kafak主要应用在大数据量场景下,在郑州项目中,300个小区的人脸抓拍和车辆抓拍每天大概在200w左右数据量,kafka consumer 是单线程设计,如何保证消息的及时快速消费,使用多线程或许是一种方法。
kafka consumer 设计原理
Kafka 0.10.1.0之前,KafkaConsumer 是单线程的设计。
Kafka 0.10.1.0 开始,KafkaConsumer 就变为了双线程的设计,即用户主线程和心跳线程。
- 用户主线程,就是你启动 Consumer 应用程序 main 方法的那个线程
- 而新引入的心跳线程(Heartbeat Thread)只负责定期给对应的 Broker 机器发送心跳请求,以标识消费者应用的存活性(liveness),并且它能将心跳频率与主线程调用 KafkaConsumer.poll 方法的频率分开,从而解耦真实的消息处理逻辑与消费者组成员存活性管理。
单线程设计的优点
- 以单线程 + 轮询的机制,较好地实现非阻塞式的消息获取
- 简化 Consumer 端的设计。Consumer 获取到消息后,处理消息的逻辑是否采用多线程,完全由你决定。
多线程方案
消费者程序启动多个线程,每个线程维护专属的 KafkaConsumer 实例,负责完整的消息获取、消息处理流程。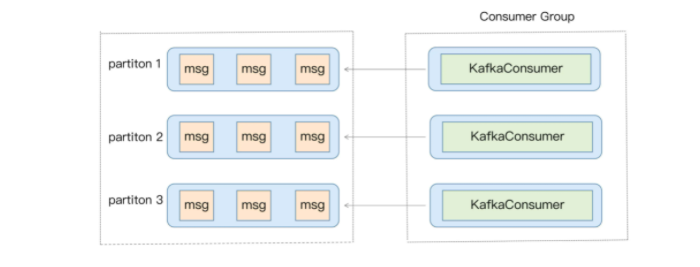
消费者程序使用单或多线程获取消息,同时创建多个消费线程执行消息处理逻辑
获取消息的线程可以是一个,也可以是多个,每个线程维护专属的 KafkaConsumer 实例,处理消息则交由特定的线程池来做,从而实现消息获取与消息处理的真正解耦。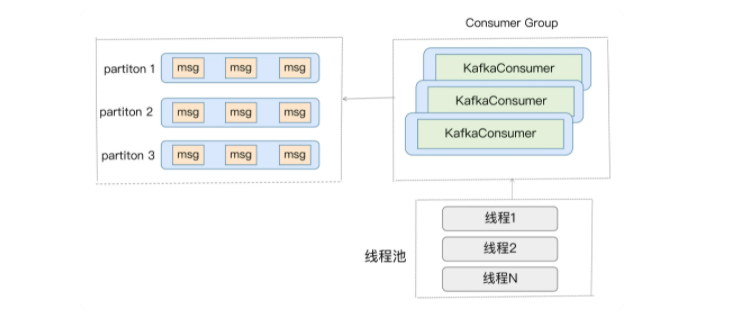
方案对比

伪代码实现
方案二
单consumer + 多 woker 来处理消息。consumer 只负责拉取消息,woker线程负责执行消息处理逻辑。
private final KafkaConsumer<String, String> consumer;private ExecutorService executors;...private int workerNum = ...;//根据业务实际情况创建线程池executors = new ThreadPoolExecutor(workerNum, workerNum, 0L, TimeUnit.MILLISECONDS,new ArrayBlockingQueue<>(1000),new ThreadPoolExecutor.CallerRunsPolicy());...while (true) {//拉取消息ConsumerRecords<String, String> records =consumer.poll(Duration.ofSeconds(1));//消息传递给线程池进行执行for (final ConsumerRecord record : records) {executors.submit(new Worker(record));}}..
方案二的思考:
1.offset怎么管理?
2.是手动提交还是自动提交?
3.选择手动提交时,如果某个线程链路上出现异常,导致超时,会触发rebalance。如果选择自动提交,异步处理消息逻辑如果出现异常会导致消息丢失。
4.如何选择合适的方式管理offset的提交,来保证消息尽快消费。
读者的实现 :
@wukong
1、消息放在数据库或者redis这种不会丢失的队列中,多线程消费队列
2、使用闭锁工具,多个线程处理完毕之后再提交位移。
@linken
方案二可以这样第一个线程组poll消息并落地到db提交offset,第二个线程组读取db处理业务逻辑
详细实现

若有收获,就点个赞吧
0 人点赞
