Slate is a completely customizable framework for building rich text editors.
语雀使用的就是Slate,Slate有三个库:
- slate: 包括数据模型和操作
- slate-react: view层,用于rendering
-
Concepts
数据模型
slate 将整个文档抽象成一棵Node Tree, 每个Node有三种类型:
Editor: 只作为根节点
- Element: 中间节点,可以是block (这里是指抽象的block,可以是一个html block, 也可以是多个html block组合成的一个block), 也可以是inline
- Text: 叶子节点, 也是一种 inline
有一些约束条件(通过 editor.normalizeNode() 来实现):
- Editor节点只能包含Block节点(为了保证始终存在Block节点,从而可以split block)
- Element节点的子节点要么都是Block Element, 要么都是Inline Element 或 Text
- Element节点必须包含至少一个子节点(自动插入一个空Text节点)
- Inline Element节点不能是第一个、最后一个子节点,不能相邻 (我认为是为了方便插入Text)
- 相邻的Text节点,属性相同的话会合并
操作
操作有high level的 Commands 和 low level 的 Operations
- Commands 表示的是 user 执行的操作,在 Editor object中以helper functions实现。另外 Transforms也提供一套helper functions. 每个Command 会分解成一系列 Operations. 你可以扩展自定义的Commands.
- Operations 由 Editor interface定义,包括所有可能的low level操作,不可扩展。
对节点的操作应使用 Transforms 或 Editor API, 不能直接改变editor节点的值。因为Slate给editor赋予了immutability (在哪?因为React state需要?), editor的值是 read only 的。
Plugins
plugins 主要通过以下几项实现:
- 重写Editor interface中的operations 和 定义新的 Editor helper functions
- 重写Editor Component的RenderElement,RenderLeaf, onKeyDown等props
API Details
API 有 Interface 和 Helper Function两种,例如 Node 既可以作为 Inteface,也作为一个 object提供helper functions.
API 既要从Node tree的角度来理解,又要从文档界面位置的角度来理解。例如 Transforms.insertNodes() 的一个Location 参数就代表它在Node tree中的插入位置,但是如果是在一个Text节点中插入Block节点会如何呢,这里如果从文档角度来看就很明显它应该实现的效果了。
Tree and List
整个数据结构可以看作一棵Node tree, 根节点是一个Editor, 中间节点都是Element, 叶子节点都是Text. 如果再算上Text中的offset的话, 可以将每个offset看作Leaf节点的(虚)子节点,叶节点都是character, 称之为Offset tree.
Node是按出现在document的顺序排序的(可以看html标签的开始位置),相当于对Node tree做前序遍历,称之为Node list. 如果只保留leaf节点的话,就叫Text list. 如果再算上offset的话,对应的就分别叫做Offset list, Point list.
从文档界面来讲,一个Point就是一个光标可能的位置,Point list 就是光标按顺序可以在的位置,Range就是两个光标的位置,它的含义是表示两个光标之间的内容(例如selection).
Range
任意一个Location都对应一个 Node list, Text List, Offset list, Point list, Range.
- 任意Node作为root的子树对应的 Node/Text/Offset/Point list 是整棵树的 Node/Text/Offset/Point list的一个子list (连续的interval)
- Range 就是整棵树的Offset list的一种特殊子list:第一个element和最后一个element都是Point
A range is hanging if: range.start.offset === 0 && range.end.offset === 0 && Range.isExpended(range))
unhang 的作用好像是把 end从当前节点的开头调整到前一个节点的结尾
Range.includes(range:Range, target: Path | Point | Range): boolean
- target 是 Point的话,显然
- target 是 Range的话,只需要range包括 target.anchor 或 target.focus中的至少一个
target 是 Path的话,需要 target 在 range.anchor.path和range.focus.path的中间 (包括端点,用Path.compare 比较)
Node
Node.nodes(root:Node, {from:Path, to:Path, reverse, pass})
按前序遍历的顺序(如果reverse的话则从右到左)返回与[from, to] 有重叠的所有节点(跳过满足pass的)考虑root的Node list(前序遍历(reverse是指先访问最右边的子节点), 遍历时跳过满足pass的节点)
- 删去
Path.isBefore(p, from)和Path.isAfter(p,to)的nodes (注意这里from的ancestors和to的decendants都既不满足isBefore也不满足isAfter) - 按顺序yield剩下的nodes
Node.elements , Node.descendants , Node.texts 都只是 Node.nodes 的筛选
Node.fragment(root, range:Range): Descendants[]
获得root的一个子树,使得该子树刚好包含range对应的text (可能要split Text节点)。使用 immer 来保证不改变原来的root对应的树
Editor
Editor.path(editor, at: Location, {depth, edge})
返回包含at的edge的最长Path(无edge的话需包含整个at)的深度为depth的子Path
- 如果at是Range, 有edge的话根据edge找到对应的Point对应的Path, 否则找LCA
- 如果at是Point的话,找到它对应的Path
- at是Path的话, 根据edge(如果有的话)找到at所在节点的第一个leaf子节点的path
- 然后取它的深度为depth(如果有的话)的subpath
Editor.above(editor, {at, match, mode, voids})
返回at所在path上方第一个match的节点
Editor.point(editor, at: Location, edge):Point
返回at对应的Point list 中第一个 (或最后一个) Point
- 如果at是Point的话,直接返回它;如果at是Range的话,直接返回该Range的第一个(或最后一个)Point
- 如果at是Path的话,找到该节点的Leaf list中的第一个(或最后一个)节点,返回它的第一个(或最后一个)offset
Editor.above(editor, {at, match, mode})
返回at对应的path上方第一个或最后一个非Text节点
editor.insert**() 在createEditor中定义成 Transforms.insert**(editor,)
editor.selection 是Range类型,这意味着它的anchor和focus都在Text节点中
Editor.nodes(editor, {at, match, mode, universal, reverse, voids})
- 先找到at对应的起止Path, 记为(from, to)
- 遍历
Node.nodes(editor, {reverse, from, to, pass}),跳过不match的node. 其中pass是指如果voids == false则跳过Void Elements。 如果universal == false的话mode === 'all', yield 所有遇到的nodemode === 'highest, yield所有分支中match到的最高的node (如果一个node yield了,那么它的decendants都不考虑)mode === lowest, yield所有分支中match到的最低的node- 如果
universal == true的话,则要求遍历的每个分支中至少有一个node, 否则整个函数返回空
Editor.previous(editor, {at, match, mode, voids}) , 返回 Editor.nodes(editor, {reverse:true, at:{from,to},match, mode, voids}) 中的第二个节点。其中 from 是at对应的左叶节点,to是整棵Node tree的左叶节点。
mode === lowest并且match === null- 如果 at是Path , 找的是它的左sibling(不存在刚返回空);
- 否则找的是at对应的叶节点的前一个叶节点(Text list)。
mode === lowest并且match !== null, 要看具体的matchmode为all和highest,或者match比较一般化的时候,返回的节点好奇怪,好像没什么意义
Refs
Refs are used to wrap a varible, registering it in global weakmaps. Some operations may change it, keeping it up to date.
Transforms
Transforms.transform(eidtor, op) 都是做简单的比较低级的操作,默认参数是有效的。其中 transform(editor, {path, type: 'split-node', position}) 是将path节点split成两个,position前的children和position后的children分别放到它们的下面。对比之下, Transforms.splitNodes(editor, {at}) 则是比较高级的操作,是把at(假设是Path) 所在的节点的父节点split成两个,使得at对应的节点及其右边的节点放到后面那个节点的下面(有可能不只split一个节点,具体要看参数)。
Transforms.splitNodes(editor, {at, match, mode, always, height, voids})
假设at范围内没有空节点或者voids为true,
- 如果at是Path, 将at的父节点split成两个,分别拥有at的左边和右边节点作为子节点
- 如果at是Range, 先将该Range删除,at变为Point
- 如果at是Point
- 如果match是空,则match block;如果height为空,则为0
- 令highest为
Editor.nodes(editor, {at, match, mode, voids})中第一个(最高的)节点 - 令lowest为at.path往上走height所在的节点
- 根据at的position, split 从lowest向上一直到highest的节点
如果voids为false, 并且at范围内有空节点
令highest与上面一样
- 令voidNode 为at所在branch第一个空节点(从上到下)
- 如果voidNode是一个inline Element,令at为at后面的Point (如果不存在,就插入一个空Text节点, 注意这里可以插入Text节点是因为它左边的节点是inline)
- 令lowest为voidNode的父节点
- 根据at的位置 split 从lowest向上一直到highest的节点
好吧,我还是不知道这是在干啥
Transforms.insertNodes(editor, nodes, {at, match, mode, hanging, select, voids})
- at为Range的话,变为它的end point
- at为Point,
- match为空的话,根据插入的第一个节点的类型来设置match
- 找到
Editor.nodes(editor, {at:at.path, match, mode, voids})中的第一个节点entry - 如果entry不存在,直接返回。
- 否则先在at位置
Transforms.splitNodes- 如果at是在entry的end point, 则将at置为entry的next path
- 否则将at置为entry的path
- 将nodes插入到at位置
Normalizing
有个全局的Normalizing开关,只有在开的时候 Editor.normalize(editor) 才会工作。 Editor.normalize(editor) 会对所有存储的DirtyPaths 执行 editor.normalize(node)
Editor.withoutNormalizing(editor, fn) 是先把开关关闭,再执行 fn , 再把开关恢复(不是打开,但我看源码好像没有其它地方有打开或关闭的操作,并且开关初始化为开,因此这里的恢复估计都是打开)
Transforms 库里面 Transforms.transform(editor, op) 以及Selection相关的transform是不会调用Editor.withoutNormalizing 的,其它transforms都会调用
normalizeNode([node, nodePath]) 主要做以下几种事
- node 是 Text 的话,直接返回
- node没有children,则插入一个空Text
- 根据该node是否inline,以及它的第一个child是否inline来决定它的children应该是block还是inline
- 遍历每一个child
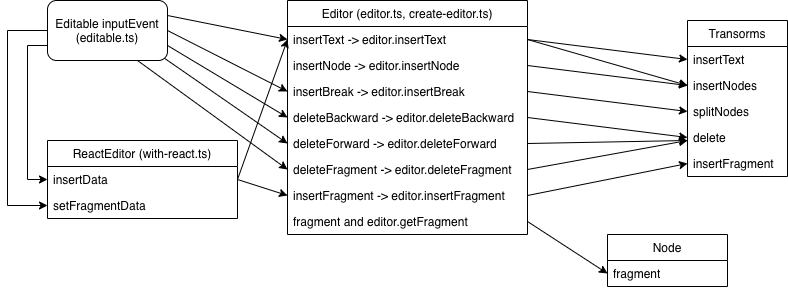
核心示意图
下图中,实线表示函数调用,虚线表示参数来源。只包括核心的对象,其它如editor.marks, editor.selection相关的略去。
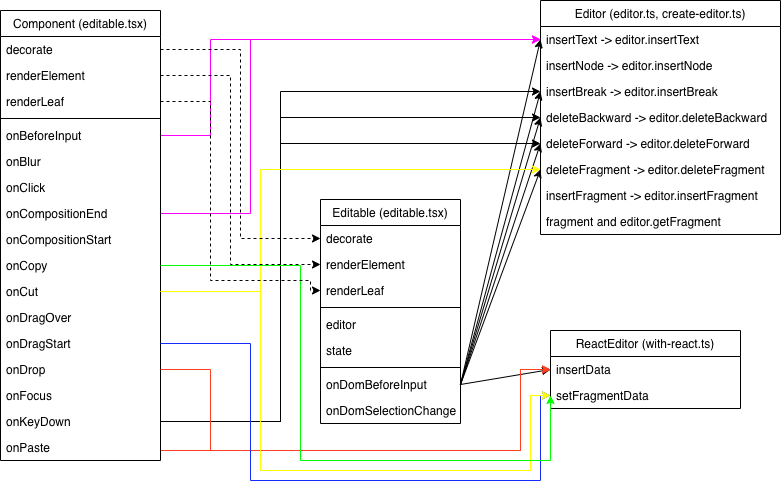
界面上编辑器对应上图中的Component,有以下几种情况
- onBeforeInput: 处理绝大部分的输入。图中的连线是使用React的onBeforeInput (因为有些浏览器不支持onBeforeInput). React主要是通过 onDomBeforeInput 来处理输入 (将onDomBeforeInput注册成 onBeforeInput的listener)
- onCopy, onPaste, onCut, onDrop等 (其中Composition是指如输入法之类的输入)
- onKeyDown: 处理其它快捷键(自定义)输入
OnBeforeInput会在以下几种情况触发
- 删除的话,如果selection是expanded, 则调用 deleteFragment, 否则调用 deleteBackward 或 deleteForward
- 插入的情况,如果是 insertLineBreak (按shift+enter) 或 insertParagraph (按enter), 则调用 insertBreak; 否则调用 insertText
- 格式化如formatBold
注意:
- 传入的handler参数如果”处理好了Event” (event.isDefaultPrevented 或 event.isPropergationStopped), Component定义的 handler 触发后啥也不干。
- 键盘快捷键cut, copy, undo, redo 不会触发 Component的 OnBeforeInput. (不知道是为啥)它们都会触发onKeyDown, cut, copy还会触发onCut, onCopy
事件调用
Editor.deleteBackward(unit)
在selection collapsed时,按del键
Editor.deleteFragment()
在selection expanded时,按del键
Editor.insertBreak()
按Enter键
Editor.insertText()
按普通键,不包括Tab
Editor.insertFragment()
onCut, onPaste, onCopy
onKeyDown
按任意键
Miscs
Slate 仓库中的Test使用了自定义的jsx, 核心在于实现这样一个函数(函数名可任取):jsx(tagNameOrComponent, attributes, ...children)
参考:using-jsx-without-react
实现代码主要是在源文件 slate-hyperscript/src/hyperscript.ts

若有收获,就点个赞吧
0 人点赞
