简介
JavaScript 被称为“web 的汇编语言”。类比(它不是完美的,还还有更完美的么?),从 JavaScipt 通常被编译的目标(即 Clojure 和 CoffeeScript)这一事实出发,还从许多其他来源(如 pyjamas(python to JS)和 Google Web Kit(Java 到 JS))中得出结论。
引用了一个更愚蠢的想法,JavaScript 和 x86 程序集一样具有表现力和低级。也许这个概念源于这样一个事实:自从 JavaScript 在 1995 年首次随 Netscape 一起发布以来,它就一直因其设计缺陷和疏忽而受到抨击。它是在匆忙中开发和发布的,正因为如此,一些有问题的设计模式进入了 JavaScript,这种语言很快成为了事实上的 web 脚本语言。“;”是个大错误。定义函数的方法也不明确。是 var foo = function();还是 function foo();
函数式编程是处理这些错误的一个很好的方法。 通过关注 JavaScript 确实是一种函数式语言这一事实,在前面关于声明函数的不同方法的示例中,最好将函数声明为变量。分号主要是为了让 JavaScript 看起来更像 C 语言。
但是请始终记住您使用的语言。 与其他任何语言一样,JavaScript 也有其缺陷。 而且,当以一种经常避开可能的前沿优势的风格进行编程时,这些小问题可能会变成不可恢复的问题陷阱。 其中一些陷阱包括:
- 递归
- 可变范围和闭包
- 函数声明与函数表达式
不过,这些问题只要稍加注意就可以解决。
递归
递归对于任何语言的函数式编程都非常重要。许多函数式语言甚至不提供 for 和 while 循环语句,从而要求迭代递归;只有当语言保证消除尾部调用时,这才是可能的,而 JavaScript 则不是这样。在第 2 章“函数式编程基础”中快速介绍了递归。但在本节中,我们将深入研究递归在 JavaScript 中的工作原理。
尾递归
JavaScript 处理递归的例程称为 tail 递归,这是基于堆栈的递归实现。 这意味着,对于每个递归调用,堆栈中都会有一个新帧。
为了说明这个方法可能产生的问题,让我们使用经典的阶乘递归算法。
var factorial = function(n) {if (n == 0) {// base casereturn 1;} else {// recursive casereturn n * factorial(n - 1);}};
该算法将调用 n 次以获取答案。 它实际上是在计算(1 x 1 x 2 x 3 x…x N)。 这意味着时间复杂度为 O(n)。
::: tip
O(n),发音为“big oh to the n,””,意味着随着输入大小的增长,算法将以 n 的速率增长,即较窄的增长。 O(n2)是指数增长,O(log(n))是对数 增长等等。 此符号可用于时间复杂度和空间复杂度。 :::
但是,因为在每个迭代中分配了存储器堆栈中的新帧,所以空间复杂度也是 O(n)。这是个问题。这意味着内存的消耗速度将很容易超过内存限制。在我的笔记本电脑上,阶乘 factorial(23456)返回Uncaught Error:RangeError: Maximum call stack size exceeded超出最大调用堆栈大小。
尽管计算 23,456 的阶乘是一件轻而易举的事,但是可以放心,用递归解决的许多问题将增长到该大小而不会带来太多麻烦。 考虑数据树的情况。 树可以是任何东西:搜索应用程序,文件系统,路由表等等。 下面是树遍历功能的一个非常简单的实现:
var traverse = function(node) {node.doSomething(); // whatever work needs to be donenode.childern.forEach(traverse); // many recursive calls};
每个节点只有两个子节点,时间复杂度和空间复杂度(在最坏的情况下,必须遍历整棵树才能找到答案)都将是 O(n2),因为每个将有两个递归调用。 每个节点有许多子代,复杂度将为 O(nm),其中 m 是子代数。 递归是树遍历的首选算法; while 循环会复杂得多,并且需要维护堆栈。
这样的指数增长意味着不需要很大的 tree 就可以抛出 RangeError 异常。肯定有更好的办法。
尾部调用消除
我们需要一种方法来消除每个递归调用的新堆栈帧的分配。 这被称为尾部调用消除。
使用尾部调用消除,当函数返回调用自身的结果时,语言实际上不会执行另一个函数调用。它把整件事都变成了一个循环。
好,那我们该怎么做呢? 有了惰性求值。 如果我们可以重写它来折叠一个延迟序列,这样函数返回一个值,或者它返回调用另一个函数的结果而不对该结果做任何处理,那么就不需要分配新的堆栈帧。
要将其放入“尾递归形式”,必须重写阶乘函数,以使内部过程事实在控制流中最后调用自身,如以下代码片段所示:
var factorial = function(n) {var _fact = function(x, n) {if (n == 0) {// base casereturn x;} else {// recursive casereturn _fact(n * x, n - 1);}};return fact(1, n);};
::: tip 结果不是由递归尾中的第一个函数生成(如在 n factorial(n-1)中),而是由递归尾中的最后一个函数生成(通过调用_fact(r n,n-1) )),并由该尾部的最后一个函数产生(带有 return r;)。 计算仅向下进行一次,而不向上进行。 将其作为解释器的迭代进行处理相对容易。 :::
但是,消除尾部调用在 JavaScript 中不起作用。 将上面的代码放入您最喜欢的 JavaScript 引擎中,factorial(24567)仍返回 Uncaught Error:RangeError: Maximum call stack size exceeded exception(最大调用堆栈大小超出异常)。 Tail-call 消除被列为新功能,将包含在下一版 ECMAScript 中,但是所有浏览器都需要一段时间才能实现。
语言规范和运行时解释器的功能,简单明了。 它与解释器如何获取堆栈帧资源有关。 某些语言在不需要记住任何新内容时会重用同一堆栈框架,例如前面的函数。 这就是消除 Tail-call 的方法,从而减少了时间和空间的复杂性。
不幸的是,JavaScript 无法做到这一点。 但是,如果这样做,它将从此重组堆栈帧:
call factorial (3)call fact (3 1)call fact (2 3)call fact (1 6)call fact (0 6)return 6return 6return 6return 6return 6
具体如下:
call factorial (3)call fact (3 1)call fact (2 3)call fact (1 6)call fact (0 6)return 6return 6
蹦床函数
解决方案? 一个被称为蹦床的过程。 这是通过使用 thunks 将“尾声消除”概念“破解”到程序中的一种方法。
::: tip
因此,Thunk 是带有参数的表达式,这些参数包装了没有自身参数的匿名函数。 例如:function (str){return function() {console.log(str)}。 这样可以防止在接收函数调用匿名函数之前对表达式进行求值。
:::
蹦床是一个函数,它接受一个函数作为输入,并重复执行其返回值,直到返回函数以外的其他值。下面的代码片段显示了一个简单的实现:
var trampoline = function(f) {while (f && f instanceof Function) {f = f.apply(f.context, f.args);}return f;};
要真正实现 tail-call 消除,我们需要使用 thunks。 为此,我们可以使用 bind()函数,该函数使我们可以将 this 关键字分配给另一个对象的方法应用于一个对象。 在内部,它与 call 关键字相同,但已链接到方法并返回一个新的绑定函数。 bind()函数实际上执行部分应用程序,但实际上确实可以部分应用。
要真正实现尾部调用消除,我们需要使用 thunks。为此,我们可以使用 bind()函数,该函数允许我们将一个方法应用于一个对象,并将此关键字分配给另一个对象。在内部,它与 call 关键字相同,但它链接到方法并返回一个新的绑定函数。bind()函数实际上执行部分应用程序,尽管方式非常有限。
var factorial = function(n) {var _fact = function(x, n) {if (n == 0) {// base casereturn x;} else {// recursive casereturn _fact.bind(null, n * x, n - 1);}};return trampoline(_fact.bind(null, 1, n));};
但是,编写 fact.bind(null,…)方法很麻烦,并且会使代码阅读困难。 取而代之的是,让我们编写自己的函数来创建 thunk(), 函数做以下几件事:
- thunk()函数必须模拟_fact.bind(null,n * x,n-1)方法返回一个未求值的函数
- thunk()函数应包含另外两个函数:
- 用于处理给定函数,以及
- 用于处理调用给定函数时将使用的函数参数
这样,我们就可以编写函数了。我们只需要几行代码就可以编写它。
var thunk = function(fn) {return function() {var args = Array.prototype.slice.apply(arguments);return function() {return fn.apply(this, args);};};};
现在我们可以在阶乘算法中使用 thunk()函数,如下所示:
var factorial = function(n) {var fact = function(x, n) {if (n == 0) {return x;} else {return thunk(fact)(n * x, n - 1);}};return trampoline(thunk(fact)(1, n));};
另外,我们可以通过将_fact()函数定义为 thunk()函数来进一步简化它。通过将内部函数定义为 thunk()函数,我们就不用在内部函数定义和 return 语句中都使用 thunk()函数了。
var factorial = function(n) {var _fact = thunk(function(x, n) {if (n == 0) {// base casereturn x;} else {// recursive casereturn _fact(n * x, n - 1);}});return trampoline(_fact(1, n));};
结果令人满意。 对于无尾递归,递归调用的函数_fact()几乎透明地作为迭代处理
最后,让我们看看 trampoline()和 thunk()函数如何与我们更有意义的树遍历示例一起工作。下面案例说明如何使用 trampolining 和 thunk 来遍历数据树:
var treeTraverse = function(trunk) {var _traverse = thunk(function(node) {node.doSomething();node.children.forEach(_traverse);}trampoline(_traverse(trunk));}
我们已经解决了尾部递归的问题。但还有更好的办法吗?如果我们可以简单地将递归函数转换为非递归函数呢?下一节,我们看看如何做。
Y-Combinator 推导
在计算机科学中,Y-combinator 推导甚至让编程大师们感到震惊。它将递归函数自动转换为非递归函数的能力,这就是为什么 Douglas Crockford 将其称为“计算机科学中最奇怪、最奇妙的产物之一”的原因,而 Sussman 和 Steele 曾经说过,“这种方法真的很了不起”。
264/5000 因此,将递归功能带到膝盖的计算机科学的真正卓越,奇特的奇特产物必须庞大而复杂,对吗? 不,不完全是。 它在 JavaScript 中的实现只有九行,非常奇怪。 它们如下:
它在 JavaScript 中的实现只有九行的代码。具体如下:
var Y = function(F) {return (function(f) {return f(f);})(function(f) {return F(function(x) {return f(f)(x);});});};
它的工作原理如下:它找到作为参数传入的函数的“固定点”。定点提供了另一种考虑功能的方法,而不是计算机编程理论中的递归和迭代。它仅通过使用匿名函数表达式,函数应用程序和变量引用来完成此操作。这里注意,Y 并没有引用它自己。实际上,所有这些都是匿名函数。(知乎:函数式编程的 Y Combinator 有哪些实用价值?)
正如你可能已经猜到的,Y-combinator 来自 lambda 表达式。它实际上是在另一个叫做 U-combinator 的组合器的帮助下导出的。组合器是一种特殊的高阶函数,它只使用函数应用程序和早期定义的组合器来定义输入的结果。
为了演示 Y-combinator,我们将再次讨论阶乘问题,但是我们需要对阶乘函数的定义稍有不同。我们编写的函数不是递归函数,该函数是阶乘的数学定义。 然后,我们可以将其传递给 Y-combinator。
var FactorialGen = function(factorial) {return (function(n) {if (n == 0) {// base casereturn 1;} else {// recursive casereturn n * factorial(n – 1);}});};Factorial = Y(FactorialGen);Factorial(10); // 3628800
但是,当我们给它一个很大的数字时,堆栈会溢出,就像使用了没有 trampolining 函数(蹦床函数)的尾递归一样。
Factorial(23456); // RangeError: Maximum call stack size exceeded
但是我们可以将 Y-combinator 用于蹦床函数,如下所示:
var FactorialGen2 = function(factorial) {return function(n) {var factorial = thunk(function(x, n) {if (n == 0) {return x;} else {return factorial(n * x, n - 1);}});return trampoline(factorial(1, n));};};var Factorial2 = Y(FactorialGen2);Factorial2(10); // 3628800Factorial2(23456); // Infinity
我们还可以重新排列 Y-combinator 来执行一种叫做 Memoization 的操作。
Memoization
Memoization 是 JavaScript 中的一种技术,通过缓存结果并在下一个操作中重新使用缓存来加速查找费时的操作。
尽管 Y 组合器比递归快得多,但它仍然相对较慢。 为了加快速度,我们可以创建一个记忆定点组合器:类似 Y 的组合器,用于缓存中间函数调用的结果。
尽管 Y-combinator 运算比递归运算快得多,但它仍然相对较慢。为了加快速度,我们可以创建一个 Memoization 优化组合:一个类似 Y-combinator 组合器,用于缓存中间函数调用的结果。
var Ymem = function(F, cache) {if (!cache) {cache = {}; // Create a new cache.}return function(arg) {if (cache[arg]) {// Answer in cachereturn cache[arg];}// else compute the answervar answer = F(function(n) {return Ymem(F, cache)(n);})(arg); // Compute the answer.cache[arg] = answer; // Cache the answer.return answer;};};
那么要快多少呢?通过使用http://jsperf.com/,我们可以比较性能。
以下结果是 1 到 100 之间的随机数。我们可以看到,记忆的(memoizing) Y-combinator 快得多。 并且向其添加蹦床函数不会使它减慢太多。 您可以在以下 URL 上查看结果并自己运行测试:http://jsperf.com/memoizing-y-combinator-vs-tail-calloptimization/7。
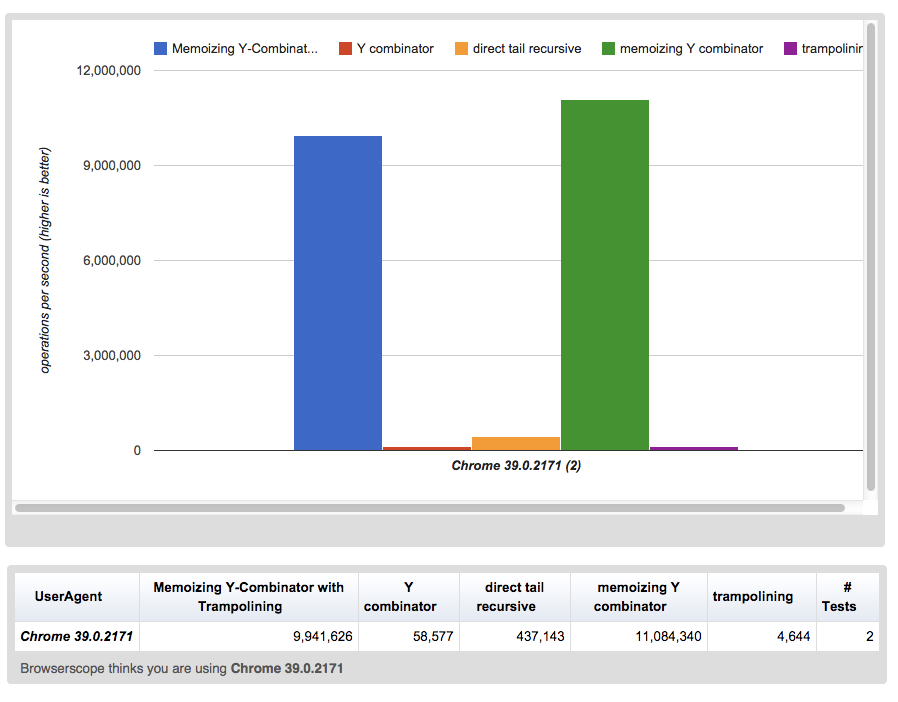
底线是:在 JavaScript 中执行递归的最安全有效的方法是通过蹦床函数和 thunk 来使用带有 Tail-call 消除的 memoization Y-combinator 组合器。
变量作用域
JavaScript 中变量作用域不是既定的,有人说 JavaScript 程序员可以通过对代码的理解程度来判断其作用域。
域范围
让我们讨论一下 JavaScript 中的不同域解析,JavaScript 使用作用域链来建立变量的作用域。 解析变量时,它从最内部的域开始并向外搜寻。
全局作用域
在此级别定义的变量,函数和对象可用于整个程序中的任何代码。 这是最外部的作用域。
局部作用域
每个函数都有自己的局部作用域。在另一个函数中定义的任何函数都具有链接到外部函数的嵌套局部作用域,几乎总是由源中的位置定义范围。
var x = "hi";function a() {console.log(x);}function b() {var x = "hello";console.log(x);}b(); // helloa(); // hi
局部作用域仅适用于函数,不适用于任何表达式语句(if, for, while 等),这与大多数语言对待作用域的方式不同。
function c() {var y = "greetings";if (true) {var y = "guten tag";}console.log(y);}function d() {var y = "greetings";function e() {var y = "guten tag";}console.log(y);}c(); // 'guten tag'd(); // 'greetings'
在函数式编程中,这并不是什么大问题,因为函数的使用频率更高,而表达式语句的使用频率更低。 例如:
function e(){var z = 'namaste';[1,2,3].foreach(function(n) {var z = 'aloha';}isTrue(function(){var z = 'good morning';});console.log(z);}e(); // 'namaste'
对象属性
对象属性也有自己的作用域链。
var x = "hi";var obj = function() {this.x = "hola";};var foo = new obj();console.log(foo.x); // 'hola'foo.x = "bonjour";console.log(foo.x); // 'bonjour'
并且对象的原型在作用域链的下游。
obj.prototype.x = "greetings";obj.prototype.y = "konnichi ha";var bar = new obj();console.log(bar.x); // still prints 'hola'console.log(bar.y); // 'konnichi ha'
闭包
这种作用域结构的一个问题是它没有空间容纳私有变量。如以下代码段:
var name = "Ford Focus";var year = "2006";var millage = 123456;function getMillage() {return millage;}function updateMillage(n) {millage = n;}
这些变量和函数是全局的,这意味着后面的代码很容易意外覆盖它们。 一种解决方案是将它们封装到一个函数中,并在定义它后立即调用该函数。
var car = (function() {var name = "Ford Focus";var year = "2006";var millage = 123456;function getMillage() {return Millage;}function updateMillage(n) {millage = n;}})();
函数之外什么都没有发生,因此我们应该通过使匿名函数来丢弃它。
(function() {var name = "Ford Focus";var year = "2006";var millage = 123456;function getMillage() {return millage;}function updateMillage(n) {millage = n;}})();
为了使函数 getValue()和 updateMillage()在匿名函数之外可用,我们需要以对象文本形式返回它们,如以下代码片段所示:
var car = (function() {var name = "Ford Focus";var year = "2006";var millage = 123456;return {getMillage: function() {return millage;},updateMillage: function(n) {millage = n;}};})();console.log(car.getMillage()); // worksconsole.log(car.updateMillage(n)); // also worksconsole.log(car.millage); // undefined
以上方法我们为我们提供了伪私有变量,但问题并不止于此。下一节将探讨 JavaScript 中变量作用域的更多问题。
一些问题
在 JavaScript 中可以找到许多可变范围的细微差别。以下并非一份全面的清单,但涵盖了最常见的情况:
- 以下将输出 4,而不是预期的’undefined’:
for (var n = 4; false; ) { } console.log(n);这是因为在 JavaScript 中,变量定义发生在相应作用域的开头,而不仅仅是在声明时。 - 如果在外部作用域中定义了一个变量,然后让 If 语句在函数内部使用相同的名称定义一个变量,即使没有到达分支,也会重新定义它。例如:
var x = 1;function foo() {if (false) {var x = 2;}return x;}foo(); // Return value: 'undefined', expected return value:2;// 同样,这是由于将变量定义移至未定义值的范围的开头而引起的。
- 在浏览器中,全局变量实际上存储在 window 对象中。
window.a = 19;console.log(a); // Output: 19
全局范围内的 a 表示 a 作为当前上下文的属性,因此 a === this.a 和浏览器中的 window 对象等效于全局范围内 this 关键字。
前两个示例是 JavaScript 功能(称为提升)的结果,这将成为下一部分有关编写函数的关键概念。
函数声明 vs 函数表达式 vs 函数构造函数
这三个语句有什么区别?
function foo(n) {return n;}var foo = function(n) {return n;};var foo = new Function("n", "return n");
乍一看,它们只是编写同一函数的不同方式。 但是这里还有更多事情要做。 而且,如果我们要充分利用 JavaScript 中的功能,以便将其操纵为功能编程风格,那么我们最好能够做到这一点。 如果有更好的方法可以在计算机编程中做某事,那么该方法应该是唯一的方法。
函数声明
函数声明(有时也称为函数语句)通过使用 function 关键字定义函数。
function foo(n) {return n;}
使用此语法声明的函数将提升到当前作用域的顶部。 这实际上意味着的是,即使将函数定义了几行,JavaScript 也会知道它,并且可以在范围内更早地使用它。 例如,以下将方法正确打印数字 6:
foo(2, 3);function foo(n, m) {console.log(n * m);}
函数表达式
通过定义匿名函数并将其分配给变量,命名函数也可以定义为表达式。
var bar = function(n, m) {console.log(n * m);};
它们不像函数声明那样被提升。这是因为,在提升函数声明时,变量声明不会。例如,这将不起作用并引发错误:
bar(2, 3);var bar = function(n, m) {console.log(n * m);};
在函数式编程中,我们将要使用函数表达式,以便将函数视为变量,使它们可用作回调和高阶函数(例如 map()函数)的参数。 将函数定义为表达式使它们更明显地成为分配给函数的变量。 另外,如果我们要以一种分格编写函数,为了一致性和清晰性,我们应该用这种样式编写所有函数。
Function()构造函数
JavaScript 实际上还有第三种创建函数的方法:使用 Function()构造函数。 就像函数表达式一样,不会悬挂使用 Function()构造函数定义的函数。
var func = new Function("n", "m", "return n+m");func(2, 3); // returns 5
但是 Function()构造函数不仅令人困惑,而且非常危险。 无法进行语法校正,无法进行优化。 编写相同的函数,如下所示更加容易,安全和避免混淆:
var func = function(n, m) {return n + m;};func(2, 3); // returns 5
不可预测的行为
所以不同的是,函数声明是提升的,而函数表达式不是。这会导致意想不到的事情发生。请考虑以下几点:
function foo() {return "hi";}console.log(foo());function foo() {return "hello";}
实际打印到控制台的是hello。这是因为foo()函数的第二个定义被提升到了顶部,成为JavaScript解释器实际使用的声明。
乍一看,这似乎并不是关键的区别,但在函数式编程中,这可能会造成混乱。 考虑以下代码片段:
if (true) {function foo() {console.log("one");}} else {function foo() {console.log("two");}}foo();
当调用foo()函数时,two被打印到控制台,而不是one!
最后,还有一种方法可以将函数表达式和声明结合起来:
var foo = function bar(){ console.log('hi'); };foo(); // 'hi'bar(); // Error: bar is not defined
这种方式的 使用方法没有什么意义,因为声明中使用的名称(前例中的bar()函数)在函数外部不可用,并导致混淆。它只适用于递归,例如:
var foo = function factorial(n) {if (n == 0) {return 1;} else {return n * factorial(n - 1);}};foo(5);
小结
JavaScript被称为“web的汇编语言”,因为它和x86汇编一样无处不在,不可避免。它是所有浏览器上唯一运行的语言。它也有缺陷,但把它作为一种低级语言来指是没有意义的。
相反,可以将JavaScript看作是web的原始咖啡豆。当然,有些豆子坏了,有些烂了。但是,如果好的咖啡豆是由一位熟练的咖啡师挑选、烘焙和酿造的,那么这些咖啡豆就可以变成一种绝妙的果酱,而这种果酱不可能只吃一次就被遗忘。它的消费成为一种日常习惯,没有它的生活将是静止的,更难回顾,更不令人兴奋。有些人甚至更喜欢使用插件和诸如奶油、糖和可可之类的附加组件来增强啤酒的质量,这些插件和附加组件可以很好地补充啤酒的质量。
引用JavaScript的最大批评家之一Douglas Crawford说:“肯定有很多人拒绝考虑JavaScript有没有可能做对任何事情。我以前也是那种人。但现在我仍然对那里的辉煌感到惊讶。
JavaScript真是太棒了。

若有收获,就点个赞吧
0 人点赞
