一、集群架构
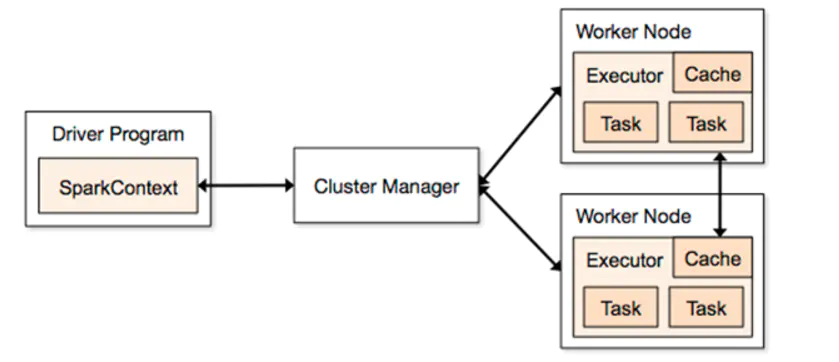
部署系统是第一件事,那么系统部署成功以后,各个节点都启动了哪些服务?服务之间的关联是什么,服务之间的配合是怎样的?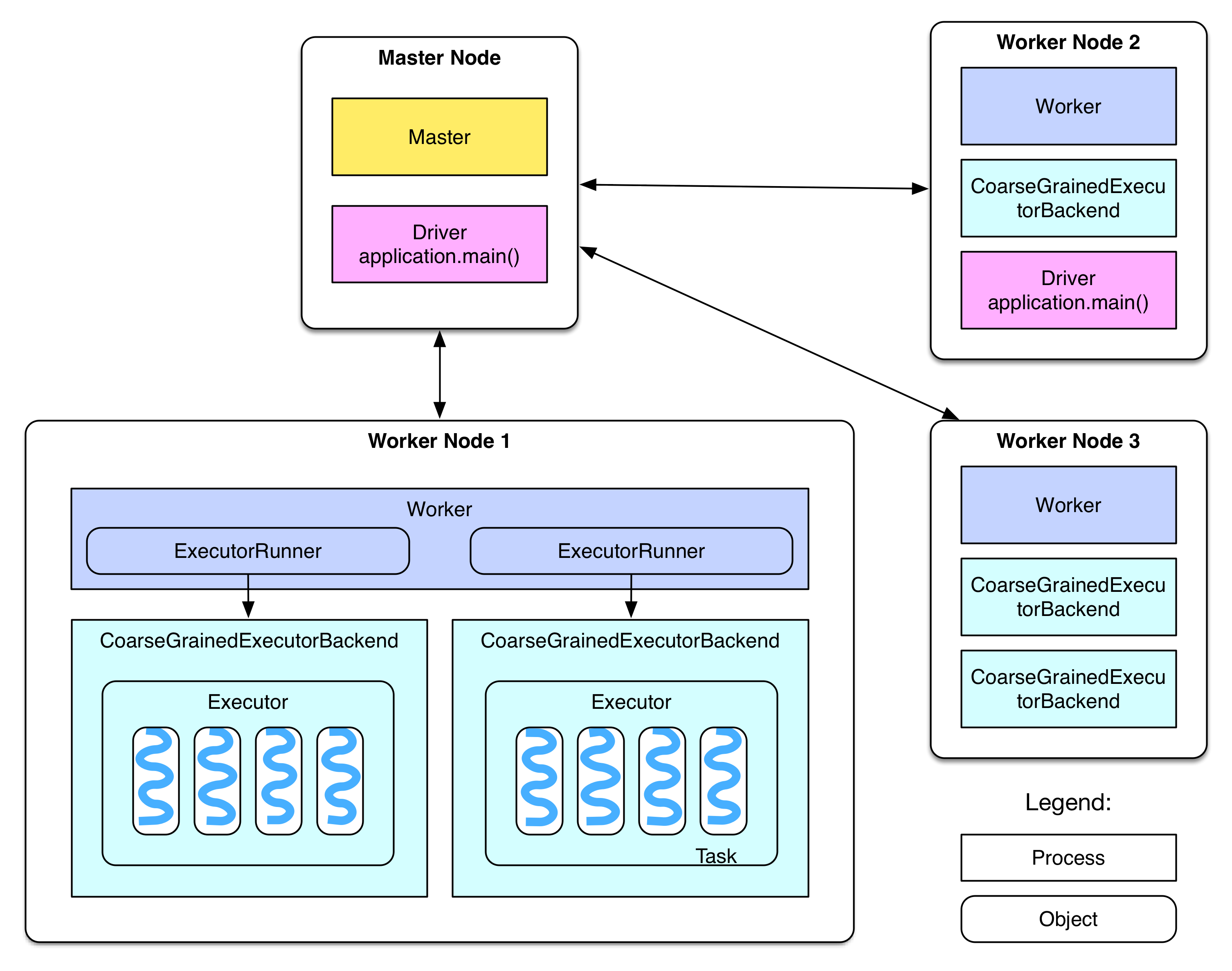
二、主机设置
1. 主机信息
| Host | hostname | Type |
|---|---|---|
| 192.168.2.20 | spark0 | Master |
| 192.168.2.21 | spark1 | Worker |
| 192.168.2.22 | spark2 | Worker |
| 192.168.2.23 | spark3 | Worker |
2. 网络配置-设置静态IP
Centos:/etc/sysconfig/network-scripts/ifcfg-ens33
TYPE=EthernetPROXY_METHOD=noneBROWSER_ONLY=noBOOTPROTO=static # 静态IPDEFROUTE=yesIPV4_FAILURE_FATAL=noIPV6INIT=yesIPV6_AUTOCONF=yesIPV6_DEFROUTE=yesIPV6_FAILURE_FATAL=noIPV6_ADDR_GEN_MODE=stable-privacyNAME=ens33UUID=0be22931-2f93-49ba-a410-6d366009dd1eDEVICE=ens33ONBOOT=yesIPADDR=192.168.2.20 # 设置IP地址NETMASK=255.255.255.0 # 设置子网掩码GATEWAY=192.168.2.2 # 设置网关DNS1=192.168.2.2 # 设置dns1DNS2=114.114.114.114 # 设置dns2
3. 设置hostname
hostnamectl set-hostname sparkN
4. 设置hosts
在4台主机上分别修改 /etc/hosts ,添加以下内容
192.168.2.20 spark0192.168.2.21 spark1192.168.2.22 spark2192.168.2.23 spark3
测试
ping spark1
5. 公钥私钥配置
在每台主机上产生新的rsa公钥私钥文件,并统一拷贝到一个authorized_keys文件中
(1)登录spark0,输入命令:
ssh-keygen -t rsa
三次回车后,.ssh目录下将会产生id_rsa,id_rsa.pub文件,其他主机也使用该方式产生密钥文件。
(2)登录spark0,输入命令:
cd .sshcat id_rsa.pub >> authorized_keys
将id_rsa.pub公钥内容拷贝到authorized_keys文件中
(3)登录其它主机,将其它主机的公钥文件内容都拷贝到spark0主机上的authorized_keys文件中,命令如下:
# 登录spark1,将公钥拷贝到spark0的authorized_keys中ssh-copy-id -i spark0# 登录spark2,将公钥拷贝到spark0的authorized_keys中ssh-copy-id -i spark0# 登录spark3,将公钥拷贝到spark0的authorized_keys中ssh-copy-id -i spark0# 登录spark0,查看authorized_keys是否成功cd .ssh & cat authorized_keys
6. 授权authorized_keys文件
(1)登录spark0,输入命令:
cd .sshchmod 600 authorized_keys
7. 将授权文件分发到其他主机上
(1)登录spark0,将授权文件拷贝到spark1、spark2…,命令如下:
# 拷贝到spark1上scp /root/.ssh/authorized_keys spark1:/root/.ssh/# 拷贝到spark2上scp /root/.ssh/authorized_keys spark2:/root/.ssh/# 拷贝到spark3上scp /root/.ssh/authorized_keys spark3:/root/.ssh/# 测试ssh spark1
三、环境安装配置(在spark0上操作)
JDK
- Downlaod JDK
下载地址:jdk-8u281-linux-x64.tar.gz.zip
解压JDK
tar -zxvf jdk-8u281-linux-x64.tar.gz -C /opt/
配置环境变量
编辑/etc/profile,添加如下内容:
export JAVA_HOME=/opt/jdk1.8.0_281export JRE_HOME=$JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATHexport JAVA_PATH=$JAVA_HOME/bin:$JRE_HOME/binexport PATH=$PATH:$JAVA_PATH
更新文件
source /etc/profile
测试
java -version
Scala
- 下载Scala
下载地址:scala-2.13.5.gz
解压
tar -zxvf scala-2.13.5.tgz -C /opt/
配置环境变量
编辑/etc/profile,添加如下内容:
export SCALA_HOME=/opt/scala-2.13.5export PATH=$SCALA_HOME/bin:$PATH
更新文件
source /etc/profile
测试
scala -version
Hadoop
- 下载Hadoop
下载地址:hadoop-2.7.3.tar.gz
解压
tar -zxvf hadoop-2.7.3.tar.gz -C /opt/
配置环境变量
编辑/etc/profile,添加如下内容:
export HADOOP_HOME=/opt/hadoop-2.7.3export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATHexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
添加文件夹
mkdir $HADOOP_HOME/tmp
修改$HADOOP_HOME/etc/hadoop/slaves为:
spark1spark2spark3
修改$HADOOP_HOME/etc/hadoop/core-site.xml为:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>hadoop.tmp.dir</name> <value>file:/opt/hadoop-2.7.3/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://spark0:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> </configuration>修改$HADOOP_HOME/etc/hadoop/hdfs-site.xml为:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>dfs.http.address</name> <value>spark0:50070</value> <description>The address and the base port where the dfs namenode web ui will listen on.If the port is 0 then the server will start on a free port. </description> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>spark0:50090</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/opt/hadoop-2.7.3/hdfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/opt/hadoop-2.7.3/hdfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>修改$HADOOP_HOME/etc/hadoop/yarn-site.xml为:
<?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.resourcemanager.hostname</name> <value>spark0</value> </property> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>spark0:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>spark0:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>spark0:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>spark0:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>spark0:8088</value> </property> </configuration>修改$HADOOP_HOME/etc/hadoop/mapred-site.xml为:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> <final>true</final> </property> <property> <name>mapreduce.jobtracker.http.address</name> <value>spark0:50030</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>spark0:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>spark0:19888</value> </property> <property> <name>mapred.job.tracker</name> <value>http://spark0:9001</value> </property> </configuration>修改$HADOOP_HOME/etc/hadoop/hadoop-env.sh的JAVA_HOME
export JAVA_HOME=/opt/jdk1.8.0_281格式化 namenode
hadoop namenode -format出现Exitting with status 0 表示成功,若为 Exitting with status 1 则是出错
Spark
- 下载Spark
下载地址:spark-3.1.1-bin-hadoop2.7.gz
解压
tar -zxvf spark-3.1.1-bin-hadoop2.7.tgz -C /opt/配置环境变量
编辑/etc/profile,添加如下内容:
export SPARK_HOME=/opt/spark-3.1.1-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
刷新配置
source /etc/profile配置spark-env.sh文件
cd /opt/spark-3.1.1-bin-hadoop2.7/conf cp spark-env.sh.template spark-env.sh vim spark-env.sh添加以下内容:
export JAVA_HOME=/opt/jdk1.8.0_281 export HADOOP_HOME=/opt/hadoop-2.7.3 export SCALA_HOME=/opt/scala-2.13.5 export SPARK_MASTER_IP=spark0配置workers文件
cd /opt/spark-3.1.1-bin-hadoop2.7/conf cp workers.template workers vim workers添加以下内容:
spark0 spark1 spark2 spark3
四、Spark 1-3配置
文件拷贝(在Spark0上操作)
拷贝/opt/目录
scp -r /opt/ root@spark1:/ scp -r /opt/ root@spark2:/ scp -r /opt/ root@spark3:/拷贝/etc/profile文件
scp /etc/profile root@spark1:/etc/ scp /etc/profile root@spark2:/etc/ scp /etc/profile root@spark3:/etc/
修改SPARK_LOCAL_IP(在spark1-3上操作)
刷新/etc/profile
source /etc/profile改SPARK_LOCAL_IP ```bash vim $SPARK_HOME/conf/spark-env.sh
把最后一行的spark0分别修改为spark1、spark2、spark3
export SPARK_MASTER_HOST=spark1
<a name="qBE4R"></a>
## 五、启动/停止集群
1. 启动脚本(_start-cluster.sh_)
```bash
#!/bin/bash
echo -e "\033[31m ========Start The Cluster======== \033[0m"
echo -e "\033[31m Starting Hadoop Now !!! \033[0m"
/opt/hadoop-2.7.3/sbin/start-all.sh
echo -e "\033[31m Starting Spark Now !!! \033[0m"
/opt/spark-3.1.1-bin-hadoop2.7/sbin/start-all.sh
echo -e "\033[31m The Result Of The Command \"jps\" : \033[0m"
jps
echo -e "\033[31m ========END======== \033[0m"
- 停止脚本(stop-cluser.sh)
#!/bin/bash echo -e "\033[31m ===== Stoping The Cluster ====== \033[0m" echo -e "\033[31m Stoping Spark Now !!! \033[0m" /opt/spark-3.1.1-bin-hadoop2.7/sbin/stop-all.sh echo -e "\033[31m Stopting Hadoop Now !!! \033[0m" /opt/hadoop-2.7.3/sbin/stop-all.sh echo -e "\033[31m The Result Of The Command \"jps\" : \033[0m" jps echo -e "\033[31m ======END======== \033[0m"
六、VMware完整集群虚拟机
链接: https://pan.baidu.com/s/1uXXX2lwk9au3AyF3_OK-Xg
密码: hpdt
七、参考

若有收获,就点个赞吧
0 人点赞
