台从服务器切换为主服务器,这就需要人工干预,费事费力,还会造成一段时间内服务不可用。这不是一种推荐的方式,更多时候,我们优先考虑哨兵模式。
哨兵模式是一种特殊的模式,首先 Redis 提供了哨兵的命令,哨兵是一个独立的进程,作为进程,它会独立运行。其原理是哨兵通过发送命令,等待Redis服务器响应,从而监控运行的多个 Redis 实例。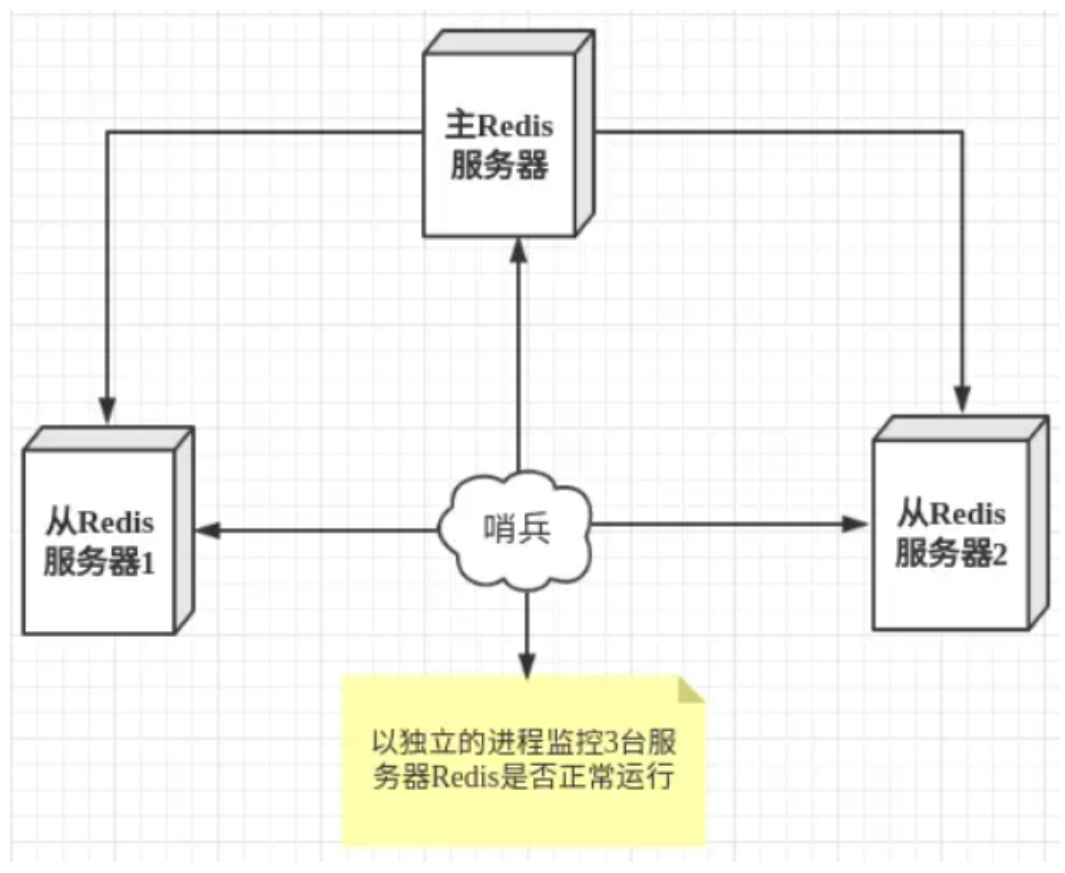
哨兵模式的作用
通过发送命令,让 Redis 服务器返回监控其运行状态,包括主服务器和从服务器;
- 当哨兵监测到 master 宕机,会自动将 slave 切换成 master ,然后通过发布订阅模式通知其他的从服务器,修改配置文件,让它们切换主机;
然而一个哨兵进程对Redis服务器进行监控,也可能会出现问题,为此,我们可以使用多个哨兵进行监控。各个哨兵之间还会进行监控,这样就形成了多哨兵模式。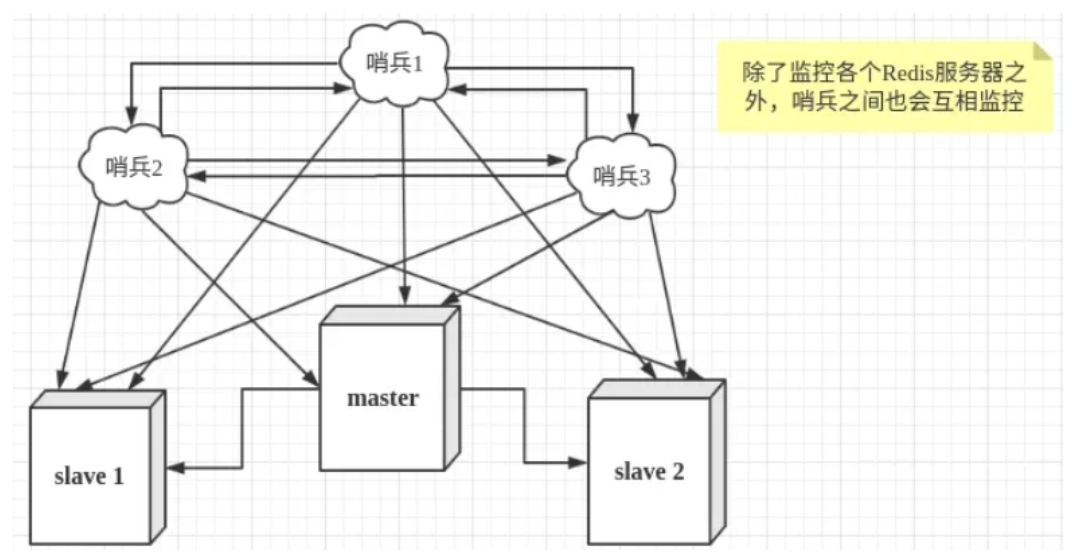
故障切换的过程
假设主服务器宕机,哨兵1先检测到这个结果,系统并不会马上进行 failover 过程,仅仅是哨兵1主观的认为主服务器不可用,这个现象成为主观下线。当后面的哨兵也检测到主服务器不可用,并且数量达到一定值时,那么哨兵之间就会进行一次投票,投票的结果由一个哨兵发起,进行 failover 操作。切换成功后,就会通过发布订阅模式,让各个哨兵把自己监控的从服务器实现切换主机,这个过程称为客观下线。这样对于客户端而言,一切都是透明的。
哨兵模式的工作方式:
- 每个Sentinel(哨兵)进程以每秒钟一次的频率向整个集群中的 Master 主服务器,Slave 从服务器以及其他Sentinel(哨兵)进程发送一个 PING 命令。
- 如果一个实例(instance)距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值, 则这个实例会被 Sentinel(哨兵)进程标记为主观下线(SDOWN)
- 如果一个 Master 主服务器被标记为主观下线(SDOWN),则正在监视这个 Master 主服务器的所有 Sentinel(哨兵)进程要以每秒一次的频率确认 Master 主服务器的确进入了主观下线状态
- 当有足够数量的 Sentinel(哨兵)进程(大于等于配置文件指定的值)在指定的时间范围内确认 Master 主服务器进入了主观下线状态(SDOWN), 则 Master 主服务器会被标记为客观下线(ODOWN)
- 在一般情况下, 每个 Sentinel(哨兵)进程会以每 10 秒一次的频率向集群中的所有 Master 主服务器、Slave 从服务器发送 INFO 命令。
- 当 Master 主服务器被 Sentinel(哨兵)进程标记为客观下线(ODOWN)时,Sentinel(哨兵)进程向下线的 Master 主服务器的所有 Slave 从服务器发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
若没有足够数量的 Sentinel(哨兵)进程同意 Master主服务器下线, Master 主服务器的客观下线状态就会被移除。若 Master 主服务器重新向 Sentinel(哨兵)进程发送 PING 命令返回有效回复,Master主服务器的主观下线状态就会被移除。
哨兵模式的优缺点
优点:
哨兵模式是基于主从模式的,所有主从的优点,哨兵模式都具有。
- 主从可以自动切换,系统更健壮,可用性更高(可以看作自动版的主从复制)。
缺点:
Redis较难支持在线扩容,在集群容量达到上限时在线扩容会变得很复杂。
集群模式(Cluster)—-Redis官方
Redis Cluster是一种服务器 Sharding 技术,3.0版本开始正式提供。
Redis 的哨兵模式基本已经可以实现高可用,读写分离 ,但是在这种模式下每台 Redis 服务器都存储相同的数据,很浪费内存,所以在 redis3.0上加入了 Cluster 集群模式,实现了 Redis 的分布式存储,也就是说每台 Redis 节点上存储不同的内容。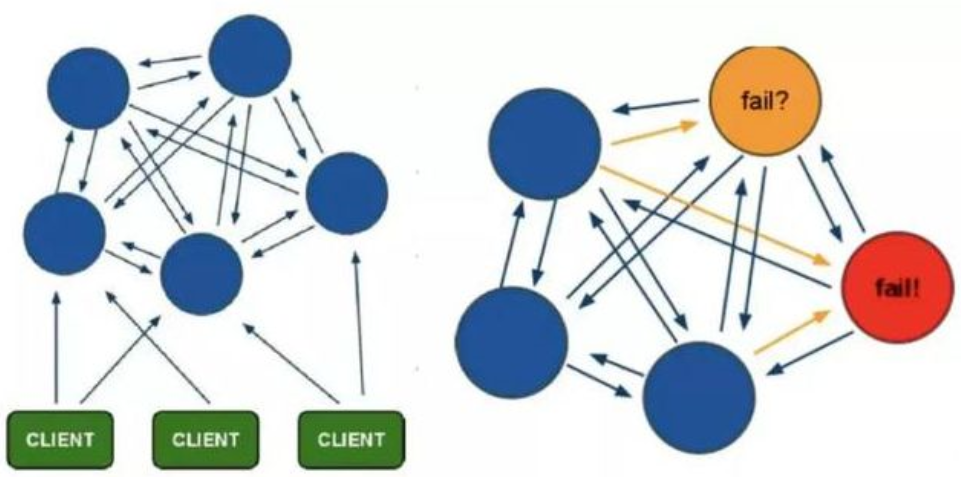
在这个图中,每一个蓝色的圈都代表着一个 redis 的服务器节点。它们任何两个节点之间都是相互连通的。客户端可以与任何一个节点相连接,然后就可以访问集群中的任何一个节点。对其进行存取和其他操作。集群的数据分片
Redis 集群没有使用一致性 hash,而是引入了哈希槽【hash slot】的概念。
Redis 集群有16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽。集群的每个节点负责一部分hash槽,举个例子,比如当前集群有3个节点,那么:节点 A 包含 0 到 5460 号哈希槽
- 节点 B 包含 5461 到 10922 号哈希槽
- 节点 C 包含 10923 到 16383 号哈希槽
这种结构很容易添加或者删除节点。比如如果我想新添加个节点 D , 我需要从节点 A, B, C 中得部分槽到 D 上。如果我想移除节点 A ,需要将 A 中的槽移到 B 和 C 节点上,然后将没有任何槽的 A 节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
在 Redis 的每一个节点上,都有这么两个东西,一个是插槽(slot),它的的取值范围是:0-16383。还有一个就是 cluster,可以理解为是一个集群管理的插件。当我们的存取的 Key到达的时候,Redis 会根据 CRC16 的算法得出一个结果,然后把结果对 16384 求余数,这样每个 key 都会对应一个编号在 0-16383 之间的哈希槽,通过这个值,去找到对应的插槽所对应的节点,然后直接自动跳转到这个对应的节点上进行存取操作。
Redis 集群的主从复制模型
为了保证高可用,redis-cluster集群引入了主从复制模型,一个主节点对应一个或者多个从节点,当主节点宕机的时候,就会启用从节点。当其它主节点 ping 一个主节点 A 时,如果半数以上的主节点与 A 通信超时,那么认为主节点 A 宕机了。如果主节点 A 和它的从节点 A1 都宕机了,那么该集群就无法再提供服务了。
集群的特点
- 所有的 redis 节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
- 节点的 fail 是通过集群中超过半数的节点检测失效时才生效。
- 客户端与 Redis 节点直连,不需要中间代理层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
Docker-redis集群+混合持久化搭建
redis_version:6.0.6 (2020年09月02日14:29:59)安装docker-ce
yum install -y yum-utils device-mapper-persistent-data lvm2yum-config-manager \--add-repo \https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo# 更新yum软件源缓存yum makecache fastyum -y install docker-ce# 开机自启动systemctl enable dockersystemctl start docker
定义安装目录
自定义自定义redis配置文件
```bash官方最新配置文件(6.0.7)搭建3主3从 共6节点
for port in $(seq 7002 7007);do;
mkdir -p node-${port}/{conf,data} touch node-${port}/conf/redis.conf cat << EOF >node-${port}/conf/redis.conf
节点端口
port 6379
允许任何来源
bind 0.0.0.0
是为了禁止公网访问redis cache,加强redis安全的。它启用的条件,有两个:1) 没有bind IP 2) 没有设置访问密码 启用后只能够通过lookback ip(127.0.0.1)访问Redis cache,如果从外网访问,则会返回相应的错误信息
protected-mode no
cluster集群模式
cluster-enabled yes
用来保存集群状态信息,可以自定义配置名。
cluster-config-file nodes.conf
如果要最大的可用性,值设置为0。定义slave和master失联时长的倍数,如果值为0,则只要失联slave总是尝试failover,而不管与master失联多久。——-如果不加该参数,集群中的节点宕机后不会进行高可用恢复!!!!!
cluster-replica-validity-factor 0
定义slave多久(秒)ping一次master,如果超过repl-timeout指定的时长都没有收到响应,则认为master挂了
repl-ping-replica-period 1
超时时间
cluster-node-timeout 5000
节点映射端口
cluster-announce-port 6379
节点总线端口
cluster-announce-bus-port 16379
实际为各节点网卡分配ip
cluster-announce-ip 192.168.XX.XX
redis密码
requirepass China
表示m秒内数据集存在n次修改时,自动触发bgsave
手动执行save该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。
显然该命令对于内存比较大的实例会造成长时间阻塞,这是致命的缺陷,为了解决此问题,Redis提供了第二种方式——bgsave
执行bgsave命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。
基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
执行执行 flushall 命令,也会产生dump.rdb文件,但里面是空的.
关闭RDB功能的话,配置这个即可以,其他save要注释掉
save 300 10
save “”
它是数据文件。当采用快照模式备份(持久化)时,Redis 将使用它保存数据,将来可以使用它恢复数据。
dbfilename dump.rdb
持久化模式
appendonly yes
appendfilename appendonly.aof
aof-use-rdb-preamble yes
文件达到64m时进行重写,然后如果文件大小增长了一倍,也会触发重写。
auto-aof-rewrite-min-size 64mb auto-aof-rewrite-percentage 100
AOF 文件和 Redis 命令是同步频率的,假设配置为 always,其含义为当 Redis 执行命令的时候,则同时同步到 AOF 文件,这样会使得 Redis 同步刷新 AOF 文件,造成缓慢。而采用 evarysec 则代表
每秒同步一次命令到 AOF 文件。
appendfsync everysec
pidfile redis.pid
后台运行 —— docker中使用后台运行将无法启动容器(应该是容器无法检测后台运行进程)
daemonize yes
EOF
修改第一个匹配到的port 6379 为 port $port
sed -i “0,/port 6379/s//port $port/“ node-${port}/conf/redis.conf sed -i “0,/announce-port 6379/s//announce-port $port/“ node-${port}/conf/redis.conf sed -i “0,/bus-port 16379/s//bus-port 1$port/“ node-${port}/conf/redis.conf done
<a name="7s6Q0"></a>
## 安装docker-redis
镜像版本版本可以自己修改
```bash
# 创建用于redis集群的虚拟网卡(也可以自定义子网)
docker network create -d macvlan --subnet=192.168.2.1/24 --gateway=192.168.2.1 -o parent=eth0 mynet
docker network create redis-net
# 查看网关IP1
docker network inspect redis-net | grep "Gateway" | grep --color=auto -P '(\d{1,3}.){3}\d{1,3}' -o
# 查看网关IP2
docker network inspect redis-net | grep "Gateway"
# 运行节点容器
for port in `seq 7002 7007`; do
docker run -it -p ${port}:${port} \
--restart always \
--name=redis-${port} \
--net redis-net \
--privileged=true \
-v `pwd`/node-${port}/conf/redis.conf:/usr/local/etc/redis/redis.conf \
-v `pwd`/node-${port}/data:/data \
-d redis:latest redis-server /usr/local/etc/redis/redis.conf;
done
# 查看redis运行情况
docker ps -a |grep redis
建立Redis集群
查看各个redisIP
docker network inspect redis-net | grep -E "IPv4Address|Name"返回结果
"Name": "redis-net", "Name": "redis-6385", "IPv4Address": "172.18.0.7/16", "Name": "redis-6382", "IPv4Address": "172.18.0.4/16", "Name": "redis-6380", "IPv4Address": "172.18.0.2/16", "Name": "redis-6383", "IPv4Address": "172.18.0.5/16", "Name": "redis-6381", "IPv4Address": "172.18.0.3/16", "Name": "redis-6384", "IPv4Address": "172.18.0.6/16",进入redis-7007节点创建集群,返回提示信息后,输入yes
# 进入docker redis-7007 docker exec -it $(docker ps -qn 1) bash # 创建集群 redis-cli -p 7007 --cluster create 172.18.0.2:7002 172.18.0.3:7003 172.18.0.4:7004 172.18.0.5:7005 172.18.0.6:7006 172.18.0.7:7007 -a China --cluster-replicas 1查看集群
查看集群状态
redis-cli -c -p 7007 -a China cluster info返回结果
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:2 cluster_stats_messages_ping_sent:566 cluster_stats_messages_pong_sent:568 cluster_stats_messages_meet_sent:1 cluster_stats_messages_sent:1135 cluster_stats_messages_ping_received:568 cluster_stats_messages_pong_received:567 cluster_stats_messages_received:1135查看集群各个节点信息
redis-cli -c -p 7007 -a China cluster nodes返回结果
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. 76b5c213dfcb8112c4270db8deadd9faced1189f 172.18.0.7:6379@16379 myself,slave e3092bff97ffea51806dafc7031450ffb1195129 0 1598411316000 2 connected a35caec7a5e3fe8631f006752565063ea9354785 172.18.0.4:6379@16379 master - 0 1598411317000 3 connected 10923-16383 89c88b527dec0e531c83dbd095bac00d88d33c39 172.18.0.6:6379@16379 slave 1e40c530cc4d1b4cc52cbfc9ed9efe52ef28fb72 0 1598411316072 1 connected e3092bff97ffea51806dafc7031450ffb1195129 172.18.0.3:6379@16379 master - 0 1598411317000 2 connected 5461-10922 7438a2db04ec7a97094c2b8a4542d7c68b847008 172.18.0.5:6379@16379 slave a35caec7a5e3fe8631f006752565063ea9354785 0 1598411317584 3 connected 1e40c530cc4d1b4cc52cbfc9ed9efe52ef28fb72 172.18.0.2:6379@16379 master - 0 1598411316000 1 connected 0-5460Dokcer-redis集群新增节点
自定义redis配置文件
配置2个新的redis配置文件
for port in $(seq 7008 7009);do; mkdir -p node-${port}/{conf,data} touch node-${port}/conf/redis.conf cat << EOF >node-${port}/conf/redis.conf ##节点端口 port 6379 ##允许任何来源 bind 0.0.0.0 ## 是为了禁止公网访问redis cache,加强redis安全的。它启用的条件,有两个:1) 没有bind IP 2) 没有设置访问密码 启用后只能够通过lookback ip(127.0.0.1)访问Redis cache,如果从外网访问,则会返回相应的错误信息 protected-mode no ##cluster集群模式 cluster-enabled yes ##用来保存集群状态信息,可以自定义配置名。 cluster-config-file nodes.conf ## 如果要最大的可用性,值设置为0。定义slave和master失联时长的倍数,如果值为0,则只要失联slave总是尝试failover,而不管与master失联多久。-----如果不加该参数,集群中的节点宕机后不会进行高可用恢复!!!!! cluster-replica-validity-factor 0 # 定义slave多久(秒)ping一次master,如果超过repl-timeout指定的时长都没有收到响应,则认为master挂了 repl-ping-replica-period 1 ##超时时间 cluster-node-timeout 5000 ##节点映射端口 cluster-announce-port 6379 ##节点总线端口 cluster-announce-bus-port 16379 ##实际为各节点网卡分配ip #cluster-announce-ip 192.168.XX.XX ##redis密码 requirepass China ##表示m秒内数据集存在n次修改时,自动触发bgsave ## 手动执行save该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。 ## 显然该命令对于内存比较大的实例会造成长时间阻塞,这是致命的缺陷,为了解决此问题,Redis提供了第二种方式----bgsave ## 执行bgsave命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。 ## 基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。 ## 执行执行 flushall 命令,也会产生dump.rdb文件,但里面是空的. #关闭RDB功能的话,配置这个即可以,其他save要注释掉 #save 300 10 save "" ##它是数据文件。当采用快照模式备份(持久化)时,Redis 将使用它保存数据,将来可以使用它恢复数据。 #dbfilename dump.rdb ##持久化模式 appendonly yes #appendfilename appendonly.aof aof-use-rdb-preamble yes # 文件达到64m时进行重写,然后如果文件大小增长了一倍,也会触发重写。 auto-aof-rewrite-min-size 64mb auto-aof-rewrite-percentage 100 ##AOF 文件和 Redis 命令是同步频率的,假设配置为 always,其含义为当 Redis 执行命令的时候,则同时同步到 AOF 文件,这样会使得 Redis 同步刷新 AOF 文件,造成缓慢。而采用 evarysec 则代表 每秒同步一次命令到 AOF 文件。 appendfsync everysec pidfile redis.pid # 后台运行 ---- docker中使用后台运行将无法启动容器(应该是容器无法检测后台运行进程) # daemonize yes EOF # 修改第一个匹配到的port 6379 为 port $port sed -i "0,/port 6379/s//port $port/" node-${port}/conf/redis.conf sed -i "0,/announce-port 6379/s//announce-port $port/" node-${port}/conf/redis.conf sed -i "0,/bus-port 16379/s//bus-port 1$port/" node-${port}/conf/redis.conf done运行新增节点容器
# 运行节点容器 for port in `seq 7008 7009`; do docker run -it -p ${port}:${port} \ --restart always \ --name=redis-${port} \ --net redis-net \ --privileged=true \ -v `pwd`/node-${port}/conf/redis.conf:/usr/local/etc/redis/redis.conf \ -v `pwd`/node-${port}/data:/data \ -d redis:latest redis-server /usr/local/etc/redis/redis.conf; done登陆redis7007 新增节点
新增主节点
# 登陆redis7007 docker exec -it redis-7007 bash # 新增主节点 # 说明:为一个指定集群添加节点,需要先连到该集群的任意一个节点IP(172.18.0.7:7007),再把新节点加入。该2个参数的顺序有要求:新加入的节点放前 redis-cli -c -a China --cluster add-node 172.18.0.8:7008 172.18.0.7:7007提示添加成功
root@c9f5ce54a903:/data# redis-cli -c -p 7007 -a China --cluster add-node 172.18.0.8:7008 172.18.0.7:7007 Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe. >>> Adding node 172.18.0.9:7009 to cluster 172.18.0.7:7007 >>> Performing Cluster Check (using node 172.18.0.7:7007) S: a1dc21e356f983ce8f6af9ffd63e5819f6168f34 172.18.0.7:7007 slots: (0 slots) slave replicates 4a6116ea0bd3e13e603fc93a96e639b1b257e873 M: 4a6116ea0bd3e13e603fc93a96e639b1b257e873 172.18.0.3:7003 slots:[5461-10922] (5462 slots) master 1 additional replica(s) M: 9d257e1f3be993ab6cc418bee526ad8833e1b371 172.18.0.4:7004 slots:[10923-16383] (5461 slots) master 1 additional replica(s) M: 5ae566444b78ebc3d077c4fb7f17578b9725045f 172.18.0.2:7002 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 16a5ada35a648750daabdb91afa54ba6c62a26c4 172.18.0.8:7008 slots: (0 slots) master S: 149b52decbb11b3fbf4199e97da5058bfae4af15 172.18.0.5:7005 slots: (0 slots) slave replicates 9d257e1f3be993ab6cc418bee526ad8833e1b371 S: aa7977e699159e0042a2cec003e4e163ed8c6af2 172.18.0.6:7006 slots: (0 slots) slave replicates 5ae566444b78ebc3d077c4fb7f17578b9725045f [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered. >>> Send CLUSTER MEET to node 172.18.0.9:7009 to make it join the cluster. [OK] New node added correctly.新增从节点
# 新增从节点 # 16a5ada35a648750daabdb91afa54ba6c62a26c4 是主节点的 Node-ID 如果不指定 --cluster-master-id 会随机分配到任意一个主节点。 redis-cli -c -a China --cluster add-node 172.18.0.9:7009 172.18.0.7:7007 --cluster-slave --cluster-master-id 16a5ada35a648750daabdb91afa54ba6c62a26c4提示添加成功 ```bash root@c9f5ce54a903:/data# redis-cli -c -a China —cluster add-node 172.18.0.9:7009 172.18.0.7:7007 —cluster-slave —cluster-master-id 16a5ada35a648750daabdb91afa54ba6c62a26c4 Warning: Using a password with ‘-a’ or ‘-u’ option on the command line interface may not be safe.
Adding node 172.18.0.9:7009 to cluster 172.18.0.7:7007 Performing Cluster Check (using node 172.18.0.7:7007) S: a1dc21e356f983ce8f6af9ffd63e5819f6168f34 172.18.0.7:7007 slots: (0 slots) slave replicates 4a6116ea0bd3e13e603fc93a96e639b1b257e873 M: 4a6116ea0bd3e13e603fc93a96e639b1b257e873 172.18.0.3:7003 slots:[5461-10922] (5462 slots) master 1 additional replica(s) M: 9d257e1f3be993ab6cc418bee526ad8833e1b371 172.18.0.4:7004 slots:[10923-16383] (5461 slots) master 1 additional replica(s) M: 5ae566444b78ebc3d077c4fb7f17578b9725045f 172.18.0.2:7002 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 16a5ada35a648750daabdb91afa54ba6c62a26c4 172.18.0.8:7008 slots: (0 slots) master S: 149b52decbb11b3fbf4199e97da5058bfae4af15 172.18.0.5:7005 slots: (0 slots) slave replicates 9d257e1f3be993ab6cc418bee526ad8833e1b371 S: aa7977e699159e0042a2cec003e4e163ed8c6af2 172.18.0.6:7006 slots: (0 slots) slave replicates 5ae566444b78ebc3d077c4fb7f17578b9725045f [OK] All nodes agree about slots configuration. Check for open slots… Check slots coverage… [OK] All 16384 slots covered. Send CLUSTER MEET to node 172.18.0.9:7009 to make it join the cluster. Waiting for the cluster to join
Configure node as replica of 172.18.0.8:7008. [OK] New node added correctly.
<a name="SVp7s"></a> ### 重新分配哈希槽 ip:port 为任意一个节点 ```bash redis-cli --cluster reshard 172.18.0.7:7007 -a China输入需要迁移的槽点数
复制粘贴需要被接收的主节点 ```bash root@c9f5ce54a903:/data# redis-cli -c -a China —cluster reshard 172.18.0.4:7004 Warning: Using a password with ‘-a’ or ‘-u’ option on the command line interface may not be safe. Performing Cluster Check (using node 172.18.0.4:7004) M: 9d257e1f3be993ab6cc418bee526ad8833e1b371 172.18.0.4:7004 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 28cfd99f6a93f49cbb8d9eff8ed6bc77d201d494 172.18.0.9:7009 slots: (0 slots) slave replicates 16a5ada35a648750daabdb91afa54ba6c62a26c4 M: 16a5ada35a648750daabdb91afa54ba6c62a26c4 172.18.0.8:7008 slots: (0 slots) master 1 additional replica(s) M: 4a6116ea0bd3e13e603fc93a96e639b1b257e873 172.18.0.3:7003 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: aa7977e699159e0042a2cec003e4e163ed8c6af2 172.18.0.6:7006 slots: (0 slots) slave replicates 5ae566444b78ebc3d077c4fb7f17578b9725045f S: a1dc21e356f983ce8f6af9ffd63e5819f6168f34 172.18.0.7:7007 slots: (0 slots) slave replicates 4a6116ea0bd3e13e603fc93a96e639b1b257e873 M: 5ae566444b78ebc3d077c4fb7f17578b9725045f 172.18.0.2:7002 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: 149b52decbb11b3fbf4199e97da5058bfae4af15 172.18.0.5:7005 slots: (0 slots) slave replicates 9d257e1f3be993ab6cc418bee526ad8833e1b371 [OK] All nodes agree about slots configuration. Check for open slots… Check slots coverage… [OK] All 16384 slots covered. How many slots do you want to move (from 1 to 16384)? 1000 What is the receiving node ID? 16a5ada35a648750daabdb91afa54ba6c62a26c4 Please enter all the source node IDs. Type ‘all’ to use all the nodes as source nodes for the hash slots. Type ‘done’ once you entered all the source nodes IDs. Source node #1: all
Ready to move 1000 slots. Source nodes: M: 9d257e1f3be993ab6cc418bee526ad8833e1b371 172.18.0.4:7004 slots:[10923-16383] (5461 slots) master 1 additional replica(s) M: 4a6116ea0bd3e13e603fc93a96e639b1b257e873 172.18.0.3:7003 slots:[5461-10922] (5462 slots) master 1 additional replica(s) M: 5ae566444b78ebc3d077c4fb7f17578b9725045f 172.18.0.2:7002 slots:[0-5460] (5461 slots) master 1 additional replica(s) Destination node: M: 16a5ada35a648750daabdb91afa54ba6c62a26c4 172.18.0.8:7008 slots: (0 slots) master 1 additional replica(s) Resharding plan:
<a name="c61f12c4"></a>
### 测试set get 是否正常
<a name="a595e63a"></a>
# Dokcer-redis集群删除节点
```bash
# 说明:指定集群中任意节点IP、端口 和node_id 来删除一个节点,从节点可以直接删除,主节点不能直接删除,删除之后,该节点会被shutdown。
# f6a6957421b80409106cb36be3c7ba41f3b603ff 是Node-ID
redis-cli --cluster del-node ip:port f6a6957421b80409106cb36be3c7ba41f3b603ff
Redis持久化
RDB介绍
RDB是Redis用来进行持久化的一种方式,是把当前内存中的数据集快照写入磁盘,也就是 Snapshot 快照(数据库中所有键值对数据)。恢复时是将快照文件直接读到内存里。
数据恢复
将备份文件 (dump.rdb) 移动到 redis 安装目录并启动服务即可,redis就会自动加载文件数据至内存了。Redis 服务器在载入 RDB 文件期间,会一直处于阻塞状态,直到载入工作完成为止。<br /> 获取 redis 的安装目录可以使用 config get dir 命令
停止RDB持久化
有些情况下,我们只想利用Redis的**缓存功能**,并不像使用 Redis 的持久化功能(保存到硬盘),那么这时候我们最好停掉 RDB 持久化。可以通过上面讲的在配置文件 redis.conf 中,可以注释掉所有的 save 行来停用保存功能或者直接一个空字符串来实现停用:save ""<br /> 也可以通过命令:
redis-cli config set save ``" "
RDB优势和劣势
优势
1.RDB是一个非常紧凑(compact)的文件,它保存了redis 在某个时间点上的数据集。这种文件非常适合用于进行备份和灾难恢复。
2.生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
3.RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
劣势
1、RDB方式数据没办法做到实时持久化/秒级持久化。因为bgsave每次运行都要执行fork操作创建子进程,属于重量级操作,如果不采用压缩算法(内存中的数据被克隆了一份,大致2倍的膨胀性需要考虑),频繁执行成本过高(影响性能)
2、RDB文件使用特定二进制格式保存,Redis版本演进过程中有多个格式的RDB版本,存在老版本Redis服务无法兼容新版RDB格式的问题(版本不兼容)
3、在一定间隔时间做一次备份,所以如果redis意外down掉的话,就会丢失最后一次快照后的所有修改(数据有丢失)
AOF介绍
Redis的持久化方式之一RDB是通过保存数据库中的键值对来记录数据库的状态。而另一种持久化方式 AOF 则是通过保存Redis服务器所执行的写命令来记录数据库状态。<br /> RDB 持久化方式就是将 str1,str2,str3 这三个键值对保存到 RDB文件中,而 AOF 持久化则是将执行的 set,sadd,lpush 三个命令保存到 AOF 文件中。<br /> ①、**appendonly**:默认值为no,也就是说redis 默认使用的是rdb方式持久化,如果想要开启 AOF 持久化方式,需要将 appendonly 修改为 yes。<br /> ②、**appendfilename** :aof文件名,默认是"appendonly.aof"<br /> ③、**appendfsync:**aof持久化策略的配置;<br /> no表示不执行fsync,由操作系统保证数据同步到磁盘,速度最快,但是不太安全;<br /> always表示每次写入都执行fsync,以保证数据同步到磁盘,效率很低;<br /> everysec表示每秒执行一次fsync,可能会导致丢失这1s数据。通常选择 everysec ,兼顾安全性和效率。<br /> ④、no-appendfsync-on-rewrite:在aof重写或者写入rdb文件的时候,会执行大量IO,此时对于everysec和always的aof模式来说,执行fsync会造成阻塞过长时间,no-appendfsync-on-rewrite字段设置为默认设置为no。如果对延迟要求很高的应用,这个字段可以设置为yes,否则还是设置为no,这样对持久化特性来说这是更安全的选择。 设置为yes表示rewrite期间对新写操作不fsync,暂时存在内存中,等rewrite完成后再写入,建议yes。Linux的默认fsync策略是30秒。可能丢失30秒数据。默认值为no。<br /> ⑤、auto-aof-rewrite-percentage:默认值为100。aof自动重写配置,当目前aof文件大小超过上一次重写的aof文件大小的百分之多少进行重写,即当aof文件增长到一定大小的时候,Redis能够调用bgrewriteaof对日志文件进行重写。当前AOF文件大小是上次日志重写得到AOF文件大小的二倍(设置为100)时,自动启动新的日志重写过程。<br /> ⑥、auto-aof-rewrite-min-size:64mb。设置允许重写的最小aof文件大小,避免了达到约定百分比但尺寸仍然很小的情况还要重写。<br /> ⑦、aof-load-truncated:aof文件可能在尾部是不完整的,当redis启动的时候,aof文件的数据被载入内存。重启可能发生在redis所在的主机操作系统宕机后,尤其在ext4文件系统没有加上data=ordered选项,出现这种现象 redis宕机或者异常终止不会造成尾部不完整现象,可以选择让redis退出,或者导入尽可能多的数据。如果选择的是yes,当截断的aof文件被导入的时候,会自动发布一个log给客户端然后load。如果是no,用户必须手动redis-check-aof修复AOF文件才可以。默认值为 yes。
AOF数据恢复
重启 Redis 之后就会进行 AOF 文件的载入。<br /> 异常修复命令:redis-check-aof --fix 进行修复
AOF重写
由于AOF持久化是Redis不断将写命令记录到 AOF 文件中,随着Redis不断的进行,AOF 的文件会越来越大,文件越大,占用服务器内存越大以及 AOF 恢复要求时间越长。为了解决这个问题,Redis新增了重写机制,当AOF文件的大小超过所设定的阈值时,Redis就会启动AOF文件的内容压缩,只保留可以恢复数据的最小指令集。可以使用命令 bgrewriteaof 来重新。 <br /> 如果不进行 AOF 文件重写,那么 AOF 文件将保存四条 SADD 命令,如果使用AOF 重写,那么AOF 文件中将只会保留下面一条命令:
sadd animals ``"dog"` `"tiger"` `"panda"` `"lion"` `"cat"
也就是说 AOF 文件重写并不是对原文件进行重新整理,而是直接读取服务器现有的键值对,然后用一条命令去代替之前记录这个键值对的多条命令,生成一个新的文件后去替换原来的 AOF 文件。
AOF 文件重写触发机制:通过 redis.conf 配置文件中的 auto-aof-rewrite-percentage:默认值为100,以及auto-aof-rewrite-min-size:64mb 配置,也就是说默认Redis会记录上次重写时的AOF大小,默认配置是当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发。
这里再提一下,我们知道 Redis 是单线程工作,如果 重写 AOF 需要比较长的时间,那么在重写 AOF 期间,Redis将长时间无法处理其他的命令,这显然是不能忍受的。Redis为了克服这个问题,解决办法是将 AOF 重写程序放到子程序中进行,这样有两个好处:
①、子进程进行 AOF 重写期间,服务器进程(父进程)可以继续处理其他命令。
②、子进程带有父进程的数据副本,使用子进程而不是线程,可以在避免使用锁的情况下,保证数据的安全性。
使用子进程解决了上面的问题,但是新问题也产生了:因为子进程在进行 AOF 重写期间,服务器进程依然在处理其它命令,这新的命令有可能也对数据库进行了修改操作,使得当前数据库状态和重写后的 AOF 文件状态不一致。
为了解决这个数据状态不一致的问题,Redis 服务器设置了一个 AOF 重写缓冲区,这个缓冲区是在创建子进程后开始使用,当Redis服务器执行一个写命令之后,就会将这个写命令也发送到 AOF 重写缓冲区。当子进程完成 AOF 重写之后,就会给父进程发送一个信号,父进程接收此信号后,就会调用函数将 AOF 重写缓冲区的内容都写到新的 AOF 文件中。
这样将 AOF 重写对服务器造成的影响降到了最低。
AOF优缺点
优点:
①、AOF 持久化的方法提供了多种的同步频率,即使使用默认的同步频率每秒同步一次,Redis 最多也就丢失 1 秒的数据而已。
②、AOF 文件使用 Redis 命令追加的形式来构造,因此,即使 Redis 只能向 AOF 文件写入命令的片断,使用 redis-check-aof 工具也很容易修正 AOF 文件。
③、AOF 文件的格式可读性较强,这也为使用者提供了更灵活的处理方式。例如,如果我们不小心错用了 FLUSHALL 命令,在重写还没进行时,我们可以手工将最后的 FLUSHALL 命令去掉,然后再使用 AOF 来恢复数据。
缺点:
①、对于具有相同数据的的 Redis,AOF 文件通常会比 RDB 文件体积更大。
②、虽然 AOF 提供了多种同步的频率,默认情况下,每秒同步一次的频率也具有较高的性能。但在 Redis 的负载较高时,RDB 比 AOF 具好更好的性能保证。
③、RDB 使用快照的形式来持久化整个 Redis 数据,而 AOF 只是将每次执行的命令追加到 AOF 文件中,因此从理论上说,RDB 比 AOF 方式更健壮。官方文档也指出,AOF 的确也存在一些 BUG,这些 BUG 在 RDB 没有存在。
那么对于 AOF 和 RDB 两种持久化方式,我们应该如何选择呢?
如果可以忍受一小段时间内数据的丢失,毫无疑问使用 RDB 是最好的,定时生成 RDB 快照(snapshot)非常便于进行数据库备份, 并且 RDB 恢复数据集的速度也要比 AOF 恢复的速度要快,而且使用 RDB 还可以避免 AOF 一些隐藏的 bug;否则就使用 AOF 重写。但是一般情况下建议不要单独使用某一种持久化机制,而是应该两种一起用,在这种情况下,当redis重启的时候会优先载入AOF文件来恢复原始的数据,因为在通常情况下AOF文件保存的数据集要比RDB文件保存的数据集要完整。Redis后期官方可能都有将两种持久化方式整合为一种持久化模型。
RDB-AOF混合持久化
混合持久化是Redis 4.X之后的一个新特性,说是新特性其实更像是一种RDB&AOF的结合,持久化文件变成了RDB + AOF,首先由RDB定期完成内存快照的备份,然后再由AOF完成两次RDB之间的数据备份。这样就充分了利用了RDB 加载快,备份文件小等特点,也利用了AOF能尽可能不丢数据这个特性(进一步保证了数据一致性),当然了基本上丢失了AOF的可读性。加载过程就是按部分进行加载的,先按照RDB进行加载,然后把AOF命令追加写入就好了。在大多数场景下RDB + AOF的混合持久化模式其实还是很合适的.
这里补充一个知识点,在Redis4.0之后,之前有介绍的RDB和AOF两种持久化方式,又新增了RDB-AOF混合持久化方式。
这种方式结合了RDB和AOF的优点,既能快速加载又能避免丢失过多的数据。
具体配置为:
#1,关闭RDB,参考上面的配置
#2,开启AOF,参考上面的配置
aof-use-rdb-preamble yes
设置为yes表示开启,设置为no表示禁用。
当开启混合持久化时,主进程先fork出子进程将现有内存副本全量以RDB方式写入aof文件中,然后将缓冲区中的增量命令以AOF方式写入aof文件中,写入完成后通知主进程更新相关信息,并将新的含有 RDB和AOF两种格式的aof文件替换旧的aof文件。
混合持久化优缺点
优点
混合持久化结合了RDB持久化 和 AOF 持久化的优点, 由于绝大部分都是RDB格式,加载速度快,同时结合AOF,增量的数据以AOF方式保存了,数据更少的丢失。简单来说:混合持久化方式产生的文件一部分是RDB格式,一部分是AOF格式。
缺点
兼容性差,一旦开启了混合持久化,在4.0之前版本都不识别该aof文件,同时由于前部分是RDB格式,阅读性较差
RDB和AOF,应该用哪一个?
循环插入数据测试脚本参考
for a in $(seq 1 10000);do redis-cli -p 7008 -a China set a$a $a;done
问题记录
集群中执行get/set报错
(error) MOVED 5798 172.0.0.X:XXXX
解决方案
Redis-cli启动/访问/请求时候增加-c 参数启动集群模式
高可用测试报错
进行高可用测试的时候,关闭任意一个主节点,在集群中执行get set命令报错(error) CLUSTERDOWN The cluster is down 并且从节点没有被选举成主节点。
解决方案
配置文件中新增参数
##如果要最大的可用性,值设置为0。定义slave和master失联时长的倍数,如果值为0,则只要失联slave总是尝试failover,而不管与master失联多久。-----如果不加该参数,集群中的节点宕机后不会进行高可用恢复!!!!!
cluster-slave-validity-factor 0
该参数在5.0之后为
cluster-replica-validity-factor 0
新增节点失败
查看cluster nodes时候发现报错 handshake - 0 0 0 disconnected
解决方案
因新增节点映射端口和总线端口与集群中的端口冲突,需要修改端口号
##节点映射端口
cluster-announce-port 6379
##节点总线端口
cluster-announce-bus-port 16379
内存以及策略配置
如需要自定义配置
解决方案
#最大内存,注释或设置0表示为物理机器最大可用内存,具体配置示情况而定* maxmemory 2g
# 本文中采用默认配置
#内存淘汰策略,Redis使用内存超过最大内存时的处理机制(是否清除部分内存),默认是noeviction,不会清除内存,超过时会报错
maxmemory-policy volatile-lru
局域网下其他主机无法使用集群
配置情况
主机A 与主机B 在同一个局域网下
容器redis集群在主机A 172.18.0.1/24 网段中
问题现象
该部署方式可以让局域网中其他主机连接docker-redis集群中的单节点成功
能正常连接是因为 主机B 通过 主机A 在启动容器的时候创建的防火墙规则。
DNAT tcp -- 0.0.0.0/0 0.0.0.0/0 tcp dpt:7002 to:172.18.0.2:7002
也就是通过局域网其他 主机B 尝试执行redis-cli -c ip:port -a auth可以正常连接
实际上该 主机B 与 主机A 的容器172.18.0.1/24网络环境是隔离的,所以get / set 跳跃到其他节点的时候 ,报错连接超时。
redis-cli -c -h 192.168.2.200 -p 7002 -a China
Warning: Using a password with '-a' or '-u' option on the command line interface may not be safe.
192.168.2.200:7002> get a
-> Redirected to slot [15495] located at 172.18.0.4:7004
Could not connect to Redis at 172.18.0.4:7004: Connection timed out
Could not connect to Redis at 172.18.0.4:7004: Connection timed out
(254.52s)
not connected>
解决方案
理论上打通主机B到主机A上的容器172.18.0.1/24网络即可。但不知道是否会影响效率
目前还没有落地的解决方案(2020年09月08日16:23:22)

若有收获,就点个赞吧
0 人点赞
