声明:博主写了一些Ambari自定义服务系列文章,可以在历史文章中查看。
仔细看,肯定会对ambari的自定义服务有一个更清晰的认识。
版本:ambari 2.6.1
一、实时更改服务配置
# 以hue的配置文件hue.ini为例File(format("/usr/hdp/2.6.4.0-91/hue/desktop/conf/hue.ini"),content=Template("hue.ini.j2"),owner=params.hue_user,group=params.hue_group)# 解读:# 1. File的第一个变量为:实际服务的配置文件的所在地# 2. File的第二个变量为:在服务的./package/目录下新建templates文件夹,该文件夹下放入hue.ini.j2文件,与配置文件hue.ini内容一致。# 3. File的第三个变量为:所有者为hue# 4. File的第四个变量为: 所在组为hue

变量以{% raw %}{{}}{% endraw %}括起来,变量定义在param.py文件。
# param.py局部from resource_management.libraries.script.script import Scriptconfig = Script.get_config()http_host = config['hostname']http_port = config['configurations']['hue-env']['http_port']# 其中的'configurations'是代表着ambari集群已安装组件的所有xml配置文件# 'hue-env'对应着 configuration/hue-env.xml
hue-env.xml文件
目录:configuration/hue-env.xml
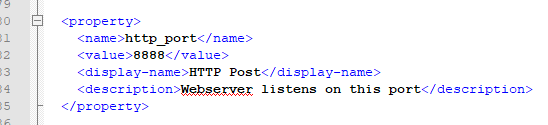
这样的话,当在ambari界面上的hue服务那修改配置,后台根据config命令来读取前端修改的值,然后赋值于hue.ini.j2,hue.ini.j2又与hue.ini相关联。这样,hue的配置文件就会被实时更改,然后在ambari界面上根据提示重启hue服务,配置即可生效。
二、py脚本内创建/删除文件夹、文件
2.1 创建文件夹、文件
def start(self, env):import paramsenv.set_params(params)Directory([params.hue_pid_dir],mode=0755,cd_access='a',owner=params.hue_user,group=params.hue_group,create_parents=True)File([params.hue_log_file, params.hue_server_pid_file],mode=0644,owner=params.hue_user,group=params.hue_group,content='')# 说明# import导入params.py文件,该文件内有上面用到的‘hue_pid_dir’,‘hue_log_file’,‘hue_server_pid_file’变量的定义# Directory表示执行文件夹操作,[]括起来的是要创建的文件夹名称,mode是权限,owner/group是用户/组,create_parents=True是父目录不存在时一起创建。# create_parents=True 有待验证。# File表示执行文件操作,[]括起来的是要创建的文件名称,mode是权限,owner/group是用户/组,content=''代表内容为空。
2.2 删除文件夹/文件
def stop(self, env):import paramsenv.set_params(params)Directory(params.hue_pid_dir,action="delete",owner=params.hue_user)# 说明# Directory表示执行文件夹操作,第一个参数为执行操作的文件夹名称,action="delete"代表删除,owner代表由哪个用户执行操作。# File同理
2.3 设置密码校验
<property require-input="true"><name>kadmin.local.password</name><display-name>admin password</display-name><value/><property-type>PASSWORD</property-type><description>The password is used to add the kerberos database administrator</description><value-attributes><overridable>false</overridable><type>password</type></value-attributes></property>
效果图:

三、依赖包说明
自定义服务python脚本依赖的模块是resource_management,该模块的位置在/usr/lib/ambari-agent/lib/resource_management,ambari的自定义服务程序环境就是依赖的这个目录。
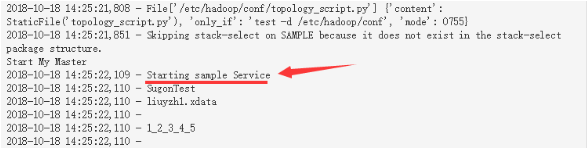
四、调试代码逻辑,如何打印日志
from resource_management.core.logger import LoggerLogger.info("Starting sample Service")
五、如何获取集群内的一些参数值
1. 获取ambari-server所在的主机,即主节点
from resource_management.libraries.script.script import Scriptconfig = Script.get_config()ambari_server_hostname = config['clusterHostInfo']['ambari_server_host'][0]
2. 获取集群名称
cluster_name = str(config['clusterName'])
3. 获取当前主机名称
hostname = config['hostname']
4. 获取已安装服务组件所在主机
clusterHostInfo = config['clusterHostInfo']## 返回的clusterHostInfo是一个数组,我们用”,”将其分割为字符串,来看一下里面是什么clusterHostInfo = ",".join(params.clusterHostInfo)## clusterHostInfo 的值为:snamenode_host,nm_hosts,metrics_collector_hosts,hive_metastore_host,ranger_tagsync_hosts,elasticsearch_service_hosts,ranger_usersync_hosts,slave_hosts,spark_jobhistoryserver_hosts,mymaster_hosts,infra_solr_hosts,hive_server_host,hue_server_hosts,hbase_rs_hosts,webhcat_server_host,ranger_admin_hosts,ambari_server_host,zookeeper_hosts,mysalve_hosts,spark_thriftserver_hosts,app_timeline_server_hosts,livy_server_hosts,all_ping_ports,rm_host,all_hosts,ambari_server_use_ssl,metrics_monitor_hosts,oozie_server,all_racks,all_ipv4_ips,hs_host,metrics_grafana_hosts,phoenix_query_server_hosts,ambari_server_port,namenode_host,hbase_master_hosts## 解析:上述格式为:component_name_hosts## 假如我们需要查看namenode所在的主机,需要怎么做呢?namenode = config['clusterHostInfo']['nm_hosts']## 或者namenode = default("/clusterHostInfo/nm_hosts", [“localhost”])## 上面这行代码的意思是,如果nm_hosts不存在,则以localhost代替。可见,default这种方法比config的那种方法要更全面。## 注意:以上namenode是一个数组,所以我们需要再做进一步处理,这里就不再进行demo演示了
5. 获取ambari系统内其它已安装服务的xml属性值
configurations = config['configurations']configurations = ",".join(configurations)## configurations 的值为:spark-defaults,livy-log4j-properties,ranger-hdfs-audit,webhcat-log4j,ranger-yarn-plugin-properties,ranger-hdfs-policymgr-ssl,pig-env,hue-hive-site,hdfs-logsearch-conf,slider-env,ranger-hive-policymgr-ssl,hivemetastore-site,llap-cli-log4j2,spark-hive-site-override,ranger-hive-security,spark-log4j-properties,ams-logsearch-conf,ams-hbase-security-site,oozie-env,mapred-site,hue-mysql-site,spark-env,hdfs-site,hue-hadoop-site,ams-env,ams-site,ams-hbase-policy,zookeeper-log4j,hadoop-metrics2.properties,hue-env,hdfs-log4j,hbase-site,ranger-hbase-plugin-properties,ams-log4j,ranger-yarn-audit,hive-interactive-env,ranger-hdfs-plugin-properties,hue-pig-site,pig-properties,oozie-log4j,hawq-limits-env,oozie-logsearch-conf,ams-hbase-site,hive-env,ams-hbase-log4j,hadoop-env,hue-solr-site,hive-logsearch-conf,tez-interactive-site,yarn-site,parquet-logging,hive-exec-log4j,webhcat-site,sqoop-site,hawq-sysctl-env,hive-log4j,ranger-hdfs-security,hiveserver2-site,sqoop-atlas-application.properties,mapred-env,ranger-hive-audit,ranger-hbase-security,slider-client,ssl-client,sqoop-env,livy-conf,ams-grafana-env,ranger-yarn-policymgr-ssl,ranger-hbase-audit,livy-env,hive-log4j2,hive-site,spark-logsearch-conf,spark-javaopts-properties,ams-ssl-client,yarn-client,hbase-policy,webhcat-env,hive-atlas-application.properties,hue-ugsync-site,hcat-env,tez-site,slider-log4j,spark-thrift-sparkconf,spark-thrift-fairscheduler,hue-hbase-site,mapred-logsearch-conf,yarn-log4j,hue-oozie-site,ams-grafana-ini,livy-spark-blacklist,hadoop-policy,ranger-hive-plugin-properties,ams-ssl-server,tez-env,hive-interactive-site,hawq-env,ams-hbase-env,core-site,yarn-env,hawq-site,spark-metrics-properties,hbase-logsearch-conf,hue-desktop-site,hdfs-client,yarn-logsearch-conf,zookeeper-logsearch-conf,beeline-log4j2,hiveserver2-interactive-site,ranger-yarn-security,capacity-scheduler,hbase-log4j,oozie-site,ssl-server,llap-daemon-log4j,hbase-env,hawq-check-env,zoo.cfg,ranger-hbase-policymgr-ssl,hue-spark-site,hive-exec-log4j2,zookeeper-env,pig-log4j,cluster-env## 例如,我要获取oozie-site.xml内oozie.base.url的值oozie_url = config['configurations']['oozie-site']['oozie.base.url']
6. 获取当前安装hdp的版本
hdp_version = default("/commandParams/version", None)# 说明:返回结果为2.6.4.0-91,如果没有/commandParams/version的话,结果返回None
7. 一些特殊约定
tmp_dir = Script.get_tmp_dir()# 结果:/var/lib/ambari-agent/tmp
六、config补充
config = Script.get_config()## 打印config,内容如下:agentConfigParams,credentialStoreEnabled,taskId,configurations,clusterName,localComponents,commandType,configuration_attributes,repositoryFile,roleParams,public_hostname,configurationTags,commandId,roleCommand,configuration_credentials,commandParams,componentVersionMap,hostname,hostLevelParams,kerberosCommandParams,serviceName,role,forceRefreshConfigTagsBeforeExecution,stageId,clusterHostInfo,requestId
如果需要看agentConfigParams里面有什么key值,可以参考标题四使用Logger.info打印,比如:
# 如果是数组的话,就以“,”分隔Logger.info(",".join(config['configurations']))# 如果是字符串就直接打印出来Logger.info(config['configurations'])
点关注,不迷路
好了各位,以上就是这篇文章的全部内容了,能看到这里的人呀,都是人才。
白嫖不好,创作不易。各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
如果本篇博客有任何错误,请批评指教,不胜感激 !


若有收获,就点个赞吧
0 人点赞
