1、CAP理论、Base理论?
1)CAP理论:
1、Consistency一致性:即更新操作成功并返回客户端后,所有节点在同一时间的数据完全一致。
对于客户端:一致性指的是并发访问同时更新过的数据如果获取的问题;
对于服务端:则是更新如何复制分布到整个系统,以保证数据最终一致。
2、Availability可用性:
即服务一直可用,而且是正常响应时间。不出现用户操作失败或者访问超时等
3、Partition Tolerance(分区容错性):
即分布式系统在遇到某节点或者网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务。比如系统中某一个或者多个系统宕机了,其他剩下的机器还能正常运转满足系统需求
注:一般满足CP或者AP,即如果发生网络分区异常时,一致性和可用性只能满足其一
2)Base理论:
Base理论是对CAP中一致性和可用性权衡的结果,其核心理论就是:即使系统无法满足强一致性,但每个应用都可以根据自身的特点采用一定的方式满足最终一致性。主要可分为基本可用、软状态和最终一致性
1.基本可用(Basically Available): 基本可用是指分布式系统在出现故障的时候,允许损失部分可用性,即保证核心可用。电商大促时,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的体现。
2、软状态(Soft State): 软状态是指允许系统存在中间状态,而该中间状态不会影响系统整体可用性。分布式存储中一般一份数据至少会有三个副本,允许不同节点间副本同步的延时就是软状态的体现。MySQL Replication 的异步复制也是一种体现。
3、最终一致性(Eventual Consistency): 最终一致性是指系统中的所有数据副本经过一定时间后,最终能够达到一致的状态。弱一致性和强一致性相反,最终一致性是弱一致性的一种特殊情况。
2、负载均衡算法、类型
静态负载均衡:
1)轮询法
将请求按顺序轮流地分配到每个节点上,不关心每个节点实际的连接数和当前的系统负载。
2)随机法
将请求随机分配到各个节点。由概率统计理论得知,随着客户端调用服务端的次数增多,其实际效果越来越接近于平均分配,也就是轮询的结果。
3)源地址哈希法
源地址哈希的思想是根据客户端的IP地址,通过哈希函数计算得到一个数值,用该数值对服务器节点数进行取模,得到的结果便是要访问节点序号。采用源地址哈希法进行负载均衡,同一IP地址的客户端,当后端服务器列表不变时,它每次都会落到到同一台服务器进行访问。
4)加权轮询法:
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载。
5)加权随机法:
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
动态负载均衡:
1)最小连接数法
根据每个节点当前的连接情况,动态地选取其中当前积压连接数最少的一个节点处理当前请求,尽可能地提高后端服务的利用效率,将请求合理地分流到每一台服务器。俗称闲的人不能闲着,大家一起动起来。
负载均衡类型:
1、DNS方式实现负载均衡
2、硬件负载均衡
3、软件负载均衡:
Nginx:反向代理,七层负载均衡,支持HTTP、E-mail协议,同时也支持4层负载均衡
HAproxy:支持七层负载均衡,Open默认就是使用的负载均衡。
3、分布式架构下,怎么解决session共享问题?
什么是session
服务器会为每个用户创建一个session会话,存储用户的相关信息,以便在后面的请求中,可以够定位到同一个上下文。
在N年前,那个都是单个服务器的年代,session直接保存在服务器中,是一点问题没有的,而且实现起来很容易。但是随着分布式架构的流行,单个服务器已经不能满足系统的需要了,通常都会把系统部署在多台服务器上,通过负载均衡把请求分发到其中的一台服务器上,这样很可能同一个用户的请求被分发到不同的服务器上,因为session是保存在服务器上的,那么很有可能第一次请求访问的A服务器,创建了session,但是第二次访问到了B服务器,这时就会出现取不到session的情况。于是,分布式架构中,session共享就成了一个很大的问题。
解决session共享问题:
- 不要有session:大家可能觉得我说了句废话,但是确实在某些场景下,是可以没有session的,其实在很多接口类系统当中,都提倡【API无状态服务】;也就是每一次的接口访问,都不依赖于session、不依赖于前一次的接口访问;
- 存入cookie中:将session存储到cookie中,但是缺点也很明显,例如每次请求都得带着session,数据存储在客户端本地,是有风险的;
- session同步:对个服务器之间同步session,这样可以保证每个服务器上都有全部的session信息,不过当服务器数量比较多的时候,同步是会有延迟甚至同步失败;
- 使用Nginx(或其他复杂均衡软硬件)中的ip绑定策略,利用hash算法,比如nginx的ip_hash,使得同一个Ip的请求分发到同一台服务器上,但是这样做风险也比较大,而且也是去了负载均衡的意义;
- 我们现在的系统会把session放到Redis中存储,虽然架构上变得复杂,并且需要多访问一次Redis,但是这种方案带来的好处也是很大的:实现session共享,可以水平扩展(增加Redis服务器),服务器重启session不丢失(不过也要注意session在Redis中的刷新/失效机制),不仅可以跨服务器session共享,甚至可以跨平台(例如网页端和APP端)。
4、简述对RPC、RMI的理解?
RPC(远程调用协议):在本地调用远程的函数,远程过程调用,可以跨语言实现,例如HTTPClient。
RMI(Remote Method Invocation):远程方法调用,java中实现RPC的一种机制,能够让在客户端Java虚拟机上的对象像调用本地对象一样调用服务端java 虚拟机中的对象上的方法。(例如A远程调用B,要求A和B都部署在JVM虚拟机中。)
RPC的实现步骤:
1. 执行客户端调用语句,传送参数
2. 调用本地系统发送网络消息
3. 消息传送到远程主机
4. 服务器得到消息并取得参数
5. 根据调用请求以及参数执行远程过程(服务)
6. 执行过程完毕,将结果返回服务器句柄(也称伺服器,是提供计算服务的设备)
7. 服务器句柄返回结果,调用远程主机的系统网络服务发送结果
8. 消息传回本地主机
9. 客户端句柄由本地主机的网络服务接收消息
10. 客户端收到调用语句返回的结果数据
RMI远程调用:
1、当一个对象直接或者间接实现接口Remote,就成为存在于服务器端的远程对象,供客户端访问并提供一定的服务。
2、远程对象必须实现UnicCastRemoteObject类,这样才能保证客户端访问获得远程对象时,该远程对象将会把自身的一个拷贝以socket的形式传输给客户端,此时客户端所获得这个拷贝称为“存根”,而服务器端本身存在的远程对象称之为“骨架”,其实此时的存根是客户端对象的一个代理,用于与服务器的通信,而骨架其实也是服务器的一个代理,用于接收客户端的请求之后调用远程方法来响应客户端的请求。
RMI远程调用的步骤: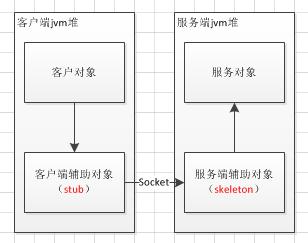
1. 客户调用客户端辅助对象 stub(上图)上的方法
2. 客户端辅助对象 stub 打包调用信息(变量、方法名),通过网络发送给服务器辅助对象 skeleton
3. 服务器端辅助对象 skeleton 将客户端辅助对象发送来的信息解包,找出真正被调用的方法以及该方法所在对象
4. 调用真正服务对象上的真正方法,并将结果返回给服务器辅助对象 skeleton
5. 服务器端辅助对象将结果打包,发送给客户端辅助对象 stub
6. 客户端辅助对象将返回值解包,返回给调用者
7. 客户获得返回值
5、分布式id生成方案?
分布式系统id的需求:
在复杂的系统中,往往需要对大量的数据如订单,账户进行标识,以一个有意义的有序的序列号来作为全局唯一的ID;
而分布式系统中我们对ID生成器要求又有哪些呢?
全局唯一性:不能出现重复的ID号,既然是唯一标识,这是最基本的要求。
递增:比较低要求的条件为趋势递增,即保证下一个ID一定大于上一个ID,而比较苛刻的要求是连续递增,如1,2,3等等。
高可用高性能:ID生成事关重大,一旦挂掉系统崩溃;高性能是指必须要在压测下表现良好,如果达不到要求则在高并发环境下依然会导致系统瘫痪。
方法1:UUID
1)生成UUID的一些组成:
1、当前日期和时间 时间戳
2、时钟序列
3、全局唯一的IEEE机器识别号,如果有网卡,则从网卡MAC地址获得。
2)优点:代码简单,性能好(本地生成,没有网络消耗)、保证唯一性.
3)缺点:
1。性能为题:UUID太长,通常以36长度的字符串表示,对MySQL索引不利,存储性比较差:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能
2. UUID无业务含义:很多需要ID能标识业务含义的地方不使用
3.不满足递增要求
4.UUID中包含MAC地址,可能存在线程安全问题
方法2:数据库自增序列(自增ID)
利用数据库生成ID是最常见的方案。能够确保ID全数据库唯一。其优缺点如下:
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
- 不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。
- 在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。
- 在性能达不到要求的情况下,比较难于扩展。
- 如果涉及多个系统需要合并或者数据迁移会比较麻烦。
- 分表分库的时候会有麻烦。
方法3:数据库多主模式:
多节点部署数据库,当然我们这里使用的是双主模式的数据库,因为主从数据库之间数据不同步的情况下会出现ID重复的现象,这也就违背了我们全局ID唯一的特点。为了多个数据库(这里用两个数据库举例)生成不重复的ID,我们可以使用给每台mysql数据库设置初始值和步长的方式来配置数据库。
方法4:基于Redis生成唯一ID
Redis的所有命令操作都是单线程的,本身提供像 incr 和 increby 这样的自增原子命令,所以能保证生成的 ID 肯定是唯一有序的。
方法5:号段模式:
我们可以使用号段的方式来获取自增ID,号段可以理解成批量获取,比如DistributIdService从数据库获取ID时,如果能批量获取多个ID并缓存在本地的话,那样将大大提供业务应用获取ID的效率。
比如DistributIdService每次从数据库获取ID时,就获取一个号段,比如(1,1000],这个范围表示了1000个ID,业务应用在请求DistributIdService提供ID时,DistributIdService只需要在本地从1开始自增并返回即可,而不需要每次都请求数据库,一直到本地自增到1000时,也就是当前号段已经被用完时,才去数据库重新获取下一号段。
方法6:雪花算法
snowflake是twitter开源的分布式ID生成算法,是一种算法,所以它和上面的三种生成分布式ID机制不太一样,它不依赖数据库。
核心思想是:雪花算法是分布式主键生成算法,它能够保证不同表的主键的不重复性,以及相同表的主键的有序性。
生成一个64bit的整形数字,其中第一位符号固定为0(正数是0,负数是1,所以id一般是正数,最高位是0),41为时间戳,10为workId,12位序列号
6、分布式锁解决方案?
分布式锁应具备的条件:
1、在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
2、高可用的获取锁与释放锁;
3、高性能的获取锁与释放锁;
4、具备可重入特性;
5、具备锁失效机制,防止死锁;
6、具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
分布式锁常用解决方案:
1. 基于数据库实现分布式锁
利用主键冲突控制一次只能由一个线程获取锁,直接创建一张锁表,然后通过操作该表中的数据来实现了。当我们要锁住某个方法或资源时,我们就在该表中增加一条记录,想要释放锁的时候就删除这条记录。
缺点就是非阻塞方式、不可重入、单点(一但数据库挂掉,业务系统将会不可用)、锁没有失效时间。
2. 基于ZooKeeper实现分布锁
Zookeeper的数据存储结构就像一棵树,这棵树由节点组成,这种节点叫做Znode。 Zookeeper分布式锁利用了临时顺序节点。
1.创建一个目录 mylock;
2.线程 A 想获取锁就在 mylock 目录下创建临时顺序节点;
3.获取 mylock 目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
4.线程 B 获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
5.线程 A 处理完,删除自己的节点,线程 B 监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
ZooKeeper 具备高可用、可重入、阻塞锁特性,可解决失效死锁问题。 但 ZooKeeper 因为需要频繁的创建和删除节点,性能上不如 Redis 方式。
3. 基于缓存(Redis等)实现分布式锁
1.获取锁的时候,使用 setnx 加锁,并使用 expire 命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的 value 值为一个随机生成的 UUID,通过此在释放锁的时候进行判断。
2.获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
3.释放锁的时候,通过 UUID 判断是不是该锁,若是该锁,则执行 delete 进行锁释放。
redis实现分布式锁是单线程处理网络请求,不需要考虑并发安全性。
4、三种分布式锁的比较:
- 从理解的难易程度角度(从低到高): 数据库 > 缓存 > Zookeeper
- 从实现的复杂性角度(从低到高): Zookeeper >= 缓存 > 数据库
- 从性能角度(从高到低): 缓存 > Zookeeper >= 数据库
- 从可靠性角度(从高到低): Zookeeper > 缓存 > 数据库
7、分布式事务解决方法
XA规范:分布式事务规范,定义了分布式事务模型。
四个角色:事务管理器(协调者TM,统一管理我们的多个数据库)、浏览管理器(参与者RM,一般是指我们的数据库)、应用程序AP(发起事务者)、通信资源管理器CRM。
全局事务:一个横跨多个数据库的事务,要么全部提交,要么全部回滚。
JTA事务是java对XA规范的实现,对于JDBC的单库事务。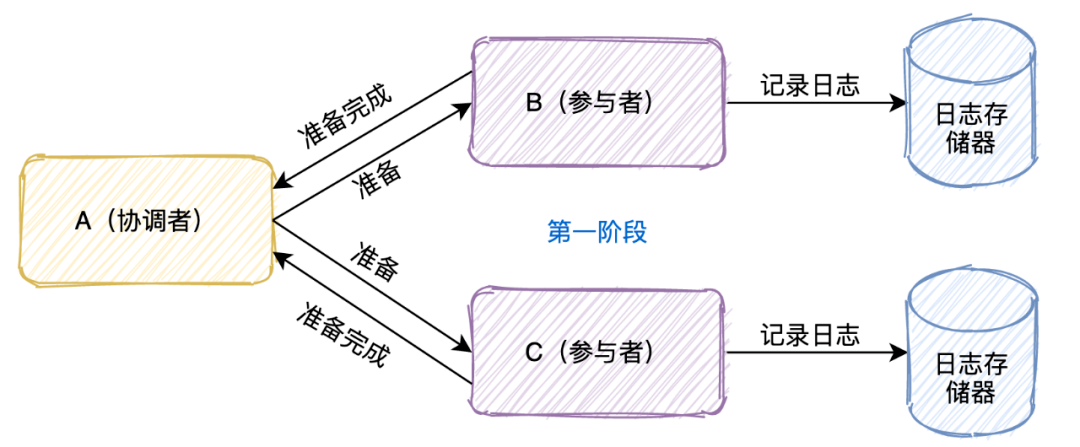
基于数据库的两阶段协议:
第一阶段:每个参与者执行本地事务但不提交,进入ready状态,并通知协调者已经准备就绪。
第二阶段:当协调者确认每个参与者都ready后,通知参与者进行commit操作;如果有参与者fail,则发送rollback命令,各参与者发生回滚。
两阶段可能会出现的问题:
- 「单点故障」:一旦事务管理器出现故障,整个系统不可用
- 「数据不一致」:在阶段二,如果事务管理器只发送了部分 commit 消息,此时网络发生异常,那么只有部分参与者接收到 commit 消息,也就是说只有部分参与者提交了事务,使得系统数据不一致。
- 「响应时间较长」:整个消息链路是串行的,要等待响应结果,不适合高并发的场景
- 「不确定性」:当事务管理器发送 commit 之后,并且此时只有一个参与者收到了 commit,那么当该参与者与事务管理器同时宕机之后,重新选举的事务管理器无法确定该条消息是否提交成功
三阶段协议:
基于两阶段协议的优化,增加了CanCommit阶段和超时机制。如果段时间内没有收到协调者的commit请求,那么就会自动进行commit,解决了2PC单点故障的问题。
step1:发送canCommint消息,确认参与者(数据库)的环境是否正常
step2:发送preCommit消息,各个数据库执行本地事务但不提交
step3:发送doCommit消息,当协调者确认每个参与者都ready后,通知参与者进行commit操作;如果有参与者fail,则发送rollback命令,各参与者发生回滚。
基于业务层面的TCC事务补偿机制:(Try、Confrim、Cancel)
「针对每个操作,都要注册一个与其对应的确认和补偿(撤销)操作」。它分为三个阶段:Try操作做业务检查及资源预留,Confrim做业务确认操作,Cancel实现一个与Try相反的操作即回滚操作。
step1:TM首先发起所有的分支事务的try操作(业务系统做检测及资源预留)
step2:若Try操作全部成功,则TM将会发起所有分支事务的Confrim操作(业务系统做确认提交)
step3:任何一个分支事务的try操作执行失败,TM将会发起所有的分支事务的Cancel操作。(预留资源释放)
消息队列mq:
step1:(生产者)事务A发送prepare消息到消息中间件
step2:发送成功后,执行本地事务
如果事务执行成功,则commit,消息中间件将消息下发至消费端(事务B)【commit之前,消息不会被消费】
如果事务执行失败,则进行回滚,消息中间件将这条prepare消息删除
step3:消息端(事务B)若收到消息,则进行消费(事务执行),如果事务B执行失败,则不断重试。
8、如何实现接口的幂等性校验?
同一个接口,多次发出同一个请求,必须保证操作只执行一次。比如用户登录注册、订单创建、订单支付重复发送请求。
如何解决:
1、token机制:功能上允许重复提交,但要保证重复提交不产生副作用,比如点击n次只产生一条记录,具体实现就是进入页面时申请一个token,然后后面所有的请求都带上这个token,后端根据token是否存在于redis中来避免重复请求。
2、乐观锁的机制:如果更新已有数据,可以进行加锁更新,也可以设计表结构时使用乐观锁,通过version来做乐观锁,这样既能保证执行效率,又能保证幂等, 乐观锁的version版本在更新业务数据要自增。只有当版本符合要求时,才能进行数据更新。
3、防重表:将业务中有唯一标识的字段保存到去重表(比如说订单表的订单号),如果去重表中已存在,说明已经处理过了。

若有收获,就点个赞吧
0 人点赞
