1. Flink时间分类
在Flink的流式处理中,会涉及到时间的不同概念,如下图所示:
- EventTime[事件时间]
事件发生的时间,例如:点击网站上的某个链接的时间,每一条日志都会记录自己的生成时间
- IngestionTime[**摄入时间**]
数据进入Flink的时间,如某个Flink节点的sourceoperator接收到数据的时间,例如:某个source消费到kafka中的数据
如果以IngesingtTime为基准来定义时间窗口那将形成IngestingTimeWindow,以source的systemTime为准- ProcessingTime[**处理时间**]
某个Flink节点执行某个operation的时间,例如:timeWindow处理数据时的系统时间,默认的时间属性就是Processing Time
如果以ProcessingTime基准来定义时间窗口那将形成ProcessingTimeWindow,以operator的systemTime为准在Flink的流式处理中,绝大部分的业务都会使用EventTime,一般只在EventTime无法使用时,才会被迫使用ProcessingTime或者IngestionTime。
如果要使用EventTime,那么需要引入EventTime的时间属性,引入方式如下所示:
final StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironrnent();// 使用处理时间env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime) ;// 使用摄入时间env.setStrearnTimeCharacteristic(TimeCharacteristic.IngestionTime);// 使用事件时间env.setStrearnTimeCharacteristic(TimeCharacteri stic Eve~tTime);
2. Window概念和划分机制
窗口概念:将无界流的数据,按时间区间,划分成多份数据,分别进行统计(聚合)
Flink支持两种划分窗口的方式(time和count),第一种,按时间驱动进行划分、另一种按数据驱动进行划分。

1、按时间驱动Time Window 划分可以分为 滚动窗口 Tumbling Window 和滑动窗口 Sliding Window。
2、按数据驱动Count Window也可以划分为滚动窗口 Tumbling Window 和滑动窗口 Sliding Window。
3、Flink支持窗口的两个重要属性(窗口长度size和滑动间隔interval),通过窗口长度和滑动间隔来区分滚动窗口和滑动窗口。
如果size=interval,那么就会形成tumbling-window(无重叠数据)—滚动窗口
如果size(1min)>interval(30s),那么就会形成sliding-window(有重叠数据)—滑动窗口
通过组合可以得出四种基本窗口:
(1)time-tumbling-window 无重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(5))—-基于时间的滚动窗口
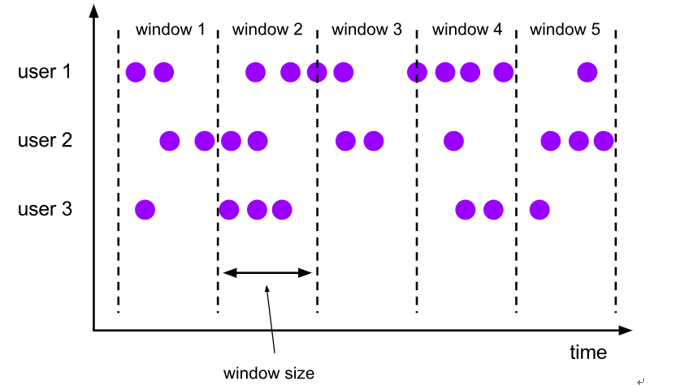
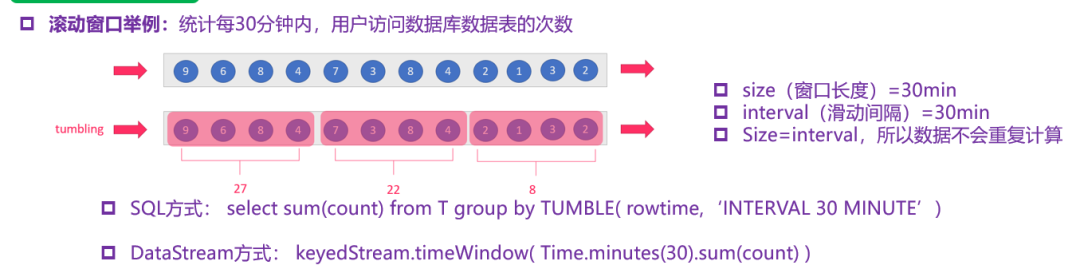
(2)time-sliding-window 有重叠数据的时间窗口,设置方式举例:timeWindow(Time.seconds(10), Time.seconds(5))—-基于时间的滑动窗口
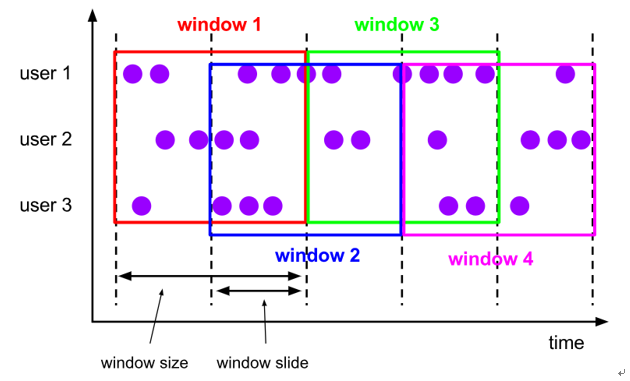

(3)count-tumbling-window无重叠数据的数量窗口,设置方式举例:countWindow(5)—-基于数量的滚动窗口

(4)count-sliding-window 有重叠数据的数量窗口,设置方式举例:countWindow(10,5)—-基于数量的滑动窗口

Flink中还支持一个特殊的窗口:会话窗口SessionWindows
session窗口分配器通过session活动来对元素进行分组,session窗口跟滚动窗口和滑动窗口相比,不会有重叠和固定的开始时间和结束时间的情况
session窗口在一个固定的时间周期内不再收到元素,即非活动间隔产生,那个这个窗口就会关闭。
一个session窗口通过一个session间隔来配置,这个session间隔定义了非活跃周期的长度,当这个非活跃周期产生,那么当前的session将关闭并且后续的元素将被分配到新的session窗口中去,如下图所示:

3. WaterMark(水印)
在进行数据处理的时候应该按照事件时间进行处理,也就是窗口应该要考虑到事件时间,但是窗口不能无限的一直等到延迟数据的到来,需要有一个触发窗口计算的机制,就是watermaker水位线/水印机制。
所以:**水印是用来解决数据延迟、数据乱序等问题,总结如下图所示:**

水印就是一个时间戳(timestamp),Flink可以给数据流添加水印
水印并不会影响原有Eventtime事件时间
当数据流添加水印后,会按照水印时间来触发窗口计算,也就是说watermark水印是用来触发窗口计算的
设置水印时间,会比事件时间小几秒钟,表示最大允许数据延迟达到多久
水印时间 = 事件时间 - 允许延迟时间 (例如:10:09:57 = 10:10:00 - 3s )
4. 水印运行原理
如下图所示:

窗口是10分钟触发一次,现在在12:00 - 12:10 有一个窗口,本来有一条数据是在12:00 - 12:10这个窗口被计算,但因为延迟,12:12到达,这时12:00 - 12:10 这个窗口就会被关闭,只能将数据下发到下一个窗口进行计算,这样就产生了数据延迟,造成计算不准确。
现在添加一个水位线:数据时间戳为2分钟。这时用数据产生的事件时间 12:12 -允许延迟的水印 2分钟 = 12:10 >= 窗口结束时间 。窗口触发计算,该数据就会被计算到这个窗口里
5. 水印 API调用
在DataStream API 中使用 TimestampAssigner 接口定义时间戳的提取行为,包含两个子接口 AssignerWithPeriodicWatermarks 接口和 AssignerWithPunctuatedWaterMarks接口


6. 侧道输出保证超过WaterMark数据不丢失
使用 WaterMark+ EventTimeWindow 机制可以在一定程度上解决数据乱序的问题,但是,WaterMark 水位线也不是万能的,在某些情况下,数据延迟会非常严重,即使通过Watermark + EventTimeWindow也无法等到数据全部进入窗口再进行处理,因为窗口触发计算后,对于延迟到达的本属于该窗口的数据,**Flink**默认会将这些延迟严重的数据进行丢弃
那么如果想要让一定时间范围的延迟数据不会被丢弃,可以使用Allowed Lateness(允许迟到机制/侧道输出机制)设定一个允许延迟的时间和侧道输出对象来解决
即使用WaterMark + EventTimeWindow + **Allowed Lateness**方案(包含侧道输出),可以做到数据不丢失。
API调用
- allowedLateness(lateness:Time)—-设置允许延迟的时间
该方法传入一个Time值,设置允许数据迟到的时间,这个时间和watermark中的时间概念不同。再来回顾一下,
watermark=数据的事件时间-允许乱序时间值
随着新数据的到来,watermark的值会更新为最新数据事件时间-允许乱序时间值,但是如果这时候来了一条历史数据,watermark值则不会更新。
总的来说,watermark永远不会倒退它是为了能接收到尽可能多的乱序数据。
那这里的Time值呢?主要是为了等待迟到的数据,如果属于该窗口的数据到来,仍会进行计算,后面会对计算方式仔细说明
注意:该方法只针对于基于event-time的窗口
- sideOutputLateData(outputTag:OutputTag[T])—保存延迟数据
该方法是将迟来的数据保存至给定的outputTag参数,而OutputTag则是用来标记延迟数据的一个对象。
- DataStream.getSideOutput(tag:OutputTag[X])—获取延迟数据
通过window等操作返回的DataStream调用该方法,传入标记延迟数据的对象来获取延迟的数据

若有收获,就点个赞吧
0 人点赞
