第13章:用隐写术隐藏数据
steganography 一词是希腊词 steganos(意为覆盖、隐藏或保护)和 graphien (意为书写)的组合。 在安全方面,steganography是指用于通过将数据植入其他数据(例如图像)中来混淆(或隐藏)数据的技术和程序,以便可以在未来的某个时间点提取数据。作为安全社区的一员,通过隐藏交付给目标后恢复的有效负载来研究这一常规实践。
在本章中,你将植入 Portable Network Graphics(PNG)图片的数据。首先研究PNG格式,并学习如何读取PNG数据。 然后将自己的数据植入到现存的图像中。最后,探索XOR,一种加解密植入数据的方法。
探索PNG格式
先从查看PNG说明开始,这有助于理解PNG图像的格式,及如何将数据植入到文件中。 在http://www.libpng.org/pub/png/spec/1.2/PNG-Structure.html 查看技术文档。 上面有PNG图像二进制文件的字节格式的详细信息,该文件由重复字节块组成。
在十六进制编辑器中打开PNG文件,浏览每个相关字节块组件查看其作用。 我们使用 Linux 上原生的 hexdump 十六进制编辑器,其实任何十六进制编辑器都应该可以。 可以在https://github.com/blackhat-go/bhg/blob/master/ch-13/imgInject/images/battlecat.png 上查看我们打开的示例图片;不过,所有有效的PNG图片都将遵循相同的格式。
头
图像文件的前8个字节,89 50 4e 47 0d 0a 1a 0a,被称为 header 在图13-1中高亮标记。
 图13-1:PNG文件头
图13-1:PNG文件头
转换为ASCII时,逐个读取PNG的第二、三、四个十六进制值。任意的末尾字节由DOS和Unix Carriage-Return Line Feed (CRLF)组成。这种特定的头序列,称为文件的 magic bytes,在每个有效的PNG文件中都是相同的。内容的变化发生在剩余的块中,很快就会看到。
我们按照规范来完成,从在Go中构建表示PNG格式开始。 这将帮助我们加快嵌入有效载荷的最终目标。 因为头长是8字节,可以封装成uint64数据类型,因此继续构建 Header 结构体来保存该值(清单 13-1)。 (所有代码清单在github https://github.com/blackhat-go/bhg/ 跟目录下。)
//Header holds the first UINT64 (Magic Bytes)type Header struct {Header uint64}
清单 13-1:定义Header结构体 (/ch-13/imgInject/pnglib/commands.go)
序列块
PNG文件的其余部分,如图13-2所示,由遵循此模式的重复字节块组成:SIZE(4字节),TYPE(4字节),DATA(任意数量的字节),和CRC(4字节)。
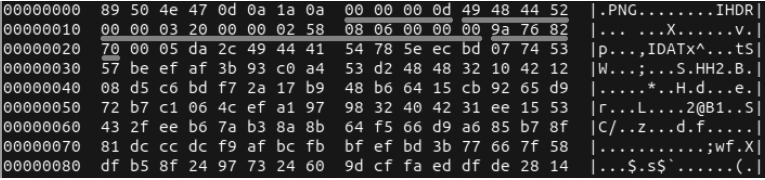 图13-2 图像数据剩余块及模式
图13-2 图像数据剩余块及模式
进一步查看十六进制转储,您可以看到第一个块——SIZE块——由字节0x00 0x00 0x00 0x0d组成。 这个块定义接下来的DATA块的长度。 该十六进制转换成ASCII是13——这表示DATA块由13个字节组成。 TYPE 块的字节是 0x49 0x48 0x44 0x52,本例中转换成IHDR的ASCII值。PNG规范定义了各种有效的类型。 其中一些类型,如IHDR用于定义图像的元数据,或标志图像数据流的结束。其他类型,特别是IDAT类型,表示实际图像的字节。
接下来是DATA块,长度由SIZE块定义。 最后,CRC块结束了整个块段。 它由 TYPE 和 DATA 字节的 CRC-32 校验和组成。 这个CRC块的字节是 0x9a 0x76 0x82 0x70。 这种格式在整个图像文件中不断重复,直到End of File (EOF)状态,该状态由类型为IEND的块表示。
像清单13-1中那样定义Header结构,构建一个结构来保存单个块,如清单13-2中所示。
//Chunk represents a data byte chunk segmenttype Chunk struct {Size uint32Type uint32Data []byteCRC uint32}
清单 13-2:定义Chunk结构体 (/ch-13/imgInject/pnglib/commands.go)
读取图片的字节数据
Go语言能相对容易地处理二进制数据的读写,这在一定程度上要归功于 binary 包(在第6章的时候介绍过),但是在解析PNG数据前需要先打开文件来读取。 创建PreProcessImage() 函数,参数为 *os.File 类型的文件句柄,且返回值为 *bytes.Reader 类型(清单13-3)。
//PreProcessImage reads to buffer from file handlefunc PreProcessImage(dat *os.File) (*bytes.Reader, error) {stats, err := dat.Stat()if err != nil {return nil, err}var size = stats.Size()b := make([]byte, size)bufR := bufio.NewReader(dat)_, err = bufR.Read(b)bReader := bytes.NewReader(b)return bReader, err}
清单 13-3:定义 PreProcessImage() 函数 (/ch-13/imgInject/utils/reader.go)
函数打开文件对象,以获取用于抓取大小信息的 FileInfo 结构体。 接下来的几行代码用过 bufio.NewReader() 实例化一个 Reader 实例,然后调用 bytes.NewReader() 生成 *bytes.Reader 实例。 函数返回一个 *bytes.Reader 类型,用于开始使用 binary 包读取字节数据。 先读取头数据,再读取序列块。
读取头数据
使用定义PNG文件的前8个字节验证文件是否是PNG文件,构建 validate() 方法(清单13-4)。
func (mc *MetaChunk) validate(b *bytes.Reader) {var header Headerif err := binary.Read(b, binary.BigEndian, &header.Header); err != nil {log.Fatal(err)}bArr := make([]byte, 8)binary.BigEndian.PutUint64(bArr, header.Header)if string(bArr[1:4]) != "PNG" {log.Fatal("Provided file is not a valid PNG format")} else {fmt.Println("Valid PNG so let us continue!")}}
清单 13-4: 验证是否是 PNG 文件 (/ch-13/imgInject/pnglib/commands.go)
尽管此方法可能看起来并不太复杂,但它引入了几个新条目。 首先,也是最明显的一个是 binary.Read() 函数,该函数从 bytes.Reader 复制8个字节到 Header 结构体中。 还记得定义的定义的 Header 结构体中,字段类型为 uint64(清单13-1),相当于8个字节。 同样值得注意的是, binary 包提供了通过 binary.BigEndian 和 binary.LittleEndian 分别读取 Most Significant Bit 和 Least Significant Bit 格式的方法。 当进行二进制写时,这些函数也十分有用;例如,可以使用 BigEndian 将字节放在指定使用网络字节排序的线路上。
二进制字节序函数还包含有助于将数据类型编码为文字数据类型(例如 uint64)的方法。 这里创建了一个长度为8的字节数组,并执行二进制读取,将数据复制到uint64数据类型中。 然后将字节转换为字符串形式,并使用切片和简单的字符串比较来确认1到4字节是PNG字符串,标志着这是个有效的图片文件格式。
为优化查验文件是否为PNG文件这一过程,我们鼓励你查阅Go的bytes 包,因为含有简便的函数,可以使用这些函数快捷地进行文件头和之前提到过的PNG魔法字节序列的比较。 自己去研究吧。
读取序列块
一旦验证了是PNG文件,就可以写读取序列块的代码了。 头在PNG文件中只出现一次,但序列块是SIZE, TYPE, DATA, 和 CRC 的重复,直到EOF。 因此,需要合适地处理这种重复,Go中的条件循环可以方便地做到。 基于此,构建 ProcessImage() 方法,迭代地处理所有的数据块,直到文件末尾(清单13-5)。
func (mc *MetaChunk) ProcessImage(b *bytes.Reader, c *models.CmdLineOpts) {// Snip code for brevity (Only displaying relevant lines from code block)count := 1 //Start at 1 because 0 is reserved for magic bytechunkType := ""endChunkType := "IEND" //The last TYPE prior to EOFfor chunkType != endChunkType {fmt.Println("---- Chunk # " + strconv.Itoa(count) + " ----")offset := chk.getOffset(b)fmt.Printf("Chunk Offset: %#02x\n", offset)chk.readChunk(b)chunkType = chk.chunkTypeToString()count++}}
清单13-5:ProcessImage() 方法 (/ch-13/imgInject/pnglib/commands.go)
首先传递将一个对 bytes.Reader 内存地址指针 (*bytes.Reader) 的引用作为参数传递给 ProcessImage()。 刚刚创建的validate() 方法(清单13-4)也使用一个 bytes.Reader 指针的引用。 按照约定,对同一个内存地址指针位置的多次引用将允许对引用数据的可变访问。 这实质上意味着将 bytes.Reader 引用作为参数传递给 ProcessImage() 时,由于Header的大小,读取器已经前进了8个字节,因为访问的是相同的 bytes.Reader 实例。
或者,没有传递指针, bytes.Reader 要么是相同的PNG图像数据的副本,要么是单独的唯一实例数据。 这是因为,读取header时推进指针不会在其他地方适当地推进读取器。 需要避免采用这种方式。 一方面,在不必要的情况下传递多个数据副本只是一种糟糕的约定。 更重要的是,每次传递副本时,它都被定位在文件的开头,迫使在读取块序列之前通过编程定义和管理它在文件中的位置。
随着代码块的进行,定义 count 变量来记录图像文件包含多少块段。 chunkType 和 endChunkType 作为比较逻辑的一部分,将 chunkType 和 endChunkType’s IEND 来比较作为 EOF 的条件。
最好知道每个块段从哪里开始——或者更确切地说,每个块在文件字节结构中的绝对位置,被称为 offset。 如果知道偏移值,非常容易地将负载植入到文件中。 例如,可以将一组偏移位置提供给解码器—— 一个单独的函数,用于收集每个已知偏移处的字节,然后将它们展开为您想要的有效负载。 要取到每个块的偏移,需要调用 mc.getOffset(b) 方法(清单13-6)。
func (mc *MetaChunk) getOffset(b *bytes.Reader) {offset, _ := b.Seek(0, 1)mc.Offset = offset}
清单13-6:getOffset(b) 方法 (/ch-13/imgInject/pnglib/commands.go)
bytes.Reader 中有个 Seek() 方法,该方法可以非常简单地取得当前位置。 Seek() 方法移动当前的读取或写入偏移,然后返回相对于文件开头的新的偏移。 该方法的第一个参数是要移动偏移量的字节数,第二个参数定义将要发生移动的位置。 第二个参数的可选值是0(文件开头),1(当前位置),和2(文件末尾)。 例如,想从当前位置左移8字节,可以使用 b.Seek(-8,1)。
在这里,b.Seek(0,1) 表示从当前位置偏移0字节,因此仅仅返回当前偏移:本质上检索偏移量而不移动它。
下面的方法中详细定义了如何读取实际的块段字节。 为了更容易理解,创建readChunk() 方法,然后创建读取每个子块的单独方法(清单13-7)。
func (mc *MetaChunk) readChunk(b *bytes.Reader) {mc.readChunkSize(b)mc.readChunkType(b)mc.readChunkBytes(b, mc.Chk.Size)mc.readChunkCRC(b)}func (mc *MetaChunk) readChunkSize(b *bytes.Reader) {if err := binary.Read(b, binary.BigEndian, &mc.Chk.Size); err != nil {log.Fatal(err)}}func (mc *MetaChunk) readChunkType(b *bytes.Reader) {if err := binary.Read(b, binary.BigEndian, &mc.Chk.Type); err != nil {log.Fatal(err)}}func (mc *MetaChunk) readChunkBytes(b *bytes.Reader, cLen uint32) {mc.Chk.Data = make([]byte, cLen)if err := binary.Read(b, binary.BigEndian, &mc.Chk.Data); err != nil {log.Fatal(err)}}func (mc *MetaChunk) readChunkCRC(b *bytes.Reader) {if err := binary.Read(b, binary.BigEndian, &mc.Chk.CRC); err != nil {log.Fatal(err)}}
清单 13-7:块读取方法 (/ch-13/imgInject/pnglib /commands.go)
readChunkSize(), readChunkType(), 和 readChunkCRC() 是相似的。 每个读取 uint32 值到各自的 Chunk 结构体的字段中。 然而,readChunkBytes() 有点不一样。 因为图片数据的长度是可变的,需要将这个长度提供给readChunkBytes() 函数,以便知道要读取多少字节。 回想下,数据长度是在SIZE子块中维护的。 识别出 SIZE 的值,将其作为参数传递给 readChunkBytes() 用于定义切片的合适大小。 只有这样,才能将字节数据读入结构体的 data 字段。 这就是读取数据的方法,让我们继续研究如何写入字节数据。
写入图像字节数据以植入有效载荷
尽管可以从许多复杂的隐写技术中进行选择来植入有效载荷,但在本节中,将重点介绍一种写入特定字节偏移量的方法。PNG 文件格式定义了规范中的 critical 和 ancillary 。critical 块是图像解码器处理图像所必需的。ancillary 是可选的,并提供对编码或解码不重要的各种元数据,例如时间戳和文本。
因此, ancillary 块类型提供了覆盖现有块或插入新块的理想位置。在这里,我们将展示如何将新的字节片插入到 ancillary 块段中。
定位块偏移量
首先,需要在ancillary数据中确定适当的偏移量。您可以发现ancillary块,因为它们总是以小写字母开头。再次使用十六进制编辑器打开原始 PNG 文件,并前进到十六进制转储的末尾。
每个有效的 PNG 图像都有一个IEND 块类型,指示文件的最后一个块(EOF 块)。 移动到最终 SIZE 块之前的4个字节,处于 IEND 块的起始偏移量和整个PNG文件中包含的任意(critical 或 ancillary)块的最后一个偏移量。 回想下辅助块是可选的,因此在本文中所检查的文件可能没有相同的辅助块,或者与此相关的任何辅助块。 在我们的示例中,IEND块的偏移量从字节偏移量0x85258开始(图13-3)。
 图13-3 识别相对于
图13-3 识别相对于 IEND 位置的块偏移
使用 ProcessImage() 方法写入字节
将有序字节写入字节流的标准方法是使用Go结构体。 让我们重新查看清单13-5中开始构建的 ProcessImage() 方法的另一部分,并浏览其中的细节。 清单13-8中的代码调用各个函数,将在本节中逐步构建这些函数。
func (mc *MetaChunk) ProcessImage(b *bytes.Reader, c *models.CmdLineOpts) {--snip--var m MetaChunkm.Chk.Data = []byte(c.Payload)m.Chk.Type = m.strToInt(c.Type)m.Chk.Size = m.createChunkSize()m.Chk.CRC = m.createChunkCRC()bm := m.marshalData(){bmb := bm.Bytes()fmt.Printf("Payload Original: % X\n", []byte(c.Payload))fmt.Printf("Payload: % X\n", m.Chk.Data)utils.WriteData(b, c, bmb)}
清单13-8:
使用 ProcessImage() 方法写入字节(/ch-13/imgInject/pnglib/commands.go)
该方法使用 byte.Reader 和另一个结构体 models.CmdLineOpts 作为参数。 CmdLineOpts 结构体如清单13-9 所示,含有通过命令行传入的标志。 这些标志确定使用什么样的负载,及将其插入的图片数据中的位置。 因为你要写的字节遵循相同的结构化格式,从已经存在的块段读取,可以创建一个新的 MetaChunk 结构体实例来接受新的块段值。
下一步是将负载读取到字节切片中。 但是,需要额外的功能强制把文字标志放到可用的字节数组中。 我们来深入研究 strToInt(), createChunkSize(), createChunkCRC(), MarshalData(), WriteData() 这些方法的细节。
package models//CmdLineOpts represents the cli argumentstype CmdLineOpts struct {Input stringOutput stringMeta boolSuppress boolOffset stringInject boolPayload stringType stringEncode boolDecode boolKey string}
清单 13-9:CmdLineOpts 结构体 (/ch-13/imgInject/models/opts.go)
strToInt() 方法
先从 strToInt() 方法开始(清单13-10)。
func (mc *MetaChunk) strToInt(s string) uint32 {t := []byte(s)return binary.BigEndian.Uint32(t)}
清单 13-10: strToInt() 方法(/ch-13/imgInject/pnglib/commands.go)
strToInt() 方法将 string 转换成 uint32,是 Chunk 结构体 TYPE 值所需要的数据类型。
createChunkSize() 方法
接下来使用 createChunkSize() 方法创建 Chunk 结构体 SIZE 值 (清单13-11)。
func (mc *MetaChunk) createChunkSize() uint32 {return uint32(len(mc.Chk.Data))}
清单 13-11: createChunkSize() 方法 (/ch-13/imgInject/pnglib/commands.go)
这个方法取得 chk.DATA 字节数组的长度,并将类型转换成 uint32。
createChunkCRC() 方法
回想一下,每个块段的CRC校验和包括 TYPE 和 DATA 字节。 用createChunkCRC() 方法计算该校验和。 该方法利用 Go 的 hash/crc32 包(清单13-12)。
func (mc *MetaChunk) createChunkCRC() uint32 {bytesMSB := new(bytes.Buffer)if err := binary.Write(bytesMSB, binary.BigEndian, mc.Chk.Type); err != nil {log.Fatal(err)}if err := binary.Write(bytesMSB, binary.BigEndian, mc.Chk.Data); err != nil {log.Fatal(err)}return crc32.ChecksumIEEE(bytesMSB.Bytes())}
清单 13-12:createChunkCRC() 方法 (/ch-13/imgInject/pnglib/commands.go)
在返回语句之前,声明 bytes.Buffer,并将 TYPE 和 DATA 字节写入其中。 缓冲区中的字节切片作为参数传递给 ChecksumIEEE, 且 CRC-32 校验和作为 uint32 字节类型被返回。 return 语句在这里做了所有繁重的工作,实际上是在必要的字节上计算校验和。
marshalData() 方法
块的所有必要部分都被分配给它们各自的结构体字段中,现在可以编码到 bytes.Buffer 中。 缓冲区提供要插入到新图像文件中的自定义块的原始字节。 清单 13-13 是 marshalData() 方法。
func (mc *MetaChunk) marshalData() *bytes.Buffer {bytesMSB := new(bytes.Buffer)if err := binary.Write(bytesMSB, binary.BigEndian, mc.Chk.Size); err != nil {log.Fatal(err)}if err := binary.Write(bytesMSB, binary.BigEndian, mc.Chk.Type); err != nil {log.Fatal(err)}if err := binary.Write(bytesMSB, binary.BigEndian, mc.Chk.Data); err != nil {log.Fatal(err)}if err := binary.Write(bytesMSB, binary.BigEndian, mc.Chk.CRC); err != nil {log.Fatal(err)}return bytesMSB}
清单 13-13: marshalData() 方法 (/ch-13/imgInject/pnglib/commands.go)
marshalData() 方法声明 bytes.Buffer,并将包括大小、类型、数据、校验和在内的块信息写入其中。 该方法将所有块段数据返回到单个合并的 bytes.Buffer 中。
WriteData() 函数
现在剩下要做的就是将新的块段字节写入到原始PNG图像文件的偏移量中。让我们瞥一眼 WriteData() 函数,它存在于我们创建的名为 utils 包中(清单13-14)。
//WriteData writes new Chunk data to offsetfunc WriteData(r *bytes.Readeru, c *models.CmdLineOptsv, b []bytew) {offset, _ := strconv.ParseInt(c.Offset, 10, 64)w, err := os.Create(c.Output)if err != nil {log.Fatal("Fatal: Problem writing to the output file!")}defer w.Close()r.Seek(0, 0)var buff = make([]byte, offset)r.Read(buff)w.Write(buff)w.Write(b)_, err = io.Copy(w, r)if err == nil {fmt.Printf("Success: %s created\n", c.Output)}}
清单 13-14: WriteData() 函数 (/ch-13/imgInject/utils/writer.go)
WriteData() 函数使用一个含有原始图片文件字节数据的 bytes.Reader,一个含有命令行参数值的 models.CmdLineOpts 结构体,和一个 保存有新块字节段的字节切片。 代码块以 string-to-int64 转换开始,以便从 models.CmdLineOpts 结构体中获取偏移值;这将帮助您将新的块段写入特定位置,而不会损坏其他块。 然后创建文件句柄,以便将新修改的PNG图片写入到磁盘。
调用 r.Seek(0,0) 函数回到 bytes.Reader 绝对位置的开头。回想下前8个字节是为PNG头预留的,所以新的输出PNG图像也要包含这些头字节是很重要的。实例化一个由 offset 确定长度的字节切片,将这些字节保存到切片中。然后从原始图片中读取一定数量的字节,并将相同的字节写入到新的图片文件中。现在原始和新图片中是一样的头了。
然后将新断块写入到新图片文件中。向新图片文件追加剩余的 bytes.Reader 字节(也就是原始图像的块段字节)。回想下 bytes.Reader 推进到的偏移位置,因为之前读取到的字节切片包含了从 offset 到EOF的字节。得到了一个新图片文件。新文件具有与原始图像相同的前导和尾块,但是它还包含作为新的辅助块注入的有效负载。
为了解迄今为止所做的项目进度,请参考 https://github.com/blackhat-go/bhg/tree/master/ch-13/imgInject/ 上的整个项目代码。imgInject 程序使用命令行参数,其中包含原始PNG图像文件、偏移位置、任意数据有效负载、自声明的任意块类型,以及修改后的PNG图像文件的输出文件名,如清单13-15所示。
$ go run main.go -i images/battlecat.png -o newPNGfile --inject –offset \ 0x85258 --payload 1234243525522552522452355525
清单 13-15: 运行 imgInject 命令行程序
如果一切都按照计划进行,offset 0x85258 现在应该包含一个新的rNDm块段,如图13-4所示。
 图13-4 作为辅助块注入的有效载荷(例如rNDm)
图13-4 作为辅助块注入的有效载荷(例如rNDm)
恭喜——已经完成了第一个隐写程序!
使用 XOR 编解码图片字节数据
正如有许多类型的隐写术一样,也有许多技术用于混淆二进制文件中的数据。我们继续构建上一节中的示例程序。这次,使用模糊处理来隐藏有效负载的真正意图。
混淆可以隐藏有效负载,不让网络监视设备和端点安全解决方案看到。 例如,如果嵌入用于生成新的Meterpreter shell或Cobalt Strike信标的原始shellcode,当然希望确保它避免被检测到。 为此,要使用Exclusive OR位操作对数据进行加密和解密。
Exclusive OR (XOR) 是两个二进制值之间的条件比较,当且仅当两个值不一样时返回true,否则的话返回false。 换句话说,如果x或y中有一个为真,这个命题为真,但如果两个都为真就不成立了。 可以在表13-1中看到这一点,因为x和y都是二进制输入值。
表 13-1:XOR 真值表 | x | y | x^y | | —- | —- | —- | | 0 | 1 | True 或 1 | | 1 | 0 | True 或 1 | | 0 | 0 | False 或 0 | | 1 | 1 | False 或 0 |
可以使用此逻辑通过比较数据中的位与密钥中的位来混淆数据。 当两个值相等时,将有效负载中的位更改为0,当它们不同时,您将其更改为1。 让我们展开上一节中创建的代码,包括 encodeDecode() 函数,以及 XorEncode() 和 XorDecode() 函数。 将这些函数放在 utils 包中(清单 13-16)。
func encodeDecode(input []byteu, key stringv) []byte {var bArr = make([]byte, len(input))for i := 0; i < len(input); i++ {bArr[i] += input[i] ^ key[i%len(key)]}return bArr}
清单 13-16: encodeDecode() 函数 (/ch-13/imgInject/utils/encoders.go)
encodeDecode() 函数以负载的字节切片和秘钥作为参数。 函数中创建 bArr 字节切片,并以输入的字节长度初始化(负载的长度)。 接下来,函数使用条件循环迭代输入字节数组的每个索引位置。
在条件循环内,每次迭代都将当前索引的二进制值与从当前索引值的模和秘钥长度导出的二进制值进行XORs。 这可以使用一个比负载短的key。 当到达key的末尾时,模将强制下一次迭代使用key的第一个字节。 每次XOR操作的结果写到新 bArr 字节切片中,函数返回结果切片。
清单13-17中的函数封装了 encodeDecode()函数,以方便编码和解码过程。
// XorEncode returns encoded byte arrayfunc XorEncode(decode []byte, key string) []byte {return encodeDecode(decode, key)}// XorDecode returns decoded byte arrayfunc XorDecode(encode []byte, key string) []byte {return encodeDecode(encode, key)}
清单 13-17: XorEncode() 和 XorDecode() 函数(/ch-13/imgInject/utils/encoders.go)
定义两个函数,XorEncode() 和 XorDecode(), 使用相同的参数,且返回相同的值。 这是因为编码过程和解码过程使用相同的XOR编码数据。 但是,分别定义这两个函数是让代码更清晰。
要在现有的程序中使用 XOR,需要修改清单13-8中创建的 ProcessImage() 逻辑。 使用 XorEncode() 函数加密负载来更新。 如清单13-18所示的修改,假设使用命令行参数将值传递给条件编码和解码逻辑。
// Encode Blockif (c.Offset != "") && c.Encode {var m MetaChunkm.Chk.Data = utils.XorEncode([]byte(c.Payload), c.Key)m.Chk.Type = chk.strToInt(c.Type)m.Chk.Size = chk.createChunkSize()m.Chk.CRC = chk.createChunkCRC()bm := chk.marshalData()bmb := bm.Bytes()fmt.Printf("Payload Original: % X\n", []byte(c.Payload))fmt.Printf("Payload Encode: % X\n", chk.Data)utils.WriteData(b, c, bmb)}
清单 13-18: XOR 编码更新ProcessImage() (/ch-13/imgInject/pnglib/commands.go)
函数调用 XorEncode() ,传递含有负载字节切片和key,即XOR的两个值,将返回的字节切片赋值给 chk.Data。 其余功能保持不变,并封送新块段,以便最终写入图像文件。
程序的命令行运行应该产生类似于清单13-19中的结果。
$ go run main.go -i images/battlecat.png --inject --offset 0x85258 --encode \--key gophers --payload 1234243525522552522452355525 --output encodePNGfileValid PNG so let us continue!Payload Original: 31 32 33 34 32 34 33 35 32 35 35 32 32 35 35 32 35 32 32 34 35 32 33 35 35 35 32 35Payload Encode: 56 5D 43 5C 57 46 40 52 5D 45 5D 57 40 46 52 5D 45 5A 57 46 46 55 5C 45 5D 50 40 46Success: encodePNGfile created
清单 13-19:运行imgInject程序对数据块进行XOR编码
payload 被写入到字节表示并作为Payload Original显示到标准输出。 然后用值为gophers的key对 payload 进行 XOR, 并作为 Payload Encode 显示。
要解密负载字节,使用解码函数,如清单13-20。
//Decode Blockif (c.Offset != "") && c.Decode {var m MetaChunkoffset, _ := strconv.ParseInt(c.Offset, 10, 64)b.Seek(offset, 0)m.readChunk(b)origData := m.Chk.Datam.Chk.Data = utils.XorDecode(m.Chk.Data, c.Key)m.Chk.CRC = m.createChunkCRC()bm := m.marshalData()bmb := bm.Bytes()fmt.Printf("Payload Original: % X\n", origData)fmt.Printf("Payload Decode: % X\n", m.Chk.Data)utils.WriteData(b, c, bmb)}
清单 13-20:解码图片文件和负载 (/ch-13/imgInject/pnglib/commands.go)
代码块需要包含有效负载的块段的偏移位置。 使用该偏移来 Seek() 文件位置,以及后续调用readChunk()来获取 SIZE、TYPE、DATA 和 CRC 值所必需的。 使用 chk.Data 负载值和相同的秘钥调用 XorDecode() 编码数据,然后将解码的值再赋值给 chk.Data 。(记住,这是对称加密,因此您使用相同的密钥来加密和解密数据。)继续调用 marshalData(),将 Chunk 结构体转换为字节切片。 最后,使用 WriteData() 函数将包含已解码有效负载的新块段写入文件。
程序这次带有解码参数的命令行运行,应该生成如清单13-21所示的结果。
$ go run main.go -i encodePNGfile -o decodePNGfile --offset 0x85258 –decode \--key gophersValid PNG so let us continue!Payload Original: 56 5D 43 5C 57 46 40 52 5D 45 5D 57 40 46 52 5D 45 5A 57 46 46 55 5C 45 5D 50 40 46Payload Decode: 31 32 33 34 32 34 33 35 32 35 35 32 32 35 35 32 35 32 32 34 35 32 33 35 35 35 32 35Success: decodePNGfile created
清单 13-21:运行imgInject程序对数据 XOR 解码
从原始PNG文件中读取的 Payload Original 被编码成负载数据,而 Payload Decode 被解密成负载。 如果比较前面例子运行的命令行和这里的输出,会注意到解码后的负载与最初提供的原始明文值匹配。
不过,代码有个问题。 记得程序代码将在规范的偏移位置注入新的已解码块。 如果已经包含编码的块段的文件,然后尝试用一个解码的块段编写一个新文件,那么将在新的输出文件中得到两个块。可以在图13-5中看到这一点。
 图13-5 含有解码和编码块段文件的输出
图13-5 含有解码和编码块段文件的输出
要理解为什么会发生这种情况,请回想一下已编码的PNG文件在偏移量为0x85258处有已编码的块段,如图13-6所示。
 图13-6 含有编码块段文件的输出
图13-6 含有编码块段文件的输出
当解码数据被写入偏移量0x85258时,问题就出现了。解码数据被写入与编码数据相同的位置时,我们不会删除编码数据;它只是将文件字节的其余部分向右移动,包括编码的块段,如前面图13-5所示。这可能会使负载提取复杂化或产生意想不到的后果,例如将明文负载透露给网络设备或安全软件。
幸运的是,这个问题很容易解决。看一下之前的 WriteData() 函数。这一次可以修改该函数来解决问题(清单13-22)。
//WriteData writes new data to offsetfunc WriteData(r *bytes.Reader, c *models.CmdLineOpts, b []byte) {offset, err := strconv.ParseInt(c.Offset, 10, 64)if err != nil {log.Fatal(err)}w, err := os.OpenFile(c.Output, os.O_RDWR|os.O_CREATE, 0777)if err != nil {log.Fatal("Fatal: Problem writing to the output file!")}r.Seek(0, 0)var buff = make([]byte, offset)r.Read(buff)w.Write(buff)w.Write(b)if c.Decode {r.Seek(int64(len(b)), 1)}_, err = io.Copy(w, r)if err == nil {fmt.Printf("Success: %s created\n", c.Output)}}
清单 13-22:更新 WriteData() 以防止重复辅助块类型 (/ch-13/imgInject/utils/writer.go)
使用 c.Decode 条件逻辑引入修复。 XOR 操作产生一个字节对字节的事务。 因此,编码和解码的块段长度相同。 此外,bytes. reader 将在写入已解码的块段时要包含原始编码图像文件的其余部分。 因此,可以在 bytes.Reader 上执行包含解码块段长度的右字节移位,将 bytes.Reader 推进经过编码的块段并将剩余字节写入新的图像文件。
瞧!如图 13-7 所示,十六进制编辑器确认问题已解决。 不再有重复的辅助块类型。
 图13-7 无重复的辅助块段文件的输出
图13-7 无重复的辅助块段文件的输出
编码数据不在了。此外,对文件运行 ls -la应该会产生相同的文件长度,即使文件字节已经改变。
总结
在本章中,学习了如何将 PNG 图像文件格式描述为一系列重复的字节块段,每个块段都有各自的用途和适用性。 接下来,学习了读取和浏览二进制文件的方法。 然后创建字节数据并将其写入图像文件。 最后,使用 XOR 编码来混淆负载。
本章重点介绍图像文件,只是触及了使用隐写技术可以完成的工作的皮毛。 但是您应该能够应用在本章学到的知识来研究其他二进制文件类型。
附加练习
与本书中的其他章节一样,跟着本章一起编码和练习是最有价值。 因此,希望通过一些任务来扩展已经涉及到的想法:
当阅读XOR部分时,应该注意到
XorDecode()函数生成已解码的块段,但是并没有更新CRC校验和。 看看能不能纠正这个问题。WriteData()函数方便注入辅助块段的能力。 如果要覆盖现有的辅助块段,必须进行哪些代码更改? 如果需要帮助,我们关于字节移位和Seek()函数的解释可能对解决这个问题有用。这是一个更具挑战性的问题:尝试注入一个负载——PNG DATA 字节块——通过将其分布在各种辅助块段中。 可以一次执行一个字节,也可以使用多个字节分组,所以要有创造力。 作为额外的好处,创建一个解码器来读取准确的负载的字节偏移位置,从而更容易提取负载。
本章解释了如何使用XOR作为加密技术——一种混淆植入负载的方法。 尝试实现不同的技术,如AES加密。 Go 的核心代码包提供了许多可能性(如果需要复习,请参阅第11章)。 观察解决方案如何影响新图像。它会导致整体大小增加吗??如果会,增加多少?
使用本章中的代码思想来扩展对其他图像文件格式的支持。 其他图像规格可能不像PNG那样有组织。要证据吗?请阅读PDF规范,因为它可能相当令人生畏。 如何解决将数据读写到这种新的图像格式的挑战?

若有收获,就点个赞吧
0 人点赞

{kind=link}