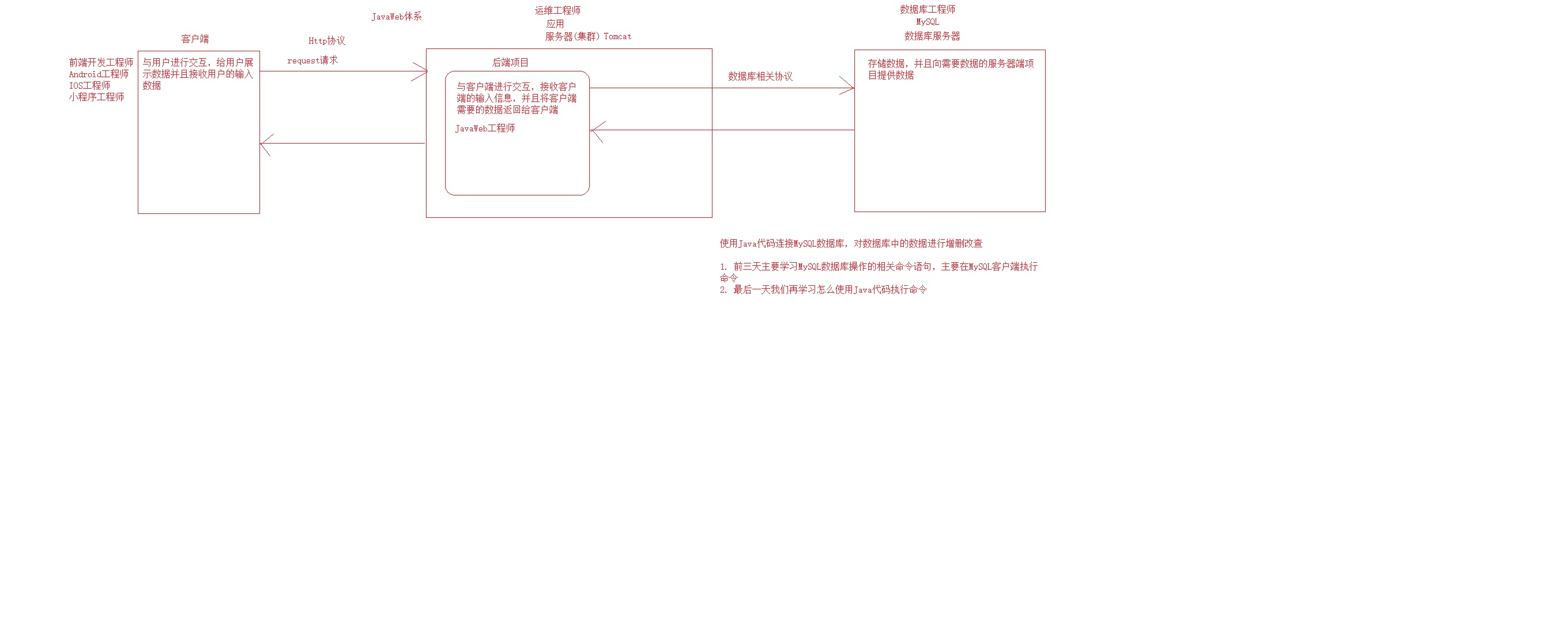
关系型数据库设计规程
- 遵循ER模型
- E entity 代表实体的意思 对应到数据库当中的一张表
- R relationship 代表关系的意思
- 具体体现
- 将数据放到表中,表再放到库中。
- 一个数据库中可以有多个表,每个表都有一个名字,用来标识自己。表名具有唯一性。
- 表具有一些特性,这些特性定义了数据在表中如何存储,类似java和python中 “类”的设计。
- 表由列组成,我们也称为字段。每个字段描述了它所含有的数据的意义,数据表的设计实际上就是对字段的设计。创建数据表时,为每个字段分配一个数据类型,定义它们的数据长度和字段名。每个字段类似java 或者python中的“实例属性”。
- 表中的数据是按行存储的,一行即为一条记录。每一行类似于java或python中的“对象”。
MySQL启动
“我的电脑/计算机”—>右键—>“管理”—>“服务”—>启动和关闭MySQL服务
“开始菜单”—>“控制面板”—>“管理工具”—>“服务”—>启动和关闭MySQL
“任务管理器”—>“服务”—>启动和关闭MySQL
以管理员身份打开命令行
net start MySQL服务名
net stop MySQL服务名
客户端连接mysql
命令:
mysql -h 主机IP地址 -P 端口号 -u 用户名 -p回车
Enter Password:密码
sql
sql分类:
- Data Definition Language (DDL数据定义语言) 如:操作数据库,操作表
- Data Manipulation Language(DML数据操纵语言),如:对表中的记录操作增删改
- Data Query Language(DQL 数据查询语言),如:对表中数据的查询操作
- Data Control Language(DCL 数据控制语言),如:对用户权限的设置
mysql的语法要求:
(1)mysql的sql语法不区分大小写
MySQL的关键字和函数名等不区分大小写,但是对于数据值是否区分大小写,和字符集与校对规则有关。
ci(大小写不敏感),cs(大小写敏感),_bin(二元,即比较是基于字符编码的值而与language无关,区分大小写)
(2)命名时:尽量使用26个英文字母大小写,数字0-9,下划线,不要使用其他符号
(3)建议不要使用mysql的关键字等来作为表名、字段名等,如果不小心使用,请在SQL语句中使用`(飘号)引起来
(4)数据库和表名、字段名等对象名中间不要包含空格
(5)同一个mysql软件中,数据库不能同名,同一个库中,表不能重名,同一个表中,字段不能重名
(6)标点符号:
必须成对
必须英文状态下半角输入方式
字符串和日期类型可以使用单引号’’
列的别名可以使用双引号””,给表名取别名不要使用双引号。取别名时as可以省略
如果列的别名没有包含空格,可以省略双引号,如果有空格双引号不能省略。
(7)SQL脚本中如何加注释
单行注释:#注释内容
单行注释:—空格注释内容 其中—后面的空格必须有
多行注释:/ 注释内容 /
DDL操作
创建数据库:
create database 数据库名 [character set 字符集][collate 校对规则] 注: []意思是可选的意思
查看所有数据库
show databases;
查看数据库结构
show create database 数据库名;
删除数据库
drop database 数据库名;
修改数据库
alter database 数据库名 character set 字符集;
切换数据库, 选定哪一个数据库
use 数据库名; //注意: 在创建表之前一定要指定数据库. use 数据库名
查看正在使用的数据库
select database();
DDL操作表
创建表
create table 表名(
列名 类型 [约束],
列名 类型 [约束]
...
);
查看所有表
show tables;
查看表的结构
desc student;
修改表
- 增加一列
alter table 【数据库名.]表名称 add 【column】 字段名 数据类型;
alter table 【数据库名.]表名称 add 【column】 字段名 数据类型 first;
alter table 【数据库名.]表名称 add 【column】 字段名 数据类型 after 另一个字段;
- 修改列的类型约束:
alter table 表名 modify 字段 类型 约束 ; - 修改列的名称,类型,约束:
alter table 表名 change 旧列 新列 类型 约束; - 删除一列:
alter table 表名 drop 列名; - 修改表名 :
rename table 旧表名 to 新表名;
掌握表
drop table teacher;
约束
- 即规则,规矩 限制;
- 作用:保证用户插入的数据保存到数据库中是符合规范的 | 约束 | 约束关键字 | | | —- | —- | —- | | 主键 | primary key | 非空且唯一,并且一张表只能有一个主键 | | 唯一 | unique | 唯一,当前列不能出现相同的数据 | | 非空 | not null | 非空,当前列不能为null | | 默认 | default | 如果当前列没有数据,则指定默认数据 |
约束种类:
- not null: 非空 ; eg: username varchar(40) not null username这个列不能有null值
- unique:唯一约束, 后面的数据不能和前面重复; eg: cardNo char(18) unique; cardNo 列里面不可以有重复数据
- primary key;主键约束(非空+唯一); 一般用在表的id列上面. 一张表基本上都有id列的, id列作为唯一标识的
- auto_increment: 自动增长,必须是设置了primary key之后,才可以使用auto_increment
- id int primary key auto_increment; id不需要我们自己维护了, 插入数据的时候直接插入null, 自动的增长进行填充进去, 避免重复了.
注意:
- 先设置了primary key 再能设置auto_increment
- 只有当设置了auto_increment 才可以插入null , 否则插入null会报错
id列:
- 给id设置为int类型, 添加主键约束, 自动增长
- 或者给id设置为字符串类型,添加主键约束, 不能设置自动增长
DML操作表
新增
insert into 表名(列,列..) values(值,值..);
更新
update 表名 set 列 =值, 列 =值 [where 条件]
删除表
delete from 表名 [where 条件] 注意: 删除数据用delete,不用truncate
工作中删除数据
- 物理删除: 真正的删除了, 数据不在, 使用delete就属于物理删除
- 逻辑删除: 没有真正的删除, 数据还在. 搞一个标记, 其实逻辑删除是更新 eg: state 1 启用 0禁用
DQL操作表
查询
select 要查询的字段名 from 表名 [where 条件]
查询某张特定列
select 列名,列名,列名... from 表
去重查询 distinct
SELECT DISTINCT 字段名 FROM 表名; //要数据一模一样才能去重
别名查询
select 列名 as 别名 ,列名 from 表 //列别名 as可以不写
select 别名.* from 表 as 别名 //表别名(多表查询, 明天会具体讲)
运算查询(+,-,*,/,%等)
select pname ,price+10 as price from product;
select name,chinese+math+english as total from student
> 注意
- 运算查询字段,字段之间是可以的
- 字符串等类型可以做运算查询,但结果没有意义
条件查询
select ... from 表 where 条件
//取出表中的每条数据,满足条件的记录就返回,不满足条件的记录不返回
运算符
大于:>
小于:<
大于等于:>=
小于等于:<=
等于:= 不能用于null判断
不等于:!= 或 <>
安全等于: <=> 可以用于null值判断
逻辑运算符(建议用单词,可读性来说)
逻辑与:&& 或 and
逻辑或:|| 或 or
逻辑非:! 或 not
逻辑异或:^ 或 xor
范围
区间范围:between x and y
not between x and y
集合范围:in (x,x,x)
not in (x,x,x)
模糊 模糊查询和正则匹配(只针对字符串类型,日期类型)
like 'xxx' 模糊查询是处理字符串的时候进行部分匹配
如果想要表示0~n个字符,用%
如果想要表示确定的1个字符,用_
特殊的null值处理
#(1)判断时
xx is null
xx is not null
xx <=> null
单列排序
语法: 只按某一个字段进行排序,单列排序
SELECT 字段名 FROM 表名 [WHERE 条件] ORDER BY 字段名 [ASC|DESC]; //ASC: 升序,默认值; DESC: 降序组合排序
语法: 同时对多个字段进行排序,如果第1个字段相等,则按第2个字段排序,依次类推、
SELECT 字段名 FROM 表名 WHERE 字段=值 ORDER BY 字段名1 [ASC|DESC], 字段名2 [ASC|DESC];聚合函数
聚合函数通常会和分组查询一起使用,用于统计每组的数据
聚合函数列表
| 聚合函数 | 作用 |
|---|---|
| max(列名) | 求这一列的最大值 |
| min(列名) | 求这一列的最小值 |
| avg(列名) | 求这一列的平均值 |
| count(列名) | 统计这一列有多少条记录 |
| sum(列名) | 对这一列求总和 |
SELECT 聚合函数(列名) FROM 表名 [where 条件];
注意: 聚合函数会忽略空值NULL
我们发现对于NULL的记录不会统计,建议如果统计个数则不要使用有可能为null的列,但如果需要把NULL也统计进去呢?我们可以通过 IFNULL(列名,默认值) 函数来解决这个问题. 如果列不为空,返回这列的值。如果为NULL,则返回默认值。
分组查询
GROUP BY将分组字段结果中相同内容作为一组,并且返回每组的第一条数据,所以单独分组没什么用处。分组的目的就是为了统计,一般分组会跟聚合函数一起使用
SELECT 字段1,字段2... FROM 表名 [where 条件] GROUP BY 列 [HAVING 条件];
分组后筛选 having
- 练习根据性别分组, 统计每一组学生的总人数> 5的(分组后筛选)
SELECT sex, count() FROM student GROUP BY sex HAVING count() > 5
where和having的区别【面试】
| 子名 | 作用 |
|---|---|
| where 子句 | 1) 对查询结果进行分组前,将不符合where条件的行去掉,即在分组之前过滤数据,即先过滤再分组。2) where后面不可以使用聚合函数 |
| having字句 | 1) having 子句的作用是筛选满足条件的组,即在分组之后过滤数据,即先分组再过滤。2) having后面可以使用聚合函数 |
分页查询
select ... from .... limit a ,b
| LIMIT a,b; |
|---|
| a 表示的是跳过的数据条数 |
| b 表示的是要查询的数据条数 |
查询的语法小结
select...from...where...group by...order by...limit
select...from...where...
select...from...where...order by...
select...from...where...limit...
select...from...where...order by...imit
导入和导出数据(了解)
单个数据库备份 mysql5.5
C:\Windows\System32> mysqldump -h主机地址 -P端口号 -u用户名 -p密码 —database 数据库名 > 文件路径/文件名.sql
mysql5.7版
C:\Windows\System32> mysqldump -h主机地址 -P端口号 -u用户名 -p密码 数据名 > 文件路径/文件名.sql
导入执行备份的sql脚本
先登录mysql,然后执行如下命令:
mysql> source sql脚本路径名.sql

若有收获,就点个赞吧
0 人点赞
