容错
如Actor系统 中所述,每一个actor是其子actor的监管者 , 而且每一个actor会定义一个处理错误的监管策略。这个策略制定以后不能修改,因为它集成为actor系统结构的一部分。
1 实际中的错误处理
首先我们来看一个例子,演示处理数据存储错误的一种方法,数据存储错误是真实应用中的典型错误类型。当然在实际的应用中这要依赖于当数据存储发生错误时能做些什么,在这个例子中,我们使用尽量重新连接的方法。
阅读以下源码。其中的注释解释了错误处理的各个片段以及为什么要加上它们。我们还强烈建议运行这个例子,因为根据日志输出来理解运行时都发生了什么会比较容易。
容错例子的图解
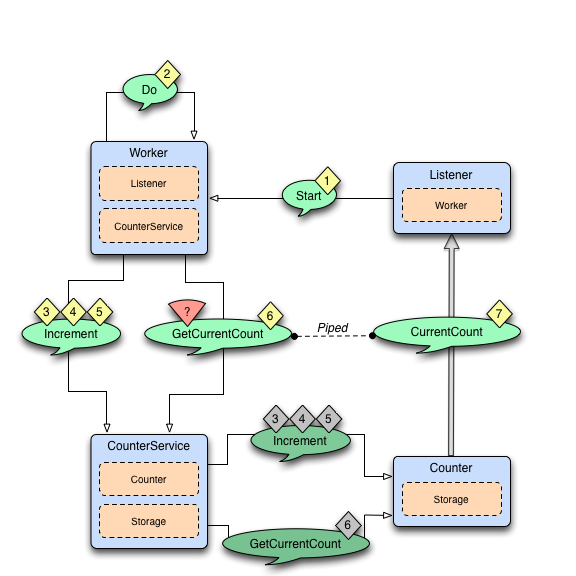
上图展示了正常的消息流。
正常流程:
| 步骤 | 描述 |
|---|---|
| 1 | Listener启动工作的过程。 |
| 2 | Worker 通过定期向自己发送 Do 消息来安排工作 |
| 3、4、5 | 接收到Do时Worker通知CounterService更新计数器值, 三次。Increment消息被转发给Counter, 它会更新自己的计数器变量并将当前值发给Storage。 |
| 6、7 | Worker向CounterService请求计数器的当前值并将结果回送给Listener。 |
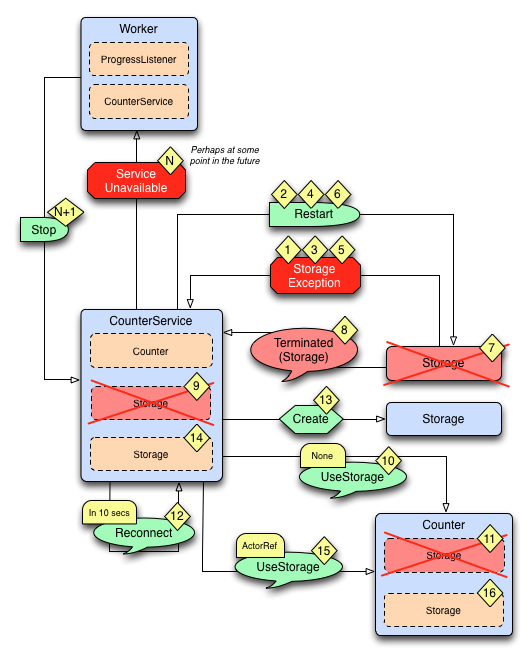
上图展示了当发生数据存储失败时的过程。
失败流程:
| 步骤 | 描述 |
|---|---|
| 1 | Storage 抛出 StorageException异常 |
| 2 | CounterService 是 Storage 的监管者, StorageException被抛出时它将 Storage 重启。 |
| 3,4,5,6 | Storage 仍旧失败,又被重启 |
| 7 | 在5秒内三次失败和重启后 Storage 被它的监管者CounterService终止。 |
| 8 | CounterService 同时观察着 Storage 并在Storage被终止时收到 Terminated消息 |
| 9,10,11 | 告诉 Counter 当前没有可用的 Storage。 |
| 12 | CounterService 计划给自己发一个Reconnect 消息 |
| 13,14 | 收到 Reconnect 消息后它创建一个新的 Storage |
| 15,16 | 通知 Counter 使用新的 Storage |
容错例子的完整源代码
import akka.actor._import akka.actor.SupervisorStrategy._import scala.concurrent.duration._import akka.util.Timeoutimport akka.event.LoggingReceiveimport akka.pattern.{ ask, pipe }import com.typesafe.config.ConfigFactory//运行这个例子object FaultHandlingDocSample extends App {import Worker._val config = ConfigFactory.parseString("""akka.loglevel = DEBUGakka.actor.debug {receive = onlifecycle = on}""")val system = ActorSystem("FaultToleranceSample", config)val worker = system.actorOf(Props[Worker], name = "worker")val listener = system.actorOf(Props[Listener], name = "listener")// 开始工作并监听进展// 注意监听者被用作tell的sender,// i.e. 它会接收从worker发来的应答worker.tell(Start, sender = listener)}//监听worker的进展,当完成到足够的程度时关闭整个系统class Listener extends Actor with ActorLogging {import Worker._// 如果15秒没有任何进展说明服务不可用context.setReceiveTimeout(15 seconds)def receive = {case Progress(percent) =>log.info("Current progress: {} %", percent)if (percent >= 100.0) {log.info("That's all, shutting down")context.system.shutdown()}case ReceiveTimeout =>// 15秒没有进展,服务不可用log.error("Shutting down due to unavailable service")context.system.shutdown()}}object Worker {case object Startcase object Docase class Progress(percent: Double)}// Worker接收到 `Start` 消息时开始处理工作.// 它持续地将当前``进展``通知 `Start` 消息的发送方// `Worker` 监管 `CounterService`.class Worker extends Actor with ActorLogging {import Worker._import CounterService._implicit val askTimeout = Timeout(5 seconds)// 如果 CounterService 子actor抛出 ServiceUnavailable异常则终止它override val supervisorStrategy = OneForOneStrategy() {case _: CounterService.ServiceUnavailable =>Stop}// 最初 Start 消息的发送方将持续地收到进展通知var progressListener: Option[ActorRef] = Noneval counterService = context.actorOf(Props[CounterService], name = "counter")val totalCount = 51def receive = LoggingReceive {case Start if progressListener.isEmpty =>progressListener = Some(sender)context.system.scheduler.schedule(Duration.Zero, 1 second, self, Do)case Do =>counterService ! Increment(1)counterService ! Increment(1)counterService ! Increment(1)// 将当前进展发送给最初的发送方counterService ? GetCurrentCount map {case CurrentCount(_, count) =>Progress(100.0 * count / totalCount)} pipeTo progressListener.get}}object CounterService {case class Increment(n: Int)case object GetCurrentCountcase class CurrentCount(key: String, count: Long)class ServiceUnavailable(msg: String) extends RuntimeException(msg)private case object Reconnect}// 将从 `Increment` 消息中获取的值加到持久的计数器上。// 在被请求 `CurrentCount` 时将 `CurrentCount` 作为应答。// `CounterService` 监管 `Storage` 和 `Counter`。class CounterService extends Actor {import CounterService._import Counter._import Storage._// 在抛出 StorageException 时重启 Storage 子actor.// 如果5秒内有3次重启,它将被终止.override val supervisorStrategy = OneForOneStrategy(maxNrOfRetries = 3, withinTimeRange = 5 seconds) {case _: Storage.StorageException => Restart}val key = self.path.namevar storage: Option[ActorRef] = Nonevar counter: Option[ActorRef] = Nonevar backlog = IndexedSeq.empty[(ActorRef, Any)]val MaxBacklog = 10000override def preStart() {initStorage()}//storage 子actor在失败时将被重启,但是3次重启后如果仍失败,它将被终止。//这样比一直不断的失败要好//它被终止后我们将在一段延时后安排重新连接.//监视子actor,这样在它终止后我们能收到`Terminated` 消息.def initStorage() {storage = Some(context.watch(context.actorOf(Props[Storage], name = "storage")))// 告诉计数器(如果有的话),使用新的storagecounter foreach { _ ! UseStorage(storage) }// 我们需要初始值来开始操作storage.get ! Get(key)}def receive = LoggingReceive {case Entry(k, v) if k == key && counter == None =>// 从Storage应答得到初始值, 现在我们可以创建计数器了val c = context.actorOf(Props(new Counter(key, v)))counter = Some(c)// 告诉计数器使用当前 storagec ! UseStorage(storage)// 并将缓存的积压消息发给计数器for ((replyTo, msg) <- backlog) c.tell(msg, sender = replyTo)backlog = IndexedSeq.emptycase msg @ Increment(n) => forwardOrPlaceInBacklog(msg)case msg @ GetCurrentCount => forwardOrPlaceInBacklog(msg)case Terminated(actorRef) if Some(actorRef) == storage =>// 3次重启后 storage 子actor被终止了.// 我们收到 Terminated 是因为我们监视了这个子actor.storage = None// 告诉计数器现在没有 storage 可用了counter foreach { _ ! UseStorage(None) }// 过一会尝试重新建立 storagecontext.system.scheduler.scheduleOnce(10 seconds, self, Reconnect)case Reconnect =>// 在计划的延时后重新创建 storageinitStorage()}def forwardOrPlaceInBacklog(msg: Any) {// 在开始委托给计数器之前我们需要从storage中获取初始值 .// 在那之前我们将消息放入积压缓存中,在计数器初始化完成后将这些消息发给它。counter match {case Some(c) => c forward msgcase None =>if (backlog.size >= MaxBacklog)throw new ServiceUnavailable("CounterService not available, lack of initial value")backlog = backlog :+ (sender, msg)}}}object Counter {case class UseStorage(storage: Option[ActorRef])}//如果当前有可用的 storage的话, 计数器变量将当前的值发送给`Storage`class Counter(key: String, initialValue: Long) extends Actor {import Counter._import CounterService._import Storage._var count = initialValuevar storage: Option[ActorRef] = Nonedef receive = LoggingReceive {case UseStorage(s) =>storage = sstoreCount()case Increment(n) =>count += nstoreCount()case GetCurrentCount =>sender() ! CurrentCount(key, count)}def storeCount() {// 委托危险的工作,来保护我们宝贵的状态.// 没有 storage 我们也能继续工作.storage foreach { _ ! Store(Entry(key, count)) }}}object Storage {case class Store(entry: Entry)case class Get(key: String)case class Entry(key: String, value: Long)class StorageException(msg: String) extends RuntimeException(msg)}// 收到 `Store` 消息时将键/值对保存到持久storage中.// 收到 `Get` 消息时以当前值作为应答 .// 如果背后的数据存储出问题了,会抛出 StorageException.class Storage extends Actor {import Storage._val db = DummyDBdef receive = LoggingReceive {case Store(Entry(key, count)) => db.save(key, count)case Get(key) => sender() ! Entry(key, db.load(key).getOrElse(0L))} }object DummyDB {import Storage.StorageExceptionprivate var db = Map[String, Long]()@throws(classOf[StorageException])def save(key: String, value: Long): Unit = synchronized {if (11 <= value && value <= 14)throw new StorageException("Simulated store failure " + value)db += (key -> value)}@throws(classOf[StorageException])def load(key: String): Option[Long] = synchronized {db.get(key)}}
2 创建一个监管策略
以下更加深入地讲解错误处理的机制和可选的方法。
为了演示我们假设有这样的策略:
import akka.actor.OneForOneStrategyimport akka.actor.SupervisorStrategy._import scala.concurrent.duration._override val supervisorStrategy =OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {case _: ArithmeticException => Resumecase _: NullPointerException => Restartcase _: IllegalArgumentException => Stopcase _: Exception => Escalate}
我选择了一种非常著名的异常类型来演示监管和监控 中描述的错误处理方式的使用. 首先,它是一个一对一的策略,意思是每一个子actor会被单独处理(多对一的策略与之相似,唯一的差别在于任何决策都应用于监管者的所有子actor,而不仅仅是出错的那一个)。 这里我们对重启的频率作了限制,最多每分钟能进行 10 次重启; 所有这样的设置都可以被忽略,也就是说,相应的限制并不被采用, 使设置重启频率的绝对上限值或让重启无限进行成为可能。
构成主体的 match 语句的类型是Decider, 它是一个PartialFunction[Throwable, Directive]。这一部分将子actor的失败类型映射到相应的指令上。
注意:如果策略定义在监控actor的内部(相反的是在一个组合对象的内部),它的
Decider可以线程安全的访问actor的所有内部状态,包括获取当前失败子actor的一个引用
缺省的监管机制
如果定义的监管机制没有覆盖抛出的异常,将使用上溯(Escalate)机制。
如果某个actor没有定义监管机制,下列异常将被缺省地处理:
ActorInitializationException将终止出错的子actorActorKilledException将终止出错的子 actorException将重启出错的子 actor- 其它的
Throwable将被上溯传给父actor
如果异常一直被上溯到根监管者,在那儿也会用上述缺省方式进行处理。
你可以合并你自己的策略到默认策略中去。
import akka.actor.OneForOneStrategyimport akka.actor.SupervisorStrategy._import scala.concurrent.duration._override val supervisorStrategy =OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {case _: ArithmeticException => Resumecase t =>super.supervisorStrategy.decider.applyOrElse(t, (_: Any) => Escalate)}
3 测试应用程序
以下部分展示了实际中不同的指令的效果,为此我们需要创建一个测试环境。首先我们需要一个合适的监管者:
import akka.actor.Actorclass Supervisor extends Actor {import akka.actor.OneForOneStrategyimport akka.actor.SupervisorStrategy._import scala.concurrent.duration._override val supervisorStrategy =OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {case _: ArithmeticException => Resumecase _: NullPointerException => Restartcase _: IllegalArgumentException => Stopcase _: Exception => Escalate}def receive = {case p: Props => sender() ! context.actorOf(p)} }
该监管者将用来创建一个我们用来做试验的子actor:
import akka.actor.Actorclass Child extends Actor {var state = 0def receive = {case ex: Exception => throw excase x: Int => state = xcase "get" => sender() ! state}}
这个测试可以用测试Actor系统中的工具来进行简化, 比如AkkaSpec是TestKit with WordSpec with MustMatchers的混合。
import akka.testkit.{ AkkaSpec, ImplicitSender, EventFilter }import akka.actor.{ ActorRef, Props, Terminated }class FaultHandlingDocSpec extends AkkaSpec with ImplicitSender {"A supervisor" must {"apply the chosen strategy for its child" in {// code here} }}
现在我们来创建 actor:
val supervisor = system.actorOf(Props[Supervisor], "supervisor")supervisor ! Props[Child]val child = expectMsgType[ActorRef] // retrieve answer from TestKit’s testActor
第一个测试是为了演示 Resume 指令, 我们试着将actor设为非初始状态然后让它出错:
child ! 42 // set state to 42child ! "get"expectMsg(42)child ! new ArithmeticException // crash itchild ! "get"expectMsg(42)
可以看到错误处理指令完后仍能得到42的值. 现在如果我们将错误换成更严重的 NullPointerException, 情况就不同了:
child ! new NullPointerException // crash it harderchild ! "gexpectMsg(0)
而最后当致命的 IllegalArgumentException 发生时子actor将被其监管者终止:
watch(child) // have testActor watch “child”child ! new IllegalArgumentException // break itexpectMsgPF() { case Terminated(‘child‘) => () }
到目前为止监管者完全没有被子actor的错误所影响, 因为指令集确实处理了这些错误。而对于 Exception, 就不是这么回事了, 监管者会将失败上溯传递。
supervisor ! Props[Child] // create new childval child2 = expectMsgType[ActorRef]watch(child2)child2 ! "get" // verify it is aliveexpectMsg(0)child2 ! new Exception("CRASH") // escalate failureexpectMsgPF() {case t @ Terminated(‘child2‘) if t.existenceConfirmed => ()}
监管者自己是被ActorSystem的顶级actor所监管的。顶级actor的缺省策略是对所有的Exception情况 (注意ActorInitializationException和 ActorKilledException是例外)进行重启. 由于缺省的重启指令会杀死所有的子actor,我们知道我们可怜的子actor最终无法从这个失败中幸免。
如果这不是我们希望的行为 (这取决于实际用例), 我们需要使用一个不同的监管者来覆盖这个行为。
class Supervisor2 extends Actor {import akka.actor.OneForOneStrategyimport akka.actor.SupervisorStrategy._import scala.concurrent.duration._override val supervisorStrategy =OneForOneStrategy(maxNrOfRetries = 10, withinTimeRange = 1 minute) {case _: ArithmeticException => Resumecase _: NullPointerException => Restartcase _: IllegalArgumentException => Stopcase _: Exception => Escalate}def receive = {case p: Props => sender() ! context.actorOf(p)}// override default to kill all children during restartoverride def preRestart(cause: Throwable, msg: Option[Any]) {}}
在这个父actor之下,子actor在上溯的重启中得以幸免,如以下最后的测试:
val supervisor2 = system.actorOf(Props[Supervisor2], "supervisor2")supervisor2 ! Props[Child]val child3 = expectMsgType[ActorRef]child3 ! 23child3 ! "get"expectMsg(23)child3 ! new Exception("CRASH")child3 ! "get"expectMsg(0)

若有收获,就点个赞吧
0 人点赞
