What is Elasticsearch
You know, for search (and analysis)
Elasticsearch is the distributed search and analytics engine at the heart of the Elastic Stack. Logstash and Beats facilitate collecting, aggregating, and enriching your data and storing it in Elasticsearch. Kibana enables you to interactively explore, visualize, and share insights into your data and manage and monitor the stack. Elasticsearch is where the indexing, search, and analysis magic happens.
Elasticsearch provides near real-time search and analytics for all types of data. Whether you have structured or unstructured text, numerical data, or geospatial data, Elasticsearch can efficiently store and index it in a way that supports fast searches. You can go far beyond simple data retrieval and aggregate information to discover trends and patterns in your data. And as your data and query volume grows, the distributed nature of Elasticsearch enables your deployment to grow seamlessly right along with it.
While not every problem is a search problem, Elasticsearch offers speed and flexibility to handle data in a wide variety of use cases:
- Add a search box to an app or website
- Store and analyze logs, metrics, and security event data
- Use machine learning to automatically model the behavior of your data in real time
- Automate business workflows using Elasticsearch as a storage engine
- Manage, integrate, and analyze spatial information using Elasticsearch as a geographic information system (GIS)
- Store and process genetic data using Elasticsearch as a bioinformatics research tool
We’re continually amazed by the novel ways people use search. But whether your use case is similar to one of these, or you’re using Elasticsearch to tackle a new problem, the way you work with your data, documents, and indices in Elasticsearch is the same.
数据映射
创建索引前,可预先定义索引字段的类型及属性,使索引更加标准,有利于搜索和分析工作。
静态映射
POST /school{"settings": {"number_of_shards": 5,"number_of_replicas": 1},"mappings": {"student": {"age": {"type": "long"},"course": {"type": "string"},"name": {"type": "keyword"},"study_date": {"type": "date","formate": "yyyy-MM-dd"}}}}
动态映射
可以通过 dynamic 属性进行控制(更标准)。属性值:
- true:默认值,动态添加字段;
- false:忽略新字段;
strict:强制使用当前 mapping 设置,陌生字段抛异常;
POST /school{"mappings": {"student": {"dynamic": "strict","properties": {"age": {"type": "long"},"course": {"type": "string"},"name": {"type": "keyword"},"study_date": {"type": "date","formate": "yyyy-MM-dd"},"other": {"type": "object","dynamic": true}}}}}
文档写入时,检测到该索引中没有的字段时,动态映射可以根据写入的 json 类型自动转换该字段的类型,并加入到 mapping 映射。
null: No field is added.
- true / false: boolean
- floating point number: float
- integer: long
- object: object
- array: Depends on the first non-null value in the arrat
string: date(passes date detection), double or long(passes numeric detection), text(with a keyword sub-field)
更新映射
mapping 创建后,可以新增字段类型,不能修改已有的字段映射。
如需修改,新建索引,重新定义映射。把旧索引里的数据导入到新建立的索引。PUT /school/_mapping/student{"student": {"properties": {"a_new_field": {"type": "keyword"}}}}
应用运行时
使用别名,平滑过渡:
将当前的索引定义别名,并指向这个别名
- PUT / 现有索引 / _alias / 别名
- 应用程序用别名访问索引信息
- 新建一个索引,定义好最新的映射
将别名指向新的索引,并取消之前索引的指向
POST /_aliases{"actions": [{"remove": {"index": "oldIndex","alias": "alias"}},{"add": {"index": "newIndex","alias": "alias"}}]}
类型定义属性
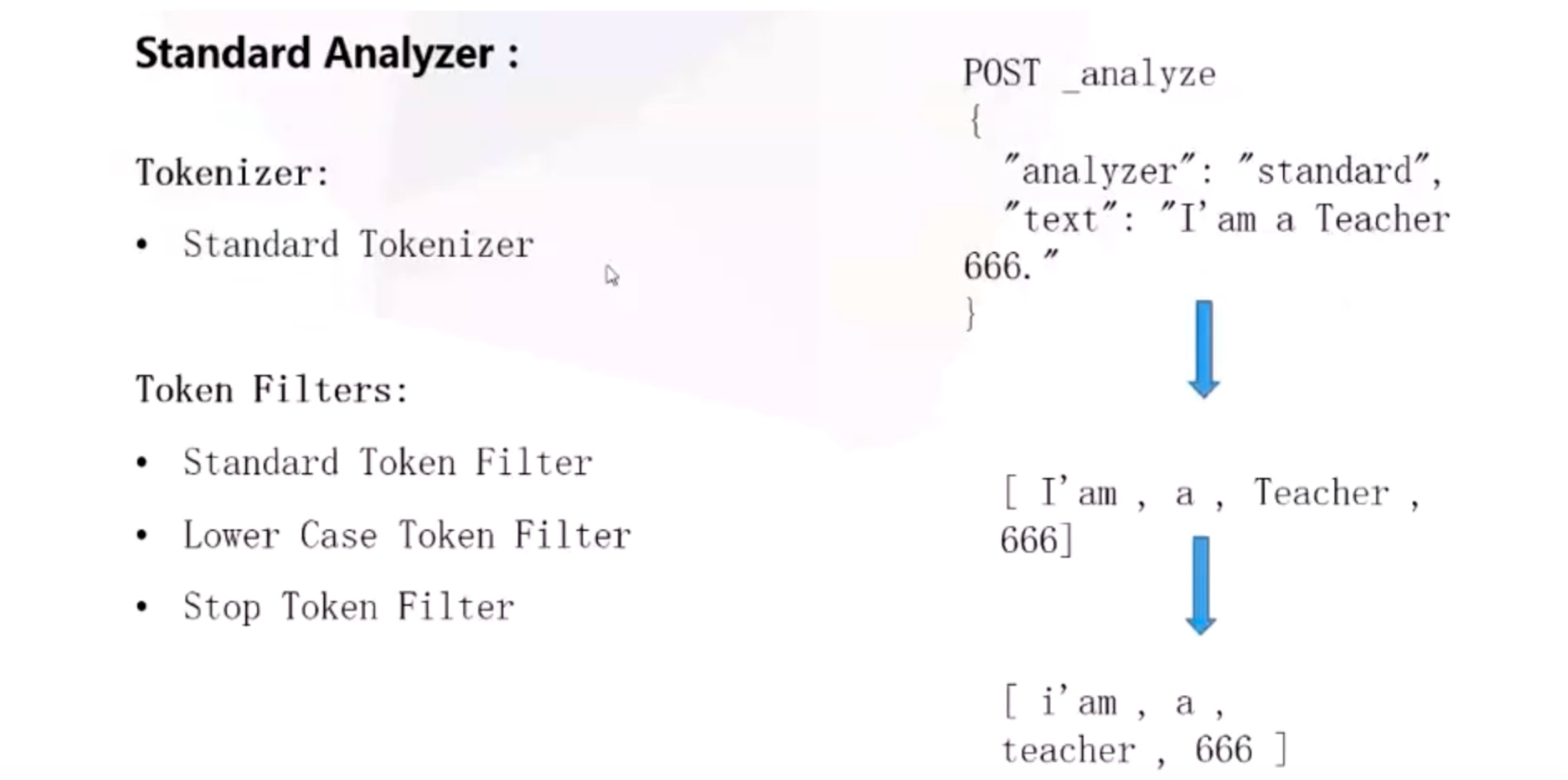
analyzer: 索引(倒排索引)时用的分析器,ES 默认使用 standard 分析器(lowercase+english),stopword,还有 whitespace, simple, syop, english
- search_analyzer: 搜索时用的分析器,默认 analyzer
- index: true / false,索引 / 不索引
- ignore_above: 默认单个 term 最大长度 32kb(32767),非英文 json 固定是 utf8,一个字占用 3b,所以要小于 32767 / 3 = 10922
- boost: 试着字段的权值,默认 1.0
- include_in_all: 默认 ES 为每个文档定义一个特殊域 _all,每个字段都将被搜索到,如果你不想让某个字段被索引到,就在字段里设置一个 include_in_all=false,默认 true
- store: true / false(默认),单独存储字段
-
分析器
Character filters 文本预处理
HTML Strip Character Filter
- Mapping Character Filter
- Pattern Replace Character Filter …
Tokenizer - 分词
- Stardard Tokenizer
- Letter Tokenizer
- Lowercase Tokenizer
- Whitespace Tokenizer …
Token filters - 对分词再处理
- Stop Token Filter
- Lower Case Token Filter
- Uppercase Token Filter …

Standard Analyzer
Simple Analyzer

Stop Analyzer

自定义分析器

倒排索引
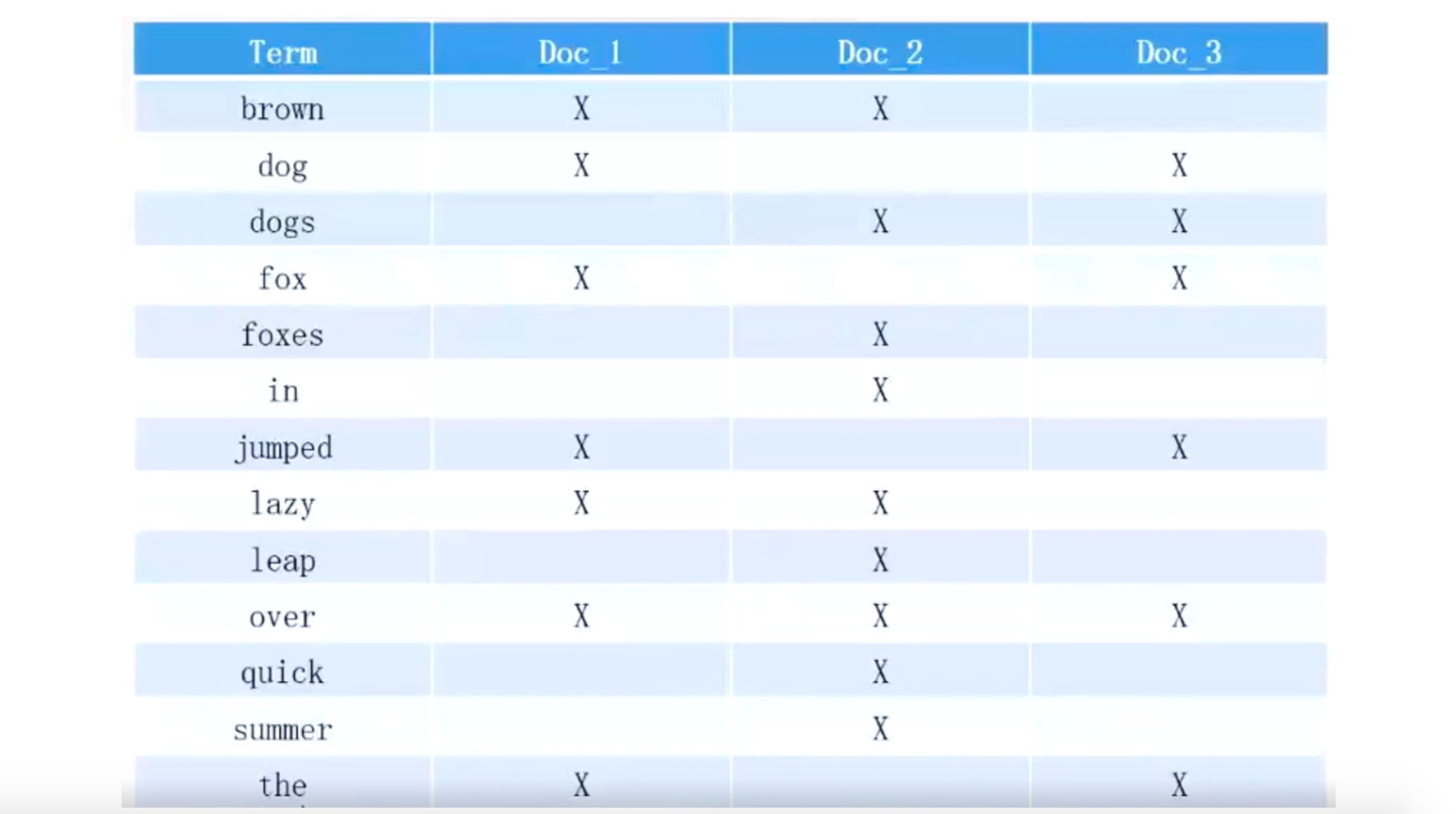
Doc Values

Doc values 可以用于聚合、排序、访问字段值的脚本,父子关系处理等(任何需要查找某个文档包含值的操作)。
旧版本将索引加载到 JVM,新版本加载到 Linux 文件系统文件缓存。
数据类型
- string:text 启用分词处理; keyword 不经过分词,枚举型
- number:integer,long,short,byte,double,float
- date:默认格式 strict_date_optional_time||epoch_millis 长整型时间戳(毫秒),例如:2017-06-12T20:30:00.000Z||1496055518000

- boolean
- ip:支持 ipv4 / ipv6

- geo_point:地理坐标搜索

- nested:嵌套类型

- object

-
内置字段
_index
- _type
- _id
- _all
- _source
- _field_names
- _meta
- _uid
- _routing

元数据

模板
动态模板
PUT my_index{"mappings": {"_default": {"_all": {// 默认不开启"enable": false}},"user": {},"blogpost": {"_all": {// 默认开启"enable": true}}}}
分词,另存一份不分词。

若有收获,就点个赞吧
0 人点赞
