content
- 当我们使用requests请求服务器成功时,服务器会向我们发送一些数据,最终数据的格式可以是bytes(字节码)或者是字符串,当是html文件时,我们可以选择数据格式是字符类型, 而当图片、视频等媒体文件,选择bytes
- 1 bytes = 8 bit
```python import requests
url = “https://www.baidu.com“
headers = {“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36”}
response = requests.get(url,headers=headers)
print(response.content)
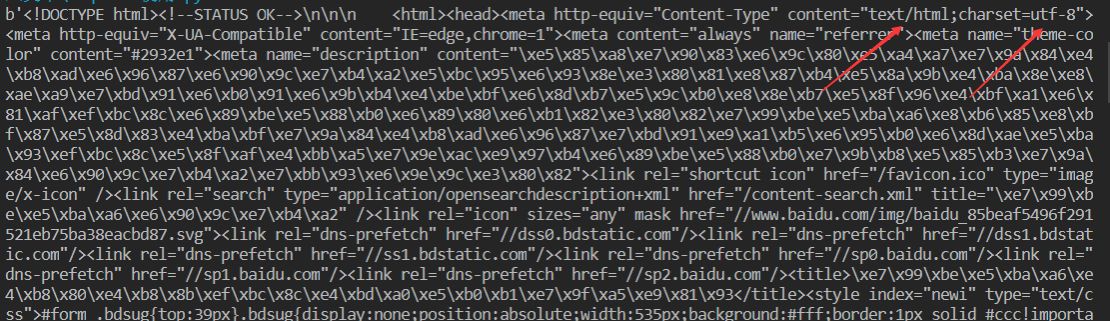<a name="eKFIM"></a>#### decode- 可以通过解码,让数据转为字符串格式,如上图,charset=utf-8即编码格式为utf-8。可以看到,中文经过节码之后就可以显示出来了。```pythonprint(response.content.decode('utf-8'))

text
- 使requests返回的数据为文本类型

encode
- 编码,将字符串转为bytes类型
print(response.text.encode('utf-8'))

错误编码
- 字符串编码可以使用任意方法,而解码只能用对应的编码方式进行解码,不然会报错 ```python string = “你好呀!I am bruin~”
string = string.encode(‘gbk’)
print(string)
print(string.decode(‘utf-8’))
```

编码格式 https://www.cnblogs.com/Hyman-Zheng/p/11076526.html

若有收获,就点个赞吧
0 人点赞
