第二十五章 设计模式
概念
最初,你可以将模式视为解决特定类问题的一种特别巧妙且有深刻见解的方法。这就像前辈已经从所有角度去解决问题,并提出了最通用,最灵活的解决方案。问题可能是你之前看到并解决过的问题,但你的解决方案可能没有你在模式中体现的那种完整性。
虽然它们被称为“设计模式”,但它们实际上并不与设计领域相关联。模式似乎与传统的分析、设计和实现的思维方式不同。相反,模式在程序中体现了一个完整的思想,因此它有时会出现在分析阶段或高级设计阶段。因为模式在代码中有一个直接的实现,所以你可能不会期望模式在低级设计或实现之前出现(而且通常在到达这些阶段之前,你不会意识到需要一个特定的模式)。
模式的基本概念也可以看作是程序设计的基本概念:添加抽象层。当你抽象一些东西的时候,就像在剥离特定的细节,而这背后最重要的动机之一是:
将易变的事物与不变的事物分开
另一种方法是,一旦你发现程序的某些部分可能因某种原因而发生变化,你要保持这些变化不会引起整个代码中其他变化。 如果代码更容易理解,那么维护起来会更容易。
通常,开发一个优雅且易维护设计中最困难的部分是发现我称之为变化的载体(也就是最易改变的地方)。这意味着找到系统中最重要的变化,换而言之,找到变化会导致最严重后果的地方。一旦发现变化载体,就可以围绕构建设计的焦点。
因此,设计模式的目标是隔离代码中的更改。 如果以这种方式去看,你已经在本书中看到了设计模式。 例如,继承可以被认为是一种设计模式(虽然是由编译器实现的)。它允许你表达所有具有相同接口的对象(即保持相同的行为)中的行为差异(这就是变化的部分)。组合也可以被视为一种模式,因为它允许你动态或静态地更改实现类的对象,从而改变类的工作方式。
你还看到了设计模式中出现的另一种模式:迭代器(Java 1.0和1.1随意地将其称为枚举; Java 2 集合才使用Iterator)。当你逐个选择元素时并逐步处理,这会隐藏集合的特定实现。迭代器允许你编写通用代码,该代码对序列中的所有元素执行操作,而不考虑序列的构建方式。因此,你的通用代码可以与任何可以生成迭代器的集合一起使用。
即使模式是非常有用的,但有些人断言:
设计模式代表语言的失败。
这是一个非常重要的见解,因为一个模式在 C++ 有意义,可能在JAVA或者其他语言中就没有意义。出于这个原因,所以一个模式可能出现在设计模式书上,不意味着应用于你的编程语言是有用的。
我认为“语言失败”这个观点是有道理的,但是我也认为这个观点过于简单化。如果你试图解决一个特定的问题,而你使用的语言没有直接提供支持你使用的技巧,你可以说这个是语言的失败。但是,你使用特定的技巧的频率的是多少呢?也许平衡是对的:当你使用特定的技巧的时候,你必须付出更多的努力,但是你又没有足够的理由去使得语言支持这个技术。另一方面,没有语言的支持,使用这种技术常常会很混乱,但是在语言支持下,你可能会改变编程方式(例如,Java 8流实现此目的)。
单例模式
也许单例模式是最简单的设计模式,它是一种提供一个且只有一个对象实例的方法。这在java库中使用,但是这有个更直接的示例:
// patterns/SingletonPattern.javainterface Resource {int getValue();void setValue(int x);}/** 由于这不是从Cloneable基类继承而且没有添加可克隆性,* 因此将其设置为final可防止通过继承添加可克隆性。* 这也实现了线程安全的延迟初始化:*/final class Singleton {private static final class ResourceImpl implements Resource {private int i;private ResourceImpl(int i) {this.i = i;}public synchronized int getValue() {return i;}public synchronized void setValue(int x) {i = x;}}private static class ResourceHolder {private static Resource resource = new ResourceImpl(47);}public static Resource getResource() {return ResourceHolder.resource;}}public class SingletonPattern {public static void main(String[] args) {Resource r = Singleton.getResource();System.out.println(r.getValue());Resource s2 = Singleton.getResource();s2.setValue(9);System.out.println(r.getValue());try {// 不能这么做,会发生:compile-time error(编译时错误).// Singleton s3 = (Singleton)s2.clone();} catch(Exception e) {throw new RuntimeException(e);}}} /* Output: 47 9 */
创建单例的关键是防止客户端程序员直接创建对象。 在这里,这是通过在Singleton类中将Resource的实现作为私有类来实现的。
此时,你将决定如何创建对象。在这里,它是按需创建的,在第一次访问的时候创建。 该对象是私有的,只能通过public getResource()方法访问。
懒惰地创建对象的原因是它嵌套的私有类resourceHolder在首次引用之前不会加载(在getResource()中)。当Resource对象加载的时候,静态初始化块将被调用。由于JVM的工作方式,这种静态初始化是线程安全的。为保证线程安全,Resource中的getter和setter是同步的。
模式分类
“设计模式”一书讨论了23种不同的模式,分为以下三种类别(所有这些模式都围绕着可能变化的特定方面)。
创建型:如何创建对象。 这通常涉及隔离对象创建的细节,这样你的代码就不依赖于具体的对象的类型,因此在添加新类型的对象时不会更改。单例模式(Singleton)被归类为创作模式,本章稍后你将看到Factory Method的示例。
构造型:设计对象以满足特定的项目约束。它们处理对象与其他对象连接的方式,以确保系统中的更改不需要更改这些连接。
行为型:处理程序中特定类型的操作的对象。这些封装要执行的过程,例如解释语言、实现请求、遍历序列(如在迭代器中)或实现算法。本章包含观察者和访问者模式的例子。
《设计模式》一书中每个设计模式都有单独的一个章节,每个章节都有一个或者多个例子,通常使用C++,但有时也使用SmallTalk。 本章不重复设计模式中显示的所有模式,因为该书独立存在,应单独研究。 相反,你会看到一些示例,可以为你提供关于模式的理解以及它们如此重要的原因。
构建应用程序框架
应用程序框架允许您从一个类或一组类开始,创建一个新的应用程序,重用现有类中的大部分代码,并根据需要覆盖一个或多个方法来定制应用程序。
模板方法模式
应用程序框架中的一个基本概念是模板方法模式,它通常隐藏在底层,通过调用基类中的各种方法来驱动应用程序(为了创建应用程序,您已经覆盖了其中的一些方法)。
模板方法模式的一个重要特性是它是在基类中定义的,并且不能更改。它有时是一个 private 方法,但实际上总是 final。它调用其他基类方法(您覆盖的那些)来完成它的工作,但是它通常只作为初始化过程的一部分被调用(因此框架使用者不一定能够直接调用它)。
// patterns/TemplateMethod.java// Simple demonstration of Template Methodabstract class ApplicationFramework {ApplicationFramework() {templateMethod();}abstract void customize1();abstract void customize2();// "private" means automatically "final":private void templateMethod() {IntStream.range(0, 5).forEach(n -> {customize1();customize2();});}}// Create a new "application":class MyApp extends ApplicationFramework {@Overridevoid customize1() {System.out.print("Hello ");}@Overridevoid customize2() {System.out.println("World!");}}public class TemplateMethod {public static void main(String[] args) {new MyApp();}}/* Output:Hello World!Hello World!Hello World!Hello World!Hello World!*/
基类构造函数负责执行必要的初始化,然后启动运行应用程序的“engine”(模板方法模式)(在GUI应用程序中,这个“engine”是主事件循环)。框架使用者只提供 customize1() 和 customize2() 的定义,然后“应用程序”已经就绪运行。
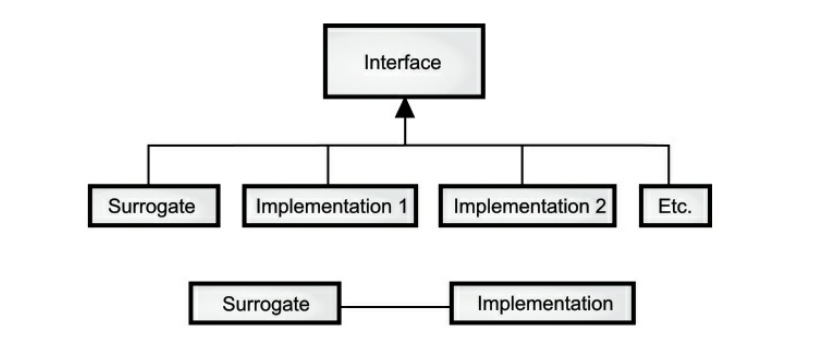
面向实现
代理模式和桥接模式都提供了在代码中使用的代理类;完成工作的真正类隐藏在这个代理类的后面。当您在代理中调用一个方法时,它只是反过来调用实现类中的方法。这两种模式非常相似,所以代理模式只是桥接模式的一种特殊情况。人们倾向于将两者合并,称为代理模式,但是术语“代理”有一个长期的和专门的含义,这可能解释了这两种模式不同的原因。基本思想很简单:从基类派生代理,同时派生一个或多个提供实现的类:创建代理对象时,给它一个可以调用实际工作类的方法的实现。
在结构上,代理模式和桥接模式的区别很简单:代理模式只有一个实现,而桥接模式有多个实现。在设计模式中被认为是不同的:代理模式用于控制对其实现的访问,而桥接模式允许您动态更改实现。但是,如果您扩展了“控制对实现的访问”的概念,那么这两者就可以完美地结合在一起
代理模式
如果我们按照上面的关系图实现,它看起来是这样的:
// patterns/ProxyDemo.java// Simple demonstration of the Proxy patterninterface ProxyBase {void f();void g();void h();}class Proxy implements ProxyBase {private ProxyBase implementation;Proxy() {implementation = new Implementation();}// Pass method calls to the implementation:@Overridepublic void f() { implementation.f(); }@Overridepublic void g() { implementation.g(); }@Overridepublic void h() { implementation.h(); }}class Implementation implements ProxyBase {public void f() {System.out.println("Implementation.f()");}public void g() {System.out.println("Implementation.g()");}public void h() {System.out.println("Implementation.h()");}}public class ProxyDemo {public static void main(String[] args) {Proxy p = new Proxy();p.f();p.g();p.h();}}/*Output:Implementation.f()Implementation.g()Implementation.h()*/
具体实现不需要与代理对象具有相同的接口;只要代理对象以某种方式“代表具体实现的方法调用,那么基本思想就算实现了。然而,拥有一个公共接口是很方便的,因此具体实现必须实现代理对象调用的所有方法。
状态模式
状态模式向代理对象添加了更多的实现,以及在代理对象的生命周期内从一个实现切换到另一种实现的方法:
// patterns/StateDemo.java // Simple demonstration of the State patterninterface StateBase {void f();void g();void h();void changeImp(StateBase newImp);}class State implements StateBase {private StateBase implementation;State(StateBase imp) {implementation = imp;}@Overridepublic void changeImp(StateBase newImp) {implementation = newImp;}// Pass method calls to the implementation:@Overridepublic void f() {implementation.f();}@Overridepublic void g() {implementation.g();}@Overridepublic void h() {implementation.h();}}class Implementation1 implements StateBase {@Overridepublic void f() {System.out.println("Implementation1.f()");}@Overridepublic void g() {System.out.println("Implementation1.g()");}@Overridepublic void h() {System.out.println("Implementation1.h()");}@Overridepublic void changeImp(StateBase newImp) {}}class Implementation2 implements StateBase {@Overridepublic void f() {System.out.println("Implementation2.f()");}@Overridepublic void g() {System.out.println("Implementation2.g()");}@Overridepublic void h() {System.out.println("Implementation2.h()");}@Overridepublic void changeImp(StateBase newImp) {}}public class StateDemo {static void test(StateBase b) {b.f();b.g();b.h();}public static void main(String[] args) {StateBase b =new State(new Implementation1());test(b);b.changeImp(new Implementation2());test(b);}}/* Output:Implementation1.f()Implementation1.g()Implementation1.h()Implementation2.f()Implementation2.g()Implementation2.h()*/
在main()中,首先使用第一个实现,然后改变成第二个实现。代理模式和状态模式的区别在于它们解决的问题。设计模式中描述的代理模式的常见用途如下:
远程代理。它在不同的地址空间中代理对象。远程方法调用(RMI)编译器rmic会自动为您创建一个远程代理。
虚拟代理。这提供了“懒加载”来根据需要创建“昂贵”的对象。
保护代理。当您希望对代理对象有权限访问控制时使用。
智能引用。要在被代理的对象被访问时添加其他操作。例如,跟踪特定对象的引用数量,来实现写时复制用法,和防止对象别名。一个更简单的例子是跟踪特定方法的调用数量。您可以将Java引用视为一种保护代理,因为它控制在堆上实例对象的访问(例如,确保不使用空引用)。
在设计模式中,代理模式和桥接模式并不是相互关联的,因为它们被赋予(我认为是任意的)不同的结构。桥接模式,特别是使用一个单独的实现,但这似乎对我来说是不必要的,除非你确定该实现是你无法控制的(当然有可能,但是如果您编写所有代码,那么没有理由不从单基类的优雅中受益)。此外,只要代理对象控制对其“前置”对象的访问,代模式理就不需要为其实现使用相同的基类。不管具体情况如何,在代理模式和桥接模式中,代理对象都将方法调用传递给具体实现对象。
状态机
桥接模式允许程序员更改实现,状态机利用一个结构来自动地将实现更改到下一个。当前实现表示系统所处的状态,系统在不同状态下的行为不同(因为它使用桥接模式)。基本上,这是一个利用对象的“状态机”。将系统从一种状态移动到另一种状态的代码通常是模板方法模式,如下例所示:
// patterns/state/StateMachineDemo.java// The StateMachine pattern and Template method// {java patterns.state.StateMachineDemo}package patterns.state;import onjava.Nap;interface State {void run();}abstract class StateMachine {protected State currentState;protected abstract boolean changeState();// Template method:protected final void runAll() {while (changeState()) // CustomizablecurrentState.run();}}// A different subclass for each state:class Wash implements State {@Overridepublic void run() {System.out.println("Washing");new Nap(0.5);}}class Spin implements State {@Overridepublic void run() {System.out.println("Spinning");new Nap(0.5);}}class Rinse implements State {@Overridepublic void run() {System.out.println("Rinsing");new Nap(0.5);}}class Washer extends StateMachine {private int i = 0;// The state table:private State[] states = {new Wash(), new Spin(),new Rinse(), new Spin(),};Washer() {runAll();}@Overridepublic boolean changeState() {if (i < states.length) {// Change the state by setting the// surrogate reference to a new object:currentState = states[i++];return true;} elsereturn false;}}public class StateMachineDemo {public static void main(String[] args) {new Washer();}}/* Output:WashingSpinningRinsingSpinning*/
在这里,控制状态的类(本例中是状态机)负责决定下一个状态。然而,状态对象本身也可以决定下一步移动到什么状态,通常基于系统的某种输入。这是更灵活的解决方案。
工厂模式
当你发现必须将新类型添加到系统中时,合理的第一步是使用多态性为这些新类型创建一个通用接口。这会将你系统中的其余代码与要添加的特定类型的信息分开,使得可以在不改变现有代码的情况下添加新类型……或者看起来如此。起初,在这种设计中,似乎你必须更改代码的唯一地方就是你继承新类型的地方,但这并不是完全正确的。 你仍然必须创建新类型的对象,并且在创建时必须指定要使用的确切构造器。因此,如果创建对象的代码分布在整个应用程序中,那么在添加新类型时,你将遇到相同的问题——你仍然必须追查你代码中新类型碍事的所有地方。恰好是类型的创建碍事,而不是类型的使用(通过多态处理),但是效果是一样的:添加新类型可能会引起问题。
解决方案是强制对象的创建都通过通用工厂进行,而不是允许创建代码在整个系统中传播。 如果你程序中的所有代码都必须执行通过该工厂创建你的一个对象,那么在添加新类时只需要修改工厂即可。
由于每个面向对象的程序都会创建对象,并且很可能会通过添加新类型来扩展程序,因此工厂是最通用的设计模式之一。
举例来说,让我们重新看一下Shape系统。 首先,我们需要一个用于所有示例的基本框架。 如果无法创建Shape对象,则需要抛出一个合适的异常:
// patterns/shapes/BadShapeCreation.java package patterns.shapes;public class BadShapeCreation extends RuntimeException {public BadShapeCreation(String msg) {super(msg);}}
接下来,是一个Shape基类:
// patterns/shapes/Shape.javapackage patterns.shapes;public class Shape {private static int counter = 0;private int id = counter++;@Overridepublic String toString(){return getClass().getSimpleName() + "[" + id + "]";}public void draw() {System.out.println(this + " draw");}public void erase() {System.out.println(this + " erase");}}
该类自动为每一个Shape对象创建一个唯一的id。
toString()使用运行期信息来发现特定的Shape子类的名字。
现在我们能很快创建一些Shape子类了:
// patterns/shapes/Circle.javapackage patterns.shapes;public class Circle extends Shape {}
// patterns/shapes/Square.javapackage patterns.shapes;public class Square extends Shape {}
// patterns/shapes/Triangle.javapackage patterns.shapes;public class Triangle extends Shape {}
工厂是具有能够创建对象的方法的类。 我们有几个示例版本,因此我们将定义一个接口:
// patterns/shapes/FactoryMethod.javapackage patterns.shapes;public interface FactoryMethod {Shape create(String type);}
create()接收一个参数,这个参数使其决定要创建哪一种Shape对象,这里是String,但是它其实可以是任何数据集合。对象的初始化数据(这里是字符串)可能来自系统外部。 这个例子将测试工厂:
// patterns/shapes/FactoryTest.javapackage patterns.shapes;import java.util.stream.*;public class FactoryTest {public static void test(FactoryMethod factory) {Stream.of("Circle", "Square", "Triangle","Square", "Circle", "Circle", "Triangle").map(factory::create).peek(Shape::draw).peek(Shape::erase).count(); // Terminal operation}}
在主函数main()里,要记住除非你在最后使用了一个终结操作,否则Stream不会做任何事情。在这里,count()的值被丢弃了。
创建工厂的一种方法是显式创建每种类型:
// patterns/ShapeFactory1.java// A simple static factory methodimport java.util.*;import java.util.stream.*;import patterns.shapes.*;public class ShapeFactory1 implements FactoryMethod {public Shape create(String type) {switch(type) {case "Circle": return new Circle();case "Square": return new Square();case "Triangle": return new Triangle();default: throw new BadShapeCreation(type);}}public static void main(String[] args) {FactoryTest.test(new ShapeFactory1());}}
输出结果:
Circle[0] drawCircle[0] eraseSquare[1] drawSquare[1] eraseTriangle[2] drawTriangle[2] eraseSquare[3] drawSquare[3] eraseCircle[4] drawCircle[4] eraseCircle[5] drawCircle[5] eraseTriangle[6] drawTriangle[6] erase
create()现在是添加新类型的Shape时系统中唯一需要更改的其他代码。
动态工厂
前面例子中的静态create()方法强制所有创建操作都集中在一个位置,因此这是添加新类型的Shape时唯一必须更改代码的地方。这当然是一个合理的解决方案,因为它把创建对象的过程限制在一个框内。但是,如果你在添加新类时无需修改任何内容,那就太好了。 以下版本使用反射在首次需要时将Shape的构造器动态加载到工厂列表中:
// patterns/ShapeFactory2.javaimport java.util.*;import java.lang.reflect.*;import java.util.stream.*;import patterns.shapes.*;public class ShapeFactory2 implements FactoryMethod {Map<String, Constructor> factories = new HashMap<>();static Constructor load(String id) {System.out.println("loading " + id);try {return Class.forName("patterns.shapes." + id).getConstructor();} catch(ClassNotFoundException |NoSuchMethodException e) {throw new BadShapeCreation(id);}}public Shape create(String id) {try {return (Shape)factories.computeIfAbsent(id, ShapeFactory2::load).newInstance();} catch(InstantiationException |IllegalAccessException |InvocationTargetException e) {throw new BadShapeCreation(id);}}public static void main(String[] args) {FactoryTest.test(new ShapeFactory2());}}
输出结果:
loading CircleCircle[0] drawCircle[0] eraseloading SquareSquare[1] drawSquare[1] eraseloading TriangleTriangle[2] drawTriangle[2] eraseSquare[3] drawSquare[3] eraseCircle[4] drawCircle[4] eraseCircle[5] drawCircle[5] eraseTriangle[6] drawTriangle[6] erase
和之前一样,create()方法基于你传递给它的String参数生成新的Shapes,但是在这里,它是通过在HashMap中查找作为键的String来实现的。 返回的值是一个构造器,该构造器用于通过调用newInstance()创建新的Shape对象。
然而,当你开始运行程序时,工厂的map为空。create()使用map的computeIfAbsent()方法来查找构造器(如果该构造器已存在于map中)。如果不存在则使用load()计算出该构造器,并将其插入到map中。 从输出中可以看到,每种特定类型的Shape都是在第一次请求时才加载的,然后只需要从map中检索它。
多态工厂
《设计模式》这本书强调指出,采用“工厂方法”模式的原因是可以从基本工厂中继承出不同类型的工厂。 再次修改示例,使工厂方法位于单独的类中:
// patterns/ShapeFactory3.java// Polymorphic factory methodsimport java.util.*;import java.util.function.*;import java.util.stream.*;import patterns.shapes.*;interface PolymorphicFactory {Shape create();}class RandomShapes implements Supplier<Shape> {private final PolymorphicFactory[] factories;private Random rand = new Random(42);RandomShapes(PolymorphicFactory... factories){this.factories = factories;}public Shape get() {return factories[ rand.nextInt(factories.length)].create();}}public class ShapeFactory3 {public static void main(String[] args) {RandomShapes rs = new RandomShapes(Circle::new,Square::new,Triangle::new);Stream.generate(rs).limit(6).peek(Shape::draw).peek(Shape::erase).count();}}
输出结果:
Triangle[0] drawTriangle[0] eraseCircle[1] drawCircle[1] eraseCircle[2] drawCircle[2] eraseTriangle[3] drawTriangle[3] eraseCircle[4] drawCircle[4] eraseSquare[5] drawSquare[5] erase
RandomShapes实现了Supplier \Stream.generate()创建Stream。 它的构造器采用PolymorphicFactory对象的可变参数列表。 变量参数列表以数组形式出现,因此列表是以数组形式在内部存储的。get()方法随机获取此数组中一个对象的索引,并在结果上调用create()以产生新的Shape对象。 添加新类型的Shape时,RandomShapes构造器是唯一需要更改的地方。 请注意,此构造器需要Supplier \
鉴于ShapeFactory2.java可能会抛出异常,使用此方法则没有任何异常——它在编译时完全确定。
抽象工厂
抽象工厂模式看起来像我们之前所见的工厂对象,但拥有不是一个工厂方法而是几个工厂方法, 每个工厂方法都会创建不同种类的对象。 这个想法是在创建工厂对象时,你决定如何使用该工厂创建的所有对象。 《设计模式》中提供的示例实现了跨各种图形用户界面(GUI)的可移植性:你创建一个适合你正在使用的GUI的工厂对象,然后从中请求菜单,按钮,滑块等等,它将自动为GUI创建适合该项目版本的组件。 因此,你可以将从一个GUI更改为另一个所产生的影响隔离限制在一处。 作为另一个示例,假设你正在创建一个通用游戏环境来支持不同类型的游戏。 使用抽象工厂看起来就像下文那样:
// patterns/abstractfactory/GameEnvironment.java// An example of the Abstract Factory pattern// {java patterns.abstractfactory.GameEnvironment}package patterns.abstractfactory;import java.util.function.*;interface Obstacle {void action();}interface Player {void interactWith(Obstacle o);}class Kitty implements Player {@Overridepublic void interactWith(Obstacle ob) {System.out.print("Kitty has encountered a ");ob.action();}}class KungFuGuy implements Player {@Overridepublic void interactWith(Obstacle ob) {System.out.print("KungFuGuy now battles a ");ob.action();}}class Puzzle implements Obstacle {@Overridepublic void action() {System.out.println("Puzzle");}}class NastyWeapon implements Obstacle {@Overridepublic void action() {System.out.println("NastyWeapon");}}// The Abstract Factory:class GameElementFactory {Supplier<Player> player;Supplier<Obstacle> obstacle;}// Concrete factories:class KittiesAndPuzzles extends GameElementFactory {KittiesAndPuzzles() {player = Kitty::new;obstacle = Puzzle::new;}}class KillAndDismember extends GameElementFactory {KillAndDismember() {player = KungFuGuy::new;obstacle = NastyWeapon::new;}}public class GameEnvironment {private Player p;private Obstacle ob;public GameEnvironment(GameElementFactory factory) {p = factory.player.get();ob = factory.obstacle.get();}public void play() {p.interactWith(ob);}public static void main(String[] args) {GameElementFactory kp = new KittiesAndPuzzles(), kd = new KillAndDismember();GameEnvironment g1 = new GameEnvironment(kp), g2 = new GameEnvironment(kd);g1.play();g2.play();}}
输出结果:
Kitty has encountered a PuzzleKungFuGuy now battles a NastyWeapon
在这种环境中,Player对象与Obstacle对象进行交互,但是根据你所玩游戏的类型,存在不同类型的玩家和障碍物。 你可以通过选择特定的GameElementFactory来确定游戏的类型,然后GameEnvironment控制游戏的设置和玩法。 在此示例中,设置和玩法非常简单,但是这些活动(初始条件和状态变化)可以决定游戏的大部分结果。 这里,GameEnvironment不是为继承而设计的,尽管这样做很有意义。 它还包含“双重调度”和“工厂方法”的示例,稍后将对这两个示例进行说明。
函数对象
一个 函数对象 封装了一个函数。其特点就是将被调用函数的选择与那个函数被调用的位置进行解耦。
《设计模式》 中也提到了这个术语,但是没有使用。然而,函数对象 的话题却在那本书的很多模式中被反复论及。
命令模式
从最直观的角度来看,命令模式 就是一个函数对象:一个作为对象的函数。我们可以将 函数对象 作为参数传递给其他方法或者对象,来执行特定的操作。
在Java 8之前,想要产生单个函数的效果,我们必须明确将方法包含在对象中,而这需要太多的仪式了。而利用Java 8的lambda特性, 命令模式 的实现将是微不足道的。
// patterns/CommandPattern.javaimport java.util.*;public class CommandPattern {public static void main(String[] args) {List<Runnable> macro = Arrays.asList(() -> System.out.print("Hello "),() -> System.out.print("World! "),() -> System.out.print("I'm the command pattern!"));macro.forEach(Runnable::run);}}/* Output:Hello World! I'm the command pattern!*/
命令模式 的主要特点是允许向一个方法或者对象传递一个想要的动作。在上面的例子中,这个对象就是 macro ,而 命令模式 提供了将一系列需要一起执行的动作集进行排队的方法。在这里,命令模式 允许我们动态的创建新的行为,通常情况下我们需要编写新的代码才能完成这个功能,而在上面的例子中,我们可以通过解释运行一个脚本来完成这个功能(如果需要实现的东西很复杂请参考解释器模式)。
《设计模式》 认为“命令模式是回调的面向对象的替代品”。尽管如此,我认为”back”(回来)这个词是callback(回调)这一概念的基本要素。也就是说,我认为回调(callback)实际上是返回到回调的创建者所在的位置。另一方面,对于 命令 对象,通常只需创建它并将其交给某种方法或对象,而不是自始至终以其他方式联系命令对象。不管怎样,这就是我对它的看法。在本章的后面内容中,我将会把一组设计模式放在“回调”的标题下面。
策略模式
策略模式 看起来像是从同一个基类继承而来的一系列 命令 类。但是仔细查看 命令模式,你就会发现它也具有同样的结构:一系列分层次的 函数对象。不同之处在于,这些函数对象的用法和策略模式不同。就像前面的 io/DirList.java 那个例子,使用 命令 是为了解决特定问题 — 从一个列表中选择文件。“不变的部分”是被调用的那个方法,而变化的部分被分离出来放到 函数对象 中。我认为 命令模式 在编码阶段提供了灵活性,而 策略模式 的灵活性在运行时才会体现出来。尽管如此,这种区别却是非常模糊的。
另外,策略模式 还可以添加一个“上下文(context)”,这个上下文(context)可以是一个代理类(surrogate class),用来控制对某个特定 策略 对象的选择和使用。就像 桥接模式 一样!下面我们来一探究竟:
// patterns/strategy/StrategyPattern.java// {java patterns.strategy.StrategyPattern}package patterns.strategy;import java.util.function.*;import java.util.*;// The common strategy base type:class FindMinima {Function<List<Double>, List<Double>> algorithm;}// The various strategies:class LeastSquares extends FindMinima {LeastSquares() {// Line is a sequence of points (Dummy data):algorithm = (line) -> Arrays.asList(1.1, 2.2);}}class Perturbation extends FindMinima {Perturbation() {algorithm = (line) -> Arrays.asList(3.3, 4.4);}}class Bisection extends FindMinima {Bisection() {algorithm = (line) -> Arrays.asList(5.5, 6.6);}}// The "Context" controls the strategy:class MinimaSolver {private FindMinima strategy;MinimaSolver(FindMinima strat) {strategy = strat;}List<Double> minima(List<Double> line) {return strategy.algorithm.apply(line);}void changeAlgorithm(FindMinima newAlgorithm) {strategy = newAlgorithm;}}public class StrategyPattern {public static void main(String[] args) {MinimaSolver solver =new MinimaSolver(new LeastSquares());List<Double> line = Arrays.asList(1.0, 2.0, 1.0, 2.0, -1.0,3.0, 4.0, 5.0, 4.0 );System.out.println(solver.minima(line));solver.changeAlgorithm(new Bisection());System.out.println(solver.minima(line));}}/* Output:[1.1, 2.2][5.5, 6.6]*/
MinimaSolver 中的 changeAlgorithm() 方法将一个不同的策略插入到了 私有 域 strategy 中,这使得在调用 minima() 方法时,可以使用新的策略。
我们可以通过将上下文注入到 FindMinima 中来简化我们的解决方法。
// patterns/strategy/StrategyPattern2.java // {java patterns.strategy.StrategyPattern2}package patterns.strategy;import java.util.function.*;import java.util.*;// "Context" is now incorporated:class FindMinima2 {Function<List<Double>, List<Double>> algorithm;FindMinima2() { leastSquares(); } // default// The various strategies:void leastSquares() {algorithm = (line) -> Arrays.asList(1.1, 2.2);}void perturbation() {algorithm = (line) -> Arrays.asList(3.3, 4.4);}void bisection() {algorithm = (line) -> Arrays.asList(5.5, 6.6);}List<Double> minima(List<Double> line) {return algorithm.apply(line);}}public class StrategyPattern2 {public static void main(String[] args) {FindMinima2 solver = new FindMinima2();List<Double> line = Arrays.asList(1.0, 2.0, 1.0, 2.0, -1.0,3.0, 4.0, 5.0, 4.0 );System.out.println(solver.minima(line));solver.bisection();System.out.println(solver.minima(line));}}/* Output:[1.1, 2.2][5.5, 6.6]*/
FindMinima2 封装了不同的算法,也包含了“上下文”(Context),所以它便可以在一个单独的类中控制算法的选择了。
责任链模式
责任链模式 也许可以被看作一个使用了 策略 对象的“递归的动态一般化”。此时我们进行一次调用,在一个链序列中的每个策略都试图满足这个调用。这个过程直到有一个策略成功满足该调用或者到达链序列的末尾才结束。在递归方法中,一个方法将反复调用它自身直至达到某个终止条件;使用责任链,一个方法会调用相同的基类方法(拥有不同的实现),这个基类方法将会调用基类方法的其他实现,如此反复直至达到某个终止条件。
除了调用某个方法来满足某个请求以外,链中的多个方法都有机会满足这个请求,因此它有点专家系统的意味。由于责任链实际上就是一个链表,它能够动态创建,因此它可以看作是一个更一般的动态构建的 switch 语句。
在上面的 StrategyPattern.java 例子中,我们可能想自动发现一个解决方法。而 责任链 就可以达到这个目的:
// patterns/chain/ChainOfResponsibility.java// Using the Functional interface// {java patterns.chain.ChainOfResponsibility}package patterns.chain;import java.util.*;import java.util.function.*;class Result {boolean success;List<Double> line;Result(List<Double> data) {success = true;line = data;}Result() {success = false;line = Collections.<Double>emptyList();}}class Fail extends Result {}interface Algorithm {Result algorithm(List<Double> line);}class FindMinima {public static Result leastSquares(List<Double> line) {System.out.println("LeastSquares.algorithm");boolean weSucceed = false;if(weSucceed) // Actual test/calculation herereturn new Result(Arrays.asList(1.1, 2.2));else // Try the next one in the chain:return new Fail();}public static Result perturbation(List<Double> line) {System.out.println("Perturbation.algorithm");boolean weSucceed = false;if(weSucceed) // Actual test/calculation herereturn new Result(Arrays.asList(3.3, 4.4));elsereturn new Fail();}public static Result bisection(List<Double> line) {System.out.println("Bisection.algorithm");boolean weSucceed = true;if(weSucceed) // Actual test/calculation herereturn new Result(Arrays.asList(5.5, 6.6));elsereturn new Fail();}static List<Function<List<Double>, Result>>algorithms = Arrays.asList(FindMinima::leastSquares,FindMinima::perturbation,FindMinima::bisection);public static Result minima(List<Double> line) {for(Function<List<Double>, Result> alg :algorithms) {Result result = alg.apply(line);if(result.success)return result;}return new Fail();}}public class ChainOfResponsibility {public static void main(String[] args) {FindMinima solver = new FindMinima();List<Double> line = Arrays.asList(1.0, 2.0, 1.0, 2.0, -1.0,3.0, 4.0, 5.0, 4.0);Result result = solver.minima(line);if(result.success)System.out.println(result.line);elseSystem.out.println("No algorithm found");}}/* Output:LeastSquares.algorithmPerturbation.algorithmBisection.algorithm[5.5, 6.6]*/
我们从定义一个 Result 类开始,这个类包含一个 success 标志,因此接收者就可以知道算法是否成功执行,而 line 变量保存了真实的数据。当算法执行失败时, Fail 类可以作为返回值。要注意的是,当算法执行失败时,返回一个 Result 对象要比抛出一个异常更加合适,因为我们有时可能并不打算解决这个问题,而是希望程序继续执行下去。
每一个 Algorithm 接口的实现,都实现了不同的 algorithm() 方法。在 FindMinama 中,将会创建一个算法的列表(这就是所谓的“链”),而 minima() 方法只是遍历这个列表,然后找到能够成功执行的算法而已。
改变接口
有时候我们需要解决的问题很简单,仅仅是“我没有需要的接口”而已。有两种设计模式用来解决这个问题:适配器模式 接受一种类型并且提供一个对其他类型的接口。外观模式 为一组类创建了一个接口,这样做只是为了提供一种更方便的方法来处理库或资源。
适配器模式(Adapter)
当我们手头有某个类,而我们需要的却是另外一个类,我们就可以通过 适配器模式 来解决问题。唯一需要做的就是产生出我们需要的那个类,有许多种方法可以完成这种适配。
// patterns/adapt/Adapter.java// Variations on the Adapter pattern// {java patterns.adapt.Adapter}package patterns.adapt;class WhatIHave {public void g() {}public void h() {}}interface WhatIWant {void f();}class ProxyAdapter implements WhatIWant {WhatIHave whatIHave;ProxyAdapter(WhatIHave wih) {whatIHave = wih;}@Overridepublic void f() {// Implement behavior using// methods in WhatIHave:whatIHave.g();whatIHave.h();}}class WhatIUse {public void op(WhatIWant wiw) {wiw.f();}}// Approach 2: build adapter use into op():class WhatIUse2 extends WhatIUse {public void op(WhatIHave wih) {new ProxyAdapter(wih).f();}}// Approach 3: build adapter into WhatIHave:class WhatIHave2 extends WhatIHave implements WhatIWant {@Overridepublic void f() {g();h();}}// Approach 4: use an inner class:class WhatIHave3 extends WhatIHave {private class InnerAdapter implements WhatIWant {@Overridepublic void f() {g();h();}}public WhatIWant whatIWant() {return new InnerAdapter();}}public class Adapter {public static void main(String[] args) {WhatIUse whatIUse = new WhatIUse();WhatIHave whatIHave = new WhatIHave();WhatIWant adapt= new ProxyAdapter(whatIHave);whatIUse.op(adapt);// Approach 2:WhatIUse2 whatIUse2 = new WhatIUse2();whatIUse2.op(whatIHave);// Approach 3:WhatIHave2 whatIHave2 = new WhatIHave2();whatIUse.op(whatIHave2);// Approach 4:WhatIHave3 whatIHave3 = new WhatIHave3();whatIUse.op(whatIHave3.whatIWant());}}
我想冒昧的借用一下术语“proxy”(代理),因为在 《设计模式》 里,他们坚持认为一个代理(proxy)必须拥有和它所代理的对象一模一样的接口。但是,如果把这两个词一起使用,叫做“代理适配器(proxy adapter)”,似乎更合理一些。
外观模式(Façade)
当我想方设法试图将需求初步(first-cut)转化成对象的时候,通常我使用的原则是:
“把所有丑陋的东西都隐藏到对象里去”。
基本上说,外观模式 干的就是这个事情。如果我们有一堆让人头晕的类以及交互(Interactions),而它们又不是客户端程序员必须了解的,那我们就可以为客户端程序员创建一个接口只提供那些必要的功能。
外观模式经常被实现为一个符合单例模式(Singleton)的抽象工厂(abstract factory)。当然,你可以通过创建包含 静态 工厂方法(static factory methods)的类来达到上述效果。
// patterns/Facade.javaclass A { A(int x) {} }class B { B(long x) {} }class C { C(double x) {} }// Other classes that aren't exposed by the// facade go here ...public class Facade {static A makeA(int x) { return new A(x); }static B makeB(long x) { return new B(x); }static C makeC(double x) { return new C(x); }public static void main(String[] args) {// The client programmer gets the objects// by calling the static methods:A a = Facade.makeA(1);B b = Facade.makeB(1);C c = Facade.makeC(1.0);}}
《设计模式》给出的例子并不是真正的 外观模式 ,而仅仅是一个类使用了其他的类而已。
包(Package)作为外观模式的变体
我感觉,外观模式 更倾向于“过程式的(procedural)”,也就是非面向对象的(non-object-oriented):我们是通过调用某些函数才得到对象。它和抽象工厂(Abstract factory)到底有多大差别呢?外观模式 关键的一点是隐藏某个库的一部分类(以及它们的交互),使它们对于客户端程序员不可见,这样那些类的接口就更加简练和易于理解了。
其实,这也正是 Java 的 packaging(包)的功能所完成的事情:在库以外,我们只能创建和使用被声明为公共(public)的那些类;所有非公共(non-public)的类只能被同一 package 的类使用。看起来,外观模式 似乎是 Java 内嵌的一个功能。
公平起见,《设计模式》 主要是写给 C++ 读者的。尽管 C++ 有命名空间(namespaces)机制来防止全局变量和类名称之间的冲突,但它并没有提供类隐藏的机制,而在 Java 里我们可以通过声明 non-public 类来实现这一点。我认为,大多数情况下 Java 的 package 功能就足以解决针对 外观模式 的问题了。
解释器:运行时的弹性
如果程序的用户需要更好的运行时弹性,例如创建脚本来增加需要的系统功能,你就能使用解释器设计模式。这个模式下,你可以创建一个语言解释器并将它嵌入你的程序内。
在开发程序的过程中,设计自己的语言并为它构建一个解释器是一件让人分心且耗时的事。最好的解决方案就是复用代码:使用一个已经构建好并被调试过的解释器。Python 语言可以免费地嵌入营利性的应用中而不需要任何的协议许可、授权费或者是任何的声明。此外,有一个完全使用 Java 字节码实现的 Python 版本(叫做 Jython), 能够轻易地合并到 Java 程序中。Python 是一门非常易学习的脚本语言,代码的读写很有逻辑性。它支持函数与对象,有大量的可用库,并且可运行在所有的平台上。你可以在 www.Python.org 上下载 Python 并了解更多信息。
回调
多次调度
模式重构
抽象用法
多次派遣
访问者模式
RTTI的优劣
本章小结

若有收获,就点个赞吧
0 人点赞
