CE / MSE
- why using CrossEntropy for classification problem, while Mean Square Error for regression problem?
CE loss:
where . For
. For  , if
, if  is closer to 0, the
is closer to 0, the  is getting smaller and the reducing speed is increasing.
is getting smaller and the reducing speed is increasing.  . That means that more distance between p and y is , more and more the loss will be.
. That means that more distance between p and y is , more and more the loss will be.
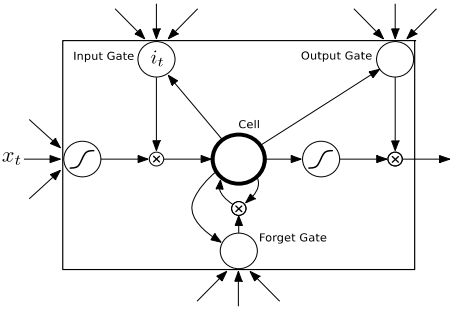
For MSE, the loss is correspond to the bias between p and y.LSTM

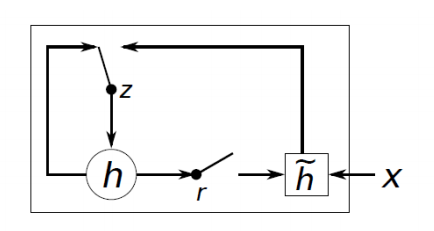
GRU


若有收获,就点个赞吧
0 人点赞
