原因一:IO多路复用epoll,除了epoll,还有select与poll两种复用方式(通俗举例:epoll:结账的时候,服务员告诉老板哪桌要结账)
select、poll、epoll都是I/O多路复用的机制,I/O多路复用就是通过一种机制,一个进程可以监视多个文件描述符,一旦某个描述符就绪(读就绪或写就绪),能够通知程序进行相应的读写操作
但是,select,poll,epoll本质还是同步I/O(I/O多路复用本身就是同步IO)的范畴,因为它们都需要在读写事件就绪后线程自己进行读写,读写的过程阻塞的,而异步I/O的实现是系统会把负责把数据从内核空间拷贝到用户空间,无需线程自己再进行阻塞的读写,内核已经准备完成
Select/
运行机制:select系统调用允许程序同时在多个底层文件描述符上,等待输入的到达或输出的完成,以数组形式存储文件描述符,64位机器默认2048个,当有数据准备好时,无法感知具体是哪个流OK了,所以需要一个一个的遍历,函数的时间复杂度为O(n)
机制缺陷:
每次调用select,都需要把fd集合从用户态拷贝到内核态,fd越多开销则越大;
每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
select支持的文件描述符数量有限,默认是1024,参见/usr/include/linux/posix_types.h中的定义:
Poll/
运行机制:Poll以链表形式存储文件描述符,没有长度限制,本质与select相同,函数的时间复杂度也为O(n)
机制缺陷:
Poll机制相较于Select机制中,解决了文件描述符数量上限为1024的缺陷,但另外两点缺陷依然存在:
每次调用poll,都需要把fd集合从用户态拷贝到内核态,fd越多开销则越大;
每次调用poll,都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
EPoll/
运行机制:Epoll是基于事件驱动的,如果某个流准备好了,会以事件通知,知道具体是哪个流,因此不需要遍历,函数的时间复杂度为O(1)
工作模式:
- LT模式(level trigger),水平触发: 默认的工作模式,即当epoll_wait检测到某描述符事件就绪并通知应用程序时,应用程序可以不立即处理该事件;事件会被放回到就绪链表中,下次调用epoll_wait时,会再次通知此事件
- ET模式(edge trigger),边缘触发: 当epoll_wait检测到某描述符事件就绪并通知应用程序时,应用程序必须立即处理该事件,如果不处理,下次调用epoll_wait时,不会再次响应并通知此事件
机制优点:
使用内存映射技术,节省了用户态和内核态间数据拷贝的资源消耗;
通过每个fd定义的回调函数来实现的,只有就绪的fd才会执行回调函数,I/O的效率不会随着监视fd的数量的增长而下降;
文件描述符数量不再受限;
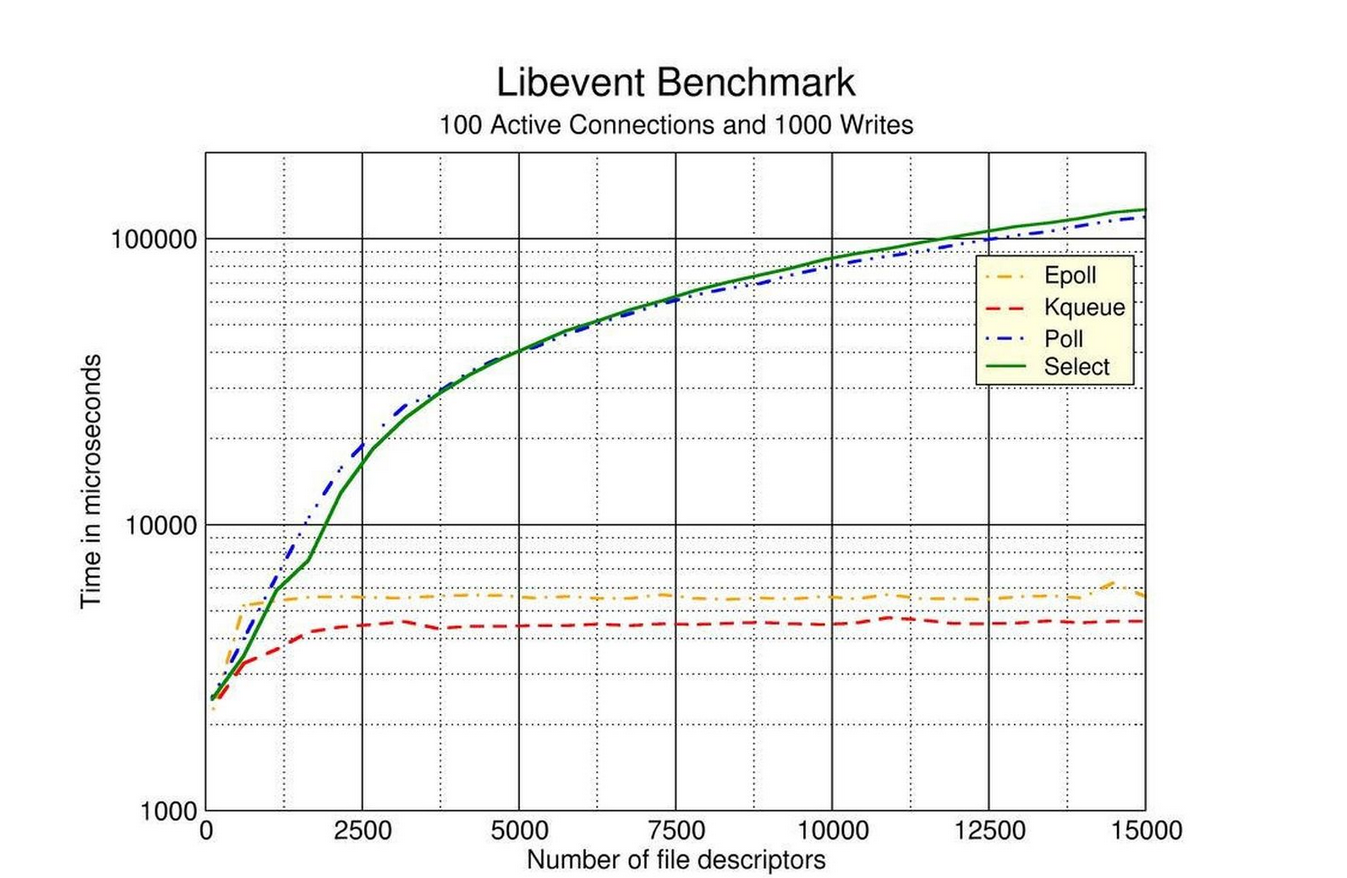
三种机制的对比
相关文献链接:
https://zhuanlan.zhihu.com/p/127170201 & https://zhuanlan.zhihu.com/p/95872805
原因二:轻量级,功能代码少,代码模块化
原因三:CPU亲和(affinity),是一种把CPU核心和Nginx工作进程worker绑定方式,把每个worker进程固定在一个CPU上执行,减少切换CPU的cache miss,获得更好的性能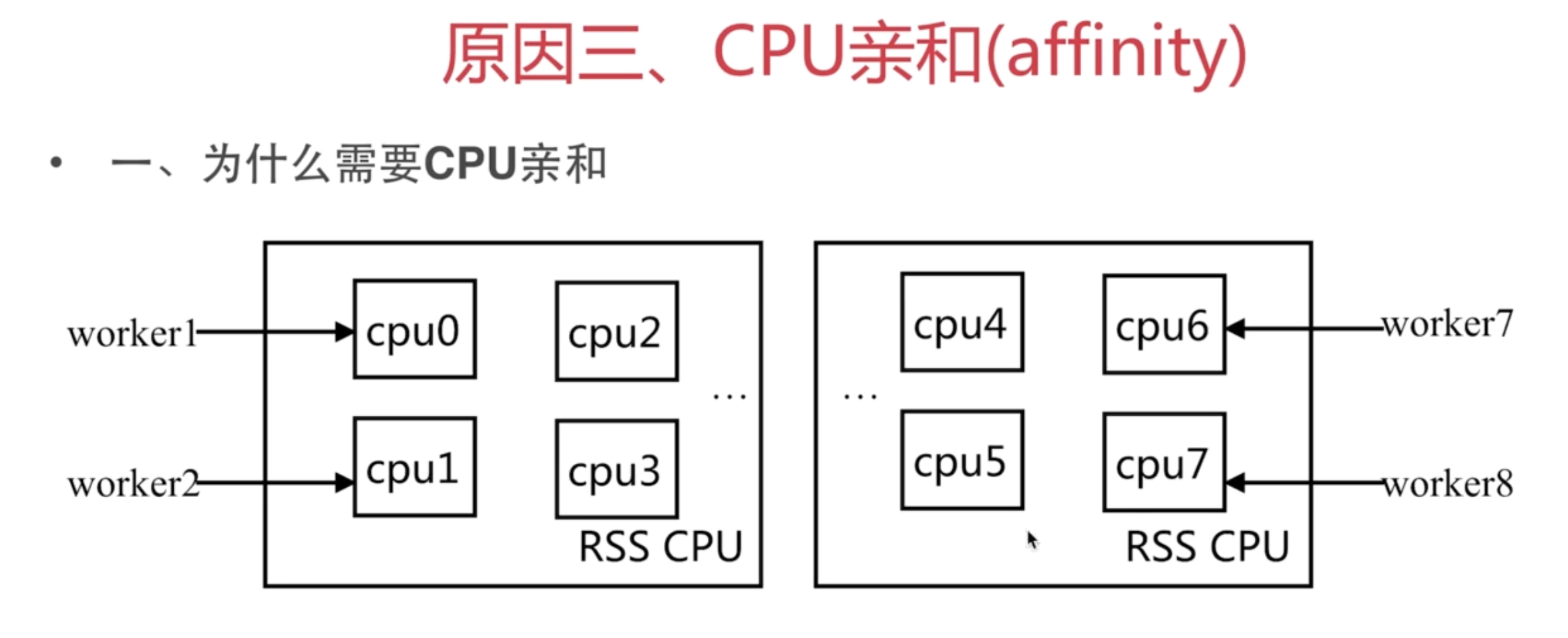
原因四:sendfile,针对静态文件的优化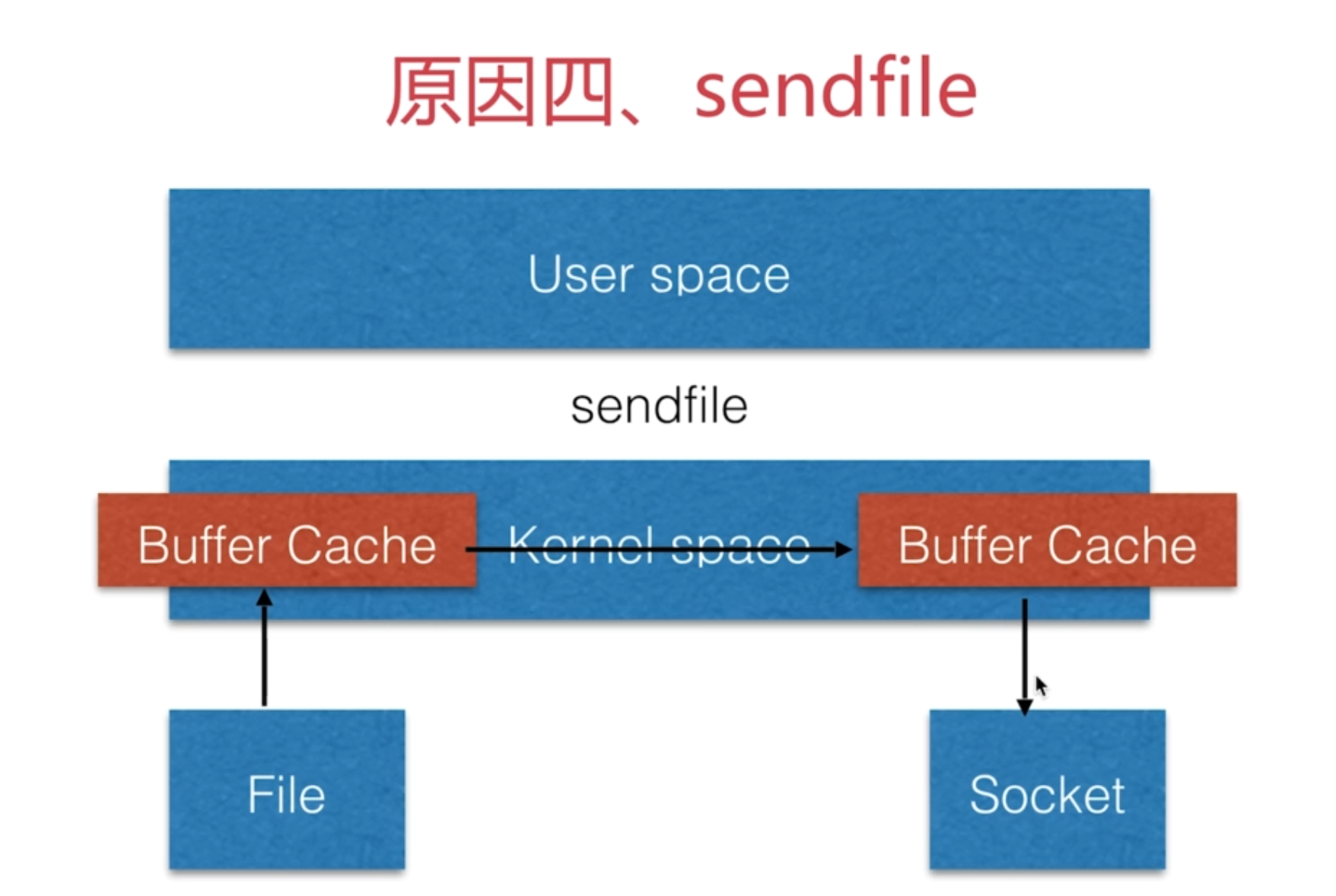

若有收获,就点个赞吧
0 人点赞
