基于云原生的事件总线框架实践
摘要
事件驱动架构可以给企业支撑提供灵活的系统,减少对通信成本、网络带宽、及智能体自身能量等有限资源的不必要的浪费能够适应变化并实时做出决策。事件在其事件源(如物联网(IoT)设备、应用和网络)发生时即被捕获,因此事件的发布者和事件的订阅者可以实时共享一致性的状态和信息的响应。企业通过为自己的系统和应用添加事件驱动架构,可以显著提高应用的可扩展性和响应能力,同时获取改善业务决策所需的数据和环境。
本文讨论了现有事件驱动架构下的程序,并指出程序使用事件驱动的好处。同时归类分析了现有事件总线的特点,讨论事件驱动下的发布订阅框架的重要性并对事件总线进行深刻的研究。根据其重要性和软件、厂商强绑定的原因,提出了云厂商无关的消息总线底层依赖架构,给出了相关的问题和实验解决方法。最后能够通过一个云厂商无关的框架和市面上主流的消息总线兼容的驱动接口设计,实现指导云原生的事件总线构建的过程。
关键词:云原生;发布订阅;云事件总线;事件驱动;微服务
A CLOUD BASE EVENT BUS FRAMEWORK
Abstract
Event-driven architecture can provide a flexible system for enterprise support, reduce unnecessary waste of limited resources such as communication costs, network bandwidth, and the energy of the agent itself, adapt to changes and make real-time decisions. Events are captured when their event sources (such as Internet of Things (IoT) devices, applications, and networks) occur, so event publishers and event subscribers can share consistent status and information responses in real time. By adding event-driven architecture to their own systems and applications, enterprises can significantly improve the scalability and responsiveness of applications, while obtaining the data and environment needed to improve business decision-making.
This article discusses programs under the existing event-driven architecture and points out the benefits of using event-driven programs. At the same time, it classifies and analyzes the characteristics of the existing event bus, discusses the importance of the event-driven publish and subscribe framework, and conducts a deep research on the event bus. According to its importance and the reasons for the strong binding of software and vendors, the underlying dependency architecture of the message bus independent of cloud vendors is proposed, and related problems and experimental solutions are given. Finally, the process of guiding cloud-native event bus construction can be realized through a driver interface design compatible with a cloud vendor-independent framework and the mainstream message bus on the market.
Keywords: Cloud Native; PubSub; Eventbus; event-driven; microservice
目 录
摘要
Abstract
1绪论
1.1课题研究背景及意义
1.1.1事件驱动架构
1.1.2事件总线
1.1.3意义
1.2课题现状
1.2.1事件总线模型
1.2.2典型代表
1.2.3问题现状与评述
1.3研究内容
1.4论文结构
2主要需求分析
2.1传统架构的困难
调用链条过长:
耦合性太高:
无法应对突发流量:
2.2消息队列的问题
重复消息问题
数据一致性问题
消息丢失问题
消息顺序问题
消息堆积
系统复杂度提升
2.3底层无关的事件总线框架
3技术选型及相关知识简介
3.1 整体概况
3.2 Golang语言
3.3 消息总线依赖及分析
3.3.1 NATS
3.4容器技术
4本章小结
4功能分析详述
4.1插件式
4.2幂等性
4.3批处理
4.4异步进行
4.5高并发
4.6 ACK 机制
4.7顺序机制
4.8中间件机制
4.9方便的过滤器
4.10配置化
4.11云事件格式
5主要功能模块的实现
5.1调度器实现
5.2批处理器实现
5.3驱动管理实现
驱动接口
驱动注册机制
驱动连接池管理
5.4驱动接口实现
6总结与展望
6.1总结
6.2展望
参考文献
致谢
1绪论
1.1课题研究背景及意义
1.1.1事件驱动架构
“为了减少对网络带宽、通信成本及智能体自身能量等有限资源的不必要的浪费,近些年来,基于事件驱动机制的协调控制的问题受到大量学者的关注[1]。”事件驱动架构是一种用于设计应用的软件架构和模型。对于事件驱动系统而言,事件的捕获、通信、处理和持久保留是解决方案的核心结构。这和传统的请求驱动模型有很大不同。许多现代应用都采用了事件驱动设计。事件驱动应用可以用任何一种编程语言来创建,因为事件驱动本身是一种编程方法,而不是一种编程语言。事件驱动架构可以最大程度减少耦合度,因此是现代化分布式应用架构的理想之选。事件驱动架构采用松散耦合方式,因为事件发起者并不知道哪个事件使用者在监听事件,而且事件也不知道其所产生的后续结果。
1.1.2事件总线
事件总线,又称为 Event-Bus,在不同程序、代码中实现基于事件的通信,使用事件协调多个软件服务在计算机历史上的实践有很长的时间,不仅在硬件上,在操作系统等软件,新兴的云原生程序中上也都有应用。在硬件上,永远不变的主题有这么一个:计算机的组成包括:运算器,控制器,存储器,输入和输出设备。但是这五部分的通信方式只是一个:总线(Bus);在操作系统等知名软件上的使用则是缓冲区、消息队列;在云原生程序中,则是与程序本身无关的云总线。在事件驱动架构下,无论软件是读取还是写入数据,软件都不需要关心作用客体的具体信息。这个优势在现代软件、网络中尤其重要,在实际使用网络通信时,是由通信发起终端与通信接收终端互发信号,存在通信复杂度与设备数的平方关系[2](图1-1)。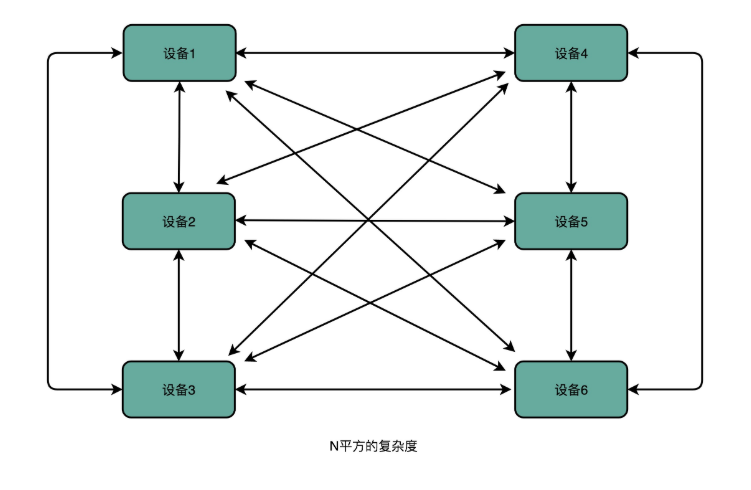
图1-1通信复杂度的N平方关系
可以预见在未来的网络通信中的终端数量大量增加的同时,通信复杂度会增长到物理资源无法支撑的强度,总线自然成为了该项问题的解决方案,而最终目的就是解耦。事件的发起者(即原通信发起终端)会检测或感知事件,并以消息的形式来表示事件。它并不知道事件的使用者或事件引起的结果。检测到事件后,系统会通过事件通道从事件发起者传输给事件使用者,而事件处理平台则会在该通道中以异步方式处理事件。事件发生时,需要通知事件使用者(即原通信接收终端)。他们可能会处理事件,也可能只是受事件的影响。事件处理平台将对事件做出正确响应,并将活动下发给相应的事件使用者。通过这种下发活动,我们就可以看到事件的结果。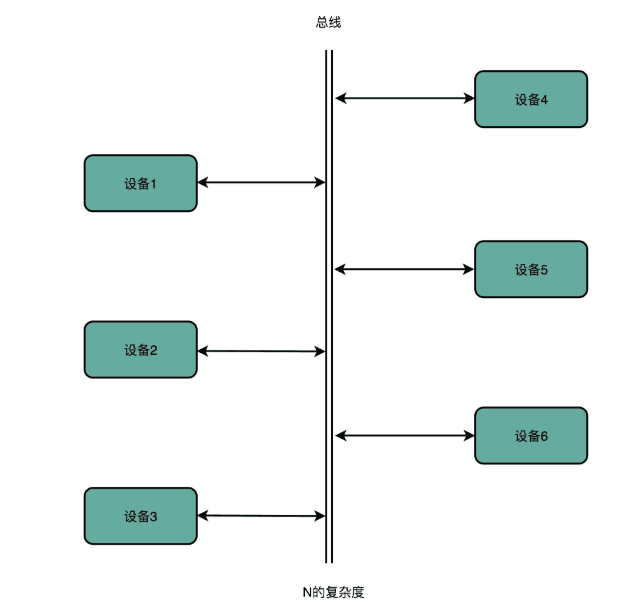
图1-2 总线下的线性关系
1.1.3意义
正如Gartner公司在2017年8月发布的题为《数字化业务中的业务事件、业务时刻和事件思维》的报告中所说,“参与数字化转型举措的应用领导者必须在技术、组织和文化战略中加入‘事件思维’”以实现事件驱动微服务的敏捷性。”事件驱动架构在整个软件领域的应用势在必行,选择合适的事件/消息平台是实现现代互联网技术的巨大优势的道路上最关键的步骤之一。基于云的事件总线在各大云厂商(Google、阿里、华为等)中都已有实例。业界在底层事件总线无关的事件驱动的框架领域也有研究。事件总线区别于调用式的编程,最大限度减少系统间的硬性依赖。如何探索这样的框架是否能成为通用云原生编程泛型,找到未来的事件驱动场景(如混合云和物联网云、边、端架构)[3],去使用事件驱动的框架进行消息传递将是云原生情况下的必然要求。
1.2课题现状
1.2.1事件总线模型
事件总线(Event-Bus)及其演进过程可分为内存模型、传统的队列模型、发布-订阅模型。
内存模型:进程内模型,事件总线(Event-Bus)在内部遍历消费者(Consumer)列表传递数据[4];如果希望在消费者(Consumer)执行程序中进行一次进行其他消息服务调用,则需要添加和实现一个新的 MessageService , 并添加对于(Event-Bus)依赖。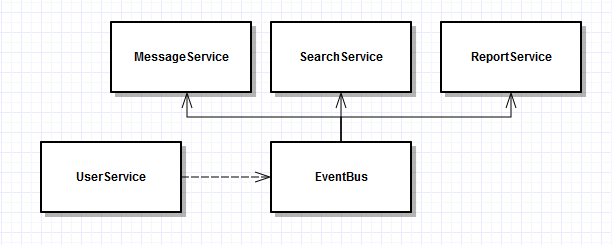
图1-3对Event-Bus的依赖
队列模型:消息或事件持久化到传统消息队列(Queue)即返回,以实时性降低换取吞吐能力提升;
在内存模型的场景中,业务需要由异步进程处理。从MSMQ到各种第3方实现方案众多,但真实业务中事件循环存在如下问题:
异常处理:消息处理中发生异常,但短时间内重试无法解决问题;
多消费者:多个消费程序可能监听相同队列;
异常的常规处理是使用监听时间依次延长的多个异常队列,定时检查并出队处理;多消费者问题由于传统队列出队即消息的特性,意味着必须在数据写多份大家各自消费和消费者集中管理遍历调用中选择一个方法。
图1-4 Queue与Event-Bus协同工作
发布-订阅模型[5]:事件源(EventSource)得到强化,之前诸多的问题由如分布式、持久化、消费复制/分区等特性提供了解决方案,使用宿主代为监听列队和消息分发、插件式寄宿消费程序,使消费者可以专注于业务。下图以云原生的Pulsar为例: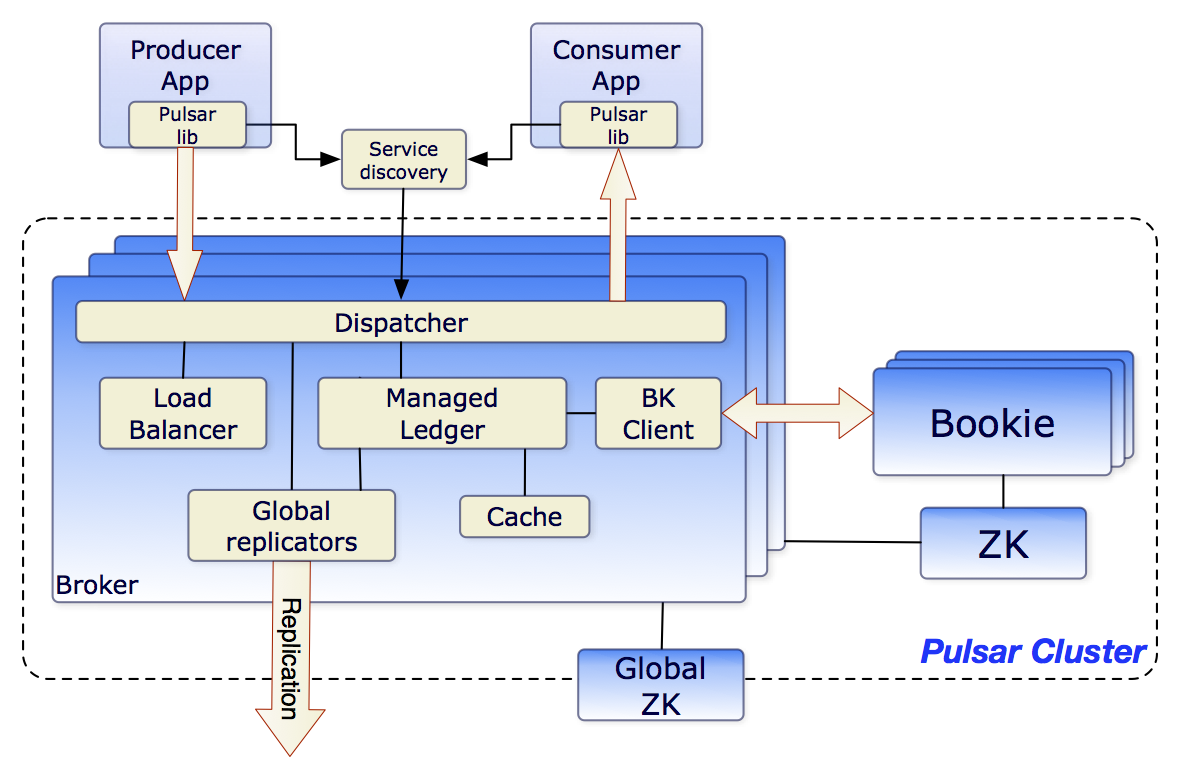
图1-5发布订阅模式下的总线多功能架构
同时,引用业界广为人知的Kafka的大量特性,解释上述相关问题:
Kafka 基于文件系统,消息移除是基于时间和磁盘的策略,不会轻易丢失数据,也不用担心消费者出现异常;
Kafka 将 Consumer 的当前位置的管理职责交由消费者负责,通过提供可选的 Offset Commit 和 Offset Fetch API,使用合适的 Offset 策略,可以从任何位置开始消费,没有重复消费限制;
Kafka 提供了 Topic Partition + Consumer Group 并定义了发布-订阅语义,可以配合堵塞式 API 保障消息处理的低延迟。
1.2.2典型代表
事件总线的典型代表有很多,从硬件总线到消息队列,比如pulsar、kafka、阿里的 RocketMQ,甚至我们常见的数据库如 Redis(Pub/Sub模式),MySQL。由于能够支持Pub/Sub模式,都可以作为事件总线来进行使用。
计算机硬件中的总线架构:在CPU与主存储器之间、CPU与I/O设备之间分别设置了总线,从而提高了微机系统信息传送的速率和效率。在硬件中的总线最大的问题通常是速度、带宽不足,从 ISA 总线(Industry Standard Architecture)到PCI总线(Peripheral Component Interconnect)到AGP总线(Accelerated Graphics Port)到 PCI-Express,经过了数十年的修补和更新,主要解决问题还是高速传输[6]。包括常见的 USB(Universal Serial Bus)实际上也分属外部总线类,指缆线和连接器系统,用来传输I/O路径技术指定的数据和控制信号,大量外部设备均采用此总线。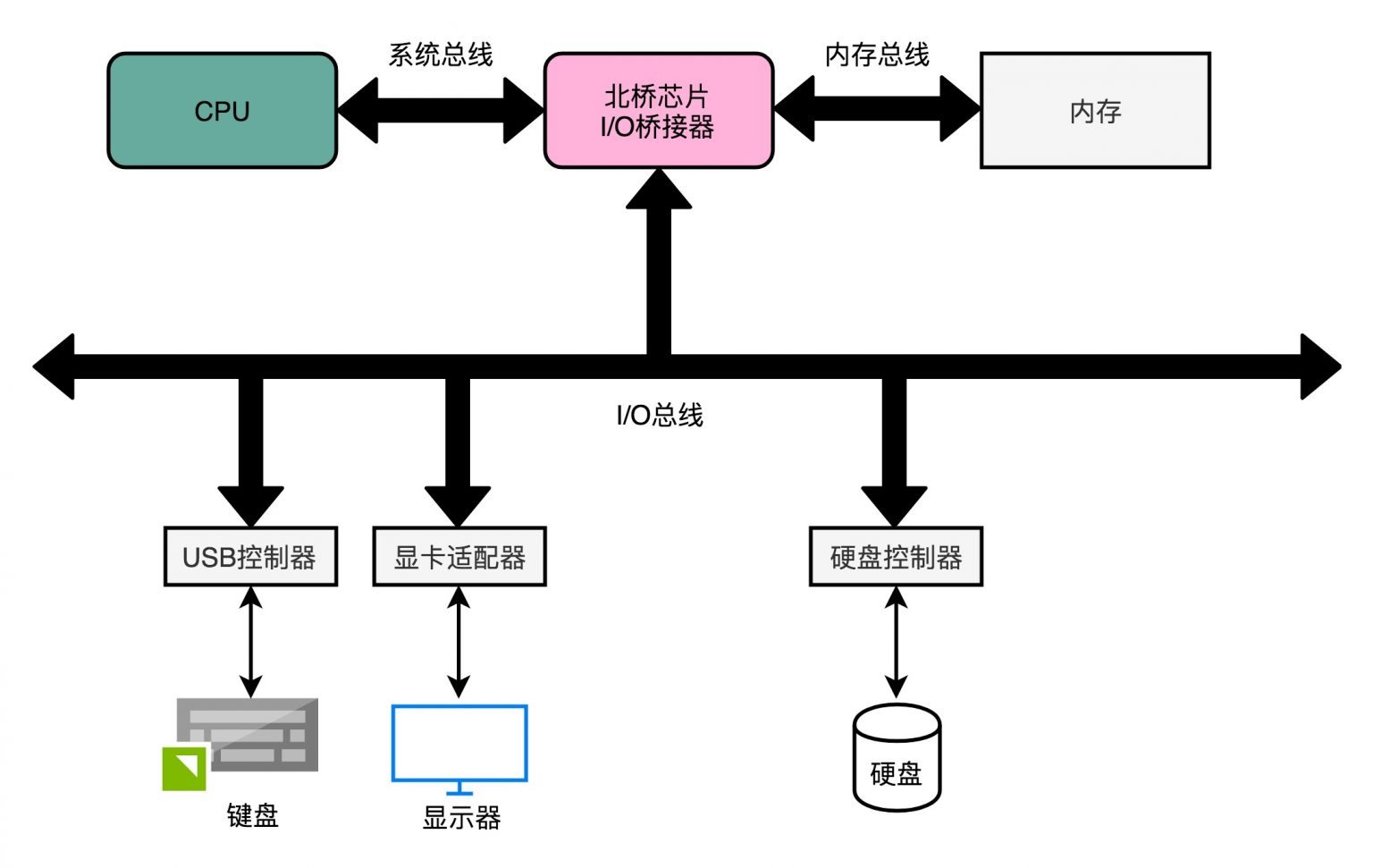
图1-6 计算机中的总线
在Apache基金会中有很多用于事件处理的相关开源软件,甚至有一些是云原生的。ApacheKafka是一种分布式数据流平台,也是事件处理的常见之选。它可以实时进行事件流的发布、订阅、存储和处理。ApacheKafka支持需要高吞吐量和可扩展性的用例,同时,通过最大程度减少某些应用中对数据共享的点对点集成需求,它可以将延迟降至毫秒级。软件的消息总线通常为下图1-4功能。

图1-7 依赖消息队列的总线通信
1.2.3问题现状与评述
1. 函数调用模型
通常情况下程序都是通过直接函数调用进行通信,当他们调用一个函数的时候,跳转到指定函数的地址上,并进行这一个函数的执行,直接函数调用存在语言限制的问题,一个语言很难去调用另一个语言的函数,即使有很多变通的技术如 DDL(Dynamic Linkable Library)动态链接库、FFI(Foreign Function Interface)外部函数调用接口编译其他语言函数库供调用,也引入了极大的复杂性,同时由于程序不再受编译器支持保证,也会出现非常多的运行时错误(Runtime Error)。而在云原生时代中广为人知的微服务中,其通信协议则主要是RPC(Remote Procedure Call Protocol)远程过程调用协议:一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议[7]。典型的RPC框架包括JAVA RMI、GRPC、Thrift、Hetty、Dubbo和一些其他框架,通常RPC框架和直接函数调用一样,受到语言的限制,但在设计上如GRPC等是支持语言无关的函数调用的,即牺牲一部分性能,使用统一且尽量高效的编码工具来完成函数调用。这也是RPC中最重要的协议部分。而在发布订阅(Pub/Sub)通信模式中,一些限制天然不存在,消息的格式任由发布者和订阅者选择即可。以事件的形式封装消息,是一个天然的语言无关且高度解耦的通信系统。
Heroku(HeroKu于2009年推出公有云PaaS)于2012年提出12因素,告诉开发者如何利用云平台提供的便利来开发更具可靠性和扩展性、更加易于维护的云原生应用。其中“和底层操作系统保持简洁的契约。”“在各个系统中提供最大的可移植性。”两句非常符合发布订阅模式的特性。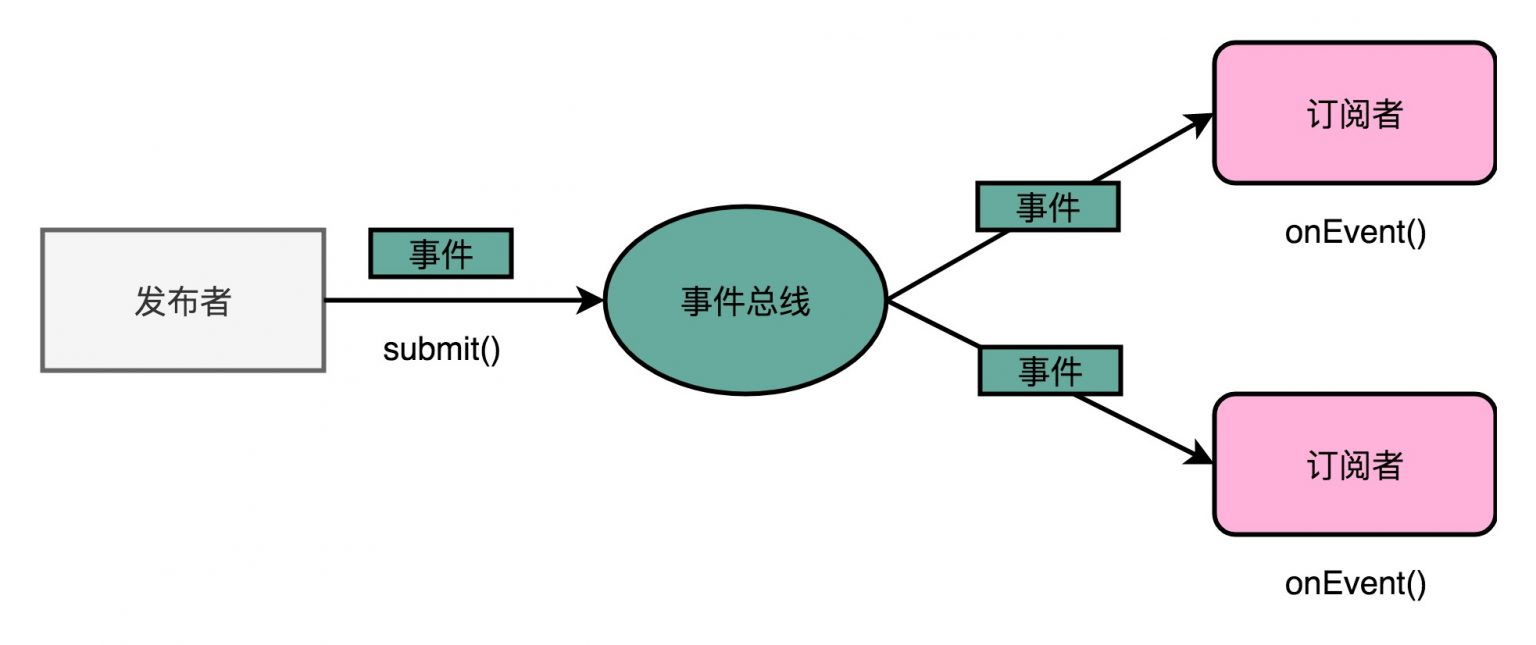
图1-8 发布订阅(Pub/Sub)模式
2. 事件驱动的思维和服务执行的编排。
采纳事件驱动思维的第一步是改变对设计和架构解决方案的思维方式。初识的倾向是将服务之间的所有交互视为请求/回复服务调用序列的一系列。使用“调用/invoking”、”请求/requesting”或“调用/calling”等术语,表明仍然在用命令式的思维模式来思考。相反,”服务应该处理哪些事件?”和“服务应该发送哪些事件?”才是采用了事件驱动的思维,需要实现从编排(orchestration)到协调(choreography)的转变。
架构师通常会从“服务A调用服务B,而服务B调用服务C“的角度来思考,然后通过调用链(a->b->c)或通过创建一个编排器服务来实现该模型,例如x->a,然后x->b,然后x->c。当分布式计算的现实出现时,这两种方法都会造成混乱,特别是当你开始扩展时。
另一种选择是遵循协调的哲学,这样做的好处是巨大的。
更加敏捷。敏捷开发团队将会更加独立,受其他服务的变化影响明显变小。
服务更小/更简单。每个服务不需要对下游服务或网络故障进行复杂的错误处理。
服务耦合性较小。不知道其他服务的存在。
实现细粒度的伸缩性。每项服务都可以根据需求独立地伸缩。这样既保证了良好的用户体验,又减少了计算资源的浪费。
易于添加新服务。由于耦合较少,一个新的服务可以上线、消费事件和实现新的功能,而不需要改变任何其他服务。
那么,状态的一致性就成为了需要关注的领域,因为一个被暂时宕机的服务意味着事件状态的变化可能无法立即处理。从根本上说,应该如何处理这种负面效应?
3. 业界解决方案。
l 拥抱最终一致性。
最终的一致性是指一致性会在未来达成的想法,这意味着需要接受软件数据在多个端点之间可能会在一段时间内不同步。这是一种模式和概念可以将昂贵的XA事务从mix中去除。事件/消息平台的工作是确保这些领域变更事件在被服务适当处理并承认之前永远不会丢失。众所周知最终一致性的好处是性能,但真正的好处是微服务的解耦,这是因为单个服务仅仅是对它们感兴趣的事件采取行动。
l 数据库+CQRS。
关于使用事件的思考过程,通常会引出一个有趣的问题。要把这些事件持久化到哪里去?数据库是命令式(Create、Read、Update、Delete)的交互。数据库的困境是极其有趣的,使用一种叫做命令查询责任隔离(CommandQueryResponsibilitySegregation/CQRS)的模式可以提供很大的好处。CQRS不是一个架构;它是一个简单的模式,可以帮助实现事件驱动架构,最终,对于大多数情况下,这个地方将是一个数据库。
以一个银行账户业务服务用例为例,来探讨一下CQRS的作用。通常,我们会有一个Account服务来处理所有的账户交互。我们定义API如下:
AccountService
{
Public void createAccount(name)
Public Account getAccount(name)
Public void debitAccount(name,amount)
Public void creditAccount(name,amount)
Public AccountList getInactiveAccounts()
Public AccountList getOverdrawnAccounts()
}
CQRS模式简单地将这个单一的服务分成两个不同的独立的可扩展服务:
AccountChangeService
{
Public void createAccount(name,acctMetadata)
Public void debitAccount(name,amount)
Public void creditAccount(name,amount)
}
和
AccountReaderService
{
Public Account getAccount(name)
Public AccountList getInactiveAccounts()
Public AccountList getOverdrawnAccounts()
}
命令和查询的执行从根本上来说是不同的。例如,命令和查询总是以不同的方式伸缩,因为他们的调用频率不同,另外他们也会导致不同的结果,如查询不会改变任何数据的状态,而命令会。当我们把事件驱动的架构和简单的CQRS模式结合起来,会有以下好处。
通常情况下,使用数据库会先进行数据设计和数据模型设计。该设计中的决策会影响到所有的上游服务和处理流程,因为它必须在数据模型的约束下工作。这种思维将数据直接放在架构的中心位置,而不是事件。
而把命令操作,如创建、更新和删除等命令操作从查询中分离出来,那么基本上就可以把改变领域状态的事件(DDD/领域驱动设计)和不改变域状态的查询分离出来。这种情况下,事件是架构的重点,也是最自然的领域建模方式。
好处包括:可以将这些领域变化事件推送到新的微服务中(意味着可以增加新的功能和特性而没有较多的负担和开销),或者用于使用大数据处理体系,用于进行分析并来进行新的发现。
继续用银行系统举例,假设一个活动功能:用于银行信用卡营销。使用EDA和CQRS可以很容易地为消费账户创建事件,并根据accountMetadata(如开户余额、地址、工作等)向新客户营销银行信用卡。当然,引入CQRS确实牺牲了一致性,但考虑得到的性能和可用性提升也就可以理解了。同时,正如前面提到的,使用最终的一致性模式为大多数用例让这些权衡更容易接受。。
l 解决现有旧软件的方式-集成事件驱动架构。
在企业中有着大量的事件和数据存储。新理念对于已经是事件驱动的系统和设备来说是非常明确的,然而对于以数据库为中心的系统就有所不同。
帮助微服务与以数据为中心的传统系统共存的一种方法是在底层数据库上实现变更数据捕获(changedatacapture/CDC)。这种技术在Oracle数据库中的一个例子是利用CDC工具GoldenGate。当事件发生时,它们被写入数据库。通过捕获这些变化并将其作为事件处理,可以在微服务平台中利用它们。这消除了对现有系统的任何影响,也消除了对昂贵代码的修改需求。这里的大部分工作是将CDC事件转化为领域数据结构。整合现代系统和设备就更容易了。例如,IoT设备本来就是事件驱动的,社交媒体平台是支持流的,甚至许多JEE应用都利用了消息驱动的Bean(MDB),这些都很容易被利用。
l 作为DR基石的事件。
在事件驱动微服务中,事件可以很容易地复制到其他活动或灾难恢复站点,因此系统始终处于同步状态,随时准备采取行动。从历史上看,这是在数据存储层面完成的,每个数据库类型都使用自己的复制机制。由于涉及到许多组件和不同的策略,非常复杂,也非常昂贵,因为在许多情况下,同一事件被存储在多个地点。围绕事件而不是数据来设计系统的一个很大的边际效应就是让业务能够在可能发生灾难性的情况下继续执行,就像什么都没发生过一样。
l 使用与供应商无关的标准API或协议来处理事件[9]。
利用云提供商的事件/消息产品如AWS的SQS/SNS、谷歌云Pub/Sub、AzureServiceBus等,或者专有事件传输解决方案如ApacheKafka、IBMM和TIBCOEMS,似乎很有吸引力。但这种方法存在着多种问题:
锁定:当由于技术或业务原因想离开这个解决方案时,问题就会出现。这需要大量的投资来撤销这个错误,因为几乎所有的服务和业务都是如此。集成受影响。
缺少API:微服务的一个主要优点是它不规定使用什么编程语言,专有的API通常只支持一小部分语言,因此限制了灵活性和选择。
抑制创新:微服务的另一个好处是随着行业和产品的发展而使用新技术和新工艺的能力。由于转换成本太高,被锁定在一个供应商的专有API中,可能意味着使用者被锁定在创新之外。就像使用单体应用的问题一样。
当选择事件/消息平台的实现时,重要的是确保它支持标准API,如Spring、JMS、NMS、Paho和Qpid,如MQTT和AMQEPv1.0。
l 抛弃API网关。
最后,API管理/网关解决方案根本就不适合于事件驱动的微服务[10]。有7个原因:
• 缺少现代化:消息本身已经存在了很长时间。15年前,还没有敏捷开发–瀑布流统治了整个时代,消息基础设施由专门的团队管理。现在,DevOps的概念及其相关的敏捷性意味着开发人员不能等待消息基础设施的安装、配置和数据变得可用。一切都必须自动化、DevOps友好和自服务。这意味着,虽然消息是正确的工具,但这些工具已经不能满足今天的敏捷需要和需求。这一点被微服务架构承诺的速度、规模和敏捷性放大了。
• 高且不可预测的延迟:随着单体应用被分解成离散的服务,有一个点:延迟会增加,性能会降低,影响用户体验和满足SLA的能力。事件/消息平台需要尽可能的低延迟,这直接影响到最终实施的成功与否。当这种情况发生时,初始的反应是反其道而行之,构建更大的、更单一的、可重用性更低的敏捷服务,以减少网络跳转,从而减少延迟。这一步完全取消了微服务的众多好处,但在许多情况下,企业由于专有的API和线路的原因被锁定,因此走的是阻力最小的道路。
• 专有协议和API:IBM、TIBCO和其他企业消息公司都实施了自己的协议。因为担心开放的标准会增加竞争,并使他们的客户很容易放弃他们的产品,因为竞争者提供创新和差异化的产品。大多数厂商最多只实现了单一标准的线路或开放的API,从而限制了可以实现微服务的语言,并排除了更大的事件生态系统,例如IoT设备的事件。这降低了微服务提供的整体价值和敏捷性,并导致了旨在统一数据移动的集成片。
• 稳定性差:没有任何服务能实现100%的可用性,没有任何系统会在任何时候都能完美运行。服务内的Bug、网络中断和有害信息都是如何拖慢服务或给微服务生态系统带来负担的真实例子。当这些异常事件发生时,只能期望基础服务,如消息等,能经受住风暴的考验,缓冲请求,确保数据不丢失。事实证明,在这些场景发生之前,许多消息系统都能很好地工作。然而在最需要它们的时候却总是会让人失望。
• 可部署性风险:云提供商都有消息/事件平台,而这些平台无法部署到竞争对手的云上,也无法部署到许多企业维护核心业务功能的场所。传统的消息系统不能轻易地部署到云环境中,有的根本无法部署到云环境中,因为它们使用的是多播系统。鉴于当今云战略不断发展的趋势,部署性是一个重要的考虑因素。当决定转向混合和/或多云架构时,迁移具有巨大困难。
• 广域网的弱点:混合云和多云架构的使用极为普遍,无论从经济性还是业务连续性来说,都是非常普遍的。所有这些策略都要求事件以可靠、安全和性能良好的方式在广域网上传播。由于传统的消息产品最初是在数据中心环境中使用的,因此它们对抖动和往返时间慢等常见的广域网属性响应较差。
• API管理/网关即错的工具。API管理/网关领域正在蓬勃发展。这个组件是必要的,因为在许多情况下,B2B和Web应用需要使用REST/HTTP等Web友好的API进行集成。这些交互,其中代表领域变化事件的交互必须快速转化为事件,以便于下游处理。API管理和网关根本没有尝试在微服务之间启用事件驱动的交互,也没有启用多种异步协议将事件流转到Web应用中。
1.3研究内容
上文中描述事件驱动架构下的程序会遇到的问题并进行分析给出了解决方案,这些都需要最后落实在事件总线框架上。事件总线本身需要达到这一个发布订阅的最基础的这个通信模式,然后需要对事件做一些质量保证,如保证只有一次需要消费,或者最终一定能到达,在上述最后两个问题中,继续提到了云供应商无关的标准和协议,所以云事件总线的进一步需求则是云厂商无关,不会因为使用特定的某一家消息队列或者事件总线就绑定于该语言或云厂商。故本文研究内容主要包括以下两点:
本文分析在现代互联网及物联网背景下如何应对端点通信的问题,提出事件总线的消息调度控制模型,使用云原生技术作为多节点、端点间协同控制手段。提出事件总线必要的功能和面临的问题,针对问题选择业界已有的消息队列功能解决方案作为参照实现,选择如 Kafka,RocketMQ等优秀开源项目进行分析,利用Golang语言作为云原生语言的特性,快速搭建具有对应功能的原型软件。设计了具有高度可扩展性接口的发布订阅系统并实现诸如 QoS,分布式等功能,测试了事件总线必需的功能及性能瓶颈。
云事件总线的设计方案中,不仅要考虑这些相关的质量保证及最基础的功能,同时需要有一个插件化的云事件,需要一个驱动框架进行总线底层依赖驱动的配置。本文提出了云事件总线的概念,以底层消息队列实现无关的思想,完成了驱动框架的设计,使用Golang的接口机制,将消息队列接口实现转移到框架外部,通过接口的方式完成实际运行时底层消息总线依赖的解耦,同时提出对应 API 的语义思考,针对不同类别的消息总线提供的不同功能,以通信的方式告知发布者和订阅者,实现高度兼容的驱动框架设计,为实际应用的可行性、容错性做出了验证。最后论述了云事件总线的实际应用场景,并对其不同场景进行了研究,针对不同的场景论述注重的功能并改善了相关的设计。
1.4论文结构
根据所要研究的主要内容,全文共分为六章,主要内容如下:
第 1 章,绪论:介绍事件驱动架构,事件总线的背景,组织了相关文献对当前程序的通信模式做出整体概述,论述了事件总线架构下的一些实现实例。说明了本文的工作安排。
第 2 章:介绍了传统软件中遇到的痛点,并解释了事件总线对应的问题和解决方案,包括Pub/Sub通信模式,数据持久化、消息分区等技术,指出云原生事件总线如何结合对应技术应对程序通信问题,并提出了插件式云事件总线的原型。
第 3 章:首先介绍了技术选型的整体概况,然后对使用的技术相关知识进行简要介绍,对使用技术的优势进行了详细分析。
第 4 章:提出来云事件总线原型的功能需求及其详述分析,展示了不同功能的使用场景并对其存在的问题和优势做出总结。
第 5 章:对本文提出的原型完成代码实现,分模块详述设计思路并针对对应问题验证解决方案。
第 6 章,结论与展望:对本课题所完成的工作进行总结,并针对当前的不足对将来工作做出展望。
2主要需求分析
2.1传统架构的困难
在传统软件架构中,存在以下情况,而对于传统模式的下列问题,都可以通过引入Message Queue解决。
调用链条过长:
有些复杂的业务系统,一次用户请求可能会同步调用N个系统的接口,需要等待所有的接口都返回了,才能真正的获取执行结果。这种同步接口调用的方式总耗时比较长,非常影响用户的体验,特别是在网络不稳定的情况下,极容易出现接口超时问题[11]。

图2-1长链条调用
同步接口调用导致响应时间长的问题,使用Message Queue之后,将同步调用改成异步,能够显著减少系统响应时间。系统A作为消息的生产者,在完成本职工作后,就能直接返回结果了。而无需等待消息消费者的返回,它们最终会独立完成所有的业务功能。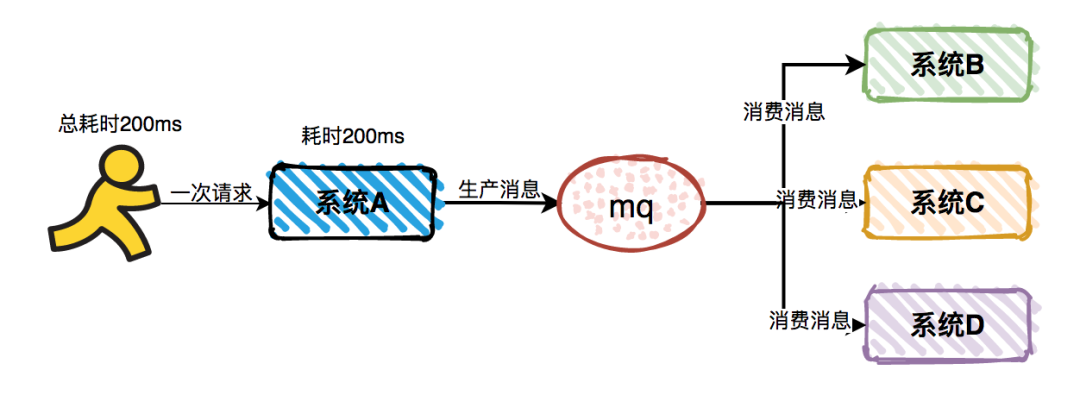
图2-2异步消息调用
这样能避免总耗时比较长,从而影响用户的体验的问题。
耦合性太高:
很多复杂的业务系统,一般都会拆分成多个子系统。我们在这里以用户下单为例,请求会先通过订单系统,然后分别调用:支付系统、库存系统、积分系统和物流系统。系统之间耦合性太高,如果调用的任何一个子系统出现异常,整个请求都会异常,对系统的稳定性非常不利。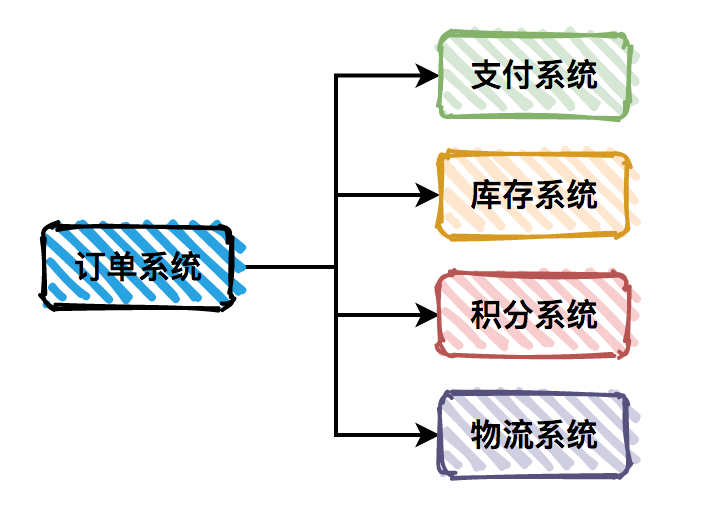
图2-3耦合系统模式
子系统间耦合性太大的问题,使用Message Queue之后,我们只需要依赖于Message Queue,避免了各个子系统间的强依赖问题。订单系统作为消息生产者,保证它自己没有异常即可,不会受到支付系统等业务子系统的异常影响,并且各个消费者业务子系统之间,也互不影响[12]。
这样就把之前复杂的业务子系统的依赖关系,转换为只依赖于Message Queue的简单依赖,从而显著的降低了系统间的耦合度。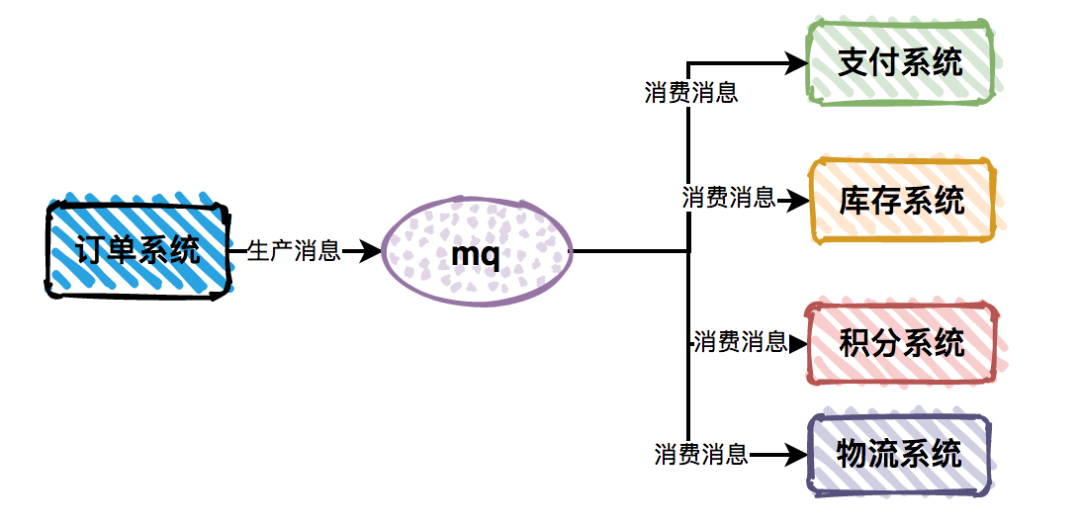
图2-4消息队列解耦的系统
无法应对突发流量:
互联网应用常常有突发活动,比如电商的秒杀等。用户量少的情况下,突发流量不会超过系统承载能力上限,不会影响系统的稳定性。但是如果用户突增,在短时间将所有的请求都打到数据库,视数据库承受能力,会响应变慢甚至直接挂掉,这对于要求高可用的计算机软件来说是不能接受的。对于这种突然出现的请求峰值,传统的软件模式便无法保证系统的稳定性。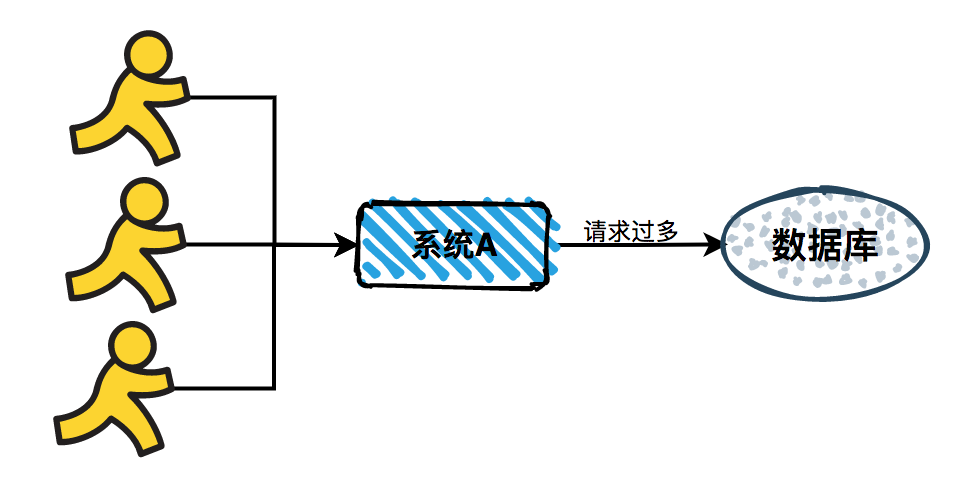
图2-5同时大量请求
由于突然出现的请求峰值,导致系统不稳定的问题。使用Message Queue后,能够起到消峰的作用。订单系统接收到用户请求之后,将请求直接发送到Message Queue,然后订单消费者从Message Queue中消费消息,做写库操作。如果出现请求峰值的情况,由于消费者的消费能力有限,会按照自己的节奏来消费消息,多的请求不处理,保留在Message Queue的队列中,不会对系统的稳定性造成影响。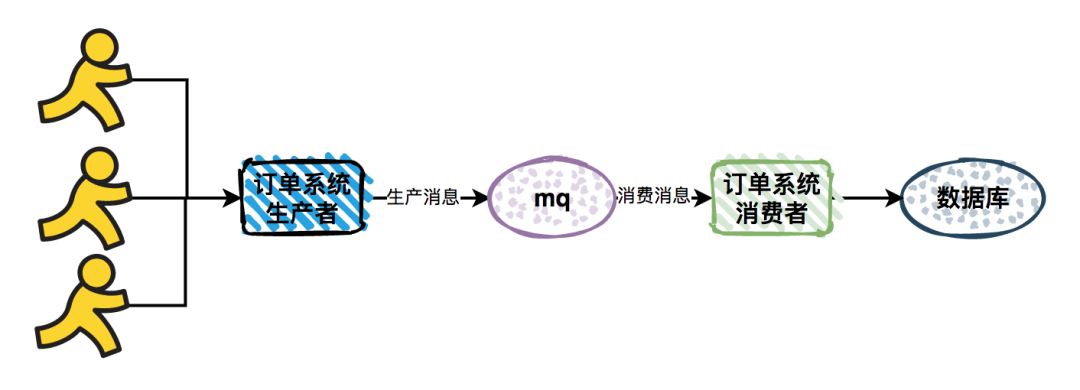
图2-6削峰填谷模式
2.2消息队列的问题
引入事件驱动架构后让我们子系统间耦合性降低了,异步处理机制减少了系统的响应时间,同时能够有效的应对请求峰值问题,提升系统的稳定性。但是Message Queue同时也会带来一些问题。
重复消息问题
重复消费问题是消息队列中普遍存在的问题,不管使用任何一种Message Queue都无法避免。有如下场景会出现重复的消息:
当消息生产者产生了重复的消息时,Message Queue一定会收到两个同样的事件而造成重复消费问题。
如Kafka和RocketMQ等支持offset模式(即可以设置开始消费事件序列的起始位置的方式)中的offset被调回过去的值,这样会造成回退区间中的所有事件重复消费。这个问题也提高了分布式消息队列中对于消费者状态一致性的要求。
消息消费者确认失败:当有质量保证的消息队列发送给消费者事件时,需要收到消费者确认收到的Response才在记录中标记事件已消费,消息消费者由于一些原因确认函数并没有调用,就会为了质量保证而重发事件,导致重复消费。
业务系统主动发起重试:如果较长时间没有收到确认Response(ACK Message),就会认为是网络问题重发,导致可能的重复消费[13]。

图2-7消息的重复消费导致业务出错
如果重复消息不做正确的处理,会对业务造成很大的影响,产生重复的数据,或者导致数据异常,比如会员系统多开通了一个月的会员。
重复消息解决思路:
由于消息的最终目的是被消费,所以不管是由于生产者产生的重复消息,还是由于消费者导致的重复消息,我们都可以在消费者中解决这个问题。这就要求消费者在做业务处理时,要做幂等设计。
本文设计增加一张消费消息表,来解决Message Queue的这类问题。在消费消息表中,记录messageId做唯一索引,每次进行消息接收并处理时(业务逻辑之前),先对消费消息表进行查询,如果存在该messageId记录,显然要退出该条消息处理,如果没有查询到,则讲该messageId记录在表中,然后再继续做业务处理,中间考虑一个程序多进程消费者的情况下,需要对记录表进行上锁。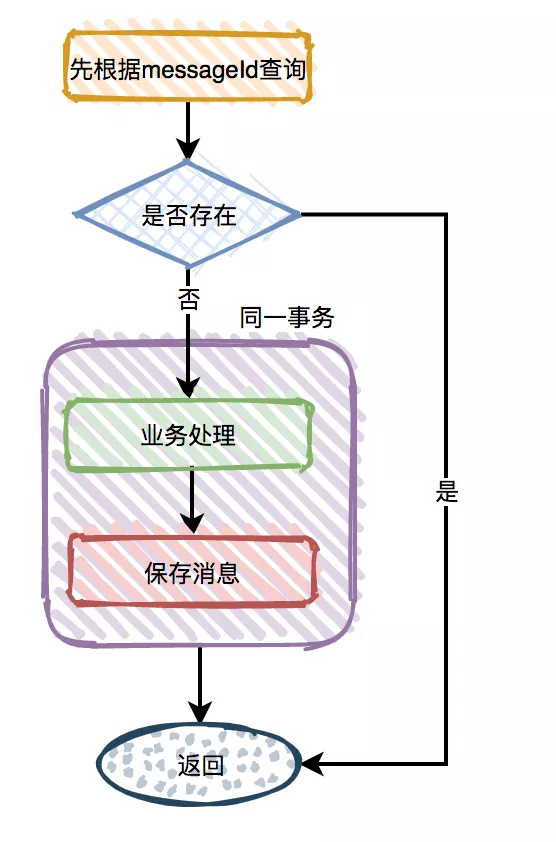
图2-8 记录消息防止重复消费的流程
同时也提供另一种思路,除了在Consumer端增加幂等设计之外,还可以在Broker端做处理,一是选取做了去重处理的Message Queue,二是将Message Queue改动为分布式有状态的Broker,但是这种方案只能解决发布者重复消息的问题,所以要在消息发送时,多携带一个标志位,表示该消息是否是因为超时重试等原因多次发送的,以此来帮助消费者端解决重复消费的问题。
数据一致性问题
数据一致性问题会出现在Message Queue的消费者在业务处理是发生异常的情况下。例:在一个完整的业务流程中,下单成功之后送100个积分。下单的信息写入数据库了,然而消息消费者在执行送积分的函数程序时因为一些原因中断失败了,就出现了数据不一致的情况,即该业务流程的一部分数据落库,另外一部分没有落库。
图2-9消息在不同系统中不一致
在数据库中,是有事务性处理来保证两者要不同时完成,要不都失败的。如果下单和送积分在同一个事务中,是不会出现数据一致性问题的。但由于跨系统调用,出现当前情况。同时为了性能考虑,一般不会使用强一致性的方案,也就是业界公认的达成最终一致性即可。
数据一致性问题解决思路:
本文将数据一致性分为[14]:
• 强一致性。
• 弱一致性。
• 最终一致性。
而Message Queue为了性能考虑通常拥抱最终一致性,数据不一致的问题是一定会出现的。大概率发生在消费者读取消息后,因为处理业务逻辑失败而致的,这种情况则可以增加重试机制来解决问题。
可以将重试分为同步重试和异步重试进行讨论。
同步重试:在消息量小的业务场景建议采用同步重试,如在处理消费消息失败,立刻重试3-5次,然后引入死信机制,即如果重试之后依旧失败,则记录在表中。而如果出现网络异常,该种方式可能会导致大量的消息同时不断重试,因为占用CPU等处理资源,还会影响影响消息读取速度,造成消息堆积。
异步重试:在消息量比较大的场景下建议采用异步重试,依旧设计一个重试表,在消费者的业务逻辑失败之后,将事件写入重试表中,使用一个独立的Job(作业)机制(可以是反馈到Broker中,也可以是多线程实现)来进行定时重试。这样会存在一些延时和性能问题,但好在业界有一些算法和权衡可以考虑。还有一种叫书签(Bookmark)的做法,如果消费失败,可以由消费者本身向同一个Topic发一条消息,在后续的某个时间点,自然会消费到自己发的事件,从而完成了重试。然而这一个功能的引入代表着消息有序性的缺失,对事件消费严格有序的业务系统是不能容忍这样的设计的。所以当对消息顺序要求较低的业务系统中可以采用这种方式[15]。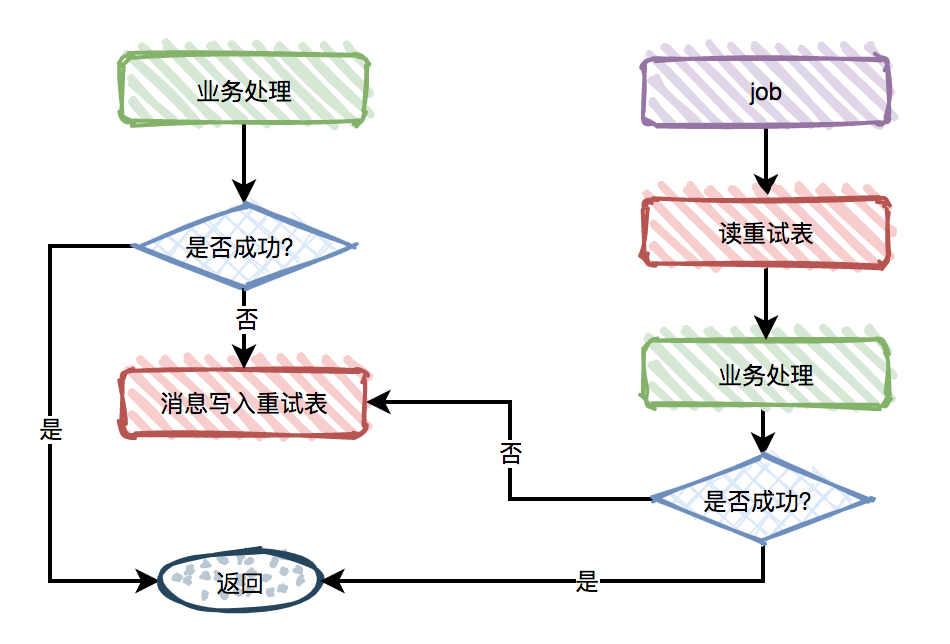
图2-10 重试处理流程
消息丢失问题
消息丢失问题也是Message Queue中无法避免且普遍存在的问题。有如下场景会出现消息丢失问题:
在跨系统调用中,最常出现的就是网络问题,包括延迟、断线、IP漂移等。在消息生产者发送消息时,由于网络原因没有将消息发送到Message Queue处理。自然就会出现丢失的情况
Message Queue服务器持久化时,磁盘出现异常:由于持久化数据需要异步批量落盘处理,消息可能已经完成他的生命周期,但是却由于磁盘异常没有记录在案,会出现消息丢失的情况。
用OffSet功能的Message Queue:kafka和RocketMQ的offset在被回调时,不仅可能重复消费很多消息,也可能跳过(Skip)很多消息,导致消息应该被消费但却永远不会消费的情况。在Message Queue中有一个独特术语死信(Dead Message)[16]即包括这种情况。
没有正常消费:消息消费者虽然收到了事件并进行ACK(Acknowledge)确认了,但实际的消费是消费者之后进行的业务处理,这部分时间端虽然不属于消息队列或总线框架关心的范畴,但属于业务和实际应用的要求。在业务还没处理完时服务被重启或者中断,也会造成消息丢失的问题。
导致消息丢失问题的原因非常多的,生产者、MESSAGE QUEUE服务器、消费者都有可能产生问题,究其原因,是因为多个组件解耦形成的系统是分布式的,中间间杂大量复杂的网络通信环境,且这些情况由于系统的设计是解耦的,故应为相互不可知的。这些实际应用中遇到的问题必须进行妥协和权衡,牺牲一些解耦合和性能来换取可靠性。本文这里不继续一一列举,总之,消息丢失的最终的结果会导致消费者无法正确的处理消息,从而导致数据不一致的情况。
消息丢失问题解决思路:
首先确定的是,现实世界极其复杂,消息的传输一定是不可靠的,由墨菲定律,如果消息有概率丢失,那么一定会有消息会丢失。因为我们的业务系统会处理上亿条数据,即使短时间里少,在长久的时间中也会处理极大的事件量。即使这种概率非常小,业务依旧有可能受到影响。而消息丢失在生产者、Message Queue服务器、消费者所有环节中均有可能发生。
同样可以采用记录表的方式,为了解决这个问题,增加一张消息发送表,在生产者发完消息之后写入一条数据到该表中,并将这条数据的状态(Status)标记为待确认。如果消费者读取消息之后,调用生产者的API(Application Program Interface)更新该消息的status为已确认。同时引入 Job系统执行一个Job:即定时检查消息发送表,假设定时间隔3分钟(据实际情况确定)后存在消息是未确认的状态,则可以认为该消息出现丢失情况,则重新发送该消息,另外注意的是,在用消息重试机制的系统中,应该将时间间隔设置到可能的重试截止时间以后,保证不从Message Queue服务器端制造非幂等的情况。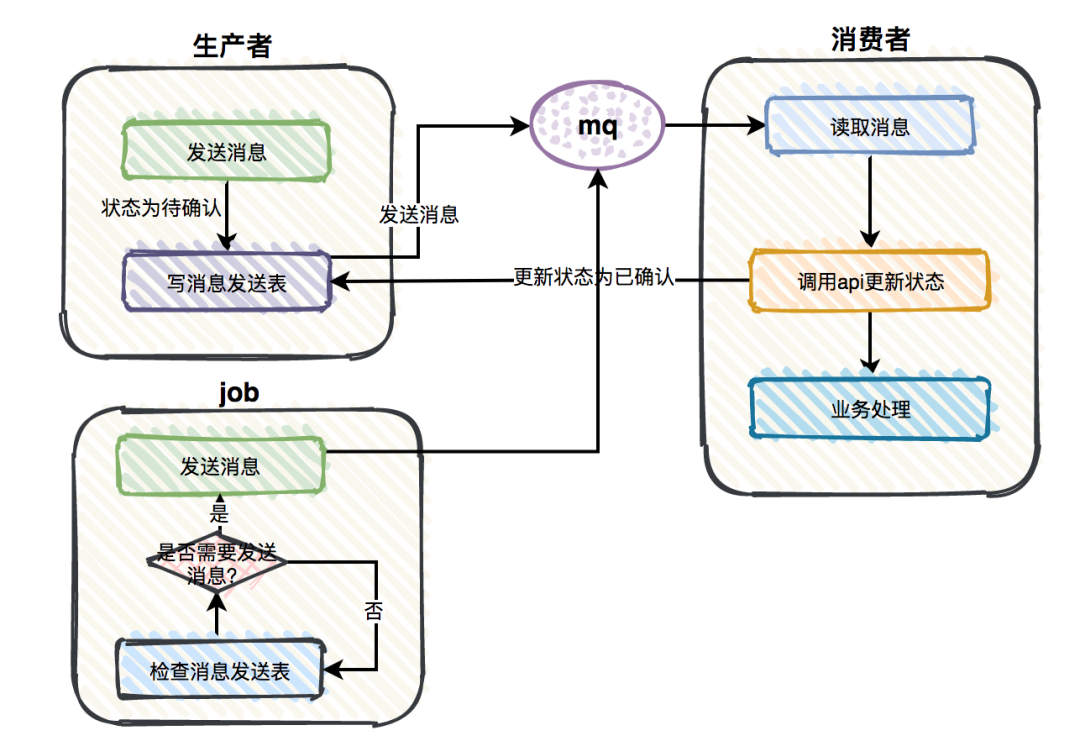
图2-11 使用Job做定时检查
引入这些机制后,可以处理由于生产者、Message Queue服务器、还是消费者导致的消息丢失问题,Job系统会负责重新发送这些丢失的消息,然而也增加了系统的复杂性,因为引入了更多的状态。
消息顺序问题
消息顺序问题也属于实际应用问题,在系统顶层设计时无法观测到,但是实际业务需要的保证性需求。业务数据通常是有状态的,比如订单有:下单、支付、完成、退货等状态,除此之外还有一些时序性等有序的业务数据,如一个活动的前几名等。如果这些数据作为事件传输,顺序问题就必须考虑。当消息消费者(Consumer)接收到同一个订单的两个事件,第一条消息的状态是下单,第二条消息的状态是支付,则会正常处理。当消息队列不保证消息的顺序时,就可能出现消费者收到的第一条消息的状态是支付的情况,之后第二条消息的状态是下单就会出现问题,还没有下单就先处理支付了。这里非常有趣的是两种情况,还是以订单系统为例:如果库存充足,下单和支付的顺序其实无关紧要。在库存不充足的情况下,就会出现已经付了钱但是没有实际商品出售的情况,这种情况在“秒杀活动”等高并发场景尤其常见。这里的问题在于虽然消息有序,但是有时业务并不要求有序处理,这个我们会在之后的性能优化环节讲到,说明对于不需要顺序处理的有序事件,我们依旧可以随机发送。
图2-12消息顺序与实际业务顺序不一致
消息顺序问题是一个非常棘手的问题,以我们常用的Message Queue为例:kafka同一个分区(partition)中能保证顺序,但是不同的partition中各自的事件无法保证顺序,即局部有序。在RabbitMQ中则是同一个Queue(队列)中的事件能够保证有顺序,但是在多个消费者对同一个Queue进行消费时依旧会出现乱序问题。还有以下情况会导致乱序:
如果消费者使用多线程消费消息,也无法保证顺序。除非消费者自身实现了调度器进行并行乱序消费和串行顺序消费,即本文中的事件驱动框架实现的顺序消费者调度器。
以订单系统为例:如果消费消息时同一个订单的多条消息中,中间任何一条消息出现异常情况(如网络原因、消息丢失、消费者消费失败或无法ACK),顺序依旧会被打乱。
在生产者发送消息时,有些Message Queue支持消息路由,如发送到order( 代表通配符)[17]Topic中,路由规则与消费者不一致,顺序也无法保证。
消息顺序问题解决思路
消息顺序问题是我们非常常见的问题,依旧以kafka消费订单消息为例。订单有:下单、支付、完成、退货等状态,这些状态是有先后顺序的,如果顺序错了会导致业务异常。需要先确认的是,消费者是否真的需要知道中间状态,因为我们的消息系统需要保证的是最终一致性。流程如下: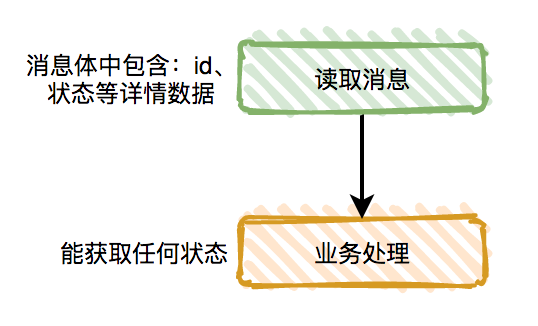
图2-13完全一致性的场景
而在只考虑最终状态一致的情况下(这也是大部分业务系统的需求),可以优化流程如下: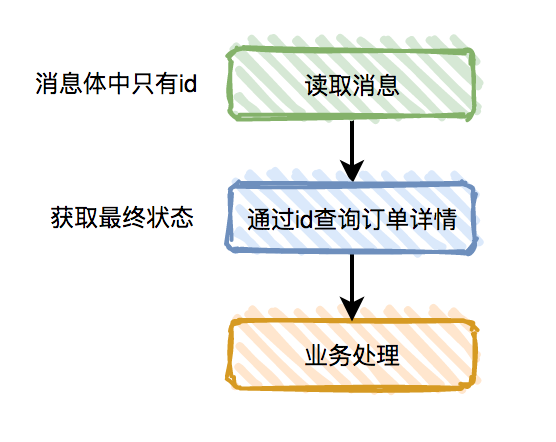
图2-14 最终一致性的场景
通过拥抱最终一致性,可以解决大部分的消息顺序问题。然而需要保证消息顺序时,还可以使用kafka的分区机制。通过将订单号路由到不同的partition,把同一个订单号的消息,固定只发送到同一个partition。这样使用局部有序性,既满足需求,也提供了性能。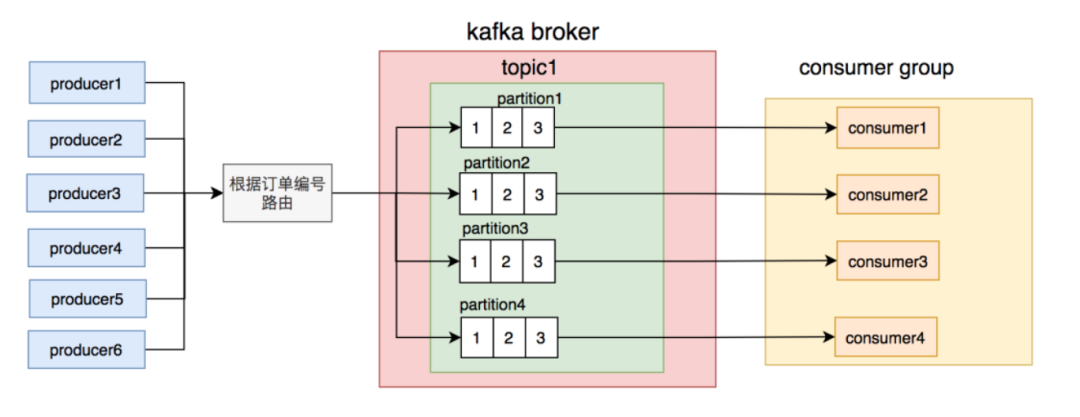
图2-15 kafka的局部分区有序性
消息堆积
如果消息消费者读取消息的速度,能够跟上消息生产者的节奏,那么整套Message Queue机制就能发挥最大作用。但是很多时候,由于某些批处理,或者其他原因,导致消息消费的速度小于生产的速度。这样会直接导致消息堆积问题,从而影响业务功能。
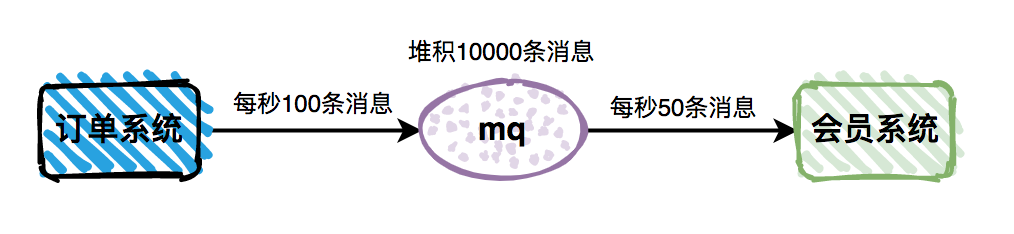
图2-16消息发布速率与消费速率不一致导致堆积
这里以下单开通会员为例,如果消息出现堆积,会导致用户下单之后,很久之后才能变成会员,这是业务系统不能接受的。
消息堆积的解决思路:
消息堆积问题出现在消费速度不一致上,消费者消费速度快的时候并不会出现问题,因为他们会等待事件。当消费者消费消息的速度小于生产者生产消息的速度时,则会有堆积速率,产生消息的堆积,并且可能越来越多。这类问题在业务系统中产生的原因很多,包括系统性能和临时突发流量,甚至网络攻击等原因。
当消息不需要保证顺序时,可以使用多线程业务逻辑处理。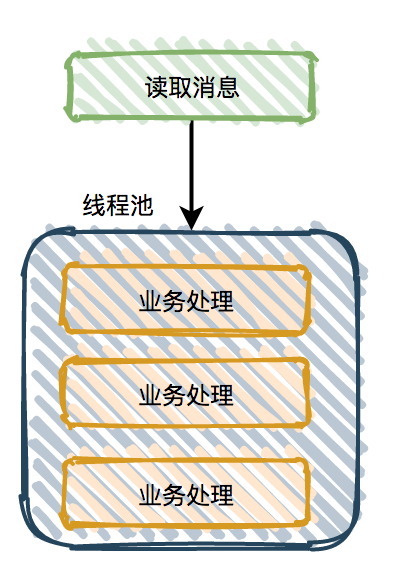
图2-17并行处理
通过增加消费者端消费速率可以解决消息堆积问题。然而多线程本质是更高效率的利用CPU核心,故合理配置线程池的核心线程数和最大线程数非常重要[19],不然会造成系统资源的浪费。
当消息需要保证顺序时,则读取消息之后,将消息路由在单线程处理的队列中,由多个队列同时处理,类似Kafka的partition分区机制。在本文的框架实现中正是采取的该种方案,通过设置OrderingKey区分一个事件到不同的队列中,保证该类消息有序处理。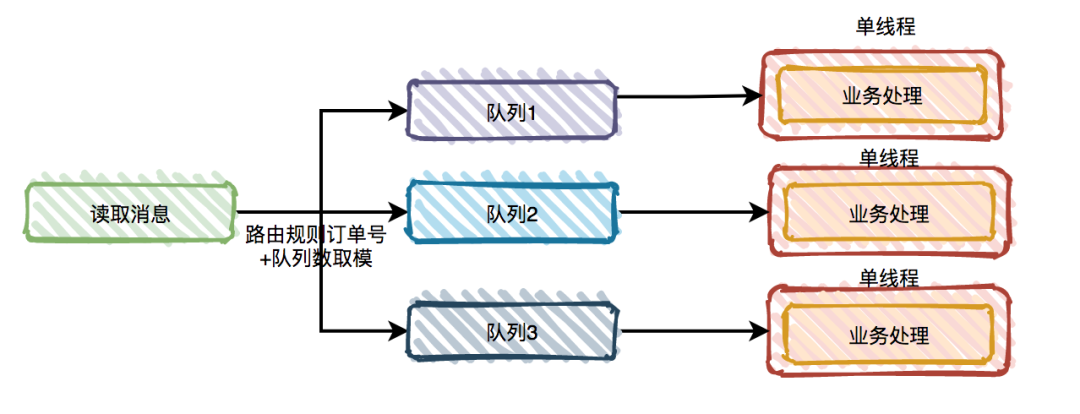
图2-18 分队列处理
系统复杂度提升
虽然引入了消息队列,让软件系统解耦度更高,然而不得不考虑的是系统的复杂度提升。比如以前只有:系统A、系统B和系统C 这三个系统,现在引入Message Queue之后,也需要进行维护和关注,当然,系统的环节越多,系统的受攻击面就越广。
同时引入消息队列注定会有一定的学习成本,如需要额外部署Message Queue服务器,尤其类似RocketMQ这样功能强大的消息队列,注定用法复杂,使用不好反而会出现问题。由于系统解耦度过高,当出现问题时,反而会造成问题难以定位成业务逻辑问题还是系统本身的问题,不像业务接口调用容易排查,当然,也可以考虑云供应商托管的方式,这就会导致相关云资源的使用和技术的选择会绑定在该云供应商上。
解决思路:**
事件驱动架构是一种趋势,对日益增长的系统是利大于弊的,所以方案就是权衡,逐步考虑,选择当前情况最适合的方案,同时考虑未来的转型预期。 比如一些Message Queue的一些特殊功能:定时发送、延迟发送、私信队列、事务问题等,就可以稳步使用,在有对应需求的时候再研究试点,逐步引入。同时考虑到云供应商团队的专业性,极力推荐使用购买第三方的服务在业务体量小于云供应商的情况下。至于绑定的问题,正是本文提出的云无关的事件总线框架要解决的。
2.3底层无关的事件总线框架
本文论述了事件总线本身需要注意的问题和解决方案,然而还有一个问题,即我们不可能在复杂的世界中只选取使用某一种消息总线来满足我们所有场景的需求,针对不同的场景,会有不同特性的消息总线软件满足甚至都不满足需要重新开发。一个已有系统推倒原有软件设计更换新的消息队列是成本巨大的。我们提出一种框架模式,使得消息总线的变更与上层业务应用编码无关,即云事件总线。通过其预留的接口,接入不同的消息总线作为底层依赖,从而达到可以任意更换使用的消息队列
3技术选型及相关知识简介
3.1 整体概况
技术选型分两大块,一块是接入依赖的云事件发布订阅框架本身,一块是消息总线底层依赖。
云事件发布订阅框架的开发语言选择的是 Golang,因为它兼具开发效率和性能,语言特性简练高效;开发框架自己实现,用于灵活接入不同的消息总线。
消息总线驱动也选择 Golang 语言,与框架接入使用语言原生的包管理工具 Go Module进行,通过接口设计解耦,使得驱动开发和框架主体开发无关。同时可以灵活的单独对框架主体和驱动进行改动。
消息总线底层依赖通过设计可以配合任何消息总线使用,只需要实现对应消息总线的驱动即可。部署消息总线可以使用 Docker配合,十分便捷。也可以通过云厂商的服务支持,直接在云端启动消息总线部署。本课题选择 Docker 来实现容器化部署[20],最终实现一个 Docker-Compose 文件即可完成所有组件的部署,相互之间通过暴露的端口进行通信和交互。
3.2 Golang语言
后端开发语言有很多选项,例如Java,PHP,NodeJS,Golang,Python,C等。每种语言都有自己的特征。 Java是当前服务器领域中使用最广泛的语言,但是开发效率不高,并且编译和部署也有些麻烦。 PHP,NodeJS和Python是动态语言,开发效率确实很高,但是单线程性能不是很好,后期维护也不容易。 C和Golang是强大的静态语言,并且在类型验证中相对安全,但是C很少用作服务器端开发选择,因为相关工具较少并且开发效率很低; Golang由Google团队于2009年推出。编程语言的新时代,Go语言针对多处理器系统应用程序的编程进行了优化。 使用Go编译的程序可以与C或C ++代码的速度相媲美,并且更安全,支持并行进程并且具有简单有效的语言功能。 随着开发效率和性能的提高,越来越多的公司开始采用Golang作为其发展的首选。
Golang的编译速度非常快,并且可以在编译后直接生成二进制可执行文件。 除了一些需要libc的代码之外,几乎没有运行环境依赖。 这是部署(尤其是容器化部署)的一项重要功能。 此外,Golang具有最终的并发编程经验,因为其底层实现是专为现代多处理器设计的,并且可以快速安全地编写并行程序。 代码只需在将函数放入协议之前声明一个go关键字即可。 并行处理过程中。 goroutine是由语言本身实现的运行时创建的用户级线程。 与操作系统中的进程和线程相比,goroutine占用的资源很少。 一个goroutine最初只需要2kb的内存,而一个线程则需要几个MB,因为协程的重量轻,一台机器可以运行数百万个协程。 而且,它在运行时具有自己的一组调度机制。 没有由操作系统切换线程引起的上下文更改引起的消耗。 由于网络请求而导致的协程阻塞不会导致线程阻塞,从而大大提高了程序的运行效率。 另外,Golang具有非常有效的垃圾回收机制,其GC性能无疑是后端语言的最前沿。 Golang也是一种开源语言,由一群顶级程序员设计和实现。 它的概念非常适合当代Internet。 Golang也被与21世纪C语言进行了比较,因此可以保证Golang的使用前景。
而本课题通过 Golang 编写框架本身和驱动,即考虑了在云原生社区中的应用,大部分都是由 Golang 语言完成,社区生态良好,有助于之后与不同场景下的消息总线对接。同时 Golang 语言简洁易学,相较于其他语言,降低了接入者的使用成本。
3.3 消息总线依赖及分析
目前消息总线中并无标准定义的云事件总线,业界知名的是 Kafka,Redis,Pulsar和Nats 等开源项目,他们本身各自都有可以在云上运行的集群解决方案,所以当多个实例组成集群的时候可能认为是一个云事件总线解决方案。
3.3.1 NATS
NATS是一个开源、轻量级、高性能的分布式消息中间件,实现了高可伸缩性和优雅的Publish/Subscribe模型,使用Golang语言开发。
Distributed System Concepts and Design一文中指出 “A distributed system is one in which components located at networked computers communicate and coordinate their actions only by passing messages。”即消息中间件在网络中的计算机中,系统中各个组件只通过消息中间件传递消息进行交流和调度。
消息中间件是分布式系统中重要的组件,主要解决应用解耦,异步消息,流量削锋,消息通信等问题[21]。
异步消息:面对高并发问题时,引入消息中间件达到异步处理效果
应用解耦:用在电商系统中较多,比如库存系统和订单系统进行解耦
流量削锋:一般用在秒杀或者团抢活动中使用广泛。秒杀活动中会因为流量过大,导致流量暴增,应用挂掉。为解决这个问题,一般早前端引入消息队列
目前市场上热度较高的消息中间件有RabbitMQ, ActiveMQ, Kafka等,这些消息队列的使用率较高。NATS属于比较小众的一款中间件产品,基于Go语言开发,虽热度不及以上提及的消息队列,但在性能方面可以说有过之而无不及,下图为各个消息队列性能对比图。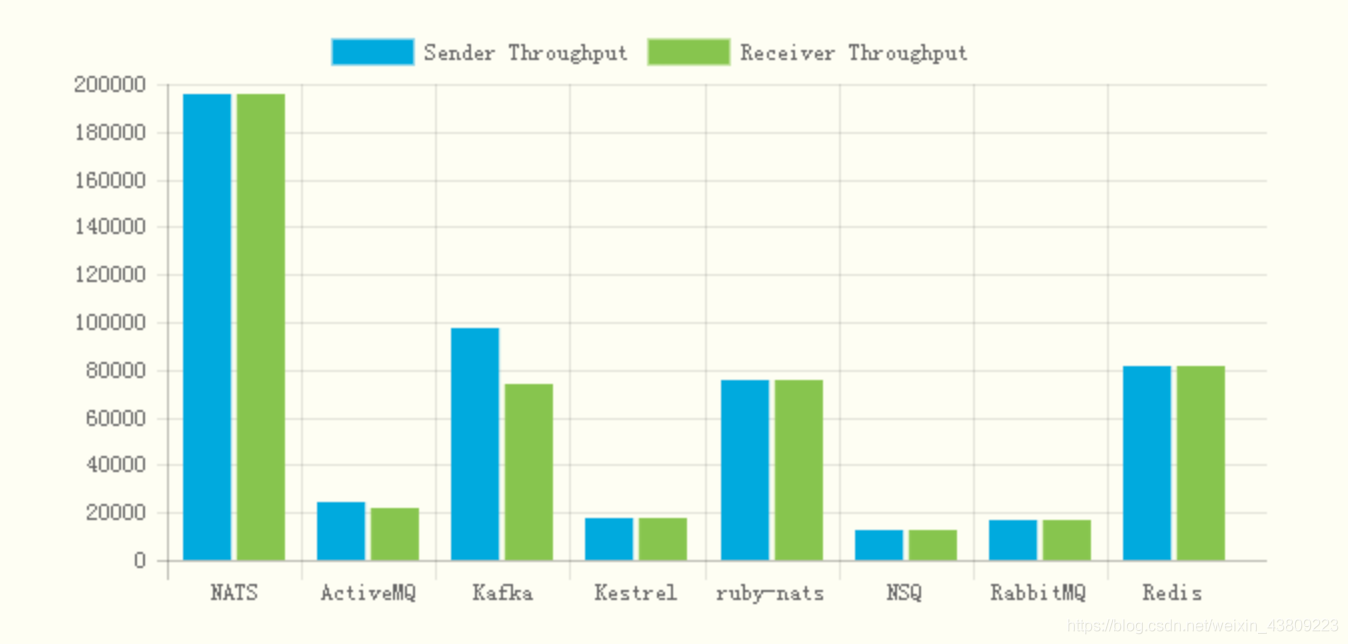
图3-1 各大消息队列处理能力对比图
3.4容器技术
最终完成整个工程的开发和测试后,如何部署也是一个很重要的问题。
容器化可以实现高效的隔离,保证进程、数据、状态的密封性,每个容器只向外暴露指定的端口,内部逻辑并不暴露,其中一个出错也不会影响其他,提高了安全性、可用性和稳定性。而且容器配置了重启机制,出错了也会自动尝试重启,提供进程守护的功能。配合 docker-compose 可以实现一键部署,简化了整个项目的部署复杂度,解放双手,提升生产力。容器化也可以解决环境依赖问题,如果直接在裸机上部署项目,相关的环境搭建可能需要很多步骤,而 docker 镜像已经可以提供我们需要的环境,只需要拉取相应的镜像然后加入工程编译好的代码包,即可运行,解决了环境搭建的麻烦。在机器上安装了 docker 的任何人都可以运行该服务,不必担心依赖项的安装,不必考虑编译器或任何其他需要支持的基础设施,开发机器也不会因为安装了这个服务的配置和依赖项而受影响。所有内容都包含在 Docker 镜像中。
4本章小结
本章在上一张需求分析的基础上做了相关功能实现的技术选型,在不同领域对相关产品或者技术方案做了一些对比,选出适合本课题研究和使用的技术方案,并对选择的技术做简单的优势分析和介绍,之后功能实现模块可能还会反复ᨀ到并使用上述提到的框架和技术。
4功能分析详述
4.1插件式
插件式是本文提出云无关消息总线的核心。本文会完成一个驱动接口的设计和实现。通过Golang语言的接口,定义驱动的相关行为,具体实现则在驱动中完成,以此来完成消息总线底层依赖和框架本身的解耦。插件式的设计让框架的灵活性提升,并且不再受到某一个消息队列的实现的绑定,同时由于抽象出了消息队列的行为如Pub/Sub等函数接口。甚至可以将所有具有输入输出(I/O)功能的软件、程序定义为底层消息总线,需要的只是为其实现专门的驱动,如我们的Linux终端支持的管道功能,就可以看做前面程序的输出作为消息发布到后面的程序的输入,而管道这一分发功能,即可通过Golang对其进行Command调用和驱动接口包装实现来转换为底层消息总线。即插件式的接口设计,极大提高了框架的解耦性,并从本质上带给了应用云原生的扩展能力。接口幂等性问题,对于开发人员来说,是一个跟语言无关的公共问题。
4.2幂等性
幂等性问题,对于开发人员来说,是一个跟语言无关的公共问题。MessageQueue的使用中在消费者在读取消息时,有时候会读取到重复消息,如前文所述,处理不好,也会产生重复的操作。而幂等性是指用户对于同一操作发起的一次请求或者多次请求的结果是一致的,不会因为多次点击而产生了副作用。针对我们的消息总线框架,即多次发送的事件只会处理一次,业界术语叫只一次语义(Exactly One/one and only one)。除了前文已经提到建表记录之外,还可能使用一些具有事务性保证的技术,如直接使用具有事务处理功能的数据库,或者为消息队列实现一个对应的事务功能。
4.3批处理
本文提到,引入MessageQueue也会赋予系统处理大量数据的能力,如异步处理,削峰填谷等作用。大数据是收集、整理、处理大容量数据集,并从中获得见解所需的非传统战略和技术的总称。虽然处理数据所需的计算能力或存储容量早已超过一台计算机的上限,但这种计算类型的普遍性、规模,以及价值在最近几年才经历了大规模扩展。大数据系统一个最基本的组件:处理框架。处理框架负责对系统中的数据进行计算,例如处理从非易失存储中读取的数据,或处理刚刚摄入到系统中的数据。数据的计算则是指从大量单一数据点中提取信息和见解的过程。
批处理在大数据世界有着悠久的历史。批处理主要操作大容量静态数据集[22],并在计算过程完成后返回结果。批处理模式中使用的数据集通常符合下列特征:
• 有界:批处理数据集代表数据的有限集合
• 持久:数据通常始终存储在某种类型的持久存储位置中
• 大量:批处理操作通常是处理极为海量数据集的唯一方法
批处理非常适合需要访问全套记录才能完成的计算工作。例如在计算总数和平均数时,必须将数据集作为一个整体加以处理,而不能将其视作多条记录的集合。这些操作要求在计算进行过程中数据维持自己的状态。需要处理大量数据的任务通常最适合用批处理操作进行处理。无论直接从持久存储设备处理数据集,或首先将数据集载入内存,批处理系统在设计过程中就充分考虑了数据的量,可提供充足的处理资源。由于批处理在应对大量持久数据方面的表现极为出色,因此经常被用于对历史数据进行分析。
故本文的事件总线框架也需要考虑批处理的问题,作为事件总线处理事件能力的基础支撑,不过批处理不适合对处理时间要求较高的场合。同时,事件总线的目的是分发事件,故像传统的批处理中使用如MapReduce框架模式的情况不会出现。本文的设计是通过一个批处理器实现将消息和事件进行缓存,同时在一定的时间间隔或者超过缓存大小的时候进行刷新,批量处理事件并发送到消息总线的底层依赖中。因此本框架的批处理表现的更像是逐步运行的流处理系统。
4.4异步进行
异步处理可以更加充分的利用CPU,从而可以宏观上提升程序运行效率。相对于同步处理,异步处理的开发过程更加复杂,出现的问题也更加难于定位。对于高负载的框架来说,异步处理是其能够扛过峰值的核心技术之一。本框架将通过调度器和队列设计完成消息的异步发送功能。事件在进入框架之后,先进入调度器的缓冲区,在一定条件满足之后,就会批量打包到消息总线中进行发送。
4.5高并发
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一,它通常是指,通过设计保证系统能够同时并行处理很多请求。高并发相关指标有响应时间(Response Time),吞吐量(Throughput),每秒查询率QPS(Query Per Second),并发用户数等:响应时间:系统对某个请求做出相应的时间.例如处理一个HTTP请求,从HTTP发出到收到响应需要200ms,则200ms就是系统的响应时间。吞吐量:单位时间内处理的请求数量。QPS:每秒响应请求数,也是各种系统的关键指标。并发用户数:同时承载正常使用系统功能的用户数量,例如微信,同时可以x亿人在线,一定程度代表了系统的并发用户数。通常提高并发能力有以下途径:增加机器:读写分离,分布式部署(不同模块),集群(相同服务)。或者是增强单机性能:数据库优化,优化代码(如算法),硬件升级(CPU,内存,SSD等)
对于本文使用Golang来讲,天生支持的并行能力和模式是支持高并发的利器。Golang从语言层面对多核CPU支持非常好,在设计程序时运用了并发的设计理念,Go程序在运行期有可能是并行的。Rob Pike(Golang之父)说“Concurrency is about structure, parallelism is about execution(并发关乎结构,并行关乎执行)”[23],实际上本框架设计时,也是直接采用原生的Goroutine 加Channel的方式完成并发,即每一批消息的发送都是通过一个新的Goroutine去实际完成的。
4.6 ACK 机制
如果在处理消息的过程中,消费者的服务器在处理消息的时候出现异常,那么可能这条正在处理的消息就没有完成消息消费,数据就会丢失。为了确保数据不会丢失,消息队列需要支持消息确定(ACK Message)。如果一个消费者在处理消息出现了网络不稳定、服务器异常等现象,那么就不会有ACK反馈, MQ会认为这个消息没有正常消费,会将消息重新放入队列中。如果在集群的情况下, MQ会立即将这个消息推送给这个在线的其他消费者。这种机制保证了在消费者服务端故障的时候,不丢失任何消息和任务。
消息永远不会从MQ中删除,只有当消费者正确发送ACK反馈,MQ确认收到后,消息才会从MQ服务器的数据中删除。通常消息队列的ACK确认机制默认是打开的。如果忘记了ACK,那么后果很严重。当Consumer退出时候,Message会一直重新分发。然后MQ会占用越来越多的内容,由于MQ会长时间运行,因此会有致命的”内存泄漏”错误。
4.7顺序机制
在MQ里,顺序消息的意思是消费消息的顺序和消息发送时(单机发送)的顺序保持一致。顺序消息(FIFO 消息)是 MQ 提供的一种严格按照顺序进行发布和消费的消息类型。顺序消息由两个部分组成:顺序发布和顺序消费。
顺序消息包含两种类型:
• 分区顺序:一个Partition内所有的消息按照先进先出的顺序进行发布和消费
• 全局顺序:一个Topic内所有的消息按照先进先出的顺序进行发布和消费
比如ProducerA按照顺序发送msga, msgb, msgc三条消息,那么consumer消费的时候也应该按照msga, msgb, msgc来消费。
对于顺序消息,在我们实际使用中发现,大部分业务系统并不需要或者并不依赖MQ提供的顺序机制,这些业务本身往往就能处理无序的消息,比如很多系统中都有状态机,是否消费消息必须根据状态机当前的状态。
但是在一些场景中顺序消息也有其必要性:比如日志收集和依赖binlog同步驱动业务等。就这两个场景而言,同样是顺序消息但对顺序的需求却不一定一样:比如一般认为日志收集对顺序的要求比较弱,即部分有序即可,在极端情况,比如Server宕机,容量调整的时候可以暂时容忍一些无序。但是对于一个依赖MySQL binlog同步来驱动的业务,会出现链式反应,短暂的无序都会导致整个系统的错乱。
分析现有的一些MQ后发现,大部分并不能在所有情况下提供可靠的顺序支持。如Kafka MQ等基本上都是以partition - based模型来提供顺序支持。以Kafka为例:topic分为一个或多个partition,partition可以理解为一个顺序文件,producer发送消息的时候,按照一定的策略选择partition,比如partition = hash(key) % partition num来选择该消息发送给哪个partition,那么具有相同key的消息就会落到相同的partition上,而consumer消费的时候一个consumer独占地绑定在一个partition上。这样一来,消息就是顺序消费的了。同时,在消息消费失败是无法跳过的,因为跳过可能导致后续的数据处理都是错误的。通过提供一些策略,由用户根据错误类型来决定是否跳过,并且提供重试队列之类的功能,在跳过之后用户可以在“其他”地方重新消费到这条消息。本文提出,通过调度器的暂停实现出错时的暂停发送消息,同时部署不同的策略,来保证消息的有序性。
4.8中间件机制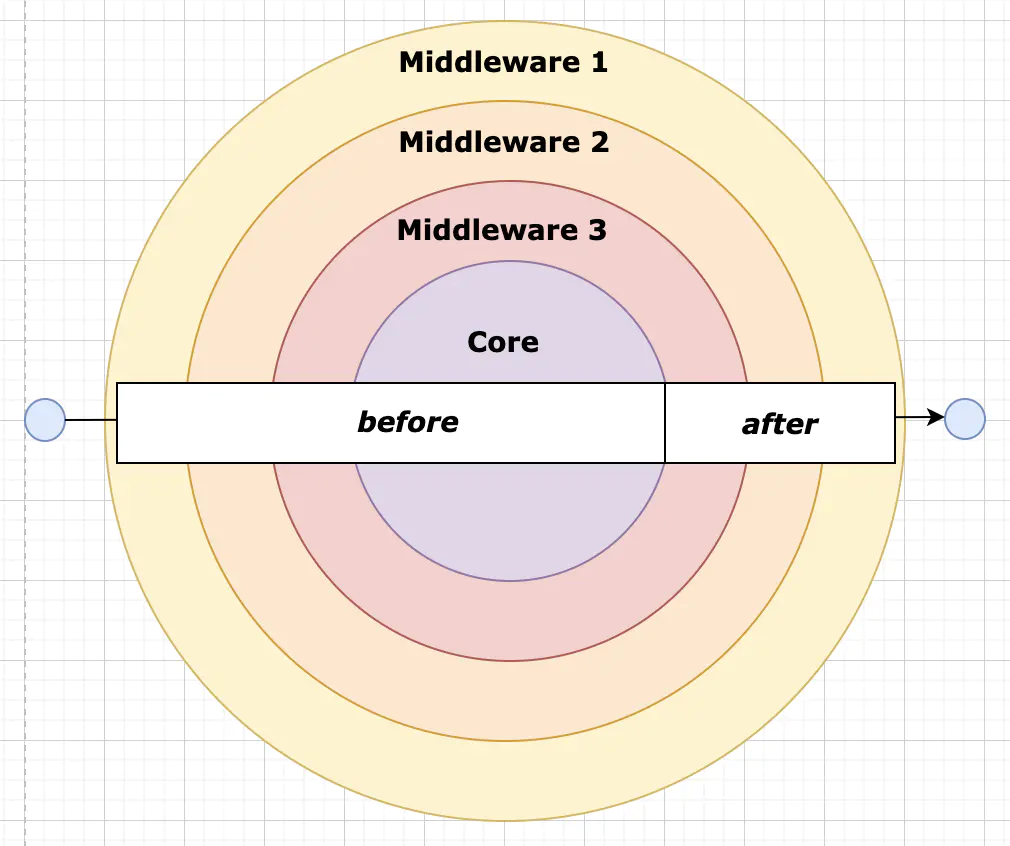
图4-1 中间件模式
中间件机制多出现在Web机制中,中间件功能是可以访问请求对象(request),响应对象(response)和应用程序的请求-响应周期中通过 next 对下一个中间件函数的调用。通俗来讲,利用这个特性在 next 之前对 request 进行处理,在 next 函数之后对 response 处理。而对于消息队列而言,中间件意味着对消息的自定义化处理。诸如上文提到的大部分问题,本文决定以中间件设计的方式在实际框架实现中解决,针对每个问题可能有专门的中间件进行处理。如超时重试,由一个超时重试的中间件进行处理。其他诸如定时发送、延迟发送、私信队列、死信机制等,都可以通过中间件的方式动态加载来完成。
4.9方便的过滤器
在MessageQueue的发布订阅模型中,并不是订阅了一个Topic之后,该Topic上的所有消息都需要接收的。有些MessageQueue会考虑子Topic的情况,然而多级Topic关系不仅难以用于管理,还会出现数据一致性问题,故大部分消息订阅会通过通配符匹配多个Topic的方式来更加细粒度的进行消息或者事件的订阅。本文设计基于中间件的过滤器设计,仿照计算机网络中的Netfilter对网络包的处理,无论是发送前还是接受前,都先经过一个过滤器,由动态的过滤器规则组成,使得发布者和订阅者可以方便的过滤与主题或者与自己关心的方面无关的消息和事件,不仅减少了系统的负载负担,还使得框架的处理逻辑更加灵活。
4.10配置化
业界有一些共识:“业务架构有三化——配置化、产品化、自动化”,在软件系统中的配置通常指的是软件系统中的对象、对象属性、数据等,借助独立于软件系统的标准数据格式语言,比如xml、json、yaml,进行表达,从而能够在只改变标准数据格式语言且不改变软件系统本身功能的情况下,就能改变系统行为的方式[24]。配置化架构是指可配置的方式构建软件的方法。它是在领域建模的基础上,以配置表述业务,以配置组织架构元素(服务、组件、数据),并对配置进行规范化、自动化的管理。配置化是云原生12因素中的一个,作为一个云原生的事件总线框架,通过配置确定实际的服务功能,不通过改代码而是通过配置的方式改动来调整事件总线的功能。
4.11云事件格式
CloudEvents是一个用标准方式描述事件数据的开源规范,旨在简化事件声明以及跨服务、平台等的消息投递。推动该规范的是云原生计算基金会( Cloud Native Computing Foundation,简称CNCF)。20 多个不同的主体共同打造了 CloudEvents,其中包括所有主要的公共云平台供应商和很多平台用户。该项目的目的是提供一个行业定义和开放框架,以了解什么是“事件”、什么是其最小的语义元素、如何对事件进行编码以便于传输以及如何传输,并且会使用如今正在用的主要编码和应用程序协议,而不是发明新东西来实现这些。本文的事件在进行包装时,采取CloudEvents协议定义的格式,进一步提升框架的普适性和云原生价值。如下是CloudEvent的标准格式:
{
“specversion”: “1.x-wip”,
“type”: “coolevent”,
“id”: “xxxx-xxxx-xxxx”,
“source”: “bigco.com”,
“data”: { … }
}
5主要功能模块的实现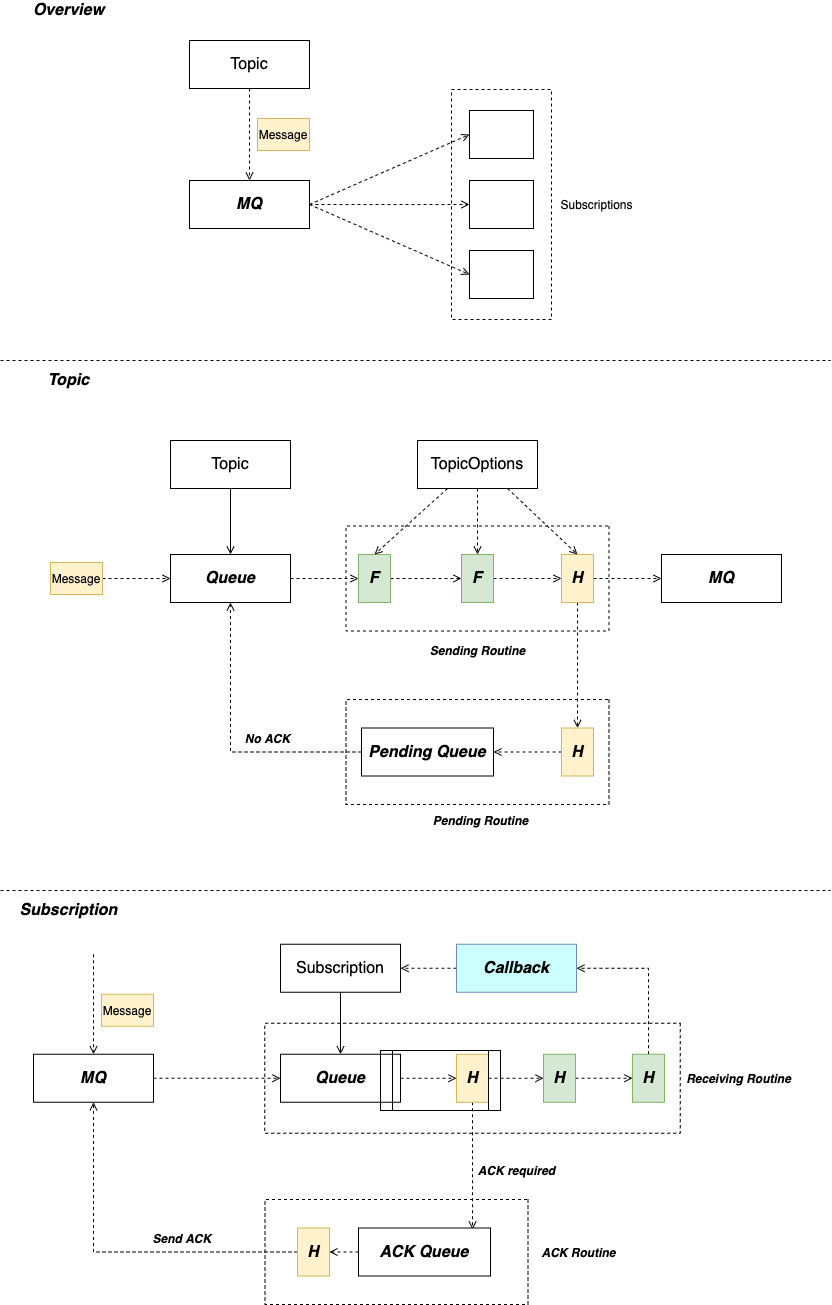
图5-1架构总体设计
本文框架总体架构如下,在插件化的事件总线框架上构建符合功能的事件处理机制,通过TopicOptions进行配置化动态管理,通过中间件模式接入各种功能机制需求,消息符合CloudEvent格式,依靠中间件的方式,如ACK机制等动态关闭或启动,并且为消费者增加消费回调,方便消费者完成事件消费。底层是不同消息队列的统一接口实现,通过驱动框架接入配置,达到不依赖固定某一个消息队列的效果。
5.1调度器实现
调度器实现了上述的顺序机制,高并发机制,缓冲机制,异步机制和中间件机制,因此诸如ACK功能,回调函数和过滤功能都是在调度器上实现的。通常来说,操作系统是应用程序和可用资源之间的媒介。而本文的调度器,正是用户程序和系统资源之间的媒介。资源包括有内存和物理设备和CPU,调度器可以临时分配一个任务在上面执行(单位是时间片)。调度器使得同时执行多个程序成为可能,通过Golang原生的Goroutine语法共享CPU。调度器的一个重要目标是有效地分配 CPU 时间片,同时提供很好的用户体验。原理是, 按所需分配的计算能力, 向系统中每个事件的处理进程提供最大的公正性, 或者从另外一个角度上说, 他试图确保没有每一个事件被亏待。调度器核心代码主要分成两个部分,分别是执行中间件调用的部分和实现调度,缓冲,顺序机制的BundleScheduler部分,Topic的发布功能如下:
func (t BundleTopic) Publish(ctx context.Context, msg protocol.Message) aresult.Result {
r := aresult.NewResult()
if !t.EnableMessageOrdering && msg.OrderingKey != “” {
r.Set(msg.UUID, errTopicOrderingDisabled)
return r
}
mb, _ := jsoniter.Marshal(msg)
size := len(mb)
t.start()
t.mu.RLock()
defer t.mu.RUnlock()
if t.stopped {
r.Set(msg.UUID, errTopicStopped)
return r
}
err := t.scheduler.Add(msg.OrderingKey, &bundledMessage{msg, r}, size)
if err != nil {
t.scheduler.Pause(msg.OrderingKey)
r.Set(msg.UUID, err)
}
return r
}
Topic只需执行启动调度器,并将消息发布给调度器即可,这也是用户使用框架时仅需要做的最少且最简单的事。调度器控制着缓冲区,当缓冲区的消息满溢的时候会阻塞发送函数调用,并能根据传递的函数参数决定传递的消息如何处理,通过这种方式实现,可以解决不同消息需要差异化处理的问题。同时队列缓冲区的存在,也一定成都保证了顺序机制。
// Add adds the item to be handled. Add may block.
//
// Buffering happens above the Scheduler in the form of a flow controller
// that requests batches of messages to pull. A backed up Scheduler.Add
// call causes pushback to the pubsub service (less Receive calls on the
// long-lived stream), which keeps memory footprint stable.
func (s Scheduler) Add(key string, item interface{}, handle func(item interface{})) error {
select {
case <-s.done:
return errors.New(”draining”)
default:
}
if key == “” {
// Spawn a worker.
s.workers <- struct{}{}
go func() {
// Unordered keys can be handled immediately.
handle(item)
<-s.workers
}()
return nil
}
// Add it to the queue. This has to happen before we enter the goroutine
// below to prevent a race from the next iteration of the key-loop
// adding another item before this one gets queued.
s.mu.Lock()
, ok := s.m[key]
s.m[key] = append(s.m[key], func() {
handle(item)
})
s.mu.Unlock()
if ok {
// Someone is already working on this key.
return nil
}
// Spawn a worker.
s.workers <- struct{}{}
go func() {
defer func() { <-s.workers }()
// Key-Loop: loop through the available items in the key’s queue.
for {
s.mu.Lock()
if len(s.m[key]) == 0 {
// We’re done processing items - the queue is empty. Delete
// the queue from the map and free up the worker.
delete(s.m, key)
s.mu.Unlock()
return
}
// Pop an item from the queue.
next := s.m[key][0]
s.m[key] = s.m[key][1:]
s.mu.Unlock()
next() // Handle next in queue.
}
}()
return nil
}
5.2批处理器实现
批处理器是调度器的底层实现,他提供了打包多个消息一并处理的能力,并且接下来的消息处理一并交由批处理器处理。以下是批处理器关于顺序机制和高并发机制的实现,即当消息需要顺序处理的时候,会给予一个orderingKey标识,表明该标识的消息都需要设置为串行处理以保证顺序,同时如果串行处理的时候出错,就会通过Pause(orderingKey string)暂停后续相同orderingKey标识的消息或者事件的继续处理,直到调用Resume()函数告知批处理器继续执行,在这段时间中,可以将失败的消息进行发送重试等补救操作以保证顺序。换句话来说,当网络不可用等情况出现时,并不会出现消息乱序的情况。另一种是消息不需要顺序处理的情况,在这种情况下,通过设置Goroutine的限制数量为1e9(10亿,几乎无限制),每当有一包消息(由Bundle结构进行打包)需要处理时就启动一个Goroutine进行并发处理,通常Goroutine在机器上可以达到上百万的并发量,该功能在处理高峰流量完成了性能考量。
// Shutdown begins flushing messages and stops accepting new Add calls. Shutdown
// does not block, or wait for all messages to be flushed.
func (s Scheduler) Shutdown() {
select {
case <-s.done:
default:
close(s.done)
}
}
// Add never blocks. Buffering happens in the scheduler’s publishers. There is
// no flow control.
//
// Since ordered keys require only a single outstanding RPC at once, it is
// possible to send ordered key messages to Topic.Publish (and subsequently to
// BundleScheduler.Add) faster than the bundler can publish them to the
// Pub/Sub service, resulting in a backed up queue of Pub/Sub bundles. Each
// item in the bundler queue is a goroutine.
func (s BundleScheduler) Add(key string, item interface{}, size int) error {
select {
case <-s.done:
return errors.New(”draining”)
default:
}
s.mu.Lock()
defer s.mu.Unlock()
b, ok := s.bundlers[key]
if !ok {
s.outstanding[key] = 1
b = bundler.NewBundler(item, func(bundle interface{}) {
s.workers <- struct{}{}
s.handle(bundle)
<-s.workers
nlen := reflect.ValueOf(bundle).Len()
s.mu.Lock()
s.outstanding[key] -= nlen
if s.outstanding[key] == 0 {
delete(s.outstanding, key)
delete(s.bundlers, key)
}
s.mu.Unlock()
})
b.DelayThreshold = s.DelayThreshold
b.BundleCountThreshold = s.BundleCountThreshold
b.BundleByteThreshold = s.BundleByteThreshold
b.BundleByteLimit = s.BundleByteLimit
b.BufferedByteLimit = s.BufferedByteLimit
if b.BufferedByteLimit == 0 {
b.BufferedByteLimit = 1e9
}
if key == “” {
// There’s no way to express “unlimited” in the bundler, so we use
// some high number.
b.HandlerLimit = 1e9
} else {
// HandlerLimit=1 causes the bundler to act as a sequential queue.
b.HandlerLimit = 1
}
s.bundlers[key] = b
}
s.outstanding[key]++
return b.Add(item, size)
}
// FlushAndStop begins flushing items from bundlers and from the scheduler. It
// blocks until all items have been flushed.
func (s *BundleScheduler) FlushAndStop() {
close(s.done)
for , b := range s.bundlers {
b.Flush()
}
}
// IsPaused checks if the bundler associated with an ordering keys is
// paused.
func (s BundleScheduler) IsPaused(orderingKey string) bool {
s.keysMu.RLock()
defer s.keysMu.RUnlock()
_, ok := s.keysWithErrors[orderingKey]
return ok
}
// Pause pauses the bundler associated with the provided ordering key,
// preventing it from accepting new messages. Any outstanding messages
// that haven’t been published will error. If orderingKey is empty,
// this is a no-op.
func (s BundleScheduler) Pause(orderingKey string) {
if orderingKey != “” {
s.keysMu.Lock()
defer s.keysMu.Unlock()
s.keysWithErrors[orderingKey] = struct{}{}
}
}
// Resume resumes accepting protocol with the provided ordering key.
func (s BundleScheduler) Resume(orderingKey string) {
s.keysMu.Lock()
defer s.keysMu.Unlock()
delete(s.keysWithErrors, orderingKey)
}
5.3驱动管理实现
驱动接口
驱动接口是消息队列能力的抽象,即Pub/Sub模式的抽象。首先存在Publisher和Subscriber接口如下:
// Publisher should realize the retry by themselves..
// like nats, it retry when conn is reconnecting, it would be in the pending queue.
type Publisher interface {
Publish(ctx context.Context, r protocol.PublishRequest) error
}
// Subscriber is a blocking method
// should be cancel() with ctx or call Driver.Close() to close all the subscribers.
// note that handle just push the received protocol to subscription
type Subscriber interface {
Subscribe(ctx context.Context, r protocol.SubscribeRequest, handler func(ctx context.Context, r protocol.Message) error) (Subscription, error)
}
他们定义了发布行为和订阅行为,借助Golang语言的接口机制,提供了这种行为能力的程序,我们就认为其实现了Pub/Sub模式,并把他集成作为Driver。并通过Connector设计进行连接池管理,帮助复用与底层消息总线的网络连接,避免重复建立连接的开销,提升框架处理性能。
// If a Driver implements DriverContext, then sql.DB will call
// OpenConnector to obtain a Connector and then invoke
// that Connector’s Connect method to obtain each needed connection,
// instead of invoking the Driver’s Open method for each connection.
// The two-step sequence allows drivers to parse the name just once
// and also provides access to per-Conn contexts.
type DriverContext interface {
OpenConnector(protocol.Metadata) (Connector, error)
}
type Driver interface {
Open(protocol.Metadata) (Conn, error)
}
type Conn interface {
Publisher
Subscriber
Closer
}
// A Connector represents a driver in a fixed configuration
// and can create any number of equivalent Conns for use
// by multiple goroutines.
//
// A Connector can be passed to sql.OpenDB, to allow drivers
// to implement their own sql.DB constructors, or returned by
// DriverContext’s OpenConnector method, to allow drivers
// access to context and to avoid repeated parsing of driver
// configuration.
type Connector interface {
// Connect returns a connection to the database.
// Connect may return a cached connection (one previously
// closed), but doing so is unnecessary; the sql package
// maintains a pool of idle connections for efficient re-use.
//
// The provided context.Context is for dialing purposes only
// (see net.DialContext) and should not be stored or used for
// other purposes. A default timeout should still be used
// when dialing as a connection pool may call Connect
// asynchronously to any query.
//
// The returned connection is only used by one goroutine at a
// time.
Connect(context.Context) (Conn, error)
// Driver returns the underlying Driver of the Connector,
// mainly to maintain compatibility with the Driver method
// on sql.DB.
Driver() Driver
}
驱动注册机制
本框架设计通过配置化的文件来进行不同底层消息队列的驱动注册,通过一个注册管理驱动的框架,动态灵活的维护驱动的实现和使用。通过驱动名,将驱动实例存在一个Hashmap中便于处理。
var driversMu = sync.RWMutex{}
var Registry = pubsubRegistry{
buses: make(map[string]func(logger logger.Logger) driver.Driver),
}
type pubsubRegistry struct {
buses map[string]func(logger logger.Logger) driver.Driver
}
func (r pubsubRegistry) Register(name string, factory func(logger logger.Logger) driver.Driver) {
r.buses[name] = factory
}
// Create instantiates a pub/sub based on name.
func (r pubsubRegistry) Create(name string) (driver.Driver, error) {
if name == “” {
log.Info(”Create default in-process driver”)
} else {
log.Infof(”Create a driver %s”, name)
}
if method, ok := r.buses[name]; ok {
return method(log), nil
}
return nil, fmt.Errorf(”couldn’t find protocol bus %s”, name)
}
驱动连接池管理
由于需要有框架与消息队列服务器连接,如果每有一个消息需要发送就重新建立网络连接是开销巨大的,我们知道在Linux等系统中,也会有文件打开数量的限制,故连接池的连接复用功能非常重要,本文设计的驱动框架,用于连接管理实现的是Connector接口,当驱动实现Connector接口时就需要返回一个可用于发布订阅的连接实例,同时我们在其上做池化处理,即可达到连接服用的目的。
// OpenPubSub opens a database using a Connector, allowing drivers to
// bypass a string based data source name.
//
// Most users will open a database via a driver-specific connection
// helper function that returns a DB. No database drivers are included
// in the Go standard library. See https://golang.org/s/sqldrivers for
// a list of third-party drivers.
//
// OpenPubSub may just validate its arguments without creating a connection
// to the database. To verify that the data source name is valid, call
// Ping.
//
// The returned DB is safe for concurrent use by multiple goroutines
// and maintains its own pool of idle connections. Thus, the OpenPubSub
// function should be called just once. It is rarely necessary to
// close a DB.
func OpenPubSub(c driver.Connector) PubSub {
, cancel := context.WithCancel(context.Background())
db := &PubSub{
connector: c,
stop: cancel,
connections: make(map[DriverConn]bool),
}
return db
}
// Open opens a database specified by its database driver name and a
// driver-specific data source name, usually consisting of at least a
// database name and connection information.
//
// Most users will open a database via a driver-specific connection
// helper function that returns a DB. No database drivers are included
// in the Go standard library. See https://golang.org/s/sqldrivers for
// a list of third-party drivers.
//
// Open may just validate its arguments without creating a connection
// to the database. To verify that the data source name is valid, call
// Ping.
//
// The returned DB is safe for concurrent use by multiple goroutines
// and maintains its own pool of idle connections. Thus, the Open
// function should be called just once. It is rarely necessary to
// close a DB.
func Open(driverName string, metadata protocol.Metadata) (PubSub, error) {
driversMu.RLock()
driveri, err := Registry.Create(driverName)
driversMu.RUnlock()
if err != nil {
return nil, fmt.Errorf(”sql: unknown driver %q (forgotten import?)”, driverName)
}
if driverCtx, ok := driveri.(driver.DriverContext); ok {
connector, err := driverCtx.OpenConnector(metadata)
if err != nil {
return nil, err
}
return OpenPubSub(connector), nil
}
return OpenPubSub(dsnConnector{dsn: metadata, driver: driveri}), nil
}
5.4驱动接口实现
最后是实际消息队列驱动的实现,本文框架实现了主流消息队列的驱动,由于框架设计,驱动实现只需要满足上述的驱动接口即可。同时由于消息队列的使用方式通常是Pub/Sub模式,所以包装消息队列作为驱动非常方便,也非常灵活。同时,驱动框架本身也是驱动的实现,这样可以统一接口使用,无论底层选用的消息队列实现是什么,都可以做到不用变更代码,只需改动配置文件即可完成底层消息队列依赖的替换。驱动实现如下:
type PubSub struct {
connector driver.Connector
mu sync.Mutex
publisherConn DriverConn
connections map[DriverConn]bool
closed bool
maxIdleCount int
maxOpen int
maxLifetime time.Duration
maxIdleTime time.Duration
cleanerCh chan struct{}
waitCount int64 // Total number of connections waited for.
maxIdleClosed int64 // Total number of connections closed due to idle count.
maxIdleTimeClosed int64 // Total number of connections closed due to idle time.
maxLifetimeClosed int64 // Total number of connections closed due to max connection lifetime limit.
stop func() // stop cancels the connection opener.
}
type DriverConn struct {
pubSub PubSub
createdAt time.Time
sync.Mutex // guards following
ci driver.Conn
closed bool
finalClosed bool // ci.Close has been called
openSubscription map[driverSubscription]bool
// guarded by pubsub.mu
inUse bool
returnedAt time.Time // Time the connection was created or returned.
onPut []func() // code (with db.mu held) run when conn is next returned
pubsubmuClosed bool // same as closed, but guarded by pubsub.mu, for removeClosedStmtLocked
}
func (dc DriverConn) Publish(ctx context.Context, r protocol.PublishRequest) error {
return dc.ci.Publish(ctx, r)
}
func (dc DriverConn) Subscribe(ctx context.Context, r protocol.SubscribeRequest, handler func(ctx context.Context, r protocol.Message) error) (driver.Subscription, error) {
return dc.ci.Subscribe(ctx, r, handler)
}
下述是Nats消息队列的驱动的主要功能实现。
// Subscribe handle protocol from specific topic.
// use context to cancel the subscription
// in metadata:
// - queueGroupName if not “”, will have a queueGroup to receive a protocol and only one of the group would receive the protocol.
// handler use to receive the protocol and move to top level subscription.
func (c natsStreamingConn) Subscribe(ctx context.Context, r protocol.SubscribeRequest, handler func(ctx context.Context, r protocol.Message) error) (driver.Subscription, error) {
var (
sub stan.Subscription
err error
MsgHandler = func(m stan.Msg) {
err = handler(ctx, &protocol.Message{Topic: r.Topic, Data: m.Data})
if err == nil {
// todo: try to use custom protocol.Message.ack() like SubscribeRequest.Features find ack. no ack here. or find ack false. ack here.
= m.Ack()
}
}
)
m, err := parseNATSStreamingMetadata(r.Metadata)
if err != nil {
return nil, err
}
opts, err := m.subscriptionOptions()
if err != nil {
return nil, fmt.Errorf(”nats-streaming: error getting subscription options %s”, err)
}
if m.subscriptionType == subscriptionTypeTopic {
sub, err = c.stanConn.Subscribe(r.Topic, MsgHandler, opts…)
} else {
sub, err = c.stanConn.QueueSubscribe(r.Topic, m.natsQueueGroupName, MsgHandler, opts…)
}
if err != nil {
//n.logger.Warnf(”nats: error subscribe: %s”, err)
return nil, err
}
if m.subscriptionType == subscriptionTypeTopic {
c.logger.Debugf(”nats: subscribed to subject %s”, r.Topic)
} else if m.subscriptionType == subscriptionTypeQueueGroup {
c.logger.Debugf(”nats: subscribed to subject %s with queue group %s”, r.Topic, m.natsQueueGroupName)
}
return &subscription{sub: sub}, nil
}
func (c natsStreamingConn) Close() error {
return c.stanConn.Close()
}
// Publish publishes a protocol to Nats Server with protocol destination topic.
func (c natsStreamingConn) Publish(ctx context.Context, r *protocol.PublishRequest) error {
select {
case <-ctx.Done():
return errors.New(”context cancelled”)
default:
}
errCh := make(chan error)
go func() {
err := c.stanConn.Publish(r.Topic, r.Data)
if err != nil {
errCh <- fmt.Errorf(”nats: error from publish: %s”, err)
}
errCh <- nil
}()
select {
case err := <-errCh:
return err
case <-ctx.Done():
return errors.New(”context cancelled”)
}
}
通过实现 Publish方法和Subscribe方法,可以轻松完成驱动程序的编写,使得云供应商无关的事件总线能够更灵活的兼容市场上主流的消息队列。
6总结与展望
6.1总结
本文讨论了现有事件驱动架构下的程序,并指出程序使用事件驱动的好处。同时归类分析了现有事件总线的特点,讨论事件驱动下的发布订阅框架的重要性并对事件总线进行深刻的研究。根据其重要性和软件、厂商强绑定的原因,提出了云厂商无关的消息总线底层依赖架构,给出了相关的问题和实验解决方法。最后能够通过一个云厂商无关的框架和市面上主流的消息总线兼容的驱动接口设计,实现指导云原生的事件总线构建的过程。
6.2展望
目前最具云原生事件总线潜力的是Dapr,在消息队列领域则是Pulsar。云供应商无关的各种技术正秉承着开源思想飞速开发中,相信在未来的云原生领域,以插件式、云供应商无关的框架技术会越来越多。本文提出的框架和理念中也有诸多不足和还未考虑到的地方,在日后的实践落地中,会逐渐发现更多的更适合的解决方案,在综合考虑下会不断反馈应用在该论文实现的开源框架中。
参考文献
[1]许文盈,曹进德.基于事件驱动机制的多智能体系统协调控制研究综述[J].南京信息工程大学学报(自然科学版),2018,10(04):395-400.
[2]徐志伟,李沛旭,查礼.计算机系统变革性研究的4个问题[J].计算机研究与发展,2008(12):2011-2019.
[3]罗军舟,何源,张兰,刘亮,孙茂杰,熊润群,东方.云端融合的工业互联网体系结构及关键技术[J].中国科学:信息科学,2020,50(02):195-220.
[4]杨秦. 基于微服务架构的云平台服务端的设计与实现[D].电子科技大学,2020.
[5]马建刚,黄涛,汪锦岭,徐罡,叶丹.面向大规模分布式计算发布订阅系统核心技术[J].软件学报,2006(01):134-147.
[6]Wang Yingying,Kadiyala Harshavardhan,Rubin Julia. Promises and challenges of microservices: an exploratory study[J]. Empirical Software Engineering,2021,26(4).
[7]. GOOGLE INC.; Patent Issued for Full-Duplex Bi-Directional Communication over a Remote Procedure Call Based Communications Protocol, and Applications (USPTO 9258345)[J]. Journal of Engineering,2016.
[8]서보민,이근혁,전철호,전현식,박현주. Proposal of web application model applying CQRS pattern[J]. 한국정보과학회 학술발표논문집,2019.
[9]ZAKIR ULLAH KHAN. Research on Congestion Free Routing Algorithm for Hybrid SDN Network[D].中国科学技术大学,2017.
[10]孙伟. 高效时空大数据服务若干关键技术研究[D].山东科技大学,2019.
[11]刘微. 基于微服务的预付卡系统的研究与设计[D].华南理工大学,2020.
[12]EMMANUEL KOBINA PAYNE. Design of Distributed Energy Resources Integration for Active Demand Power Delivery as A Microgrid System[D].江苏大学,2019.
[13]. Computers; Findings on Computers Reported by Investigators at Maulana Abul Kalam Azad University of Technology (EdgeDrone: QoS aware MQTT middleware for mobile edge computing in opportunistic Internet of Drone Things)[J]. Computer Technology Journal,2020.
[14]曾泽堂. 一种数据同步系统的设计与实现[D].南京大学,2019.
[15]Gebeyehu Belay Gebremeskel. 面向商业智能的数据挖掘算法和多智能体系统的体系结构以及优化[D].重庆大学,2013.
[16]徐超. 大型互联网公司分布式消息系统的设计与实施[D].复旦大学,2013.
[17]李想. 物联网发布/订阅系统的研究与实现[D].电子科技大学,2019.
[18]王岩,王纯.一种基于Kafka的可靠的Consumer的设计方案[J].软件,2016,37(01):61-66.
[19]杨开杰,刘秋菊,徐汀荣.线程池的多线程并发控制技术研究[J].计算机应用与软件,2010,27(01):168-170+179.
[20]秦菁. 基于Docker的OpenStack云平台自动化部署方案的设计与实现[D].武汉邮电科学研究院,2019.
[21]庞佳丽. 分布式系统中基于中间件的异步通信可靠性研究[D].浙江工业大学,2017.
[22]孟小峰,慈祥.大数据管理:概念、技术与挑战[J].计算机研究与发展,2013,50(01):146-169.
[23]DENG Liang,ZHAO Dan,BAI Hanli,WANG Fang.Performance Optimization and Comparison of the Alternating Direction Implicit CFD Solver on Multi-core and Many-Core Architectures[J].Chinese Journal of Electronics,2018,27(03):540-548.
[24]张海藩,吕云翔. 软件工程[M].人民邮电出版社:, 201309.348.
致谢
感谢老师,感谢家人,感谢帮助过我的人,感谢同学。

若有收获,就点个赞吧
0 人点赞
