磁盘的检索效率
假设有一个有序数组存储在硬盘中,如果它足够大,那么它会存储在多个块中。当我们要对这个数组使用二分查找时,需要先找到中间元素所在的块,将这个块从磁盘中读到内存里,然后在内存中进行二分查找。如果下一步要读的元素在其他块中,则需要再将相应块从磁盘中读入内存。直到查询结束,这个过程可能会多次访问磁盘。我们可以看到,这样的检索性能非常低。
由于磁盘相对于内存而言访问速度实在太慢,因此,对于磁盘上数据的高效检索,我们有一个极其重要的原则:对磁盘的访问次数要尽可能的少!使用索引和数据分离来提高磁盘的检索效率 | 方案 | 优缺点 | | —- | —- | | 线性索引 | 如,数组存放索引,但数组在数据频繁变更的场景下不适合,因为数组不支持动态调整 | | 哈希索引 | 缺乏范围检索能力,适用场景有限 | | 树形索引 | 如二叉检索树,既支持范围检索,又能保证数据频繁更新的情况下数据移动数量少,所以具有普适性。但数据量太大,不能完全加载到内存中的情况下,就不适用了。所以数据量大的情况只能将索引数据也存到磁盘中。 | | B +树索引 | 给出了将树形索引的所有节点都存在磁盘上的高效检索方案,使得索引技术摆脱了内存空间的限制,得到了广泛的应用。 |
我们以查询用户信息为例。我们知道,一个系统中的用户信息非常多,除了有唯一标识的 ID 以外,还有名字、邮箱、手机、兴趣爱好以及文章列表等各种信息。一个保存了所有用户信息的数组往往非常大,无法全部放在内存中,因此我们会将它存储在磁盘中。
当我们以用户的 ID 进行检索时,这个检索过程其实并不需要读取存储用户的具体信息。因此,我们可以生成一个只用于检索的有序索引数组。数组中的每个元素存两个值,一个是用户 ID,另一个是这个用户信息在磁盘上的位置,那么这个数组的空间就会很小,也就可以放入内存中了。这种用有序数组做索引的方法,叫作线性索引(Linear Index)。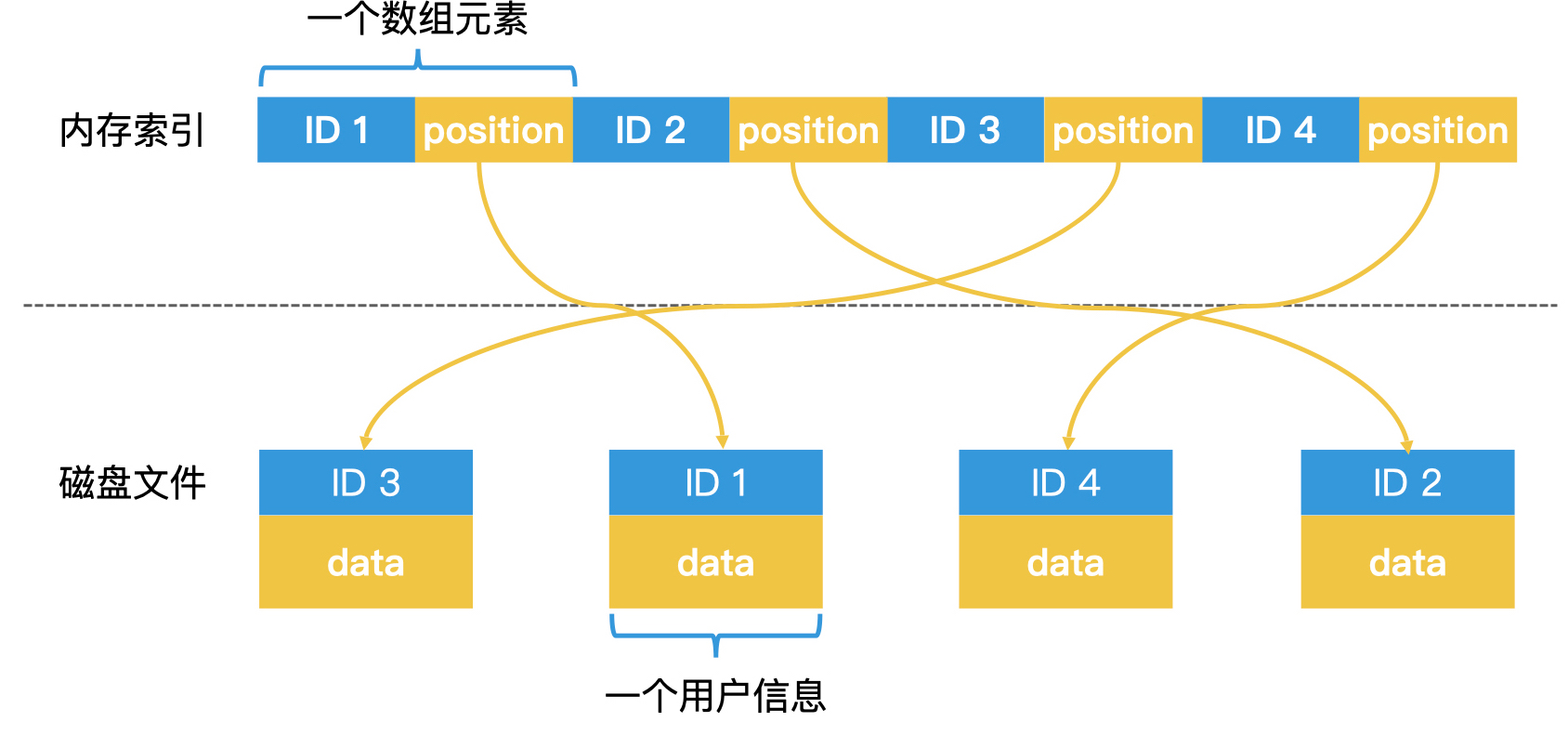
在数据频繁变化的场景中,有序数组并不是一个最好的选择,二叉检索树或者哈希表往往更有普适性。但是,哈希表由于缺乏范围检索的能力,在一些场合也不适用。因此,二叉检索树这种树形结构是许多常见检索系统的实施方案。那么,上图中的线性索引结构,就变成下图这个样子。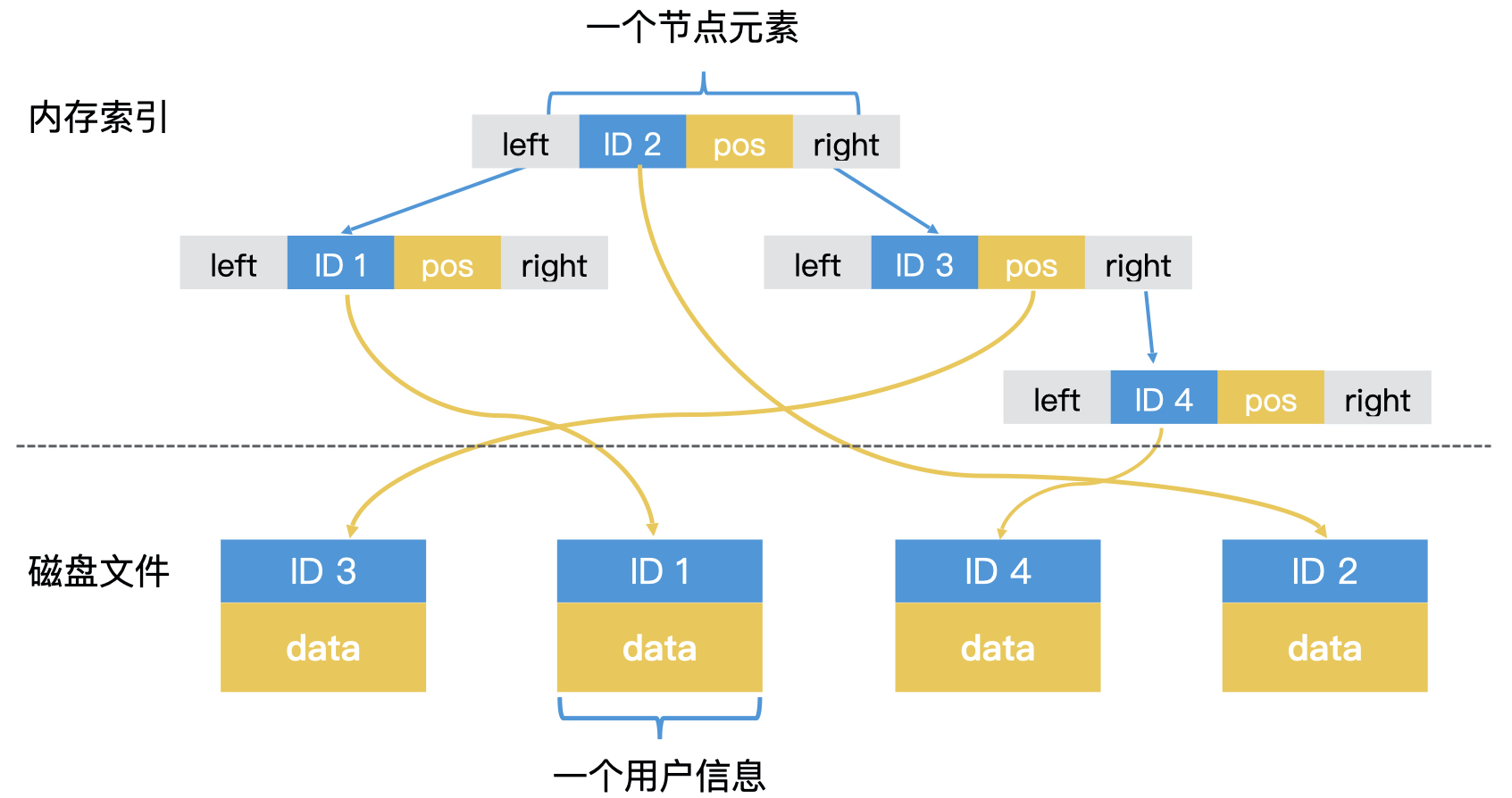
尽管二叉检索树可以解决数据动态修改的问题,但在索引数据很大的情况下,依然会有数据无法完全加载到内存中。这种情况我们应该怎么办呢?一个很自然的思路,就是将索引数据也存在磁盘中。那如果是树形索引,我们应该将哪些节点存入磁盘,又要如何从磁盘中读出这些数据进行检索呢?业界常用的解决方案是 B+ 树。
B+ 树的数据结构
由于操作系统对磁盘数据的访问是以块为单位的,如果我们想将树型索引的一个节点从磁盘中读出,即使该节点的数据量很小(比如说只有几个字节),但磁盘依然会将整个块的数据全部读出来,而不是只读这一小部分数据,这会让有效读取效率很低。B+ 树的一个关键设计,就是让一个节点的大小等于一个块的大小。节点内存储的数据,不是一个元素,而是一个可以装 m 个元素的有序数组。这样一来,我们就可以将磁盘一次读取的数据全部利用起来,使得读取效率最大化。
B+ 树还有另一个设计,就是将所有的节点分为内部节点和叶子节点。尽管内部节点和叶子节点的数据结构是一样的,但存储的内容是不同的。内部节点仅存储 key 和维持树形结构的指针,并不存储 key 对应的数据(无论是具体数据还是文件位置信息)。这样内部节点就能存储更多的索引数据,我们也就可以使用最少的内部节点,将所有数据组织起来了。而叶子节点仅存储 key 和对应数据,不存储维持树形结构的指针。通过这样的设计,B+ 树就能做到节点的空间利用率最大化。
此外,B+ 树还将同一层的所有节点串成了有序的双向链表,这样一来,B+ 树就同时具备了良好的范围查询能力和灵活调整的能力了。因此,B+ 树是一棵完全平衡的 m 阶多叉树。所谓的 m 阶,指的是每个节点最多有 m 个子节点,并且每个节点里都存了一个紧凑的可包含 m 个元素的数组。
B+ 树的检索
这样的结构,使得 B+ 树可以作为一个完整的文件全部存储在磁盘中。当从根节点开始查询时,通过一次磁盘访问,我们就能将文件中的根节点这个数据块读出,然后在根节点的有序数组中进行二分查找。
具体的查找过程:我们先确认要寻找的查询值,位于数组中哪两个相邻元素中间,然后我们将第一个元素对应的指针读出,获得下一个 block 的位置。读出下一个 block 的节点数据后,我们再对它进行同样处理。这样,B+ 树会逐层访问内部节点,直到读出叶子节点。对于叶子节点中的数组,直接使用二分查找算法,我们就可以判断查找的元素是否存在。如果存在,我们就可以得到该查询值对应的存储数据。如果这个数据是详细信息的位置指针,那我们还需要再访问磁盘一次,将详细信息读出。
我们前面说了,B+ 树是一棵完全平衡的 m 阶多叉树。所以,B+ 树的一个节点就能存储一个包含 m 个元素的数组,这样的话,一个只有 2 到 4 层的 B+ 树,就能索引数量级非常大的数据了,因此 B+ 树的层数往往很矮。比如说,一个 4K 的节点的内部可以存储 400 个元素,那么一个 4 层的 B+ 树最多能存储 400^4,也就是 256 亿个元素。
不过,因为 B+ 树只有 4 层,这就意味着我们最多只需要读取 4 次磁盘就能到达叶子节点。并且,我们还可以通过将上面几层的内部节点全部读入内存的方式,来降低磁盘读取的次数。
比如说,对于一个 4 层的 B+ 树,每个节点大小为 4K,那么第一层根节点就是 4K,第二层最多有 400 个节点,一共就是 1.6M;第三层最多有 400^2,也就是 160000 个节点,一共就是 640M。对于现在常见的计算机来说,前三层的内部节点其实都可以存储在内存中,只有第四层的叶子节点才需要存储在磁盘中。这样一来,我们就只需要读取一次磁盘即可。这也是为什么,B+ 树要将内部节点和叶子节点区分开的原因。通过这种只让内部节点存储索引数据的设计,我们就能更容易地把内部节点全部加载到内存中了。B+ 树的动态调整
插入数据
由于具体的数据都是存储在叶子节点上的,因此,数据的插入也是从叶子节点开始的。以一个节点有 3 个元素的 B+ 树为例,如果我们要插入一个 ID=6 的节点,首先要查询到对应的叶子节点。如果叶子节点的数组未满,那么直接将该元素插入数组即可。具体过程如下图所示: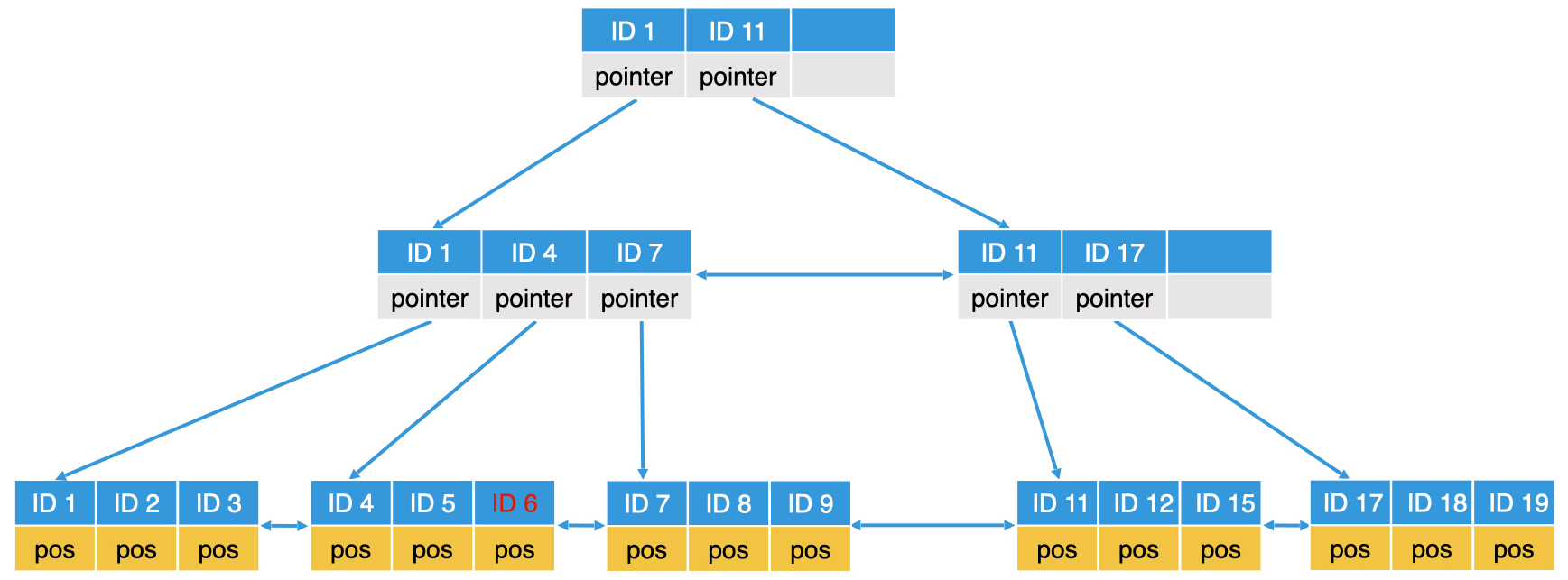
如果我们插入的是 ID=10 的节点呢?按之前的逻辑,我们应该插入到 ID 9 后面,但是 ID 9 所在的这个节点已经存满了 3 个节点,无法继续存入了。因此,我们需要将该叶子节点分裂。分裂的逻辑就是生成一个新节点,并将数据在两个节点中平分。如下图: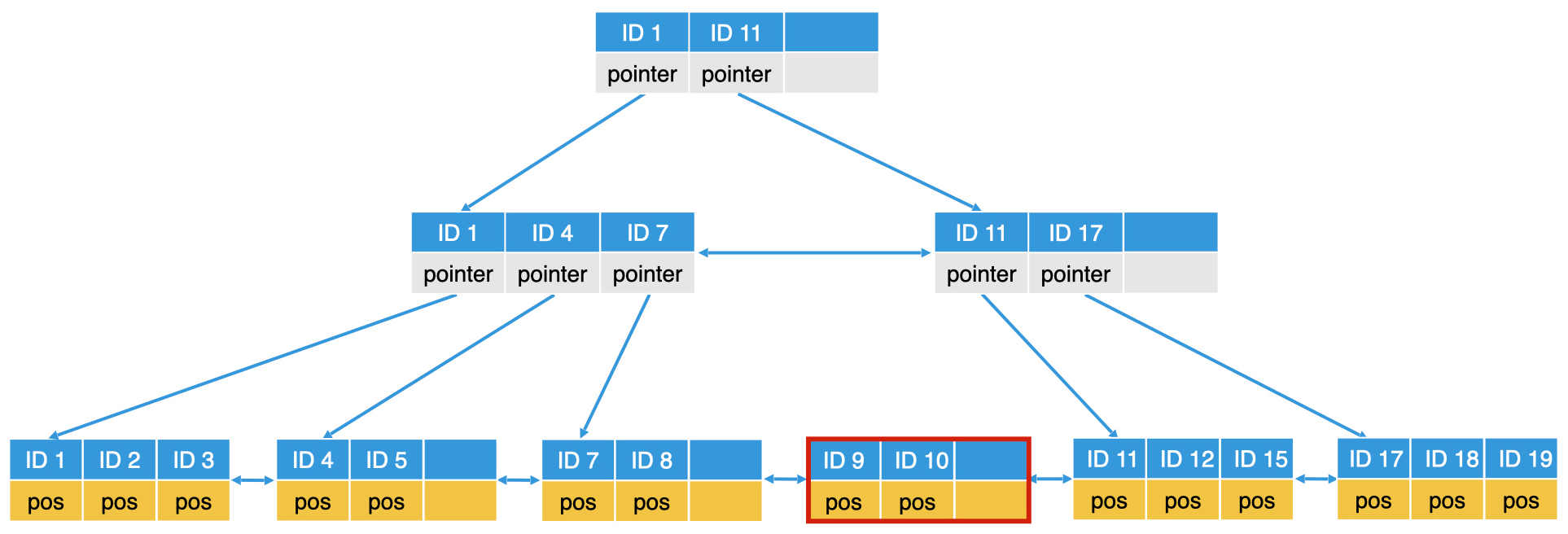
叶子节点分裂完成以后,上一层的内部节点也需要修改。但如果上一层的父节点也是满的,那么上一层的父节点也需要分裂。如下图: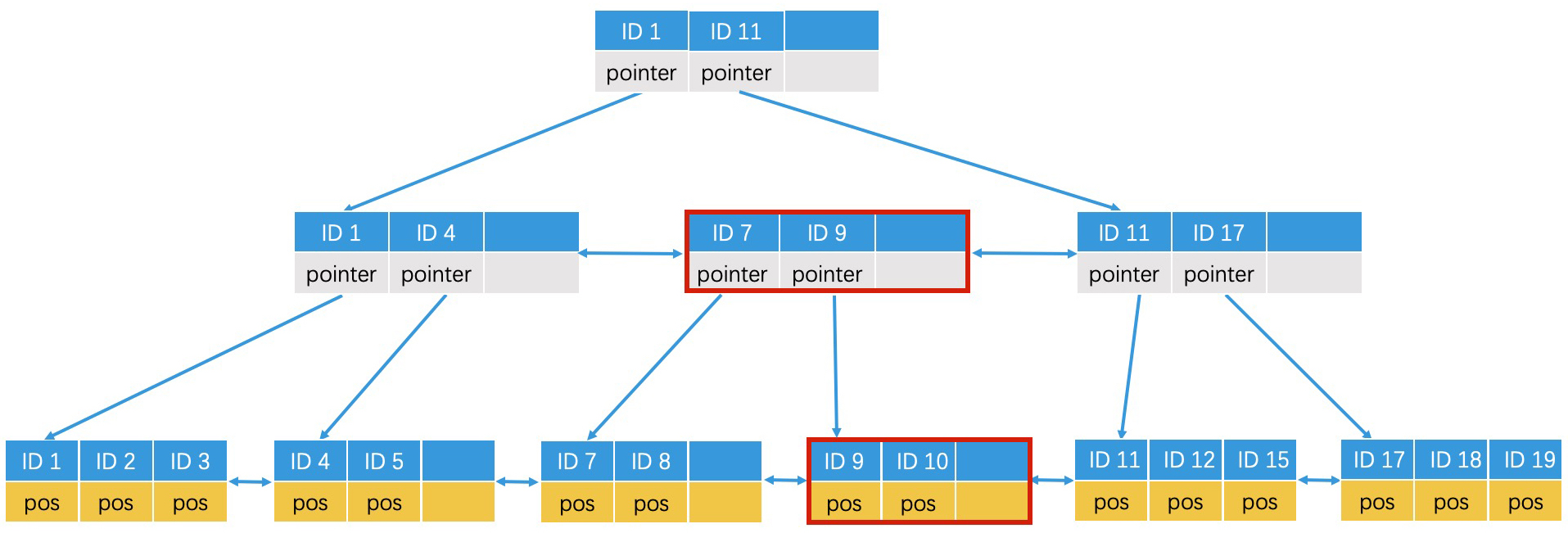
内部节点调整好了,下一步我们就要调整根节点了。由于根节点未满,因此我们不需要分裂,直接修改即可。如下图: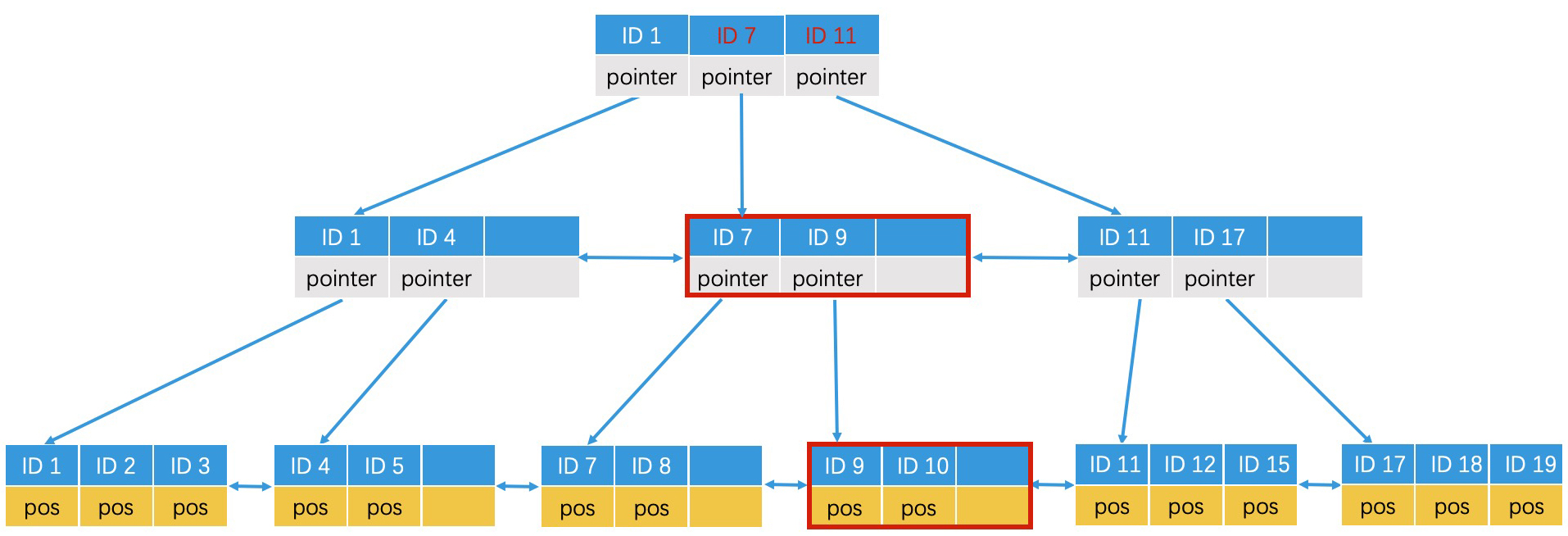
删除数据
与插入数据类似,如果节点数组较满,直接删除;如果删除后数组有一半以上的空间为空,那为了提高节点的空间利用率,该节点需要将左右两边兄弟节点的元素转移过来。可以成功转移的条件是,元素转移后该节点及其兄弟节点的空间必须都能维持在半满以上。如果无法满足这个条件,就说明兄弟节点其实也足够空闲,那我们直接将该节点的元素并入兄弟节点,然后删除该节点即可。
总结
即使是复杂的 B+ 树,我们将它拆解开来,其实也是由简单的数组、链表和树组成的,而且 B+ 树的检索过程其实也是二分查找。因此,如果 B+ 树完全加载在内存中的话,它的检索效率其实并不会比有序数组或者二叉检索树更高,也还是二分查找的 log(n) 的效率。并且,它还比数组和二叉检索树更加复杂,还会带来额外的开销。
但是,B+ 树最大的优点在于,它提供了将索引数据存在磁盘中,以及高效检索的方案。这让检索技术摆脱了内存的限制,得到了更广泛地使用。
另外,B +树很重要的一个设计思想需要你掌握,那就是将索引和数据分离。通过这样的方式,我们能将索引的数组大小保持在一个较小的范围内,让它能加载在内存中。在许多大规模系统中,都是使用这个设计思想来精简索引的。而且,B+ 树的内部节点和叶子节点的区分,其实也是索引和数据分离的一次实践。
06 | 数据库检索:如何使用B+树对海量磁盘数据建立索引?https://time.geekbang.org/column/article/221798

若有收获,就点个赞吧
0 人点赞
