Kubernetes
Kubernetes 是 Google 基于 Borg 开源的容器编排调度,用于管理容器集群自动化部署、扩容以及运维的开源平台。作为云原生计算基金会 CNCF(Cloud Native Computing Foundation)最重要的组件之一(CNCF 另一个毕业项目 Prometheus ),它的目标不仅仅是一个编排系统,而是提供一个规范,可以让你来描述集群的架构,定义服务的最终状态,Kubernetes 可以帮你将系统自动地达到和维持在这个状态,Kubernetes 也可以对容器(Docker)进行集群管理和服务编排(Docker Swarm 类似的功能),对于大多开发者来说,以容器的方式运行一个程序是一个最基本的需求,跟多的是 Kubernetes 能够提供路由网关、水平扩展、监控、备份、灾难恢复等一系列运维能力。
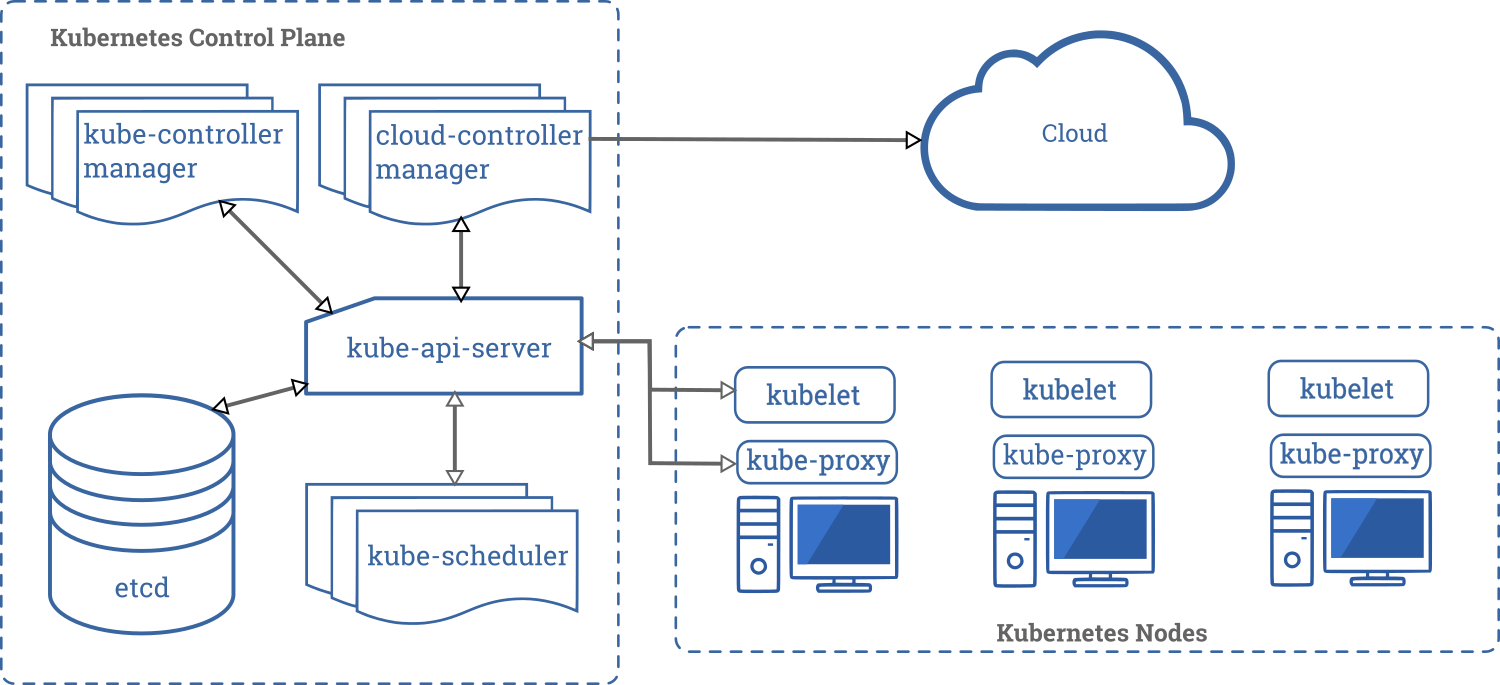
Kubernetes集群由两种角色组成:kube-apiserver集群控制入口, 提供了HTTP Rest接口的关键服务进程,是Kubernetes里所有资源的增删改查等操作的唯一入口, 也是集群控制的入口。- 提供集群管理的 REST API 接口,包括认证授权、数据校验以及集群状态变更等。
- 提供其他模块之间的数据交互和通信的枢纽(其他模块通过 API Server 查询或修改数据,只有 API Server 才直接操作 etcd)
- 提供集群管理的 REST API 接口,包括认证授权、数据校验以及集群状态变更等。
kube-controller-manager服务运行控制器, 处理常规任务的后台线程 比如故障检测、自动扩展、滚动更新等。kube-controller-manager 由一系列的控制器组成包括如下控制器Replication ControllerNode ControllerCronJob ControllerDaemon ControllerDeployment ControllerEndpoint ControllerGarbage CollectorNamespace ControllerJob ControllerPod AutoScalerRelicaSetService ControllerServiceAccount ControllerStatefulSet ControllerVolume ControllerResource quota Controller
kube-scheduler负责 Pod 资源调度。监视新创建没有分配到Node的Pod, 为Pod选择一个Node。调度方式:- 公平调度
- 资源高效利用
- QoS
- affinity 和 anti-affinity (约束)
- 数据本地化(data locality)
- 内部负载干扰(inter-workload interference)
- deadlines
- 公平调度
etcd用于共享配置和服务发现,存储 Kubernetes 集群所有的网络配置和对象的状态信息。
Node 端
kubelet负责 Pod 对应的容器的创建,启动等任务,同时与Master节点密切协作, kubelet 提供了一系列PodSpecs集合规范,并确保这些PodSpecs中描述的容器运行正常。 kubelet是主要的节点代理,它会监视已分配给节点的pod, 具体功能- 安装 Pod 所需的volume。
- 下载 Pod 的Secrets。
- 监控 Pod 中运行的 docker(或experimentally,rkt)容器。
- 定期执行容器健康检查。
- 回传 pod 的状态到其他 kubernetes 服务中。
- 回传 节点 的状态到其他 kubernetes 服务中。
- 安装 Pod 所需的volume。
kube-proxy实现 Kubernetes SVC 的通信与负载均衡机制的重要组件。通过在主机上维护网络规则并执行连接转发来实现Kubernetes服务抽象。
Kubernetes 基本对象与术语
Pod
Pod 是一组紧密关联的容器集合,它们共享
PID、IPC、Network和UTS namespace,是 Kubernetes 调度的基本单位。Pod 的设计理念是支持多个容器在一个 Pod 中共享网络和文件系统,可以通过进程间通信和文件共享这种简单高效的方式组合完成服务。Label
Label 是识别 Kubernetes 对象的标签,以
key/value的方式附加到对象上(key最长不能超过63字节,value 可以为空,也可以是不超过253字节的字符串)。 Label 不提供唯一性,并且实际上经常是很多对象(如 Pods)都使用相同的 label 来标志具体的应用。 Label 定义好后其他对象可以使用 Label Selector 来选择一组相同 label 的对象(比如 Service 用 label 来选择一组 Pod)。Label Selector 支持以下几种方式:Namespace 是对一组资源和对象的抽象集合,比如可以用来将系统内部的对象划分为不同的项目组或用户组。常见的 pods, services, deployments 等都是属于某一个 namespace 的(默认是default),而 Node, PersistentVolumes 等则不属于任何 namespace。
ReplicaSet
ReplicaSet 它的主要作用是确保
Pod以你指定的副本数运行, 如果有容器异常退出, 会自动创建新的Pod来替代, 而异常多出来的容器也会自动回收。 支持集合式的selector。ReplicaSet 可以独立使用, 但建议使用Deployment来自动管理 ReplicaSet, 这样就无需担心跟其他机制的不兼容问题(比如 ReplicaSet 不支持 rolling-update 但 Deployment 支持), 并且Deployment还支持版本记录、回滚、暂停升级等高级特性。Deployment
Deployment 确保任意时间都有指定数量的
Pod在运行。如果为某个Pod创建了 Deployment 并且指定3个副本,它会创建3个 Pod,并且持续监控它们。如果某个 Pod 不响应,那么 Deployment 会替换它,保持总数为3。如果之前不响应的 Pod 恢复了,现在就有4个 Pod 了,那么 Deployment 会将其中一个终止保持总数为3。如果在运行中将副本总数改为5,Deployment 会立刻启动2个新 Pod,保证总数为5。Deployment 还支持回滚和滚动升级。创建 Deployment 需要指定:
StatefulSet 是为了解决有状态服务的问题 (对应 Deployments 和 ReplicaSets是为无状态服务而设计), 其应用场景包括
DaemonSet 保证在每个Node上都运行一个容器副本,常用来部署一些集群的日志、监控或者其他系统管理应用。
Service
Service 是应用服务的抽象,通过 labels 为应用提供负载均衡和服务发现。匹配 labels 的Pod IP 和端口列表组成 endpoints,由 kube-proxy 负责将服务 IP 负载均衡到这些endpoints 上。每个 Service 都会自动分配一个 cluster IP(仅在集群内部可访问的虚拟地址)和 DNS 名,其他容器可以通过该地址或 DNS 来访问服务,而不需要了解后端容器的运行。
Job
Job 负责批量处理短暂的一次性任务 (short lived one-off tasks),即仅执行一次的任务,它保证批处理任务的一个或多个Pod成功结束。
Kubernetes 支持以下几种 Job
CronJob 即定时任务,就类似于 Linux 系统的 crontab,在指定的时间周期运行指定的任务。
Horizontal Pod Autoscaler(HPA)
Horizontal Pod Autoscaling 可以根据 CPU 使用率或应用自定义 metrics 自动扩展 Pod 数量(支持replication controller、deployment和replica set), 从而合理的扩展性能与使用资源。
PersistentVolume (PV)
PersistentVolume(PV)是集群中由管理员配置的一段网络存储。 它是集群中的资源,就像节点是集群资源一样。 PV是容量插件,如Volumes,但其生命周期独立于使用PV的任何单个pod。 此API对象捕获存储实现的详细信息,包括NFS,iSCSI或特定于云提供程序的存储系统。
- PersistentVolume 支持的类型:
- GCEPersistentDisk
- AWSElasticBlockStore
- AzureFile
- AzureDisk
- FC (Fibre Channel)
- Flexvolume
- Flocker
- NFS
- iSCSI
- RBD (Ceph Block Device)
- CephFS
- Cinder (OpenStack block storage)
- Glusterfs
- VsphereVolume
- Quobyte Volumes
- HostPath
- Portworx Volumes
- ScaleIO Volumes
- StorageOS
- GCEPersistentDisk
PersistentVolume 服务状态
PersistentVolumeClaim(PVC)是由用户进行存储的请求。 它类似于pod。 Pod消耗节点资源,PVC消耗PV资源。Pod可以请求特定级别的资源(CPU和内存)。声明可以请求特定的大小和访问模式(例如,可以一次读/写或多次只读)。
- PVC和PV是一一对应的。
- PVC 与 PV 的生命周期
- PV是群集中的资源。PVC是对这些资源的请求,并且还充当对资源的检查。
- PV和PVC之间的相互作用遵循生命周期:
Provisioning——->Binding——–>Using-——>Releasing-——>Recycling
- PV是群集中的资源。PVC是对这些资源的请求,并且还充当对资源的检查。
- Provisioning (准备) 通过集群外的存储系统或者云平台来提供存储持久化支持。
- 静态提供Static:集群管理员创建多个PV。 它们携带可供集群用户使用的真实存储的详细信息。 它们存在于Kubernetes API中,可用于消费。
- 动态提供Dynamic:当管理员创建的静态PV都不匹配用户的PersistentVolumeClaim时,集群可能会尝试为PVC动态配置卷。 此配置基于StorageClasses:PVC必须请求一个类,并且管理员必须已创建并配置该类才能进行动态配置。 要求该类的声明有效地为自己禁用动态配置。
- 静态提供Static:集群管理员创建多个PV。 它们携带可供集群用户使用的真实存储的详细信息。 它们存在于Kubernetes API中,可用于消费。
- Binding (绑定) 用户创建pvc并指定需要的资源和访问模式。在找到可用pv之前,pvc会保持未绑定状态。
- Using (使用) 用户可在pod中像volume一样使用pvc。
- Releasing (释放) 用户删除pvc来回收存储资源,pv将变成”released”状态。由于还保留着之前的数据,这些数据需要根据不同的策略来处理,否则这些存储资源无法被其他pvc使用。
Recycling (回收) pv 可以设置三种回收策略:保留(Retain),回收(Recycle)和删除(Delete)。
StorageClass为管理员提供了一种描述他们提供的存储的”类”的方法。 不同的类可能映射到服务质量级别,或备份策略,或者由群集管理员确定的任意策略。 Kubernetes本身对于什么类别代表是不言而喻的。 这个概念有时在其他存储系统中称为”配置文件”。
Pod 的生命周期
Pod对象自从其创建开始至其终止退出的时间范围称为其生命周期。
- 创建主容器(main container)为
必需的操作。 - 初始化容器(init container)。
- 容器启动后钩子(post start hook)。
- 容器的存活性探测(liveness probe)。
- 就绪性探测(readiness probe)。
- 容器终止前钩子(pre stop hook)
- 其他Pod的定义操作。
- 创建主容器(main container)为
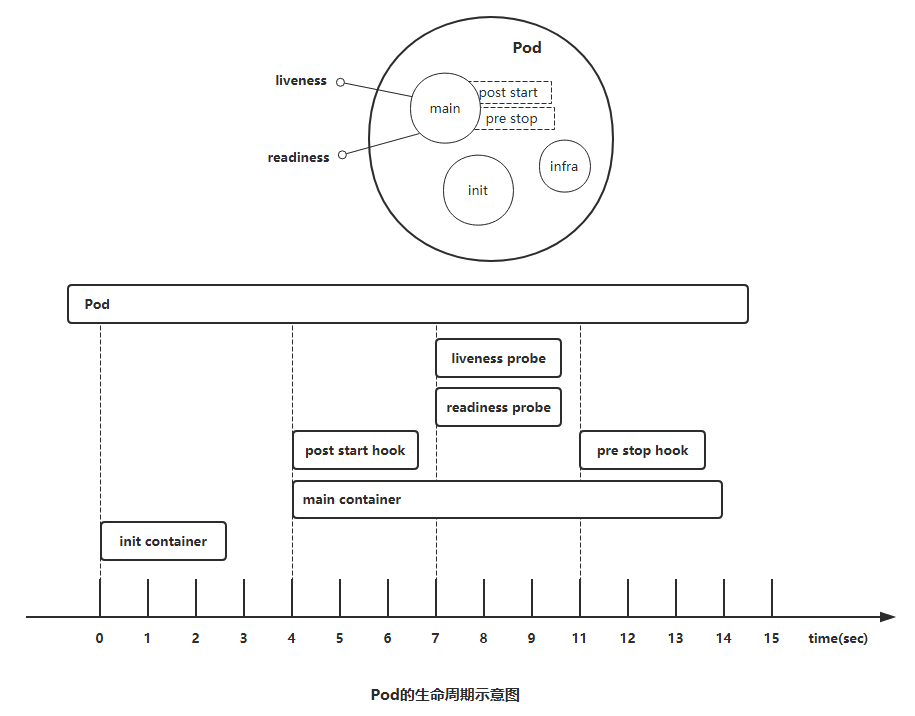
初始化容器(init container)
初始化容器(init container)即应用程序的主容器启动之前要运行的容器,常用于为主容器执行一些预置操作,它们具有两 种典型特征。
Pod 的 status 属性是一个
PodStatus对象,拥有一个 phase 字段。它简单描述了 Pod 在其生命周期的阶段。 | pod phase | 描述 | | :—-: | :—-: | | 挂起(Pending) | kubernetes 通过apiserver创建了pod 资源对象并存入etcd中, 但它尚未被调度完成, 或者仍处于从仓库下载镜像的过程中 | | 运行中(Running) | Pod已经被调度至某节点,并且所有容器都已经被kubelet创建完成,至少一个容器正在运行。 | | 成功(Succeeded) | Pod中的所有容器都已经成功并且不会被重启。 | | 失败(Failed) | Pod中的所有容器都已终止了,并且至少有一个容器是因为失败终止。即容器以非0状态退出或者被系统禁止。 | | 未知(Unknown) |ApiServer无法正常获取到Pod对象的状态信息,通常是由于无法与所在工作节点的kubelet通信所致。 |
Pod conditions
- Pod 的 status 属性是一个
PodStatus对象, 里面包含 PodConditions 数组,代表 Condition 是否通过。 PodCondition 属性描述
| 字段 | 描述 | | :—-: | :—-: | | lastProbeTime | 最后一次探测 Pod Condition 的时间戳。 | | lastTransitionTime | 上次 Condition 从一种状态转换到另一种状态的时间。 | | message | 上次 Condition 状态转换的详细描述。 | | reason | Condition 最后一次转换的原因。 | | status | Condition 状态类型,可以为 True False Unknown | | type | Condition类型(PodScheduled, Ready, Initialized, Unschedulable, ContainersReady) |Condition Type 说明
Probe 是在容器上 kubelet 的定期执行的诊断,kubelet 通过调用容器实现的 Handler 来诊断。
Success容器诊断通过。Failure容器诊断失败。Unknown诊断失败,因此不应采取任何措施。
- Handlers 包含如下三种
ExecAction在容器内部执行指定的命令,如果命令以状态代码 0 退出,则认为诊断成功。TCPSocketAction对指定 IP 和端口的容器执行 TCP 检查,如果端口打开,则认为诊断成功。HTTPGetAction对指定 IP + port + path 路径上的容器的执行 HTTP Get 请求。如果响应的状态代码大于或等于 200 且小于 400,则认为诊断成功。
- kubelet 可以选择性地对运行中的容器进行两种探测器执行和响应。
livenessProbe存活性探测, 探测容器是否正在运行,如果活动探测失败,则 kubelet 会杀死容器,并且容器将受其 重启策略 的约束。如果不指定活动探测, 默认状态是 Success。readinessProbe就绪性探测, 探测容器是否已准备好为请求提供服务,如果准备情况探测失败,则控制器会从与 Pod 匹配的所有服务的端点中删除 Pod 的 IP 地址。初始化延迟之前的默认准备状态是Failure, 如果容器未提供准备情况探测,则默认状态为 Success。
以下为 Nginx 应用的两种探针配置示例
apiVersion: apps/v1kind: Deploymentmetadata:name: nginx-dmspec:replicas: 2selector:matchLabels:name: nginxtemplate:metadata:labels:name: nginxspec:containers:- name: nginximage: nginx:alpineimagePullPolicy: IfNotPresentports:- containerPort: 80name: http# readinessProbe - 检测pod 的 Ready 是否为 truereadinessProbe:tcpSocket:port: 80# 启动后5s 开始检测initialDelaySeconds: 5# 检测 间隔为 10speriodSeconds: 10# livenessProbe - 检测 pod 的 State 是否为 RunninglivenessProbe:httpGet:path: /port: 80# 启动后 15s 开始检测# 检测时间必须在 readinessProbe 之后initialDelaySeconds: 15# 检测 间隔为 20speriodSeconds: 20
Pod RestartPolicy (重启策略)
PodSpec 中有一个
restartPolicy字段,可能的值为Always、OnFailure和Never。默认为Always。restartPolicy适用于Pod中的所有容器。而且它仅用于控制在同一节点上重新启动Pod对象的相关容器。- 首次需要重启的容器,将在其需要时立即进行重启,随后再次需要重启的操作将由kubelet延迟一段时间后进行,且反复的重启操作的延迟时长依次为10秒、20秒、40秒… 300秒是最大延迟时长。
Pod,一旦绑定到一个节点,Pod对象将永远不会被重新绑定到另一个节点,它要么被重启,要么终止,直到节点发生故障或被删除。
Pod 创建过程
创建一个 pod 的过程
- 用户通过kubectl或其他API客户端提交了Pod Spec给API Server。
- API Server尝试着将Pod对象的相关信息存入etcd中,待写入操作执行完成,API Server即会返回确认信息至客户端。
- API Server开始检测etcd中的状态变化。
- 所有的kubernetes组件均使用
watch机制来跟踪检查API Server上的相关的变动。 - kube-scheduler(调度器)通过其
watcher觉察到API Server创建了新的Pod对象但尚未绑定至任何工作节点。 - kube-scheduler(调度器)为Pod对象挑选一个工作节点并将结果信息更新至API Server。
- 调度结果信息由API Server更新至etcd存储系统,而且API Server也开始反映此Pod对象的调度结果。
- Pod被调度到的目标工作节点上的kubelet尝试在当前节点上调用Docker启动容器,并将容器的结果状态返回送至API Server。
- API Server将Pod状态信息存入etcd系统中。
- 在etcd确认写入操作成功完成后,API Server将确认信息发送至相关的kubelet,事件将通过它被接受。
Kubernetes 资源调度与限制
- 用户通过kubectl或其他API客户端提交了Pod Spec给API Server。
在 Kubernetes 体系中,资源默认是被多租户多应用共享使用的,应用与租户间不可避免地存在资源竞争问题。
- 在 Kubernetes 中支持分别从
Namespace、Pod和Container三个级别对资源进行管理。 在 Kubernetes 将 cpu 1 Core (核) = 1000m,
m这个单位表示 千分之一核, 2000m 表示 两个完整的核心, 也可以写成2或者2.0。
ResourceQuota
Namespace级别, 可以通过创建ResourceQuota对象对Namespace进行绑定, 提供一个总体资源使用量限制。- 可以设置该命名空间中 Pod 可以使用到的计算资源(CPU、内存)、存储资源总量上限。
- 可以限制该 Namespace 中某种类型对象(如 Pod、RC、Service、Secret、ConfigMap、PVC 等)的总量上限。
- 可以设置该命名空间中 Pod 可以使用到的计算资源(CPU、内存)、存储资源总量上限。
ResourceQuota 示例
apiVersion: v1kind: ResourceQuotametadata:name: quotaspec:hard:requests.cpu: "20"requests.memory: 30Girequests.storage: 500Girequests.ephemeral-storage: 10Gilimits.cpu: "40"limits.memory: 60Gilimits.ephemeral-storage: 20Gipods: "10"services: "5"replicationcontrollers: "20"resourcequotas: "1"secrets: "10"configmaps: "10"persistentvolumeclaims: "10"services.nodeports: "50"services.loadbalancers: "10"
requestskubernetes会根据Request的值去查找有足够资源的node来调度此pod, 既超过了 Request 限制的值, Pod 将不会被调度到此node中。limits对应资源量的上限, 既最多允许使用这个上限的资源量, 由于cpu是可压缩的, 进程是无法突破上限的, 而memory是不可压缩资源, 当进程试图请求超过limit限制时的memory, 此进程就会被kubernetes杀掉。
LimitRange
LimitRange 对象设置 Namespace 中 Pod 及 Container 的默认资源配额和资源限制。
apiVersion: v1kind: LimitRangemetadata:name: limitspec:limits:- type: Podmax:cpu: "10"memory: 100Gimin:cpu: 200mmemory: 6MimaxLimitRequestRatio:cpu: "2"memory: "4"- type: Containermax:cpu: "2"memory: 1Gimin:cpu: 100mmemory: 3Midefault:cpu: 300mmemory: 200MidefaultRequest:cpu: 200mmemory: 100MimaxLimitRequestRatio:cpu: "2"memory: "4"- type: PersistentVolumeClaimmax:storage: 10Gimin:storage: 5Gi
pod与Container以及pvc类型可分开定义LimitRange分配资源。limits字段下面的default字段表示每个 Pod 的默认的 limits 配置,所以任何没有分配资源的 limits 的 Pod 都会被自动分配 200Mi limits 的内存和 300m limits 的 CPU。defaultRequest字段表示每个 Pod 的默认 requests 配置,所以任何没有分配资源的 requests 的 Pod 都会被自动分配 100Mi requests 的内存和 200m requests 的 CPU。max与min字段分别限制 type 类型下的 服务最大与最小的限制值。
ResourceRequests/ResourceLimits
在 Container 级别可以对两种计算资源进行管理
CPU和内存。ResourceRequests表示容器希望被分配到的可完全保证的资源量,Requests 的值会被提供给 Kubernetes 调度器,以便优化基于资源请求的容器调度。ResourceLimits表示容器能用的资源上限,这个上限的值会影响在节点上发生资源竞争时的解决策略。apiVersion: v1kind: Podmetadata:name: busyboxspec:containers:- name: busyboximage: busyboxresources:requests:memory: "100Mi"cpu: "200m"limits:memory: "200Mi"cpu: "250m"
kubernetes 与 Cgroup
Kubernetes 对内存资源的限制实际上是通过 cgroup 来控制的,cgroup 是容器的一组用来控制内核如何运行进程的相关属性集合。针对内存、CPU 和各种设备都有对应的 cgroup。cgroup 是具有层级的,这意味着每个 cgroup 拥有一个它可以继承属性的父亲,往上一直直到系统启动时创建的 root cgroup。
内存 限制
- Kubernetes 通过 cgroup 和 OOM killer 来限制 Pod 的内存资源,当超过内存限制值以后, Kubernetes 会选择好几个进程作为
OOM killer候选人, 其中最重要的进程是标注为pause的进程, 用来为业务容器创建共享的network和namespace, 其oom_score_adj值为-998,可以确保不被杀死。oom_score_adj值越低就越不容易被杀死, 因为业务容器内pause之外的所有其他进程的oom_score_adj值都相同,所以谁的内存使用量最多,oom_score值就越高,也就越容易被杀死。
- Kubernetes 通过 cgroup 和 OOM killer 来限制 Pod 的内存资源,当超过内存限制值以后, Kubernetes 会选择好几个进程作为
- CPU 限制
- 在 Kubernetes 中设置的 cpu requests 最终会被 cgroup 设置为
cpu.shares属性的值, cpu limits 会被带宽控制组设置为cpu.cfs_period_us和cpu.cfs_quota_us属性的值。与内存一样,cpu requests 主要用于在调度时通知调度器节点上至少需要多少个 cpu shares 才可以被调度。 - cpu requests 与 内存 requests 不同,设置了 cpu requests 会在 cgroup 中设置一个属性,以确保内核会将该数量的 shares 分配给进程。
- cpu limits 与 内存 limits 也有所不同。如果容器进程使用的内存资源超过了内存使用限制,那么该进程将会成为 oom-killing 的候选者。但是容器进程基本上永远不能超过设置的 CPU 配额,所以容器永远不会因为尝试使用比分配的更多的 CPU 时间而被驱逐。系统会在调度程序中强制进行 CPU 资源限制,以确保进程不会超过这个限制。
- 在 Kubernetes 中设置的 cpu requests 最终会被 cgroup 设置为

若有收获,就点个赞吧
0 人点赞
