| 测试部 | 文档编号 | 版本 | v1.0 | 密级 | 内部 | |
|---|---|---|---|---|---|---|
| 产品型号 | 产品版本 | |||||
| 项目名称 |
Epm2.0性能测试报告
| 编 写: | 李学琪 | 日 期: | 2021.07.12 |
|---|---|---|---|
| 检 查: | 日 期: | ||
| 审 核: | 日 期: | ||
| 批 准: | 日 期: |
文档修改记录
| 序号 | 修改(+/-)说明 | 作者 | 版本号 | 日期 |
|---|---|---|---|---|
| 1 | 初版 | 李学琪 | V1.0 | |
| 2 | ||||
| 3 | ||||
| 4 |
1、指标要求
1.1目的
1.1 客户端性能要求
- 打开前端页面一般时段响应时间不超过2秒,高峰时段不超过5秒。
- 对于一些特定功能,如要加载很长一段时间区间数据的,多波形,长波形等,通过异步加载和分页加载技术,如有必要,
还需在加载过程显示进度条,提高用户体验。
- 最小支持100并发/秒
- 单台服务器最大可支持2000测点(有线2000测点的配置为,32核心+128G+12TB【年】)
- 支持系统扩展,可从1台服务器,扩展到多台,最多支持8台。
- 单台服务器上的时序数据库最大支持300亿条数据的存储。(2000测点,60个指标/测点,15钟一组,存3年,指标占将近150亿,另外的预留给工艺存储)
系统资源占用率以基准测试结果为准 (CPU,内存,磁盘IO,网络)
1.2 服务端性能要求
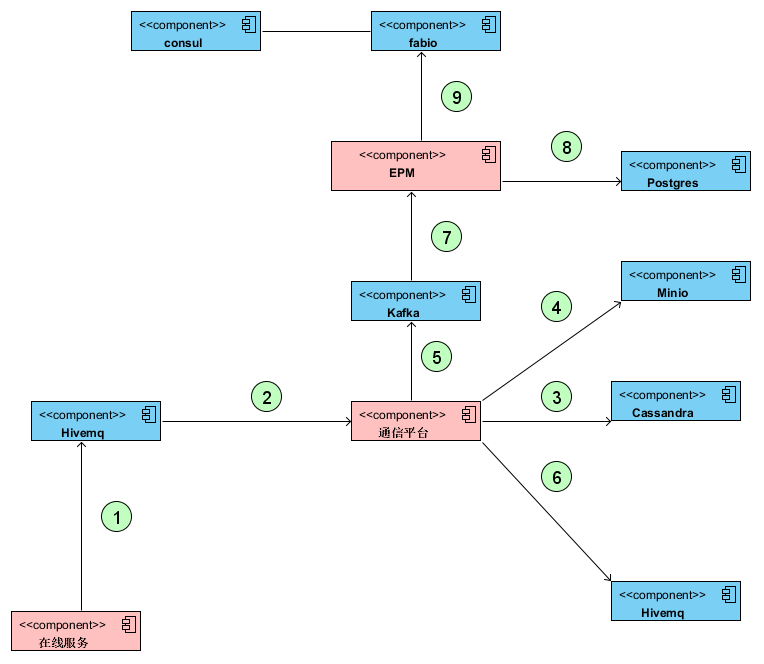
数据模拟产生波形及指标数据通过MQTT协议发送给HiveMQ
- 数据采集从HiveMQ中获取波形及指标数据
- 数据采集将指标数据转发给Cassandra
- 数据采集波形数据转发给Minio
- 数据采集将业务数据转发给Kafka
- 数据采集将HiveMQ数据转发给另一个HiveMQ(模拟DTS功能)
- 微服务从Kafka中消费业务数据
- 微服务将处理后的数据部分存入Postgres
- 微服务为外部页面提供数据接口服务
- 综合以上9个指标,系统给结合以下条件,设定性能综合指标标准:
- 硬件配置(CPU、内存、硬盘)
- 设备台数(风电为基准) | 综合标准 | 吞吐量(读/写) | 响应时间(读/写) | 资源(网络/CPU/内存/磁盘) | | —- | —- | —- | —- | | 波形存储 | | | | | 指标存储 | | | | | 数据转发 | | | | | 报警发送 | | | | | Web接口 | | | |
- 综合标准不包括采集站部分产生的性能损耗,具体解释如下:
- 指标存储:包含图中1、2、3的综合性能评价
- 波形存储:包含图中1、2、4的综合性能评价
- 数据转发:包含图中1、2、6的综合性能评价
- 报警发送:包含图中1、2、5、7的综合性能评价
- Web服务:包含途中的9、8的综合性能评价
1.3 所提取的主要业务流程
1.系统登录
2.监测数据总览
3.打开健康管理-诊断分析-趋势波形频谱
4.打开健康管理-诊断分析-多参量分析
5.打开健康管理-诊断分析-阶次分析
6.打开健康管理-诊断分析-通道温度(该对应的数据如何准备)
7.打开健康管理-启停机管理,进行状态反馈的修改
8.物设备平台-智能自诊断,进行异常记录的处理
2、风电采集配置(8核16G)
2.1风电单台性能测试硬件配置
Linux单台服务器硬件:8核心+16G+8TB以上
Windows单台服务器硬件:4核+16G+8T以上
2.2数据采集并发测试标准
风电/钢铁行业:
| 测量定义 | 采集周期 | 说明 |
|---|---|---|
| 128K 加速度波形(2-20000) 256K 加速度波形(2-2000) 16K 速度波形(2-1000) |
30分钟 | 15台采集站,16通道,2M长波形 相当于120台采集器一台服务器 |
数据标准:
采集站类型:RH1000
采集站个数:14 满配:16通道
采样频率: 波形:30min
指标:30s
2、风电采集配置(8核16G)
2.1风电单台性能测试硬件配置
2.2数据采集并发测试标准
风电/钢铁行业:
| 测量定义 | 采集周期 | 说明 |
|---|---|---|
| 128K 加速度波形(2-20000) 256K 加速度波形(2-2000) 16K 速度波形(2-1000) |
30分钟 | 15台采集站,16通道,2M长波形 相当于120台采集器一台服务器 |
2.3安装后没有上任何数据情况
2021/08/02: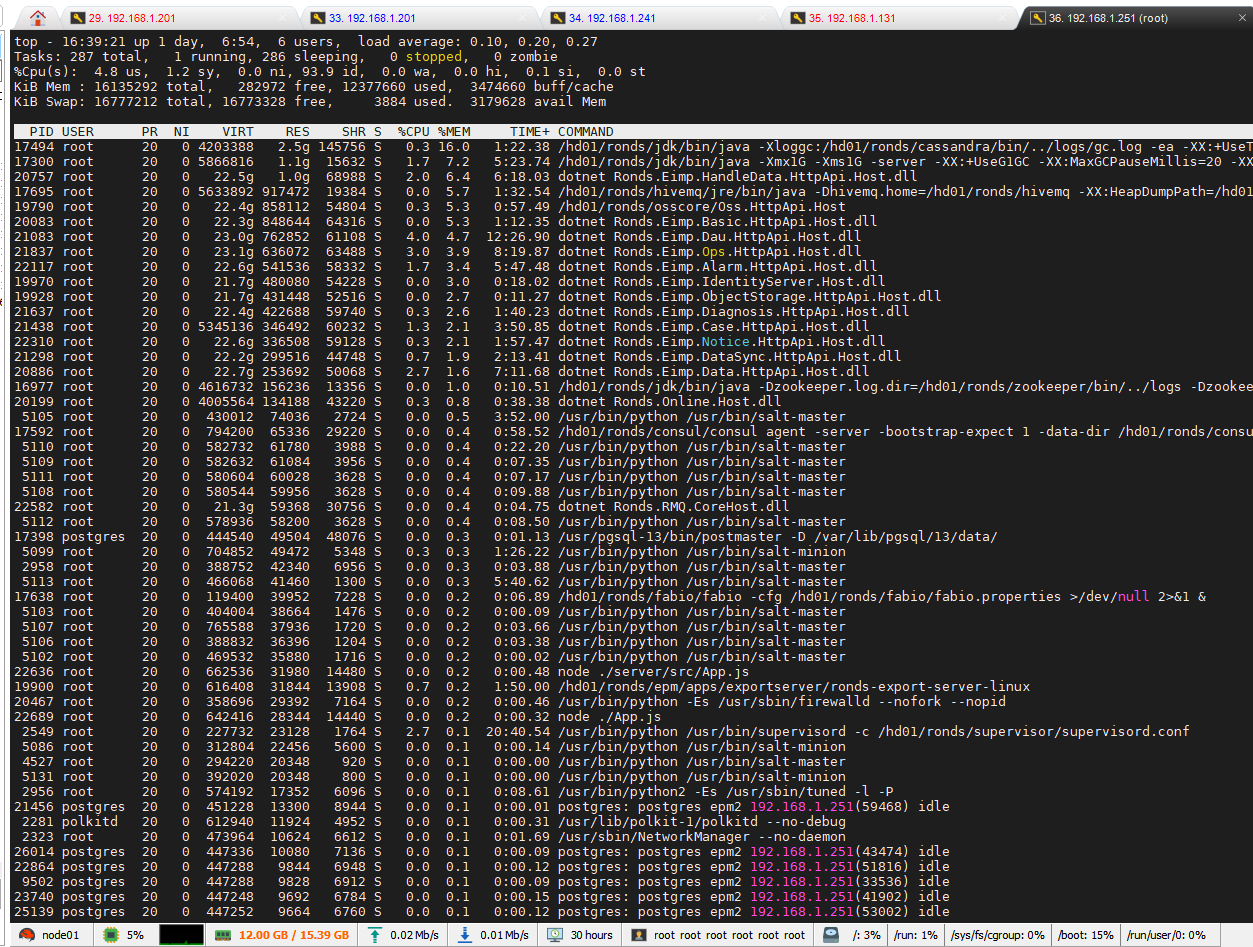
2.4正常上次数据资源情况
2.5断网情况下硬件资源情况
2021/08/02:
问题描述:
1、断网数据上传之后系统中各位服务内存占用情况:
hivemq:3.8G
cassandra:2.9G
handledata:1.4G(存在上升趋势且一直在上升,上升速度较快)
kafka:1G
online:1G(最高时达到1.6G)
basic:500M
2、磁盘io
最高读:10M/s
最高写:19M/s
磁盘队列长度:10左右,且一直在满负荷允许
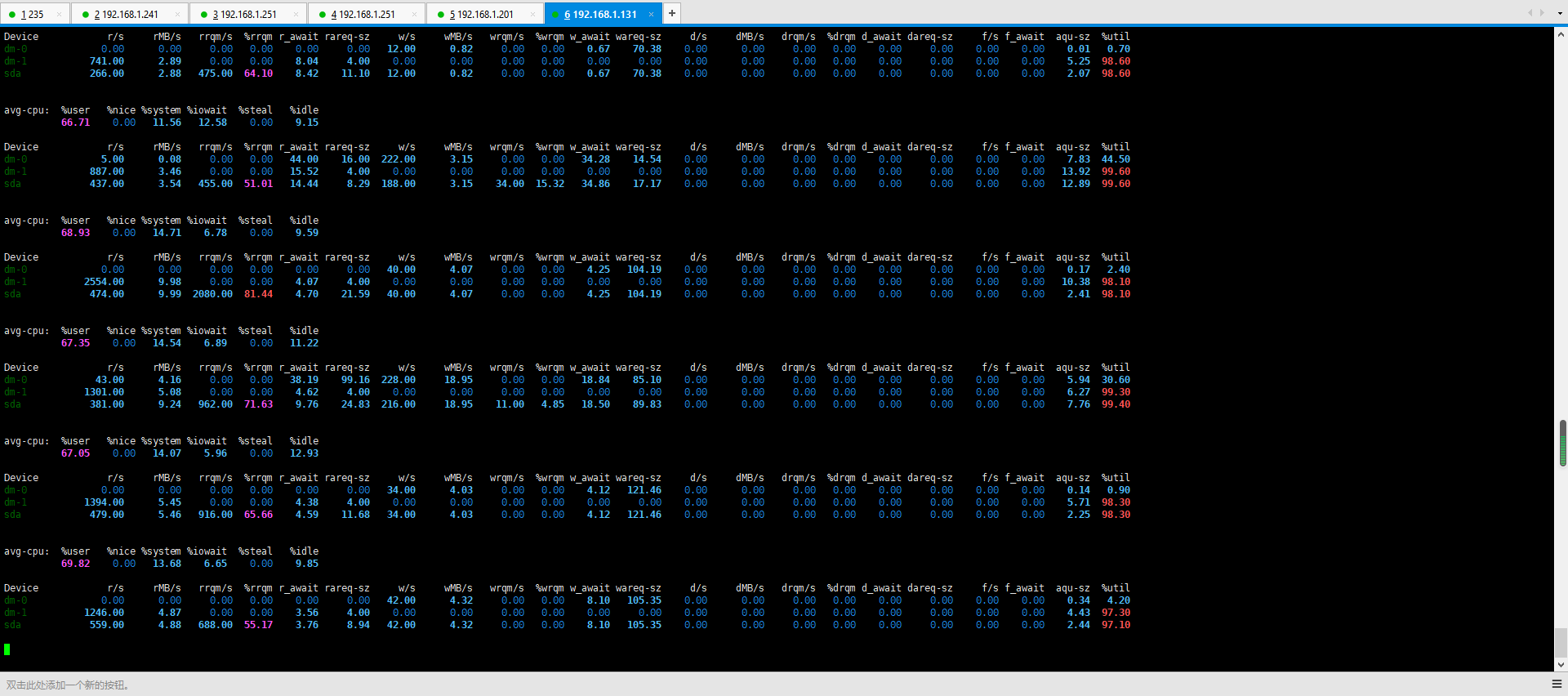
2021/08/03:
修改情况:handledata对内存有初步修改,内存上升速度变慢(上升速度半小时后结果)
cassandra对内存参数限制
hivemq对内存参数限制
断网数据上传之后系统中各位服务内存占用情况:
hivemq:1.4G
cassandra:3.0G
handledata:1.9G(存在上升趋势且一直在上升,上升速度较快)
kafka:1.4G
online:1.7G(最高时达到1.6G)
basic:450M
2、磁盘io
最高读:27M/s(平均在450M/s)
最高写:4M/s
磁盘队列长度:130左右,且一直在满负荷允许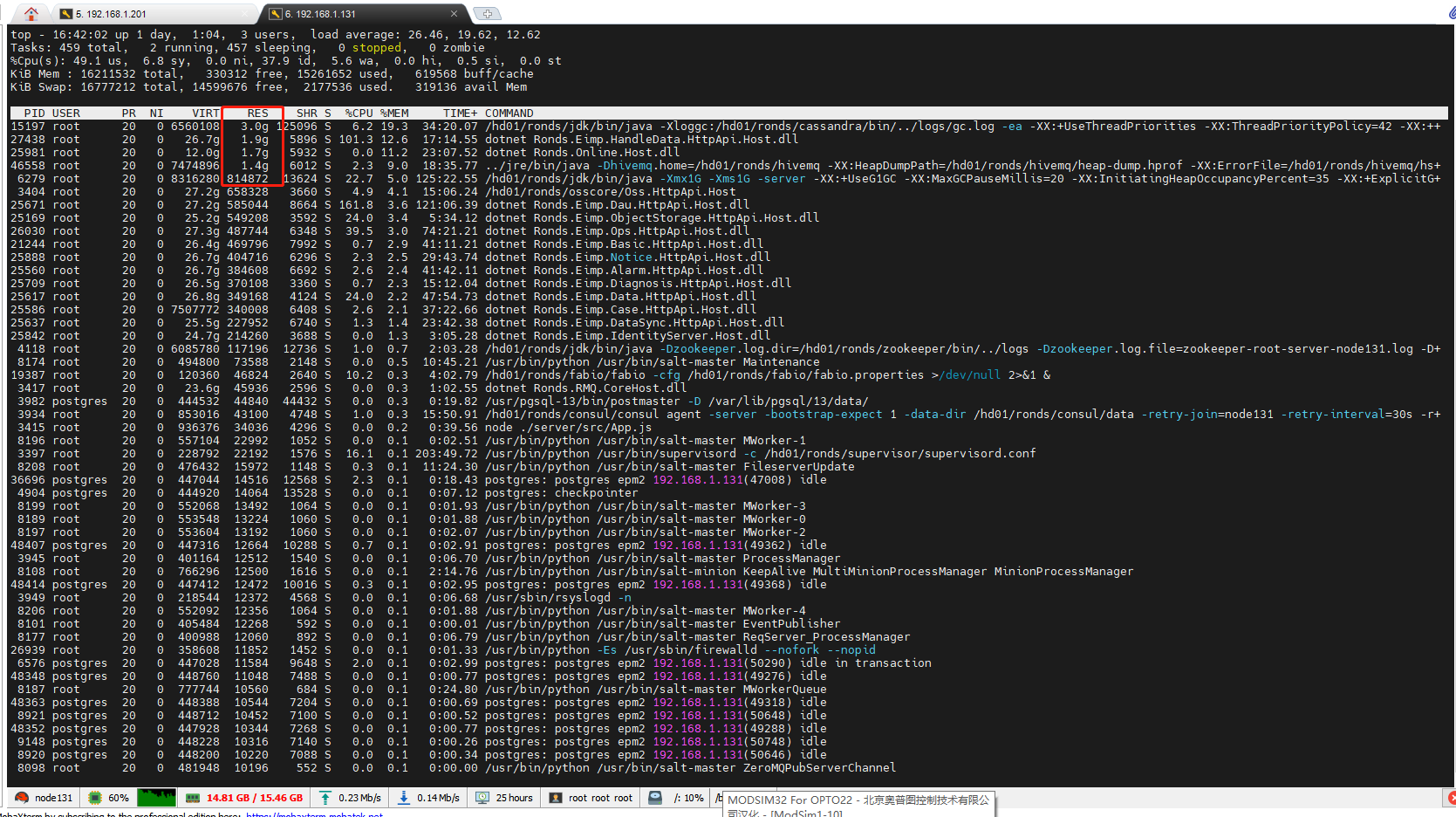
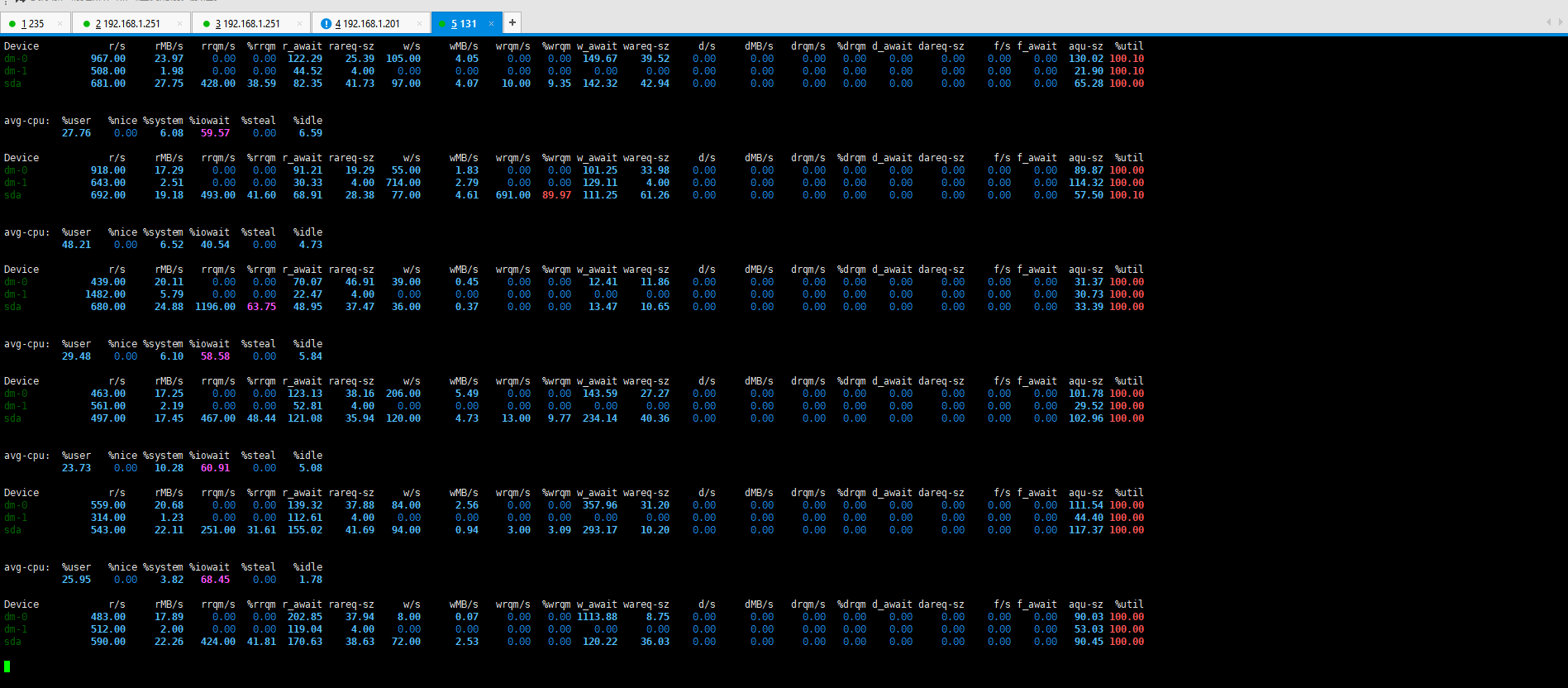
优化情况:
1、handledata内存上升速度变缓,上限并没有变化(还在优化…)
2、hivemq,cassandra设置了限制参数,但是没有明显效果(还在优化…)
2.6数据积压上传数据资源情况
Windows系统
2021/8/12正常上数据:
系统连续运行时长:24小时
3、服务器端给出的性能要求
| 综合标准 | 吞吐量(读/写) | 响应时间(读/写) | 资源(网络/CPU/内存/磁盘) |
|---|---|---|---|
| 波形存储 | |||
| 指标存储 | |||
| 数据转发 | |||
| 报警发送 | |||
| Web接口 |
难点:①需要开发提供工具,模拟采集站上送数据。②要求波形存储、指标存储这种区分程序如何确定吞吐量、响应时间。
1.4 各主要界面响应时间测试
1、要求2000个测点,15分钟一组,3年的测试数据,此处的历史测试数据如何模拟?在数据库插入相应的数据?
2、录入epm2.0打开各主要界面的脚本,模拟并发。
①并发个数10
| 各主要界面 | 吞吐量(读/写) | 响应时间(读/写) | 服务器资源(网络/CPU/内存/磁盘) |
|---|---|---|---|
| 系统登录 | |||
| 监测数据总览 | |||
| 健康管理-诊断分析-趋势波形频谱 | |||
| 健康管理-诊断分析-多参量分析 | |||
| 健康管理-诊断分析-阶次分析 | |||
| 健康管理-诊断分析-通道温度 | |||
| 健康管理-启停机管理 | |||
| 物设备平台-智能自诊断 |
后续并发个数20,、50同样给出相应的结果。
3、通过的标准:
界面响应时间<2秒,高峰期小于5秒。
难点:何为高峰期,数据库多少历史数据的基础上

若有收获,就点个赞吧
0 人点赞
